

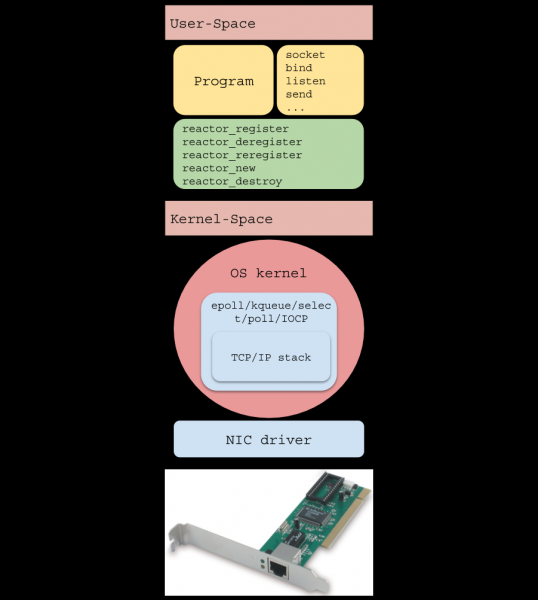
Introduzione
(filetto singolo ) è un modello per scrivere software ad alto carico, utilizzato in molte soluzioni popolari:
- ...
In questo articolo esamineremo i dettagli di un reattore I/O e come funziona, scriveremo un'implementazione in meno di 200 righe di codice e faremo in modo che un semplice server HTTP elabori oltre 40 milioni di richieste/min.
prefazione
- L'articolo è stato scritto per aiutare a comprendere il funzionamento del reattore I/O e quindi a comprendere i rischi derivanti dal suo utilizzo.
- Per comprendere l'articolo è necessaria la conoscenza delle nozioni di base. e una certa esperienza nello sviluppo di applicazioni di rete.
- Tutto il codice è scritto in linguaggio C rigorosamente secondo (attenzione: PDF lungo) per Linux ed è disponibile su .
Perché farlo?
Con la crescente popolarità di Internet, i server web hanno cominciato a dover gestire un gran numero di connessioni simultaneamente, e quindi sono stati tentati due approcci: bloccando l'I/O su un gran numero di thread del sistema operativo e non bloccando l'I/O in combinazione con un sistema di notifica degli eventi, detto anche “selettore di sistema” (///eccetera).
Il primo approccio prevedeva la creazione di un nuovo thread del sistema operativo per ogni connessione in entrata. Il suo svantaggio è la scarsa scalabilità: il sistema operativo dovrà implementarne molti и . Sono operazioni costose e possono portare alla mancanza di RAM libera con un numero impressionante di connessioni.
La versione modificata viene evidenziata (pool di thread), impedendo così al sistema di interrompere l'esecuzione, ma allo stesso tempo introducendo un nuovo problema: se un pool di thread è attualmente bloccato da operazioni di lettura lunghe, allora altri socket che sono già in grado di ricevere dati non saranno in grado di farlo fare così.
Il secondo approccio utilizza (selettore di sistema) fornito dal sistema operativo. Questo articolo discute il tipo più comune di selettore di sistema, basato su avvisi (eventi, notifiche) sulla disponibilità per le operazioni di I/O, piuttosto che su . Un esempio semplificato del suo utilizzo può essere rappresentato dal seguente schema a blocchi:
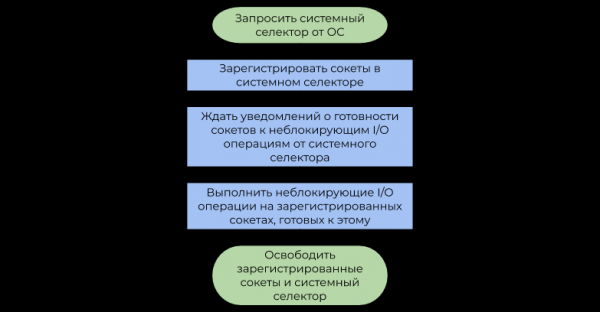
La differenza tra questi approcci è la seguente:
- Blocco delle operazioni di I/O sospendere flusso degli utenti fino afino a quando il sistema operativo non è corretto in arrivo al flusso di byte (, ricezione dati) oppure non ci sarà abbastanza spazio disponibile nei buffer di scrittura interni per il successivo invio tramite (invio dati).
- Selettore di sistema dopo un po ' notifica al programma che il sistema operativo già pacchetti IP deframmentati (TCP, ricezione dati) o spazio sufficiente nei buffer di scrittura interni già disponibile (invio dati).
Per riassumere, riservare un thread del sistema operativo per ciascun I/O è uno spreco di potenza di calcolo, perché in realtà i thread non svolgono un lavoro utile (da qui deriva il termine ). Il selettore di sistema risolve questo problema, consentendo al programma utente di utilizzare le risorse della CPU in modo molto più economico.
Modello di reattore I/O
Il reattore I/O funge da strato tra il selettore di sistema e il codice utente. Il principio di funzionamento è descritto dal seguente schema a blocchi:
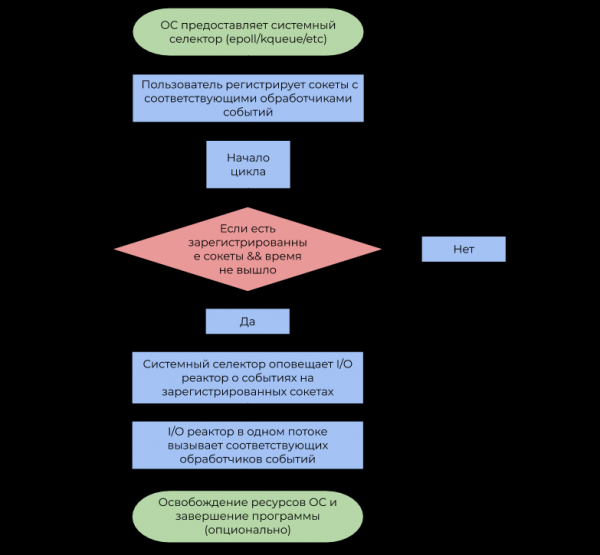
- Permettimi di ricordarti che un evento è una notifica che un determinato socket è in grado di eseguire un'operazione I/O non bloccante.
- Un gestore eventi è una funzione chiamata dal reattore I/O quando viene ricevuto un evento, che quindi esegue un'operazione I/O non bloccante.
È importante notare che il reattore I/O è per definizione a thread singolo, ma non c'è nulla che impedisca l'utilizzo del concetto in un ambiente multi-thread con un rapporto di 1 thread: 1 reattore, riciclando così tutti i core della CPU.
implementazione
Inseriremo l'interfaccia pubblica in un file e implementazione - in . reactor.h sarà composto dai seguenti annunci:
Mostra le dichiarazioni in reactor.h
typedef struct reactor Reactor;
/*
* Указатель на функцию, которая будет вызываться I/O реактором при поступлении
* события от системного селектора.
*/
typedef void (*Callback)(void *arg, int fd, uint32_t events);
/*
* Возвращает `NULL` в случае ошибки, не-`NULL` указатель на `Reactor` в
* противном случае.
*/
Reactor *reactor_new(void);
/*
* Освобождает системный селектор, все зарегистрированные сокеты в данный момент
* времени и сам I/O реактор.
*
* Следующие функции возвращают -1 в случае ошибки, 0 в случае успеха.
*/
int reactor_destroy(Reactor *reactor);
int reactor_register(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg);
int reactor_deregister(const Reactor *reactor, int fd);
int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg);
/*
* Запускает цикл событий с тайм-аутом `timeout`.
*
* Эта функция передаст управление вызывающему коду если отведённое время вышло
* или/и при отсутствии зарегистрированных сокетов.
*/
int reactor_run(const Reactor *reactor, time_t timeout);La struttura del reattore I/O è composta da selettore и , che mappa ciascun socket su CallbackData (struttura di un gestore eventi e relativo argomento utente).
Mostra Reactor e CallbackData
struct reactor {
int epoll_fd;
GHashTable *table; // (int, CallbackData)
};
typedef struct {
Callback callback;
void *arg;
} CallbackData;Tieni presente che abbiamo abilitato la possibilità di gestire secondo l'indice. IN reactor.h dichiariamo la struttura reactor, mentre in reactor.c lo definiamo, impedendo così all'utente di modificare esplicitamente i suoi campi. Questo è uno dei modelli , che si adatta succintamente alla semantica C.
funzioni reactor_register, reactor_deregister и reactor_reregister aggiornare l'elenco dei socket di interesse e dei corrispondenti gestori di eventi nel selettore di sistema e nella tabella hash.
Mostra le funzioni di registrazione
#define REACTOR_CTL(reactor, op, fd, interest)
if (epoll_ctl(reactor->epoll_fd, op, fd,
&(struct epoll_event){.events = interest,
.data = {.fd = fd}}) == -1) {
perror("epoll_ctl");
return -1;
}
int reactor_register(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg) {
REACTOR_CTL(reactor, EPOLL_CTL_ADD, fd, interest)
g_hash_table_insert(reactor->table, int_in_heap(fd),
callback_data_new(callback, callback_arg));
return 0;
}
int reactor_deregister(const Reactor *reactor, int fd) {
REACTOR_CTL(reactor, EPOLL_CTL_DEL, fd, 0)
g_hash_table_remove(reactor->table, &fd);
return 0;
}
int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg) {
REACTOR_CTL(reactor, EPOLL_CTL_MOD, fd, interest)
g_hash_table_insert(reactor->table, int_in_heap(fd),
callback_data_new(callback, callback_arg));
return 0;
}Dopo che il reattore I/O ha intercettato l'evento con il descrittore fd, chiama il gestore eventi corrispondente, al quale passa fd, eventi generati e un puntatore utente a void.
Mostra la funzione reactor_run()
int reactor_run(const Reactor *reactor, time_t timeout) {
int result;
struct epoll_event *events;
if ((events = calloc(MAX_EVENTS, sizeof(*events))) == NULL)
abort();
time_t start = time(NULL);
while (true) {
time_t passed = time(NULL) - start;
int nfds =
epoll_wait(reactor->epoll_fd, events, MAX_EVENTS, timeout - passed);
switch (nfds) {
// Ошибка
case -1:
perror("epoll_wait");
result = -1;
goto cleanup;
// Время вышло
case 0:
result = 0;
goto cleanup;
// Успешная операция
default:
// Вызвать обработчиков событий
for (int i = 0; i < nfds; i++) {
int fd = events[i].data.fd;
CallbackData *callback =
g_hash_table_lookup(reactor->table, &fd);
callback->callback(callback->arg, fd, events[i].events);
}
}
}
cleanup:
free(events);
return result;
}Riassumendo, la catena di chiamate di funzione nel codice utente assumerà la seguente forma:
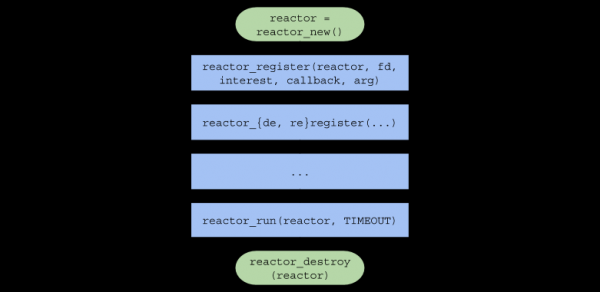
Server a thread singolo
Per testare il reattore I/O sotto carico elevato, scriveremo un semplice server web HTTP che risponde a qualsiasi richiesta con un'immagine.
Un rapido riferimento al protocollo HTTP
- questo è il protocollo , utilizzato principalmente per l'interazione server-browser.
HTTP può essere facilmente utilizzato protocollo , inviando e ricevendo messaggi in un formato specificato .
Richiedi formato
<КОМАНДА> <URI> <ВЕРСИЯ HTTP>CRLF
<ЗАГОЛОВОК 1>CRLF
<ЗАГОЛОВОК 2>CRLF
<ЗАГОЛОВОК N>CRLF CRLF
<ДАННЫЕ>CRLFè una sequenza di due caratteri:rиn, separando la prima riga della richiesta, intestazioni e dati.<КОМАНДА>- uno diCONNECT,DELETE,GET,HEAD,OPTIONS,PATCH,POST,PUT,TRACE. Il browser invierà un comando al nostro serverGET, che significa "Inviami il contenuto del file".<URI>- . Ad esempio, se URI =/index.html, quindi il client richiede la pagina principale del sito.<ВЕРСИЯ HTTP>— versione del protocollo HTTP nel formatoHTTP/X.Y. La versione più comunemente usata oggi èHTTP/1.1.<ЗАГОЛОВОК N>è una coppia chiave-valore nel formato<КЛЮЧ>: <ЗНАЧЕНИЕ>, inviato al server per ulteriori analisi.<ДАННЫЕ>— dati richiesti dal server per eseguire l'operazione. Spesso è semplice o qualsiasi altro formato.
Formato della risposta
<ВЕРСИЯ HTTP> <КОД СТАТУСА> <ОПИСАНИЕ СТАТУСА>CRLF
<ЗАГОЛОВОК 1>CRLF
<ЗАГОЛОВОК 2>CRLF
<ЗАГОЛОВОК N>CRLF CRLF
<ДАННЫЕ><КОД СТАТУСА>è un numero che rappresenta il risultato dell'operazione. Il nostro server restituirà sempre lo stato 200 (operazione riuscita).<ОПИСАНИЕ СТАТУСА>— rappresentazione in stringa del codice di stato. Per il codice di stato 200 questo èOK.<ЗАГОЛОВОК N>— intestazione dello stesso formato della richiesta. Restituiremo i titoliContent-Length(dimensione del file) eContent-Type: text/html(tipo di dati restituiti).<ДАННЫЕ>— dati richiesti dall'utente. Nel nostro caso, questo è il percorso dell'immagine .
file (server a thread singolo) include file , che contiene i seguenti prototipi di funzioni:
Mostra prototipi di funzioni in comune.h
/*
* Обработчик событий, который вызовется после того, как сокет будет
* готов принять новое соединение.
*/
static void on_accept(void *arg, int fd, uint32_t events);
/*
* Обработчик событий, который вызовется после того, как сокет будет
* готов отправить HTTP ответ.
*/
static void on_send(void *arg, int fd, uint32_t events);
/*
* Обработчик событий, который вызовется после того, как сокет будет
* готов принять часть HTTP запроса.
*/
static void on_recv(void *arg, int fd, uint32_t events);
/*
* Переводит входящее соединение в неблокирующий режим.
*/
static void set_nonblocking(int fd);
/*
* Печатает переданные аргументы в stderr и выходит из процесса с
* кодом `EXIT_FAILURE`.
*/
static noreturn void fail(const char *format, ...);
/*
* Возвращает файловый дескриптор сокета, способного принимать новые
* TCP соединения.
*/
static int new_server(bool reuse_port);Viene inoltre descritta la macro funzionale SAFE_CALL() e la funzione è definita fail(). La macro confronta il valore dell'espressione con l'errore e, se la condizione è vera, chiama la funzione fail():
#define SAFE_CALL(call, error)
do {
if ((call) == error) {
fail("%s", #call);
}
} while (false)Funzione fail() stampa gli argomenti passati al terminale (come ) e termina il programma con il codice EXIT_FAILURE:
static noreturn void fail(const char *format, ...) {
va_list args;
va_start(args, format);
vfprintf(stderr, format, args);
va_end(args);
fprintf(stderr, ": %sn", strerror(errno));
exit(EXIT_FAILURE);
}Funzione new_server() restituisce il descrittore di file del socket "server" creato dalle chiamate di sistema , и e in grado di accettare connessioni in entrata in modalità non bloccante.
Mostra la funzione new_server()
static int new_server(bool reuse_port) {
int fd;
SAFE_CALL((fd = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, IPPROTO_TCP)),
-1);
if (reuse_port) {
SAFE_CALL(
setsockopt(fd, SOL_SOCKET, SO_REUSEPORT, &(int){1}, sizeof(int)),
-1);
}
struct sockaddr_in addr = {.sin_family = AF_INET,
.sin_port = htons(SERVER_PORT),
.sin_addr = {.s_addr = inet_addr(SERVER_IPV4)},
.sin_zero = {0}};
SAFE_CALL(bind(fd, (struct sockaddr *)&addr, sizeof(addr)), -1);
SAFE_CALL(listen(fd, SERVER_BACKLOG), -1);
return fd;
}- Tieni presente che il socket viene inizialmente creato in modalità non bloccante utilizzando il flag
SOCK_NONBLOCKin modo che nella funzioneon_accept()(continua a leggere) chiamata di sistemaaccept()non ha interrotto l'esecuzione del thread. - se
reuse_portè uguale atrue, questa funzione configurerà il socket con l'opzione attraverso per utilizzare la stessa porta in un ambiente multi-thread (vedere la sezione “Server multi-thread”).
Gestore di eventi on_accept() chiamato dopo che il sistema operativo ha generato un evento EPOLLIN, in questo caso significa che la nuova connessione può essere accettata. on_accept() accetta una nuova connessione, la passa alla modalità non bloccante e si registra con un gestore eventi on_recv() in un reattore I/O.
Mostra la funzione on_accept()
static void on_accept(void *arg, int fd, uint32_t events) {
int incoming_conn;
SAFE_CALL((incoming_conn = accept(fd, NULL, NULL)), -1);
set_nonblocking(incoming_conn);
SAFE_CALL(reactor_register(reactor, incoming_conn, EPOLLIN, on_recv,
request_buffer_new()),
-1);
}Gestore di eventi on_recv() chiamato dopo che il sistema operativo ha generato un evento EPOLLIN, in questo caso significa che la connessione è stata registrata on_accept(), pronto a ricevere dati.
on_recv() legge i dati dalla connessione fino alla ricezione completa della richiesta HTTP, quindi registra un gestore on_send() per inviare una risposta HTTP. Se il client interrompe la connessione, il socket viene annullato e chiuso utilizzando .
Mostra funzione on_recv()
static void on_recv(void *arg, int fd, uint32_t events) {
RequestBuffer *buffer = arg;
// Принимаем входные данные до тех пор, что recv возвратит 0 или ошибку
ssize_t nread;
while ((nread = recv(fd, buffer->data + buffer->size,
REQUEST_BUFFER_CAPACITY - buffer->size, 0)) > 0)
buffer->size += nread;
// Клиент оборвал соединение
if (nread == 0) {
SAFE_CALL(reactor_deregister(reactor, fd), -1);
SAFE_CALL(close(fd), -1);
request_buffer_destroy(buffer);
return;
}
// read вернул ошибку, отличную от ошибки, при которой вызов заблокирует
// поток
if (errno != EAGAIN && errno != EWOULDBLOCK) {
request_buffer_destroy(buffer);
fail("read");
}
// Получен полный HTTP запрос от клиента. Теперь регистрируем обработчика
// событий для отправки данных
if (request_buffer_is_complete(buffer)) {
request_buffer_clear(buffer);
SAFE_CALL(reactor_reregister(reactor, fd, EPOLLOUT, on_send, buffer),
-1);
}
}Gestore di eventi on_send() chiamato dopo che il sistema operativo ha generato un evento EPOLLOUT, il che significa che la connessione è stata registrata on_recv(), pronto per inviare dati. Questa funzione invia una risposta HTTP contenente HTML con un'immagine al client e quindi ripristina il gestore eventi on_recv().
Mostra la funzione on_send()
static void on_send(void *arg, int fd, uint32_t events) {
const char *content = "<img "
"src="https://habrastorage.org/webt/oh/wl/23/"
"ohwl23va3b-dioerobq_mbx4xaw.jpeg">";
char response[1024];
sprintf(response,
"HTTP/1.1 200 OK" CRLF "Content-Length: %zd" CRLF "Content-Type: "
"text/html" DOUBLE_CRLF "%s",
strlen(content), content);
SAFE_CALL(send(fd, response, strlen(response), 0), -1);
SAFE_CALL(reactor_reregister(reactor, fd, EPOLLIN, on_recv, arg), -1);
}E infine, nel file http_server.c, in funzione main() creiamo un reattore I/O utilizzando reactor_new(), crea un socket del server e registralo, avvia il reattore utilizzando reactor_run() per esattamente un minuto, quindi rilasciamo le risorse e usciamo dal programma.
Mostra http_server.c
#include "reactor.h"
static Reactor *reactor;
#include "common.h"
int main(void) {
SAFE_CALL((reactor = reactor_new()), NULL);
SAFE_CALL(
reactor_register(reactor, new_server(false), EPOLLIN, on_accept, NULL),
-1);
SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1);
SAFE_CALL(reactor_destroy(reactor), -1);
}Controlliamo che tutto funzioni come previsto. Compilazione (chmod a+x compile.sh && ./compile.sh nella root del progetto) e avviare il server autoscritto, open nel browser e vedere cosa ci aspettavamo:
Valutazione della prestazione
Mostra le specifiche della mia auto
$ screenfetch
MMMMMMMMMMMMMMMMMMMMMMMMMmds+. OS: Mint 19.1 tessa
MMm----::-://////////////oymNMd+` Kernel: x86_64 Linux 4.15.0-20-generic
MMd /++ -sNMd: Uptime: 2h 34m
MMNso/` dMM `.::-. .-::.` .hMN: Packages: 2217
ddddMMh dMM :hNMNMNhNMNMNh: `NMm Shell: bash 4.4.20
NMm dMM .NMN/-+MMM+-/NMN` dMM Resolution: 1920x1080
NMm dMM -MMm `MMM dMM. dMM DE: Cinnamon 4.0.10
NMm dMM -MMm `MMM dMM. dMM WM: Muffin
NMm dMM .mmd `mmm yMM. dMM WM Theme: Mint-Y-Dark (Mint-Y)
NMm dMM` ..` ... ydm. dMM GTK Theme: Mint-Y [GTK2/3]
hMM- +MMd/-------...-:sdds dMM Icon Theme: Mint-Y
-NMm- :hNMNNNmdddddddddy/` dMM Font: Noto Sans 9
-dMNs-``-::::-------.`` dMM CPU: Intel Core i7-6700 @ 8x 4GHz [52.0°C]
`/dMNmy+/:-------------:/yMMM GPU: NV136
./ydNMMMMMMMMMMMMMMMMMMMMM RAM: 2544MiB / 7926MiB
.MMMMMMMMMMMMMMMMMMMMisuriamo le prestazioni di un server a thread singolo. Apriamo due terminali: in uno correremo ./http_server, in un modo diverso - . Dopo un minuto, nel secondo terminale verranno visualizzate le seguenti statistiche:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive"
Running 1m test @ http://127.0.0.1:18470
8 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 493.52us 76.70us 17.31ms 89.57%
Req/Sec 24.37k 1.81k 29.34k 68.13%
11657769 requests in 1.00m, 1.60GB read
Requests/sec: 193974.70
Transfer/sec: 27.19MBIl nostro server a thread singolo è stato in grado di elaborare oltre 11 milioni di richieste al minuto provenienti da 100 connessioni. Non è un brutto risultato, ma può essere migliorato?
Server multithread
Come accennato in precedenza, il reattore I/O può essere creato in thread separati, utilizzando quindi tutti i core della CPU. Mettiamo in pratica questo approccio:
Mostra http_server_multithreaded.c
#include "reactor.h"
static Reactor *reactor;
#pragma omp threadprivate(reactor)
#include "common.h"
int main(void) {
#pragma omp parallel
{
SAFE_CALL((reactor = reactor_new()), NULL);
SAFE_CALL(reactor_register(reactor, new_server(true), EPOLLIN,
on_accept, NULL),
-1);
SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1);
SAFE_CALL(reactor_destroy(reactor), -1);
}
}Ora ogni thread reattore:
static Reactor *reactor;
#pragma omp threadprivate(reactor)Si prega di notare che l'argomento della funzione new_server() atti true. Ciò significa che assegniamo l'opzione al socket del server per usarlo in un ambiente multi-thread. Puoi leggere maggiori dettagli .
Seconda corsa
Ora misuriamo le prestazioni di un server multi-thread:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive"
Running 1m test @ http://127.0.0.1:18470
8 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.14ms 2.53ms 40.73ms 89.98%
Req/Sec 79.98k 18.07k 154.64k 78.65%
38208400 requests in 1.00m, 5.23GB read
Requests/sec: 635876.41
Transfer/sec: 89.14MBIl numero di richieste elaborate in 1 minuto è aumentato di ~3.28 volte! Ma mancavano solo circa XNUMX milioni al numero tondo, quindi proviamo a risolvere il problema.
Per prima cosa diamo un'occhiata alle statistiche generate :
$ sudo perf stat -B -e task-clock,context-switches,cpu-migrations,page-faults,cycles,instructions,branches,branch-misses,cache-misses ./http_server_multithreaded
Performance counter stats for './http_server_multithreaded':
242446,314933 task-clock (msec) # 4,000 CPUs utilized
1 813 074 context-switches # 0,007 M/sec
4 689 cpu-migrations # 0,019 K/sec
254 page-faults # 0,001 K/sec
895 324 830 170 cycles # 3,693 GHz
621 378 066 808 instructions # 0,69 insn per cycle
119 926 709 370 branches # 494,653 M/sec
3 227 095 669 branch-misses # 2,69% of all branches
808 664 cache-misses
60,604330670 seconds time elapsed, compilazione con -march=native, , un aumento del numero di risultati , aumento MAX_EVENTS e usare EPOLLET non ha dato un aumento significativo delle prestazioni. Ma cosa succede se aumenti il numero di connessioni simultanee?
Statistiche per 352 connessioni simultanee:
$ wrk -c352 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive"
Running 1m test @ http://127.0.0.1:18470
8 threads and 352 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 2.12ms 3.79ms 68.23ms 87.49%
Req/Sec 83.78k 12.69k 169.81k 83.59%
40006142 requests in 1.00m, 5.48GB read
Requests/sec: 665789.26
Transfer/sec: 93.34MBÈ stato ottenuto il risultato desiderato e con esso un interessante grafico che mostra la dipendenza del numero di richieste elaborate in 1 minuto dal numero di connessioni:
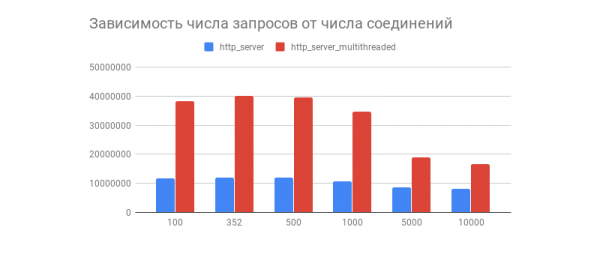
Notiamo che dopo un paio di centinaia di connessioni, il numero di richieste elaborate per entrambi i server cala drasticamente (questo è più evidente nella versione multi-thread). È forse correlato all'implementazione? TCP/IP pila LinuxSentitevi liberi di condividere le vostre opinioni su questo comportamento del grafico e sulle ottimizzazioni per le versioni multithread e single-thread nei commenti.
Come nei commenti, questo test delle prestazioni non mostra il comportamento del reattore I/O sotto carichi reali, perché quasi sempre il server interagisce con il database, genera log, utilizza la crittografia con ecc., per cui il carico diventa non uniforme (dinamico). I test insieme ai componenti di terze parti verranno eseguiti nell'articolo sul proactor I/O.
Svantaggi del reattore I/O
È necessario comprendere che il reattore I/O non è privo di inconvenienti, vale a dire:
- Usare un reattore I/O in un ambiente multi-thread è un po' più difficile, perché dovrai gestire manualmente i flussi.
- La pratica dimostra che nella maggior parte dei casi il carico non è uniforme, il che può portare alla registrazione di un thread mentre un altro è impegnato nel lavoro.
- Se un gestore eventi blocca un thread, anche il selettore di sistema stesso si bloccherà, il che può portare a bug difficili da trovare.
Risolve questi problemi , che spesso ha uno scheduler che distribuisce uniformemente il carico su un pool di thread e ha anche un'API più conveniente. Ne parleremo più avanti, in un altro mio articolo.
conclusione
Qui è giunto al termine il nostro viaggio dalla teoria direttamente allo scarico del profiler.
Non dovresti soffermarti su questo, perché esistono molti altri approcci altrettanto interessanti per scrivere software di rete con diversi livelli di comodità e velocità. Interessanti, a mio avviso, i link sono riportati di seguito.
Fino a quando ci incontriamo di nuovo!
Progetti interessanti
- se stessi
Cos'altro dovrei leggere?
Fonte: habr.com
