

Recentemente ho parlato di come utilizzare ricette standardizzate da un database PostgreSQL. Oggi parleremo di come rendere più efficiente la scrittura nel database senza utilizzare alcun «giro di vite» nella configurazione — semplicemente organizzando correttamente i flussi di dati.

#1. Секционирование
Questo articolo discute come e perché sia utile organizzare già è stato scritto, qui parleremo della pratica di applicazione di alcuni approcci nel nostro .
«Tempi che furono...»
Inizialmente, come ogni MVP, il nostro progetto è partito sotto un carico piuttosto ridotto — il monitoraggio veniva effettuato solo per una dozzina di server critici, tutte le tabelle erano relativamente compatte... Ma col passare del tempo, il numero dei nodi monitorati aumentava sempre di più, e tentando di fare di nuovo qualcosa con una delle tabelle di dimensioni 1.5TB, ci siamo resi conto che continuare così era possibile, ma davvero scomodo.
I tempi erano quasi leggendari, varie versioni di PostgreSQL 9.x erano sulla cresta dell’onda, quindi tutta la partizione doveva essere effettuata «manualmente» — tramite ereditarietà delle tabelle e trigger routing dinamico ESEGUI.
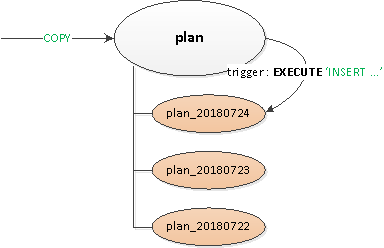
La soluzione risultante si è rivelata sufficientemente universale da poter essere traslata su tutte le tabelle:
- È stata dichiarata una tabella «genitore» vuota, in cui sono stati descritti tutti i indici e trigger necessari.
- La registrazione dal punto di vista del client veniva eseguita nella tabella «radice», e internamente tramite il trigger di routing
PRIMA INSERTla registrazione veniva «fisicamente» inserita nella sezione corretta. Se non esisteva ancora, catturavamo un'eccezione e … - … tramite veniva creata una sezione con vincolo sulla data richiesta, in modo che, durante il recupero dei dati, la lettura avvenisse solo in essa.
PG10: primo tentativo
Tuttavia, la partizione tramite ereditarietà storicamente non era molto adatta per lavorare con flussi di scrittura attivi o un gran numero di sezioni figlie. Ad esempio, si può ricordare che l'algoritmo di selezione della sezione corretta aveva complessità quadratica, il che nei casi di oltre 100 sezioni porta a prestazioni, come potete immaginare…
In PG10 questa situazione è stata notevolmente ottimizzata, implementando il supporto per . Quindi abbiamo provato subito a applicarlo subito dopo la migrazione dello storage, ma…
Come si è scoperto dopo aver esaminato il manuale, la tabella nativamente partizionata in questa versione:
- non supporta la descrizione degli indici
- non supporta i trigger
- non può essere un ‘discendente’ di nessuno
- non supporta
INSERT ... ON CONFLICT - non riesce a generare sezioni automaticamente
Dopo aver preso colpi, abbiamo capito che senza modifiche all'applicazione non avremmo potuto procedere, e abbiamo messo in pausa ulteriori ricerche per sei mesi.
PG10: una seconda possibilità
Quindi abbiamo iniziato a risolvere i problemi emersi uno alla volta:
- Poiché i trigger e
ON CONFLICTsi sono rivelati comunque necessari in alcuni casi, per gestirli abbiamo creato una tabella proxy.. - Ci siamo liberati del ‘routing’ nei trigger, ossia di
ESEGUI. - Abbiamo separato una tabella template con tutti gli indici, per far sì che non apparissero neppure nella tabella proxy.
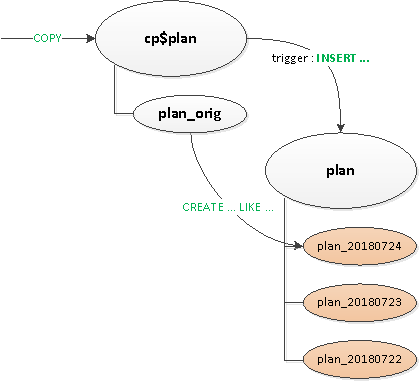
Infine, dopo tutto ciò, abbiamo nativamente partizionato la tabella principale. La creazione di una nuova sezione è rimasta a carico dell'applicazione.
Stiamo ‘scolpendo’ i dizionari
Come in qualsiasi sistema analitico, anche noi avevamo ‘fatti’ e ‘dimensioni’ (dizionari). Nel nostro caso, a questo riguardo fungevano, ad esempio, di richieste lente di tipo simile o il testo della stessa richiesta.
I «fatti» erano già stati sezionati per giorni da tempo, quindi abbiamo potuto eliminare tranquillamente le sezioni obsolete, e non ci davano fastidio (i log, dopotutto!). Ma con i dizionari siamo incappati in un problema…
Non si può dire che fossero moltissimi, ma circa con 100TB di «fatti», abbiamo avuto un dizionario di 2.5TB. Da una tale tabella non si può facilmente far nulla, non si può comprimere in un tempo adeguato, e scrivere in essa stava diventando sempre più lento.
Sembra un dizionario… in cui ogni voce dovrebbe essere rappresentata esattamente una volta… ed è corretto, ma!.. Nessuno ci impedisce di avere un dizionario separato per ogni giorno! Sì, questo porta a una certa ridondanza, ma permette:
- di scrivere/leggere più velocemente grazie a sezioni di dimensioni più ridotte
- di consumare meno memoria grazie a indici più compatti
- di memorizzare meno dati grazie alla possibilità di eliminare rapidamente i dati obsoleti
Di conseguenza, a seguito di tutto questo insieme di misure il carico sulla CPU è diminuito di circa il 30%, quello del disco - di circa il 50%:
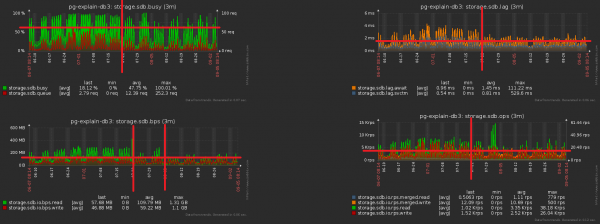
Alla fine, abbiamo continuato a scrivere nel database esattamente la stessa cosa, ma con un carico minore.
#2. Эволюция и рефакторинг БД
Quindi, ci siamo fermati a quello che abbiamo per ogni giorno c'è la propria sezione con i dati. In effetti, CHECK (dt = '2018-10-12'::date) — ecco la chiave di partizionamento e la condizione per l'inserimento del record in una specifica sezione.
Poiché tutti i report nel nostro servizio sono costruiti in base a una data specifica, anche gli indici risalenti ai «tempi non partizionati» erano tutti del tipo (Server, Data, Modello di piano), (Server, Data, Nodo del piano), (Data, Classe di errore, Server),…
Ma ora in ogni sezione vivono i propri istanziamenti di ogni indice di questo tipo... E all'interno di ogni sezione la data è una costante… Risulta che ora inseriamo in ciascun indice banalmente una costante come uno dei campi, il che aumenta sia il suo volume che il tempo di ricerca, ma non porta alcun risultato. Ci siamo lasciati dei trabocchetti, ops...

La direzione dell'ottimizzazione è ovvia: semplicemente rimuoviamo il campo con la data da tutti gli indici nelle tabelle partizionate. Con i nostri volumi, il guadagno è di circa 1TB/settimana!
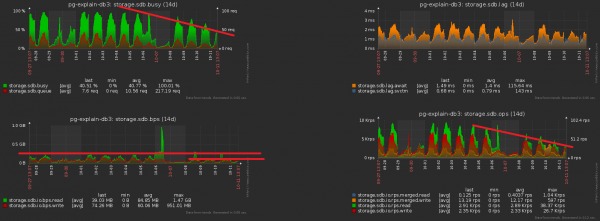
E ora notiamo che questo terabyte doveva ancora essere registrato in qualche modo. Cioè, dovevamo ancora il disco ora deve caricare meno! In questa immagine è ben visibile l'effetto ottenuto dalla pulizia a cui abbiamo dedicato una settimana:
#3. «Размазываем» пиковую нагрузку
Uno dei grandi problemi dei sistemi sovraccarichi è la sovrasincronizzazione di operazioni non necessarie. A volte 'perché non ce ne siamo accorti', altre volte 'era più semplice', ma prima o poi si deve eliminarla.
Avviciniamo l'immagine precedente e vediamo che il disco ‘sta scaricando’ un carico con un'ampiezza doppia tra le misurazioni adiacenti, cosa che chiaramente non dovrebbe esserci 'statisticamente' con un tale numero di operazioni:
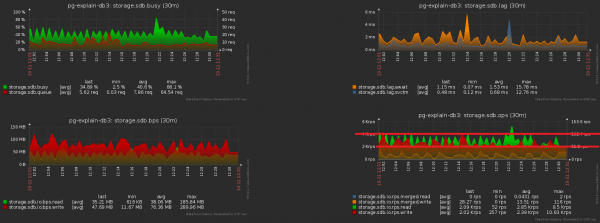
Ottenerlo è abbastanza semplice. Avevamo sotto monitoraggio quasi 1000 server, ciascuno elaborato da un flusso logico distinto, e ogni flusso invia l'informazione accumulata nel database a intervalli regolari, più o meno così:
setInterval(sendToDB, interval)Il problema risiede esattamente nel fatto che tutti i flussi partono più o meno contemporaneamente, quindi i momenti di invio coincidono quasi sempre ‘fino al punto’. Ups n.2…
Fortunatamente, questo si risolve abbastanza facilmente, aggiungendo una 'variazione' casuale nel tempo:
setInterval(sendToDB, interval * (1 + 0.1 * (Math.random() - 0.5)))#4. Кэшируем, что нужно можно
Il terzo problema tradizionale del highload — mancanza di cache dove dovrebbe potrebbe essere.
Ad esempio, abbiamo reso possibile l'analisi in base ai nodi del piano (tutti questi Seq Scan on users), ma pensare subito che siano tutti uguali — è un'idea sbagliata.
No, naturalmente, nel database non si scrive nulla due volte, questo esclude il trigger con INSERT ... ON CONFLICT DO NOTHING. Ma i dati arrivano comunque al database, e bisogna effettuare letture aggiuntive per verificare i conflitti. Oops n°3…
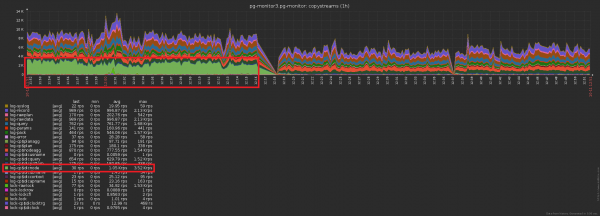
La differenza nel numero di record inviati al database prima/dopo l'attivazione della cache è evidente:
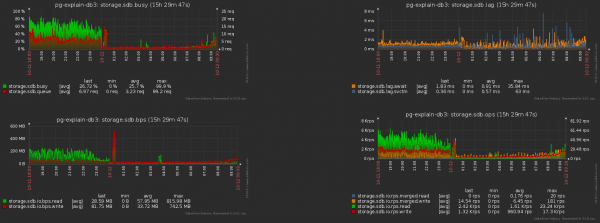
E questo è il conseguente calo del carico sullo storage:
Totale
«Terabyte-al-giorno» sembra spaventoso. Se fai tutto correttamente, si tratta semplicemente di 2^40 byte / 86400 secondi = ~12.5MB/s, che sono stati gestiti anche dai dischi IDE desktop. 🙂
E se parliamo seriamente, anche con un «sbilanciamento» di carico dieci volte superiore durante il giorno, puoi tranquillamente rimanere entro le capacità dei moderni SSD.

Fonte: habr.com
