

Ciao a tutti! Sono uno sviluppatore backend, scrivo microservizi in Java + Spring. Lavoro in uno dei team di sviluppo di prodotti interni presso Tinkoff.

Nel nostro team, ci si pone spesso la questione dell'ottimizzazione delle query nel DBMS. Vogliamo sempre un po' più velocità, ma non sempre si può fare a meno di indici ben progettati — a volte è necessario cercare soluzioni alternative. Durante uno di questi vagabondaggi in rete alla ricerca di ottimizzazioni sensate per il lavoro con i database, ho trovato , autore del libro SQL Performance Explained. Questo è il raro tipo di blog in cui si possono leggere tutti gli articoli consecutivamente.
Voglio tradurre per voi un piccolo articolo di Markus. Può essere considerato in qualche modo un manifesto, che cerca di attirare l'attenzione su un problema vecchio ma ancora attuale: le prestazioni dell'operazione offset secondo lo standard SQL.
In alcuni punti aggiungerò spiegazioni e commenti all'autore. Tutti questi punti saranno contrassegnati come «nota» per maggiore chiarezza.
Una breve introduzione
Penso che molti sappiano quanto sia problematico e lento lavorare con i selettori paginati tramite offset. Ma sapete che può essere facilmente sostituito con una costruzione molto più performante?
Quindi, la parola chiave offset indica al database di saltare le prime n righe nella query. Tuttavia, il database deve comunque leggere queste prime n righe dal disco, seguendo l'ordine specificato (nota: applicare l'ordinamento se indicato), e solo dopo sarà possibile restituire le righe a partire dalla n+1 e oltre. La cosa interessante è che il problema non risiede in una specifica implementazione nel DBMS, ma nella definizione originale secondo lo standard:
…le righe vengono prima ordinate secondo la e poi limitate scartando il numero di righe specificato nella dall'inizio…
-SQL:2016, Parte 2, 4.15.3 Tabelle derivate (nota: attualmente lo standard più utilizzato)
Il punto chiave qui è che l'offset accetta un unico parametro — il numero di righe da saltare, e basta. Seguendo tale definizione, il DBMS può solo recuperare tutte le righe, per poi scartare quelle non necessarie. È evidente che tale definizione dell'offset costringe a fare lavoro superfluo. E non importa se sia SQL o NoSQL.
Un po' di dolore in più
I problemi con l'offset non si fermano qui, ecco perché. Se un'altra operazione inserisce un nuovo record tra la lettura di due pagine di dati dal disco, cosa succede in questo caso?
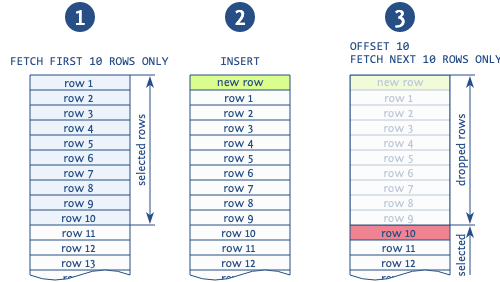
Quando si utilizza l'offset per saltare record da pagine precedenti, nella situazione in cui si aggiunge un nuovo record tra le operazioni di lettura di pagine diverse, è probabile che si ottengano duplicati (nota: ciò può accadere quando leggiamo pagina per pagina usando la costruzione order by, quindi un nuovo record potrebbe finire nel mezzo dei risultati).
L'immagine illustra chiaramente tale situazione. Il database legge i primi 10 record, dopo di che viene inserito un nuovo record, che sposta tutti i record letti di 1. Poi il database prende la nuova pagina dei successivi 10 record e inizia non dall'11°, come dovrebbe, ma dal 10°, duplicando questo record. Ci sono anche altre anomalie legate all'uso di questa espressione, ma questa è la più comune.
Come già accennato, non si tratta di problemi legati a un particolare DBMS o alle sue implementazioni. Il problema risiede nella definizione della paginazione secondo lo standard SQL. Indichiamo al DBMS quale pagina recuperare o quante righe saltare. Il database non è in grado di ottimizzare una simile richiesta, poiché dispone di informazioni troppo esigue.
Vale la pena anche chiarire che questo non è un problema di una singola parola chiave, ma piuttosto della semantica della query. Esistono anche altre sintassi identiche per problematicità:
- La parola chiave offset, come già detto precedentemente.
- La costruzione costituita da due parole chiave limit [offset] (anche se limit di per sé non è affatto negativa).
- Filtraggio basato sui limiti inferiori, costruito sulla numerazione delle righe (ad esempio, row_number(), rownum, ecc.).
Tutte queste espressioni indicano semplicemente quante righe devono essere saltate, senza fornire ulteriori informazioni o contesto.
Nell'articolo, la parola chiave offset viene utilizzata come un generalizzazione di tutte queste varianti.
Una vita senza OFFSET
E adesso immaginiamo come sarebbe il nostro mondo senza tutti questi problemi. In effetti, la vita senza offset non è così complicata: con una selezione si possono scegliere solo quelle righe che non abbiamo ancora visto (cioè quelle che non erano sulla pagina precedente), utilizzando una condizione in where.
In questo caso, partiamo dal fatto che le selezioni vengono eseguite su un insieme ordinato (il vecchio fidato order by). Poiché abbiamo un insieme ordinato, possiamo utilizzare un filtro abbastanza semplice per estrarre solo i dati che si trovano dopo l'ultima registrazione della pagina precedente:
SELECT ...
FROM ...
WHERE ...
AND id < ?last_seen_id
ORDER BY id DESC
FETCH FIRST 10 ROWS ONLYEcco tutto il principio di questo approccio. Certo, ordinando su più colonne diventa più interessante, ma l'idea rimane la stessa. È importante notare che questa costruzione è applicabile a molte -soluzioni.
Questo approccio è conosciuto come metodo seek o paginazione keyset. Risolve il problema dei risultati fluttuanti (nota: la situazione con le registrazioni tra le letture delle pagine, descritta in precedenza) e, naturalmente, ciò che tutti noi amiamo, funziona più velocemente e con maggiore stabilità rispetto all'offset classico. La stabilità consiste nel fatto che il tempo di elaborazione della richiesta non aumenta proporzionalmente al numero della tabella richiesta (nota: se desideri saperne di più sui vari approcci alla paginazione, puoi . Qui puoi trovare anche benchmark comparativi sui diversi metodi).
Una delle diapositive , che la paginazione per chiavi, ovviamente, non è onnipotente — ha le sue limitazioni. La più importante è che non ha la possibilità di leggere pagine casuali (nota: non in sequenza). Tuttavia, nell'era dello scrolling infinito (nota: sul front-end) questo non è un grosso problema. Indicare il numero di pagina per il clic è comunque una soluzione inadeguata nella progettazione dell'interfaccia utente (nota: opinione dell'autore dell'articolo).
E per quanto riguarda gli strumenti?
La paginazione basata su chiavi spesso non è adatta a causa della mancanza di supporto strumentale per questo metodo. La maggior parte degli strumenti di sviluppo, inclusi vari framework, non permette di scegliere il modo in cui la paginazione verrà eseguita.
La situazione è aggravata dal fatto che il metodo descritto richiede un supporto end-to-end nelle tecnologie utilizzate, che va dal DBMS all'esecuzione delle richieste AJAX nel browser durante lo scrolling infinito. Invece di indicare solo il numero di pagina, ora sarà necessario specificare un insieme di chiavi per tutte le pagine contemporaneamente.
Tuttavia, il numero di framework che supportano la paginazione basata su chiavi sta gradualmente aumentando. Ecco cosa abbiamo attualmente:
- per Java;
- per Ruby;
- e per Django;
- per Python;
- — critteria API per le realizzazioni JPA;
- per Perl;
- , мапер для Node.js .
(Nota: alcuni link sono stati rimossi poiché al momento della traduzione alcune librerie non erano state aggiornate dal 2017-2018. Se siete interessati, potete dare un'occhiata alla fonte originale.)
In questo momento, ho bisogno del vostro aiuto. Se state sviluppando o mantenendo un framework che utilizza la paginazione in qualche modo, vi chiedo, vi esorto, vi supplico di implementare un supporto nativo per la paginazione sulle chiavi. Se avete domande o se avete bisogno di assistenza, sarò felice di aiutarvi (, , ) (Nota: dalla mia esperienza di dialogo con Markus, posso dire che è veramente entusiasta di diffondere questo argomento).
Se state utilizzando soluzioni preconfezionate che ritenete meritino un supporto per la paginazione sulle chiavi, create una richiesta o addirittura proponete una soluzione pronta, se possibile. Potete anche includere in un link questo articolo.
Conclusione
La ragione per cui un approccio così semplice e utile come la paginazione sulle chiavi è poco diffuso non è che sia complesso da realizzare tecnicamente o richieda grandi sforzi. La principale ragione è che molti sono abituati a vedere e lavorare con l'offset — questo approccio è dettato dallo standard stesso.
Di conseguenza, pochi riflettono su un cambio di approccio alla paginazione, e per questo l'assistenza strumentale da parte di framework e librerie si sviluppa lentamente. Pertanto, se condividi l'idea e l'obiettivo di una paginazione senza offset, — aiutaci a diffonderla!
Fonte:
Autore: Markus Winand
Fonte: habr.com
