


L'effetto di bloat delle tabelle e degli indici è ampiamente conosciuto e presente non solo in Postgres. Ci sono modi per affrontarlo “out of the box” come VACUUM FULL o CLUSTER, ma essi bloccano le tabelle durante l'operazione, e quindi non sempre possono essere utilizzati.
In questo articolo troverete un po' di teoria su come si genera il bloat, come può essere gestito, sui vincoli differiti e sui problemi che questi portano nell'uso dell'estensione pg_repack.
Questo articolo è basato al PgConf.Russia 2020.
Perché si genera il bloat
Alla base di Postgres c'è un modello multi-versione (). La sua essenza è che ogni riga in una tabella può avere più versioni, mentre le transazioni vedono al massimo una di queste versioni, ma non necessariamente la stessa. Questo permette a più transazioni di operare simultaneamente e di influenzarsi a vicenda in modo quasi nullo.
È evidente che tutte queste versioni devono essere memorizzate. Postgres gestisce la memoria pagina per pagina, e la pagina è il volume minimo di dati che può essere letto dal disco o scritto. Vediamo un piccolo esempio per capire come ciò avviene.
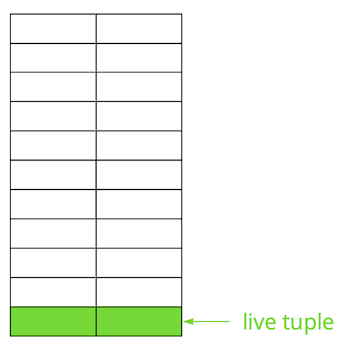
Immaginiamo di avere una tabella a cui abbiamo aggiunto diverse righe. Nella prima pagina del file, dove è memorizzata la tabella, sono apparsi nuovi dati. Queste sono versioni attive delle righe, accessibili ad altre transazioni dopo il commit (per semplicità, supponiamo che il livello di isolamento sia Read Committed).
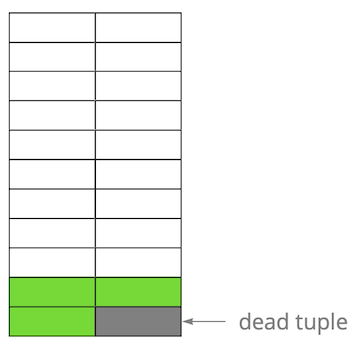
Dopodiché, abbiamo aggiornato una delle righe, contrassegnando così la vecchia versione come obsoleta.
Passo dopo passo, aggiornando ed eliminando versioni delle righe, abbiamo ottenuto una pagina in cui circa metà dei dati sono “spazzatura”. Questi dati non sono visibili a nessuna transazione.
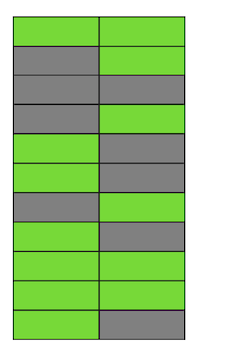
In Postgres esiste un meccanismo , che rimuove le versioni obsolete e libera spazio per i nuovi dati. Ma se non è configurato in modo abbastanza aggressivo o è occupato a lavorare su altre tabelle, i “dati spazzatura” rimangono, costringendoci a utilizzare pagine aggiuntive per i nuovi dati.
Così, nel nostro esempio, a un certo punto la tabella consisterà in quattro pagine, ma con soli la metà di dati attivi. Di conseguenza, quando accediamo alla tabella, leggeremo molti più dati di quanto necessario.
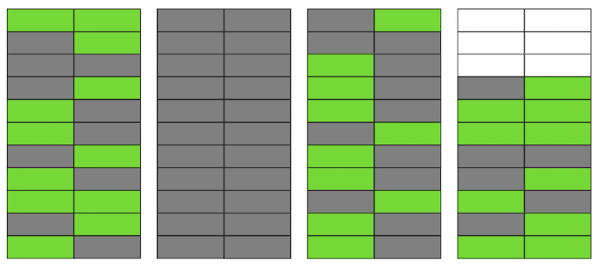
Anche se ora VACUUM rimuovesse tutte le versioni obsolete delle righe, la situazione non migliorerebbe drasticamente. Avremo spazio libero nelle pagine o persino intere pagine per nuove righe, ma continueremo a leggere più dati di quanto necessario.
A proposito, se una pagina completamente vuota (la seconda nel nostro esempio) si trovasse alla fine del file, VACUUM potrebbe tagliarla. Ma ora si trova in mezzo, quindi non possiamo farci nulla.
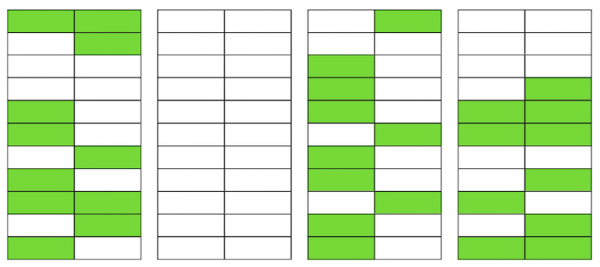
Quando il numero di pagine vuote o molto sparse diventa considerevole, ciò che viene definito bloat, questo inizia a influenzare le prestazioni.
Tutta la meccanica sopra descritta riguarda la genesi del bloat nelle tabelle. Negli indici accade più o meno allo stesso modo.
Ho del bloat?
Ci sono diversi modi per determinare se hai del bloat. L'idea principale è utilizzare le statistiche interne di Postgres, che contengono informazioni approssimative sul numero di righe nelle tabelle, sul numero di righe 'vive', ecc. Su internet puoi trovare molte varianti di script già pronti. Abbiamo preso come base da PostgreSQL Experts, che può valutare il bloat delle tabelle insieme a toast e bloat degli indici btree. Dalla nostra esperienza, la sua imprecisione è del 10-20%.
Un altro modo è utilizzare l'estensione , che permette di esaminare le pagine e ottenere sia una stima che un valore esatto del bloat. Ma nel secondo caso sarà necessario scansionare l'intera tabella.
Un valore di bloat ridotto, fino al 20%, lo consideriamo accettabile. Può essere visto come un analogo del fillfactor per e . Con il 50% o più possono sorgere problemi di prestazioni.
Modalità per gestire il bloat
In Postgres ci sono diversi modi per affrontare il bloat “out of the box”, ma non sempre sono adatti a tutti.
Configurare AUTOVACUUM in modo che non si verifichi bloat. E se vogliamo essere più precisi, affinché si mantenga a un livello accettabile per te. Potrebbe sembrare un consiglio da “capitano”, ma in realtà non è sempre facile da raggiungere. Ad esempio, se hai uno sviluppo attivo con modifiche regolari allo schema dei dati o se si verifica una qualche migrazione dei dati. Di conseguenza, il tuo profilo di carico può cambiare frequentemente e, in genere, è diverso per le varie tabelle. Quindi, devi lavorare costantemente un po' in anticipo e adattare l'AUTOVACUUM al profilo in cambiamento di ciascuna tabella. Ma è evidente che fare ciò non è semplice.
Un'altra ragione comune per cui AUTOVACUUM fatica a elaborare le tabelle è la presenza di transazioni prolungate, che impediscono di ripulire i dati, poiché sono accessibili a queste transazioni. La raccomandazione qui è altrettanto ovvia: eliminare le transazioni "pendenti" e ridurre al minimo il tempo delle transazioni attive. Tuttavia, se il carico sul vostro applicativo è una combinazione di OLAP e OLTP, potreste avere sia molteplici aggiornamenti frequenti e richieste brevi, sia operazioni lunghe, come la generazione di un report. In questa situazione, vale la pena considerare la distribuzione del carico su database diversi, il che consentirebbe un'ottimizzazione più fine di ciascuno di essi.
Un altro esempio: anche se il profilo è omogeneo, se il database è sotto un carico molto elevato, anche il più aggressivo AUTOVACUUM potrebbe non riuscire a gestire la situazione, e il bloat potrebbe verificarsi. La scalabilità (sia verticale che orizzontale) è l'unica soluzione.
Cosa fare in una situazione in cui avete configurato AUTOVACUUM, ma il bloat continua a crescere.
Team VACUUM FULL ricostruisce il contenuto delle tabelle e degli indici, mantenendo solo i dati aggiornati. Per eliminare il bloat funziona in modo ideale, ma durante la sua esecuzione acquisisce un blocco esclusivo sulla tabella (AccessExclusiveLock), che non permette di eseguire query su quella tabella, nemmeno selezioni. Se puoi permetterti di fermare il tuo servizio o una parte di esso per un periodo di tempo (da decine di minuti a diverse ore a seconda della dimensione del database e dell'hardware), allora questa opzione è la migliore. Purtroppo, non riusciamo a eseguire VACUUM FULL entro il tempo programmato per la manutenzione, quindi questa soluzione non è adatta a noi.
Team CLUSTER ricostruisce anche il contenuto delle tabelle proprio come VACUUM FULL, permettendo di specificare un indice secondo cui i dati saranno fisicamente ordinati sul disco (ma in futuro per le nuove righe l'ordine non è garantito). In determinate situazioni, è una buona ottimizzazione per alcuni tipi di query, come la lettura di più record tramite indice. Lo svantaggio del comando è lo stesso di VACUUM FULL: blocca la tabella durante l'esecuzione.
Team REINDEX è simile alle due precedenti, ma esegue la ricostruzione di un indice specifico o di tutti gli indici di una tabella. I blocchi sono un po' più deboli: ShareLock sulla tabella (che impedisce le modifiche, ma consente le selezioni) e AccessExclusiveLock sull'indice ricostruito (che blocca le query che utilizzano questo indice). Tuttavia, nella versione 12 di Postgres è stato introdotto il parametro , che consente di ricostruire l'indice senza bloccare l'aggiunta, la modifica o la cancellazione parallela di record.
Nelle versioni precedenti di Postgres si poteva ottenere un risultato simile a REINDEX CONCURRENTLY utilizzando . Questo permette di creare un indice senza un blocco severo (ShareUpdateExclusiveLock, che non impedisce le query parallele), quindi di sostituire il vecchio indice con il nuovo e rimuovere il vecchio indice. In questo modo si può eliminare il bloat degli indici senza interrompere il funzionamento della tua applicazione. È importante notare che durante la ricostruzione degli indici ci sarà un carico aggiuntivo sul sottosistema disco.
Pertanto, se per gli indici ci sono modi per eliminare il bloat "a caldo", per le tabelle non ci sono. Qui entrano in gioco diverse estensioni esterne: (precedentemente pg_reorg), , e altri. In questo articolo non li confronterò e parlerò solo di pg_repack, che dopo alcune modifiche abbiamo adottato.
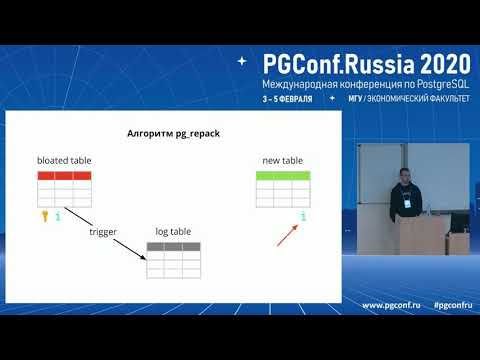
Come funziona pg_repack

Supponiamo di avere una tabella piuttosto normale – con indici, vincoli e, sfortunatamente, bloat. Il primo passo che fa pg_repack è creare una tabella di log per memorizzare i dati su tutte le modifiche durante l'esecuzione. Un trigger replicerà queste modifiche per ogni inserimento, aggiornamento e eliminazione. Successivamente viene creata una tabella, simile a quella originale nella struttura, ma senza indici e vincoli, per non rallentare il processo di inserimento dei dati.
Successivamente, pg_repack trasferisce i dati dalla vecchia tabella a quella nuova, filtrando automaticamente tutte le righe non pertinenti, e poi crea indici per la nuova tabella. Durante l'esecuzione di tutte queste operazioni, in tabella di log si accumulano le modifiche.
Il passo successivo è trasferire le modifiche nella nuova tabella. Il trasferimento avviene in più iterazioni e, quando nella tabella di log rimangono meno di 20 record, pg_repack acquisisce un blocco esclusivo, sposta gli ultimi dati e sostituisce la vecchia tabella con la nuova nelle tabelle di sistema di Postgres. Questo è l'unico e brevissimo momento in cui non è possibile lavorare con la tabella. Dopo, la vecchia tabella e la tabella dei log vengono eliminate e lo spazio viene liberato nel file system. Il processo è completato.
In teoria tutto sembra ottimo, ma nella pratica? Abbiamo testato pg_repack sia senza carico che sotto carico, verificando il suo funzionamento in caso di interruzione prematura (in altre parole, premendo Ctrl+C). Tutti i test hanno avuto esito positivo.
Siamo andati in produzione e qui tutto è andato diversamente da quanto previsto.
Il primo tentativo in produzione
Nel primo cluster abbiamo ricevuto un errore riguardante la violazione di un vincolo unico:
$ ./pg_repack -t tablename -o id
INFO: ripristino della tabella "tablename"
ERRORE: query non riuscita:
ERRORE: valore della chiave duplicato viola il vincolo unico "index_16508"
DETTAGLIO: La chiave (id, index)=(100500, 42) esiste già.
Questa restrizione aveva un nome autogenerato index_16508 – creato da pg_repack. Attraverso gli attributi che ne fanno parte, abbiamo identificato il nostro vincolo corrispondente. Il problema è emerso dal fatto che non si tratta di un vincolo ordinario, ma di un vincolo differito (), cioè la sua verifica avviene successivamente al comando SQL, il che porta a conseguenze inaspettate.
Vincoli differiti: a cosa servono e come funzionano
Un po' di teoria sui vincoli differiti.
Consideriamo un semplice esempio: abbiamo una tabella di riferimento per automobili con due attributi – nome e posizione dell'auto nel riferimento.
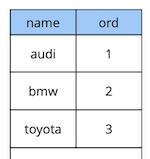
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique
);
Supponiamo di dover scambiare il primo e il secondo veicolo. La soluzione “diretta” sarebbe aggiornare il primo valore con il secondo e il secondo con il primo:
begin;
update cars set ord = 2 where name = 'audi';
update cars set ord = 1 where name = 'bmw';
commit;
Ma durante l'esecuzione di questo codice ci aspettiamo di ricevere una violazione del vincolo, poiché l'ordine dei valori nella tabella è unico:
[23305] ERROR: duplicate key value violates unique constraint “uk_cars”
Detail: Key (ord)=(2) already exists.
Come procedere in modo diverso? Prima opzione: aggiungere un'ulteriore sostituzione del valore per un ordine che non esiste garantitamente nella tabella, ad esempio "-1". In programmazione, questo è noto come "scambio dei valori di due variabili attraverso una terza". L'unico svantaggio di questo metodo è l'ulteriore aggiornamento.
Seconda opzione: riprogettare la tabella per utilizzare un tipo di dati in virgola mobile per il valore dell'ordine anziché numeri interi. Così, quando si aggiorna il valore da 1, ad esempio, a 2,5, il primo record si "inserirà" automaticamente tra il secondo e il terzo. Questa soluzione funziona, ma presenta due limiti. In primo luogo, non sarà utile se il valore è utilizzato da qualche parte nell'interfaccia. In secondo luogo, a seconda della precisione del tipo di dati, avrete un numero limitato di possibili inserimenti fino a quando non verranno ricalcolati i valori di tutti i record.
Terza opzione: rendere la restrizione ritardata, in modo che venga verificata solo al momento del commit:
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique deferrable initially deferred
);Poiché la logica della nostra richiesta iniziale garantisce che al momento del commit tutti i valori siano unici, essa avrà successo.
L'esempio considerato sopra è certamente molto sintetico, ma illustra bene l'idea. Nella nostra applicazione, utilizziamo vincoli differiti per realizzare la logica che si occupa di risolvere i conflitti quando più utenti interagiscono con gli oggetti-widget condivisi sulla bacheca. L'uso di tali vincoli ci consente di semplificare leggermente il codice applicativo.
In generale, a seconda del tipo di vincolo in Postgres, esistono tre livelli di granularità per la loro verifica: livello di riga, transazione e espressione.
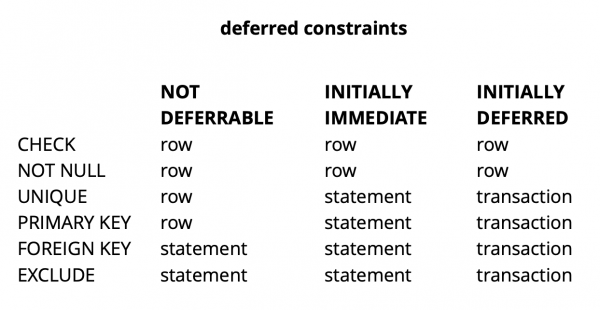
Fonte:
I vincoli CHECK e NOT NULL vengono sempre verificati a livello di riga, mentre per gli altri vincoli, come evidenziato nella tabella, ci sono diverse opzioni. Maggiori dettagli possono essere letti. .
In breve, le restrizioni posticipate in alcune situazioni forniscono un codice più leggibile e un numero ridotto di comandi. Tuttavia, ciò comporta un processo di debug più complesso, poiché il momento in cui si verifica l'errore è diverso da quando se ne viene a conoscenza. Un'altra possibile problematica è che il pianificatore non riesce sempre a costruire un piano ottimale se nel query è coinvolta una restrizione posticipata.
Miglioramento di pg_repack
Abbiamo capito cosa sono le restrizioni posticipate, ma come sono collegate al nostro problema? Ricordiamo l'errore che abbiamo ricevuto in precedenza:
$ ./pg_repack -t tablename -o id
INFO: ripristino della tabella "tablename"
ERRORE: query non riuscita:
ERRORE: valore della chiave duplicato viola il vincolo unico "index_16508"
DETTAGLIO: La chiave (id, index)=(100500, 42) esiste già.Si verifica al momento della copia dei dati dalla tabella log in una nuova tabella. Sembra strano, poiché i dati nella tabella log vengono confermati insieme ai dati della tabella originale. Se soddisfano le restrizioni della tabella originale, come possono violare le stesse restrizioni nella nuova?
A quanto pare, la radice del problema risiede nel passaggio precedente dell'operazione di pg_repack, in cui vengono creati solo indici, ma non restrizioni: nella vecchia tabella c'era una restrizione unica, mentre nella nuova è stato creato un indice unico al suo posto.
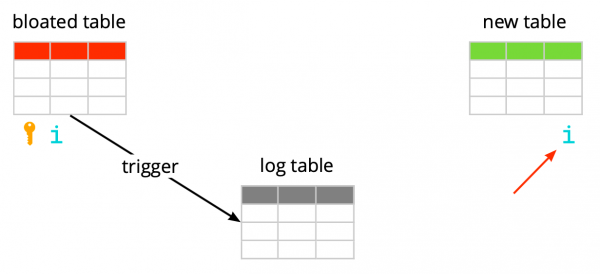
È importante notare che, se il vincolo è normale e non differito, l'indice unico creato al suo posto è equivalente a questo vincolo, poiché i vincoli unici in Postgres vengono implementati creando un indice unico. Tuttavia, nel caso di un vincolo differito, il comportamento non è lo stesso, perché l'indice non può essere differito e viene sempre controllato al momento dell'esecuzione del comando SQL.
Quindi, la questione fondamentale riguarda la "differita" della verifica: nella tabella originale avviene al momento dell'impegno, mentre nella nuova avviene al momento dell'esecuzione del comando SQL. Dobbiamo quindi fare in modo che i controlli vengano eseguiti in modo uniforme in entrambi i casi: o sempre in modo differito, oppure sempre immediatamente.
Quindi, quali idee abbiamo avuto.
Creare un indice simile a deferred
La prima idea è di eseguire entrambe le verifiche in modalità immediata. Questo potrebbe generare alcuni falsi positivi con i limiti, ma se sono pochi, non dovrebbe influire sul lavoro degli utenti, poiché tali conflitti sono situazioni normali per loro. Si verificano, ad esempio, quando due utenti iniziano a modificare contemporaneamente lo stesso widget, e il client del secondo utente non riesce a ricevere informazioni che il widget è già bloccato per la modifica dal primo utente. In questa situazione, il server risponde al secondo utente con un rifiuto, e il suo client annulla le modifiche e blocca il widget. Poco dopo, quando il primo utente termina la modifica, il secondo riceverà informazioni che il widget non è più bloccato e potrà ripetere la sua azione.

Per garantire che le verifiche siano sempre in modalità urgente, abbiamo creato un nuovo indice, simile al limite originale ritardato:
CREATE UNIQUE INDEX CONCURRENTLY uk_tablename__immediate ON tablename (id, index);
-- run pg_repack
DROP INDEX CONCURRENTLY uk_tablename__immediate;Nell'ambiente di test abbiamo riscontrato solo alcuni errori previsti. Successo! Abbiamo riavviato pg_repack in produzione e abbiamo registrato 5 errori nel primo cluster in un'ora di lavoro. Questo è un risultato accettabile. Tuttavia, nel secondo cluster il numero di errori è aumentato drasticamente e abbiamo dovuto fermare pg_repack.
Perché è successo? La probabilità di errore dipende da quanti utenti lavorano contemporaneamente con gli stessi widget. A quanto pare, in quel momento, i dati archiviati nel primo cluster hanno subito molte meno modifiche concorrenti rispetto agli altri, quindi ci è andata 'bene'.
L'idea non ha funzionato. In quel momento abbiamo considerato altre due soluzioni: riscrivere il nostro codice applicativo per rinunciare ai vincoli differiti, oppure 'insegnare' a pg_repack a funzionare con essi. Abbiamo scelto la seconda opzione.
Sostituire gli indici nella nuova tabella con i vincoli differiti dalla tabella originale.
L'obiettivo della modifica era chiaro: se la tabella originale ha un vincolo differito, allora per la nuova tabella bisogna creare un vincolo di questo tipo, e non un indice.
Per verificare le nostre modifiche, abbiamo scritto un semplice test:
- tabella con vincolo deferred e una registrazione;
- inseriamo in ciclo dati che confliggono con la registrazione esistente;
- facciamo un update – i dati non confliggono più;
- comit ini cambiamenti.
CREATE TABLE test_table
(
id serial,
val int,
CONSTRAINT uk_test_table__val UNIQUE (val) DEFERRABLE INITIALLY DEFERRED
);
INSERT INTO test_table (val) VALUES (0);
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (0) RETURNING id INTO v_id;
UPDATE test_table SET val = i WHERE id = v_id;
COMMIT;
END;
END LOOP;La versione originale di pg_repack si bloccava sempre al primo insert, la versione migliorata funzionava senza errori. Ottimo.
Andiamo in produzione e otteniamo di nuovo un errore alla stessa fase di copia dei dati dalla tabella log alla nuova:
$ ./pg_repack -t tablename -o id
INFO: ripristino della tabella "tablename"
ERRORE: query non riuscita:
ERRORE: valore della chiave duplicato viola il vincolo unico "index_16508"
DETTAGLIO: La chiave (id, index)=(100500, 42) esiste già.Situazione classica: negli ambienti di test funziona tutto, mentre in produzione non funziona?!
APPLY_COUNT e giunzione di due batch
Abbiamo iniziato ad analizzare il codice letteralmente riga per riga e abbiamo scoperto un aspetto importante: il trasferimento dei dati dalla tabella log alla nuova avviene a batch, la costante APPLY_COUNT indicava la dimensione del batch:
for (;;)
{
num = apply_log(connection, table, APPLY_COUNT);
if (num > MIN_TUPLES_BEFORE_SWITCH)
continue; /* potrebbero esserci ancora tuple, ripeti. */
...
}Il problema è che i dati della transazione originale, in cui potrebbero esserci più operazioni che potenzialmente violano il vincolo, durante il trasferimento possono trovarsi al confine di due batch: metà dei comandi sarà confermata nel primo batch e l'altra metà nel secondo. E qui dipende dalla fortuna: se i comandi nel primo batch non violano nulla, allora va tutto bene, ma se violano – si verifica un errore.
APPLY_COUNT è pari a 1000 record, il che spiega perché i nostri test sono passati con successo – non coprivano il caso del "confine dei batch". Abbiamo utilizzato due comandi – insert e update, quindi esattamente 500 transazioni con due comandi sono sempre state inserite nel batch e non abbiamo riscontrato problemi. Dopo aver aggiunto il secondo update, la nostra modifica ha smesso di funzionare:
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (1) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
UPDATE test_table set val = i where id = v_id; -- un altro update
COMMIT;
END;
END LOOP;Quindi, il prossimo compito è fare in modo che i dati nella tabella originale, che sono stati modificati in una transazione, vengano trasferiti nella nuova tabella anche all'interno di una transazione.
Abbandono del batching
E anche noi avevamo due opzioni da considerare. La prima: abbandoniamo completamente la suddivisione in batch e trasferiamo i dati con un'unica transazione. A favore di questa soluzione c'era la sua semplicità: le modifiche al codice richieste sarebbero state minime (tra l'altro, nelle versioni precedenti pg_reorg funzionava proprio in questo modo). Ma c'è un problema: creiamo una transazione lunga, e questo, come accennato in precedenza, rappresenta una minaccia per la possibilità di un nuovo bloat.
La seconda soluzione è più complessa, ma probabilmente più corretta: creare nella tabella di log una colonna con l'identificativo della transazione che ha aggiunto i dati alla tabella. In questo modo, durante la copia dei dati, potremo raggrupparli in base a questo attributo e garantire che le modifiche correlate vengano trasferite insieme. Il batch sarà formato da più transazioni (o una grande) e la sua dimensione varierà a seconda di quante informazioni sono state modificate in queste transazioni. È importante notare che, poiché i dati di diverse transazioni vengono inseriti nella tabella di log in ordine casuale, non sarà più possibile leggerla sequenzialmente come prima. Il seqscan ad ogni richiesta con filtro su tx_id è troppo costoso, è necessario un indice, ma questo rallenterà anche il metodo a causa dei costi di aggiornamento. In generale, come sempre, bisogna sacrificare qualcosa.
Quindi, abbiamo deciso di iniziare con la prima opzione, che è la più semplice. Per cominciare, era necessario capire se una transazione lunga sarebbe stata un vero problema. Poiché il trasferimento principale dei dati dalla vecchia tabella alla nuova avviene anche in una lunga transazione, la domanda si è trasformata in "quanto aumenteremo questa transazione?" La durata della prima transazione dipende principalmente dalle dimensioni della tabella. La durata della nuova dipende da quante modifiche si accumuleranno nella tabella durante il trasferimento dei dati, ossia dall'intensità del carico. L'esecuzione di pg_repack è avvenuta durante il carico minimo del servizio, e il volume delle modifiche è stato incredibilmente ridotto rispetto al volume iniziale della tabella. Abbiamo deciso che potevamo trascurare il tempo della nuova transazione (in media, è di 1 ora e 2-3 minuti per il confronto).
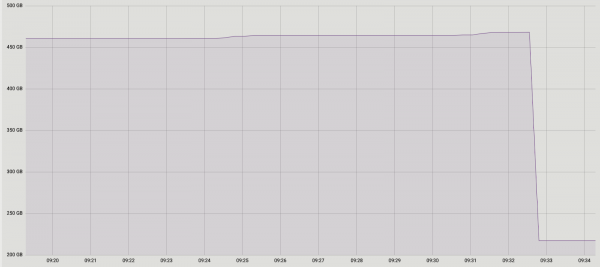
Gli esperimenti sono stati positivi. Anche il lancio in produzione lo è stato. Per chiarezza, ecco un'immagine della dimensione di uno dei database dopo l'esecuzione:
Poiché questa soluzione ci ha soddisfatti completamente, non abbiamo tentato di implementarne una seconda, ma stiamo considerando la possibilità di discuterne con gli sviluppatori dell'estensione. Sfortunatamente, il nostro attuale aggiornamento non è ancora pronto per la pubblicazione, poiché abbiamo risolto il problema solo con le limitazioni uniche rinviate, e per una patch completa è necessario supportare anche altri tipi. Speriamo di riuscirci in futuro.
Potresti chiederti perché ci siamo imbarcati in questa storia di miglioramento di pg_repack e non abbiamo semplicemente utilizzato le sue alternative. Anche noi abbiamo avuto questa riflessione in un certo momento, ma la nostra esperienza positiva precedente nell'utilizzo su tabelle senza limitazioni rinviate ci ha motivato a cercare di comprendere la natura del problema e risolverlo. Inoltre, l'utilizzo di altre soluzioni richiede tempo per i test, quindi abbiamo deciso di provare prima a correggere il problema in questo, e se capiamo di non poterlo fare in un tempo ragionevole, inizieremo a considerare le alternative.
Conclusioni
Cosa possiamo raccomandare sulla base della nostra esperienza personale:
- Monitora il tuo bloat. Grazie ai dati di monitoraggio, potrai capire quanto bene è configurato autovacuum.
- Configura AUTOVACUUM per mantenere il bloat entro limiti accettabili.
- Se il bloat continua a crescere e non riesci a gestirlo con gli strumenti 'out-of-the-box', non avere paura di utilizzare estensioni esterne. L'importante è testare tutto a fondo.
- Non temere di adattare le soluzioni esterne alle tue esigenze: a volte può essere più efficace e persino più semplice rispetto a modificare il tuo codice.
Fonte: habr.com
