

In questo articolo parlerò di come il progetto a cui sto lavorando si è trasformato da un grande monolite in un insieme di microservizi.
Il progetto ha iniziato la sua storia molto tempo fa, all'inizio del 2000. Le prime versioni sono state scritte in Visual Basic 6. Nel tempo, è diventato chiaro che lo sviluppo in questo linguaggio sarebbe stato difficile da supportare in futuro, dal momento che l'IDE e la lingua stessa sono poco sviluppate. Alla fine degli anni 2000 si decise di passare al più promettente C#. La nuova versione è stata scritta parallelamente alla revisione di quella vecchia, gradualmente sempre più codice è stato scritto in .NET. Il backend in C# era inizialmente focalizzato su un'architettura di servizi, ma durante lo sviluppo sono state utilizzate librerie comuni con logica e i servizi sono stati avviati in un unico processo. Il risultato è stato un’applicazione che abbiamo chiamato “monolite di servizi”.
Uno dei pochi vantaggi di questa combinazione era la capacità dei servizi di chiamarsi tra loro tramite un'API esterna. C'erano prerequisiti chiari per il passaggio a un servizio più corretto e, in futuro, all'architettura dei microservizi.
Abbiamo iniziato il nostro lavoro sulla decomposizione intorno al 2015. Non abbiamo ancora raggiunto uno stato ideale: ci sono ancora parti di un grande progetto che difficilmente possono essere chiamate monoliti, ma non sembrano nemmeno microservizi. Tuttavia, i progressi sono significativi.
Ne parlerò nell'articolo.
contenuto
Architettura e problemi della soluzione esistente
Inizialmente, l'architettura era simile a questa: l'interfaccia utente è un'applicazione separata, la parte monolitica è scritta in Visual Basic 6, l'applicazione .NET è un insieme di servizi correlati che funzionano con un database sufficientemente grande.
Svantaggi della soluzione precedente
Singolo punto di guasto
Abbiamo avuto un unico punto di errore: l'applicazione .NET veniva eseguita in un unico processo. Se un modulo si guastava, l'intera applicazione falliva e doveva essere riavviata. Poiché automatizziamo un gran numero di processi per utenti diversi, a causa di un guasto in uno di essi, tutti non potrebbero lavorare per un po' di tempo. E in caso di errore del software, anche il backup non ha aiutato.
Coda di miglioramenti
Questo inconveniente è piuttosto organizzativo. La nostra applicazione ha molti clienti e tutti vogliono migliorarla il prima possibile. In precedenza, era impossibile farlo in parallelo e tutti i clienti erano in fila. Questo processo è stato negativo per le imprese perché dovevano dimostrare che il loro compito era prezioso. E il team di sviluppo ha dedicato del tempo a organizzare questa coda. Ciò ha richiesto molto tempo e impegno e alla fine il prodotto non è stato in grado di cambiare così rapidamente come avrebbero voluto.
Utilizzo non ottimale delle risorse
Quando ospitiamo servizi in un unico processo, copiamo sempre completamente la configurazione da server a server. Volevamo posizionare separatamente i servizi maggiormente caricati in modo da non sprecare risorse e ottenere un controllo più flessibile sul nostro schema di implementazione.
Difficile implementare le tecnologie moderne
Un problema familiare a tutti gli sviluppatori: c'è il desiderio di introdurre tecnologie moderne nel progetto, ma non c'è alcuna opportunità. Con una soluzione monolitica di grandi dimensioni, qualsiasi aggiornamento della libreria attuale, per non parlare del passaggio a una nuova, si trasforma in un compito piuttosto non banale. Ci vuole molto tempo per dimostrare al caposquadra che questo porterà più bonus che nervi sprecati.
Difficoltà nell'emettere modifiche
Questo era il problema più serio: rilasciavamo pubblicazioni ogni due mesi.
Ogni versione si è trasformata in un vero disastro per la banca, nonostante i test e gli sforzi degli sviluppatori. L'azienda ha capito che all'inizio della settimana alcune delle sue funzionalità non avrebbero funzionato. E gli sviluppatori hanno capito che li attendeva una settimana di incidenti gravi.
Tutti avevano il desiderio di cambiare la situazione.
Aspettative dai microservizi
Emissione dei componenti quando pronti. Consegna dei componenti quando pronti scomponendo la soluzione e separando diversi processi.
Piccoli team di prodotto. Questo è importante perché una grande squadra che lavorava sul vecchio monolite era difficile da gestire. Una squadra del genere era costretta a lavorare secondo un processo rigoroso, ma voleva più creatività e indipendenza. Solo le piccole squadre potevano permetterselo.
Isolamento dei servizi in processi separati. Idealmente, vorrei isolarlo in container, ma un gran numero di servizi scritti nel .NET Framework vengono eseguiti solo sotto WindowsStanno emergendo servizi basati su .NET Core, ma sono ancora pochi.
Flessibilità di distribuzione. Vorremmo combinare i servizi nel modo in cui ne abbiamo bisogno e non nel modo in cui il codice lo impone.
Utilizzo delle nuove tecnologie. Questo è interessante per qualsiasi programmatore.
Problemi di transizione
Naturalmente, se fosse facile spezzare un monolite in microservizi, non ci sarebbe bisogno di parlarne alle conferenze e scrivere articoli. Ci sono molte insidie in questo processo; descriverò le principali che ci hanno ostacolato.
Primo problema tipico della maggior parte dei monoliti: coerenza della logica aziendale. Quando scriviamo un monolite, vogliamo riutilizzare le nostre classi per non scrivere codice non necessario. E quando si passa ai microservizi, questo diventa un problema: tutto il codice è strettamente accoppiato ed è difficile separare i servizi.
Al momento dell'inizio dei lavori, il repository conteneva più di 500 progetti e più di 700mila righe di codice. Questa è una decisione piuttosto importante e secondo problema. Non era possibile semplicemente prenderlo e dividerlo in microservizi.
Terzo problema — mancanza delle infrastrutture necessarie. In effetti, copiavamo manualmente il codice sorgente sui server.
Come passare dal monolite ai microservizi
Provisioning di microservizi
Innanzitutto abbiamo capito subito che la separazione dei microservizi è un processo iterativo. Ci è sempre stato richiesto di sviluppare i problemi aziendali in parallelo. Il modo in cui lo implementeremo tecnicamente è già un nostro problema. Pertanto, ci siamo preparati per un processo iterativo. Non funzionerà in nessun altro modo se si dispone di un'applicazione di grandi dimensioni e inizialmente non è pronta per essere riscritta.
Quali metodi utilizziamo per isolare i microservizi?
Il primo metodo — spostare i moduli esistenti come servizi. A questo proposito siamo stati fortunati: c'erano già servizi registrati che funzionavano utilizzando il protocollo WCF. Erano separati in assemblee separate. Li abbiamo portati separatamente, aggiungendo un piccolo launcher a ciascuna build. È stato scritto utilizzando la meravigliosa libreria Topshelf, che consente di eseguire l'applicazione sia come servizio che come console. Ciò è utile per il debug poiché nella soluzione non sono richiesti progetti aggiuntivi.
I servizi erano collegati secondo la logica aziendale, poiché utilizzavano assembly comuni e lavoravano con un database comune. Difficilmente potrebbero essere chiamati microservizi nella loro forma pura. Tuttavia, potremmo fornire questi servizi separatamente, in processi diversi. Solo questo ha permesso di ridurre la loro influenza reciproca, riducendo il problema con lo sviluppo parallelo e un singolo punto di fallimento.
L'assemblaggio con l'host è solo una riga di codice nella classe Program. Abbiamo nascosto il lavoro con Topshelf in una classe ausiliaria.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
Il secondo modo per allocare i microservizi è: crearli per risolvere nuovi problemi. Se allo stesso tempo il monolite non cresce è già ottimo, significa che ci stiamo muovendo nella giusta direzione. Per risolvere nuovi problemi, abbiamo provato a creare servizi separati. Se esistesse una tale opportunità, abbiamo creato servizi più “canonici” che gestiscono completamente il proprio modello di dati, un database separato.
Come molti, abbiamo iniziato con i servizi di autenticazione e autorizzazione. Sono perfetti per questo. Sono indipendenti, di norma hanno un modello di dati separato. Loro stessi non interagiscono con il monolite, si rivolge solo a loro per risolvere alcuni problemi. Utilizzando questi servizi, puoi iniziare la transizione verso una nuova architettura, eseguire il debug dell'infrastruttura su di essi, provare alcuni approcci relativi alle librerie di rete, ecc. Non abbiamo team nella nostra organizzazione che non siano in grado di creare un servizio di autenticazione.
Il terzo modo per allocare i microserviziQuello che usiamo è un po' specifico per noi. Questa è la rimozione della logica aziendale dal livello dell'interfaccia utente. La nostra principale applicazione dell'interfaccia utente è desktop; come il backend, è scritta in C#. Gli sviluppatori periodicamente commettevano errori e trasferivano parti della logica nell'interfaccia utente che avrebbero dovuto esistere nel backend ed essere riutilizzate.
Se osservi un esempio reale dal codice della parte dell'interfaccia utente, puoi vedere che la maggior parte di questa soluzione contiene una vera logica aziendale utile in altri processi, non solo per creare il modulo dell'interfaccia utente.
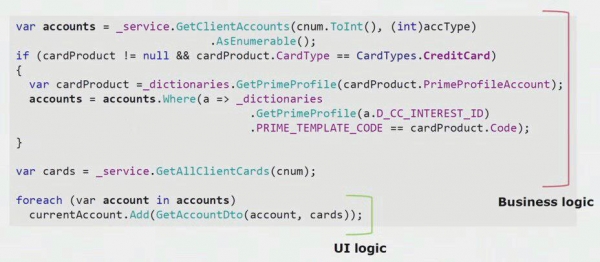
La vera logica dell'interfaccia utente è presente solo nelle ultime due righe. Lo abbiamo trasferito sul server in modo che potesse essere riutilizzato, riducendo così l'interfaccia utente e ottenendo l'architettura corretta.
Il quarto e più importante modo per isolare i microservizi, che consente di ridurre il monolite, è la rimozione dei servizi esistenti con l'elaborazione. Quando eliminiamo i moduli esistenti così come sono, il risultato non è sempre gradito agli sviluppatori e il processo aziendale potrebbe essere diventato obsoleto da quando è stata creata la funzionalità. Con il refactoring possiamo supportare un nuovo processo aziendale perché i requisiti aziendali cambiano costantemente. Possiamo migliorare il codice sorgente, rimuovere i difetti noti e creare un modello di dati migliore. Ci sono molti benefici che si ottengono.
La separazione dei servizi dal trattamento è indissolubilmente legata al concetto di contesto delimitato. Questo è un concetto di Domain Driven Design. Significa una sezione del modello di dominio in cui tutti i termini di una singola lingua sono definiti in modo univoco. Diamo un'occhiata al contesto delle assicurazioni e delle fatture come esempio. Abbiamo un'applicazione monolitica e dobbiamo lavorare con l'account dell'assicurazione. Ci aspettiamo che lo sviluppatore trovi una classe Account esistente in un altro assembly, vi faccia riferimento dalla classe Insurance e avremo un codice funzionante. Il principio DRY sarà rispettato, l'attività verrà eseguita più velocemente utilizzando il codice esistente.
Di conseguenza, risulta che i contesti dei conti e delle assicurazioni sono collegati. Man mano che emergono nuovi requisiti, questo accoppiamento interferirà con lo sviluppo, aumentando la complessità di una logica aziendale già complessa. Per risolvere questo problema, è necessario trovare i confini tra i contesti nel codice ed eliminare le loro violazioni. Nel contesto assicurativo, ad esempio, è molto probabile che siano sufficienti il numero di conto della Banca centrale di 20 cifre e la data di apertura del conto.
Per separare questi contesti delimitati gli uni dagli altri e iniziare il processo di separazione dei microservizi da una soluzione monolitica, abbiamo utilizzato un approccio come la creazione di API esterne all'interno dell'applicazione. Se sapessimo che qualche modulo dovesse diventare un microservizio, in qualche modo modificato all'interno del processo, allora faremmo immediatamente delle chiamate alla logica che appartiene ad un altro contesto limitato tramite chiamate esterne. Ad esempio, tramite REST o WCF.
Abbiamo deciso fermamente che non avremmo evitato il codice che richiederebbe transazioni distribuite. Nel nostro caso, si è rivelato abbastanza semplice seguire questa regola. Non abbiamo ancora riscontrato situazioni in cui siano realmente necessarie transazioni distribuite rigorose: la coerenza finale tra i moduli è abbastanza sufficiente.
Diamo un'occhiata a un esempio specifico. Abbiamo il concetto di orchestratore: una pipeline che elabora l'entità dell '"applicazione". Crea a sua volta un cliente, un conto e una carta bancaria. Se il cliente e il conto vengono creati con successo, ma la creazione della carta fallisce, l'applicazione non passa allo stato "riuscito" e rimane nello stato "carta non creata". In futuro, l'attività in background lo riprenderà e lo finirà. Da tempo il sistema versa in uno stato di incoerenza, ma in generale ne siamo soddisfatti.
Se si verifica una situazione in cui è necessario salvare in modo coerente parte dei dati, molto probabilmente opteremo per il consolidamento del servizio per elaborarlo in un unico processo.
Diamo un'occhiata a un esempio di allocazione di un microservizio. Come puoi portarlo in produzione in modo relativamente sicuro? In questo esempio, abbiamo una parte separata del sistema: un modulo di servizio buste paga, una delle sezioni di codice di cui vorremmo creare un microservizio.
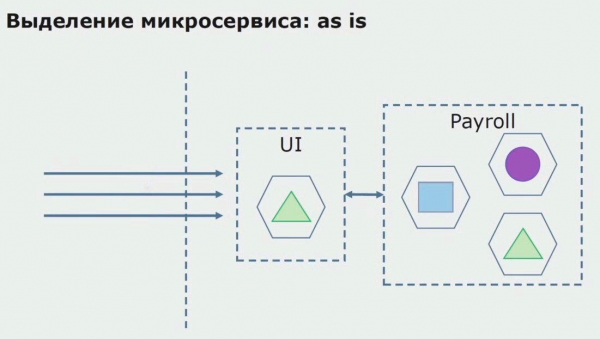
Innanzitutto creiamo un microservizio riscrivendone il codice. Stiamo migliorando alcuni aspetti di cui non eravamo soddisfatti. Implementiamo le nuove esigenze aziendali del cliente. Aggiungiamo un gateway API alla connessione tra l'interfaccia utente e il backend, che fornirà l'inoltro delle chiamate.
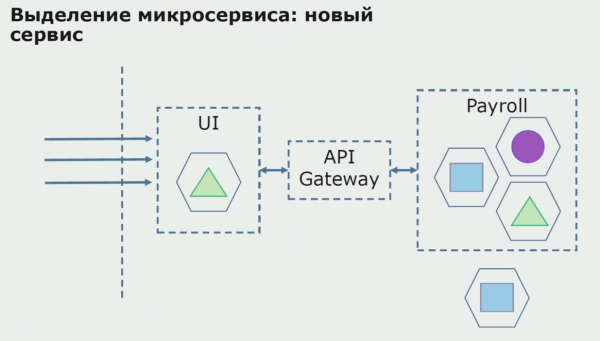
Successivamente, mettiamo in funzione questa configurazione, ma in uno stato pilota. La maggior parte dei nostri utenti lavora ancora con vecchi processi aziendali. Per i nuovi utenti, stiamo sviluppando una nuova versione dell'applicazione monolitica che non contiene più questo processo. Essenzialmente, abbiamo una combinazione di un monolite e un microservizio che funziona come pilota.
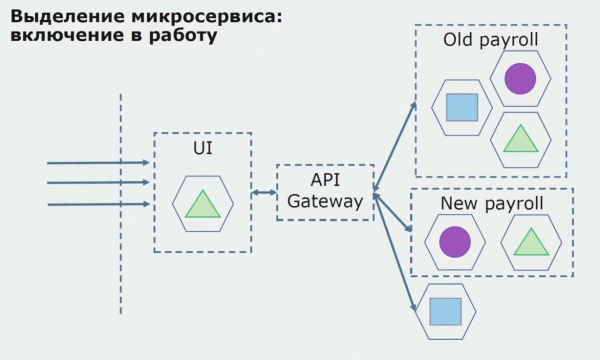
Con un progetto pilota di successo, capiamo che la nuova configurazione è effettivamente praticabile, possiamo rimuovere il vecchio monolite dall'equazione e lasciare la nuova configurazione al posto della vecchia soluzione.
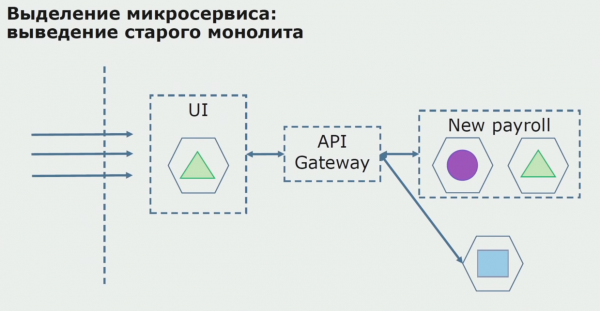
In totale, utilizziamo quasi tutti i metodi esistenti per suddividere il codice sorgente di un monolite. Tutti ci consentono di ridurre la dimensione di parti dell'applicazione e di tradurle in nuove librerie, creando un codice sorgente migliore.
Lavorare con il database
Il database può essere suddiviso in modo peggiore rispetto al codice sorgente, poiché contiene non solo lo schema corrente, ma anche i dati storici accumulati.
Il nostro database, come molti altri, presentava un altro importante inconveniente: le sue enormi dimensioni. Questo database è stato progettato secondo l'intricata logica aziendale di un monolite e le relazioni accumulate tra le tabelle di vari contesti delimitati.
Nel nostro caso, oltre a tutti i problemi (database di grandi dimensioni, molte connessioni, confini a volte poco chiari tra le tabelle), è sorto un problema che si verifica in molti progetti di grandi dimensioni: l'uso del modello di database condiviso. I dati sono stati prelevati dalle tabelle tramite visualizzazione, tramite replica e inviati ad altri sistemi in cui era necessaria questa replica. Di conseguenza, non è stato possibile spostare le tabelle in uno schema separato perché venivano utilizzate attivamente.
La stessa divisione in contesti limitati nel codice ci aiuta nella separazione. Di solito ci dà un'idea abbastanza chiara di come suddividiamo i dati a livello di database. Comprendiamo quali tabelle appartengono a un contesto delimitato e quali a un altro.
Abbiamo utilizzato due metodi globali di partizionamento del database: partizionamento delle tabelle esistenti e partizionamento con elaborazione.
La suddivisione delle tabelle esistenti è un buon metodo da utilizzare se la struttura dei dati è buona, soddisfa i requisiti aziendali e tutti ne sono soddisfatti. In questo caso, possiamo separare le tabelle esistenti in uno schema separato.
Un reparto con lavorazioni serve quando il modello di business è cambiato molto, e i tavoli non ci soddisfano più per nulla.
Divisione delle tabelle esistenti. Dobbiamo determinare cosa separeremo. Senza questa conoscenza, nulla funzionerà, e qui la separazione dei contesti delimitati nel codice ci aiuterà. Di norma, se riesci a comprendere i confini dei contesti nel codice sorgente, diventa chiaro quali tabelle dovrebbero essere incluse nell'elenco per il dipartimento.
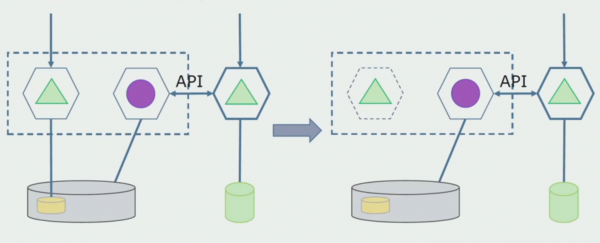
Immaginiamo di avere una soluzione in cui due moduli monolitici interagiscono con un database. Dobbiamo assicurarci che solo un modulo interagisca con la sezione delle tabelle separate e l'altro inizi a interagire con essa tramite l'API. Per cominciare è sufficiente che venga effettuata solo la registrazione tramite API. Questa è una condizione necessaria per poter parlare di indipendenza dei microservizi. Le connessioni in lettura possono rimanere finché non ci sono grossi problemi.
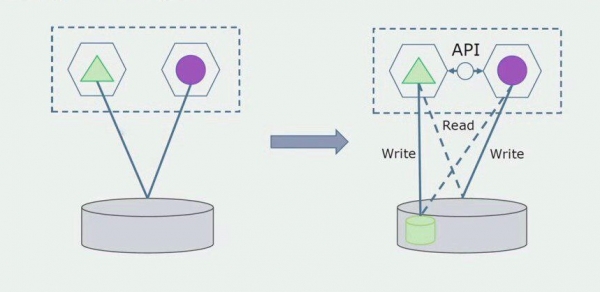
Il passaggio successivo è che possiamo separare la sezione di codice che funziona con tabelle separate, con o senza elaborazione, in un microservizio separato ed eseguirlo in un processo separato, un contenitore. Questo sarà un servizio separato con una connessione al database Monolith e a quelle tabelle che non si riferiscono direttamente ad esso. Il monolite interagisce ancora per la lettura con la parte staccabile.
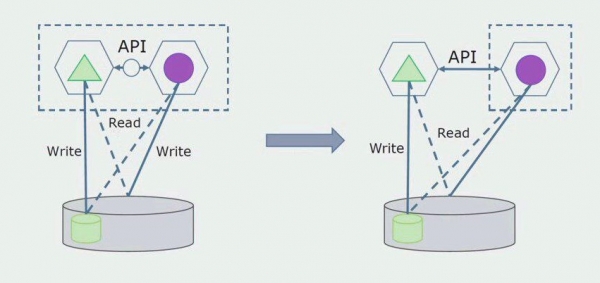
Successivamente rimuoveremo questa connessione, ovvero anche la lettura dei dati da un'applicazione monolitica da tabelle separate verrà trasferita all'API.
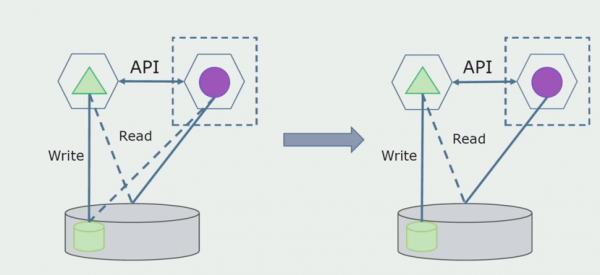
Successivamente selezioneremo dal database generale le tabelle con cui funziona solo il nuovo microservizio. Possiamo spostare le tabelle in uno schema separato o anche in un database fisico separato. Esiste ancora una connessione di lettura tra il microservizio e il database monolite, ma non c'è nulla di cui preoccuparsi, in questa configurazione può vivere a lungo.
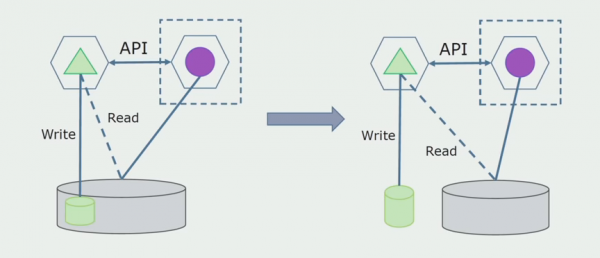
L'ultimo passaggio è rimuovere completamente tutte le connessioni. In questo caso, potrebbe essere necessario migrare i dati dal database principale. A volte vogliamo riutilizzare alcuni dati o directory replicati da sistemi esterni in diversi database. Questo ci accade periodicamente.
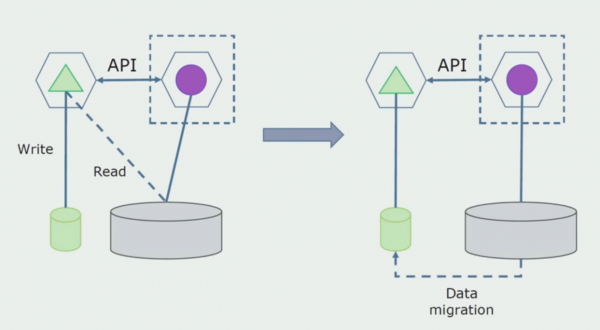
Reparto di lavorazione. Questo metodo è molto simile al primo, solo in ordine inverso. Assegniamo immediatamente un nuovo database e un nuovo microservizio che interagisce con il monolite tramite un'API. Allo stesso tempo, però, rimane una serie di tabelle del database che desideriamo eliminare in futuro. Non ne abbiamo più bisogno; lo abbiamo sostituito nel nuovo modello.
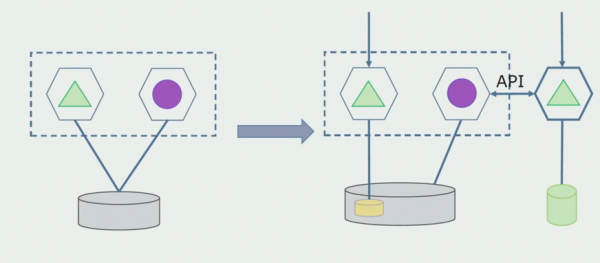
Perché questo sistema funzioni, probabilmente avremo bisogno di un periodo di transizione.
Ci sono allora due possibili approcci.
Prima: duplichiamo tutti i dati nei nuovi e vecchi database. In questo caso abbiamo una ridondanza di dati e potrebbero sorgere problemi di sincronizzazione. Ma possiamo prendere due clienti diversi. Uno funzionerà con la nuova versione, l'altro con quella vecchia.
Secondo: dividiamo i dati secondo alcuni criteri aziendali. Ad esempio, nel sistema erano presenti 5 prodotti archiviati nel vecchio database. Inseriamo il sesto all'interno della nuova attività aziendale in un nuovo database. Ma avremo bisogno di un gateway API che sincronizzerà questi dati e mostrerà al client dove e cosa ottenere.
Entrambi gli approcci funzionano, scegli a seconda della situazione.
Dopo che siamo sicuri che tutto funzioni, la parte del monolite che funziona con le vecchie strutture del database può essere disabilitata.
L'ultimo passaggio è rimuovere le vecchie strutture dati.
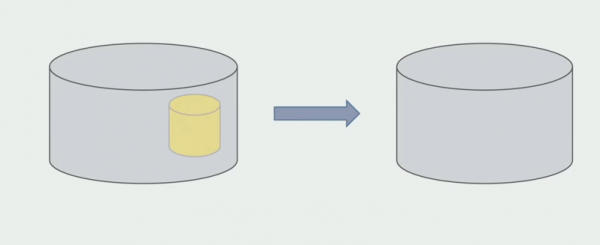
Riassumendo possiamo dire che abbiamo problemi con il database: è difficile lavorarci rispetto al codice sorgente, è più difficile condividerlo, ma si può e si deve fare. Abbiamo trovato alcuni modi che ci permettono di farlo in tutta sicurezza, ma è comunque più facile commettere errori con i dati che con il codice sorgente.
Lavorare con il codice sorgente
Questo è l'aspetto del diagramma del codice sorgente quando abbiamo iniziato ad analizzare il progetto monolitico.
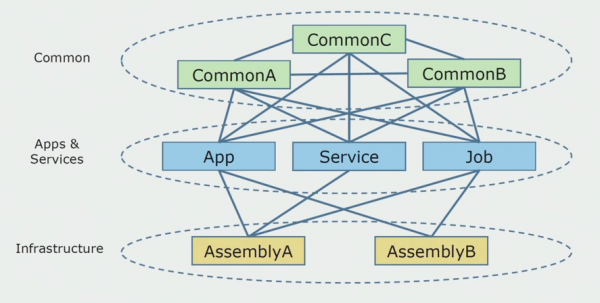
Può essere approssimativamente diviso in tre strati. Questo è uno strato di moduli lanciati, plugin, servizi e attività individuali. In realtà, questi erano punti di ingresso all’interno di una soluzione monolitica. Tutti erano sigillati ermeticamente con uno strato comune. Aveva una logica aziendale che i servizi fossero condivisi e molte connessioni. Ogni servizio e plugin utilizzava fino a 10 o più assembly comuni, a seconda delle dimensioni e della coscienza degli sviluppatori.
Siamo stati fortunati ad avere librerie infrastrutturali che potevano essere utilizzate separatamente.
A volte si verificava una situazione in cui alcuni oggetti comuni non appartenevano effettivamente a questo livello, ma erano librerie dell'infrastruttura. Questo è stato risolto rinominandolo.
La preoccupazione più grande riguardava i contesti delimitati. È capitato che 3-4 contesti si mescolassero in un unico assieme comune e si utilizzassero a vicenda all'interno delle stesse funzioni aziendali. Era necessario capire dove questo potesse essere diviso e lungo quali confini, e cosa fare dopo mappando questa divisione in gruppi di codice sorgente.
Abbiamo formulato diverse regole per il processo di suddivisione del codice.
Il primo: Non volevamo più condividere la logica di business tra servizi, attività e plugin. Volevamo rendere la logica aziendale indipendente all'interno dei microservizi. I microservizi, invece, sono idealmente pensati come servizi che esistono in modo completamente indipendente. Credo che questo approccio sia alquanto dispendioso e difficile da realizzare, perché, ad esempio, i servizi in C# saranno comunque collegati da una libreria standard. Il nostro sistema è scritto in C#; non abbiamo ancora utilizzato altre tecnologie. Pertanto, abbiamo deciso che potevamo permetterci di utilizzare assemblaggi tecnici comuni. La cosa principale è che non contengono frammenti di logica aziendale. Se disponi di un comodo wrapper sull'ORM che stai utilizzando, copiarlo da un servizio all'altro è molto costoso.
Il nostro team è un fan della progettazione basata sui domini, quindi l'architettura Onion era perfetta per noi. La base dei nostri servizi non è il livello di accesso ai dati, ma un insieme con logica di dominio, che contiene solo logica di business e non ha collegamenti con l'infrastruttura. Allo stesso tempo, possiamo modificare in modo indipendente l'assemblaggio del dominio per risolvere problemi relativi ai framework.
A questo punto abbiamo riscontrato il nostro primo problema serio. Il servizio doveva fare riferimento ad un insieme di domini, volevamo rendere la logica indipendente e qui il principio DRY ci ha molto ostacolato. Gli sviluppatori volevano riutilizzare le classi degli assembly vicini per evitare duplicazioni e, di conseguenza, i domini hanno iniziato a essere nuovamente collegati tra loro. Abbiamo analizzato i risultati e abbiamo deciso che forse il problema risiede anche nell'area del dispositivo di memorizzazione del codice sorgente. Avevamo un ampio repository contenente tutto il codice sorgente. È stato molto difficile assemblare la soluzione per l'intero progetto su una macchina locale. Pertanto, sono state create piccole soluzioni separate per parti del progetto e nessuno ha vietato di aggiungere ad esse alcuni assembly comuni o di dominio e di riutilizzarli. L'unico strumento che non ci permetteva di farlo era la revisione del codice. Ma a volte ha anche fallito.
Quindi abbiamo iniziato a passare a un modello con repository separati. La logica aziendale non scorre più da un servizio all'altro, i domini sono diventati veramente indipendenti. I contesti delimitati sono supportati in modo più chiaro. Come riutilizziamo le librerie dell'infrastruttura? Li abbiamo separati in un repository separato, quindi li abbiamo inseriti nei pacchetti Nuget, che abbiamo inserito in Artifactory. Con qualsiasi modifica, l'assemblaggio e la pubblicazione avvengono automaticamente.
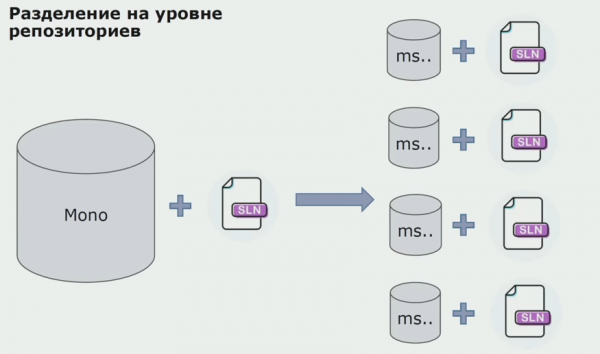
I nostri servizi hanno iniziato a fare riferimento ai pacchetti di infrastrutture interne allo stesso modo di quelli esterni. Scarichiamo librerie esterne da Nuget. Per lavorare con Artifactory, dove abbiamo inserito questi pacchetti, abbiamo utilizzato due gestori di pacchetti. Nei piccoli repository abbiamo utilizzato anche Nuget. Nei repository con più servizi, abbiamo utilizzato Paket, che fornisce una maggiore coerenza di versione tra i moduli.
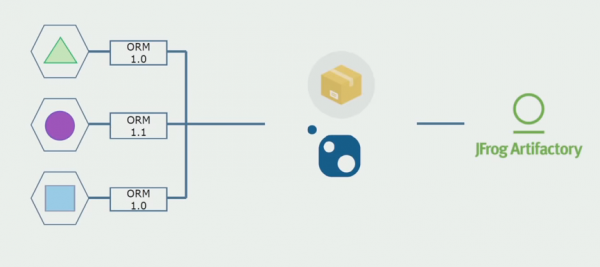
Pertanto, lavorando sul codice sorgente, modificando leggermente l'architettura e separando i repository, rendiamo i nostri servizi più indipendenti.
Problemi infrastrutturali
La maggior parte degli svantaggi del passaggio ai microservizi sono legati all’infrastruttura. Avrai bisogno di una distribuzione automatizzata, avrai bisogno di nuove librerie per eseguire l'infrastruttura.
Installazione manuale negli ambienti
Inizialmente, abbiamo installato manualmente la soluzione per gli ambienti. Per automatizzare questo processo, abbiamo creato una pipeline CI/CD. Abbiamo scelto il processo di consegna continua perché per noi l'implementazione continua non è ancora accettabile dal punto di vista dei processi aziendali. Pertanto, l'invio per l'operazione viene effettuato utilizzando un pulsante e per il test - automaticamente.
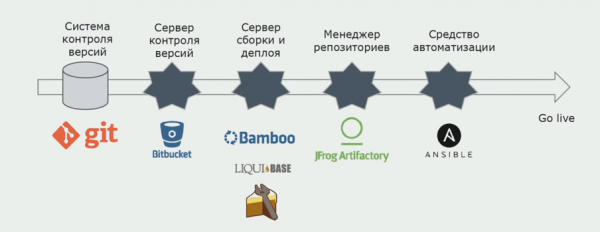
Utilizziamo Atlassian, Bitbucket per l'archiviazione del codice sorgente e Bamboo per la creazione. Ci piace scrivere script di compilazione in Cake perché è uguale a C#. I pacchetti già pronti arrivano ad Artifactory e Ansible arriva automaticamente ai server di test, dopodiché possono essere testati immediatamente.
Registrazione separata
Un tempo, una delle idee del monolite era quella di fornire una registrazione condivisa. Avevamo anche bisogno di capire cosa fare con i singoli log presenti sui dischi. I nostri log vengono scritti in file di testo. Abbiamo deciso di utilizzare uno stack ELK standard. Non abbiamo scritto a ELK direttamente tramite i provider, ma abbiamo deciso di modificare i log di testo e di scrivere al loro interno l'ID di traccia come identificatore, aggiungendo il nome del servizio, in modo che questi log potessero essere analizzati in seguito.
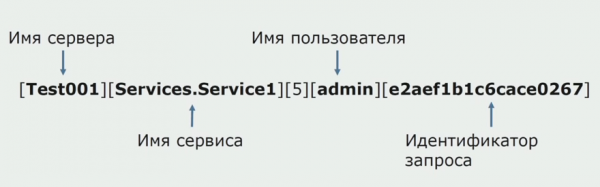
Con Filebeat siamo in grado di raccogliere i nostri log da server, quindi trasformarli, utilizzare Kibana per creare query nell'interfaccia utente e vedere come la chiamata è stata instradata tra i servizi. Gli ID di tracciamento sono molto utili a questo scopo.
Servizi correlati al test e al debug
Inizialmente, non comprendevamo appieno come eseguire il debug dei servizi in fase di sviluppo. Tutto è stato semplice con il monolite; lo abbiamo eseguito su una macchina locale. Inizialmente hanno provato a fare lo stesso con i microservizi, ma a volte per avviare completamente un microservizio è necessario avviarne molti altri, e questo è scomodo. Ci siamo resi conto che dobbiamo passare a un modello in cui lasciamo sulla macchina locale solo il servizio o i servizi di cui vogliamo eseguire il debug. I restanti servizi vengono utilizzati dai server che corrispondono alla configurazione con prod. Dopo il debug, durante il test, per ciascuna attività, solo i servizi modificati vengono inviati al server di test. Pertanto, la soluzione viene testata nella forma in cui apparirà in produzione in futuro.
Esistono server che eseguono solo versioni di produzione dei servizi. Questi server sono necessari in caso di incidenti, per verificare la consegna prima dell'implementazione e per la formazione interna.
Abbiamo aggiunto un processo di test automatizzato utilizzando la popolare libreria Specflow. I test vengono eseguiti automaticamente utilizzando NUnit immediatamente dopo la distribuzione da Ansible. Se la copertura delle attività è completamente automatica, non è necessario eseguire test manuali. Anche se a volte sono ancora necessari ulteriori test manuali. Utilizziamo i tag in Jira per determinare quali test eseguire per un problema specifico.
Inoltre è aumentata la necessità di effettuare prove di carico, che in precedenza venivano eseguite solo in rari casi. Utilizziamo JMeter per eseguire test, InfluxDB per archiviarli e Grafana per creare grafici di processo.
Cosa abbiamo ottenuto?
Innanzitutto ci siamo sbarazzati del concetto di “rilascio”. Sono finiti i rilasci mostruosi di due mesi in cui questo colosso veniva implementato in un ambiente di produzione, interrompendo temporaneamente i processi aziendali. Ora distribuiamo i servizi in media ogni 1,5 giorni, raggruppandoli perché entrano in funzione dopo l'approvazione.
Non ci sono guasti fatali nel nostro sistema. Se rilasciamo un microservizio con un bug, la funzionalità ad esso associata verrà interrotta e tutte le altre funzionalità non saranno influenzate. Ciò migliora notevolmente l'esperienza dell'utente.
Possiamo controllare il modello di distribuzione. Se necessario è possibile selezionare gruppi di servizi separatamente dal resto della soluzione.
Inoltre, abbiamo ridotto significativamente il problema con una lunga coda di miglioramenti. Ora disponiamo di team di prodotto separati che lavorano con alcuni servizi in modo indipendente. Il processo Scrum è già una buona soluzione in questo caso. Un team specifico può avere un Product Owner separato che gli assegna i compiti.
Riassunto
- I microservizi sono particolarmente adatti per scomporre sistemi complessi. Nel processo, iniziamo a capire cosa c’è nel nostro sistema, quali contesti limitati esistono, dove si trovano i loro confini. Ciò consente di distribuire correttamente i miglioramenti tra i moduli e prevenire la confusione del codice.
- I microservizi offrono vantaggi organizzativi. Spesso se ne parla solo come architettura, ma qualsiasi architettura è necessaria per risolvere le esigenze aziendali e non da sola. Pertanto, possiamo dire che i microservizi sono adatti per risolvere problemi in piccoli team, dato che Scrum è molto popolare ora.
- La separazione è un processo iterativo. Non puoi prendere un'applicazione e dividerla semplicemente in microservizi. È improbabile che il prodotto risultante sia funzionale. Quando si dedicano microservizi, è vantaggioso riscrivere l’eredità esistente, ovvero trasformarla nel codice che ci piace e che soddisfa meglio le esigenze aziendali in termini di funzionalità e velocità.
Un piccolo avvertimento: I costi del passaggio ai microservizi sono piuttosto significativi. Ci è voluto molto tempo per risolvere da solo il problema delle infrastrutture. Pertanto, se hai una piccola applicazione che non richiede un dimensionamento specifico, a meno che tu non abbia un gran numero di clienti in competizione per l'attenzione e il tempo del tuo team, i microservizi potrebbero non essere ciò di cui hai bisogno oggi. È piuttosto costoso. Se si avvia il processo con i microservizi, i costi saranno inizialmente più elevati rispetto a quando si avvia lo stesso progetto con lo sviluppo di un monolite.
PS Una storia più emozionante (e come se fosse per te personalmente) - secondo .
Ecco la versione completa del rapporto.
Fonte: habr.com
