

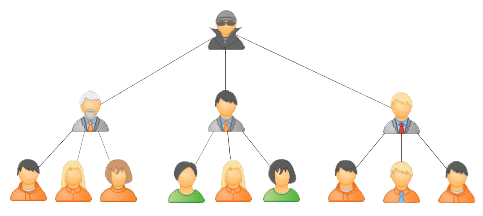
Nei complessi sistemi ERP molte entità hanno una natura gerarchica, quando oggetti omogenei si organizzano in un albero di relazioni "antenato - discendente" — si tratta sia della struttura organizzativa di un'azienda (tutti questi filiali, reparti e gruppi di lavoro), sia del catalogo dei prodotti, delle zone di lavoro e della geografia dei punti vendita,…
In effetti, non esiste un , in cui non ci sia una qualche gerarchia. Ma anche se non lavori "nel business", puoi comunque facilmente imbattersi in relazioni gerarchiche. Per esempio, il tuo albero genealogico o la pianta degli uffici in un centro commerciale hanno la stessa struttura.
Esistono molti modi per memorizzare questo albero in un DBMS, ma oggi ci soffermeremo solo su una opzione:
CREATE TABLE hier(
id
integer
PRIMARY KEY
, pid
integer
REFERENCES hier
, data
json
);
CREATE INDEX ON hier(pid); -- ricordiamo che la FK non implica la creazione automatica dell'indice, a differenza della PK
Mentre esplori la profondità della gerarchia, essa attende pazientemente di vedere quanto si rivelino [non] efficaci i tuoi approcci 'naïf' a questa struttura.

Analizziamo i compiti tipici che sorgono, la loro implementazione in SQL e proviamo a migliorarne le prestazioni.
#1. Насколько глубока кроличья нора?
Per chiarezza, supponiamo che questa struttura rispecchi la subordinazione dei reparti nella struttura dell'organizzazione: dipartimenti, divisioni, settori, filiali, gruppi di lavoro,… — qualunque nome tu voglia darle.
Cominciamo a generare il nostro 'albero' di 10K elementi.
INSERT INTO hier
WITH RECURSIVE T AS (
SELECT
1::integer id
, '{1}'::integer[] pids
UNION ALL
SELECT
id + 1
, pids[1:(random() * array_length(pids, 1))::integer] || (id + 1)
FROM
T
WHERE
id < 10000
)
SELECT
pids[array_length(pids, 1)] id
, pids[array_length(pids, 1) - 1] pid
FROM
T;Iniziamo con il compito più semplice: trovare tutti i dipendenti che lavorano all'interno di un settore specifico, o nei termini della gerarchia — trovare tutti i discendenti di un nodo.. E sarebbe utile ottenere anche la 'profondità' del discendente… Tutto ciò potrebbe essere necessario, ad esempio, per costruire una certa .
Sarebbe tutto a posto se ci fossero solo un paio di livelli di discendenti e una manciata di elementi, ma se i livelli superano 5 e i discendenti sono già decine, potrebbero sorgere problemi. Esaminiamo come vengono scritti (e funzionano) i tradizionali metodi di ricerca "verso il basso nell'albero". Ma prima, definiamo quali nodi saranno i più interessanti per le nostre indagini.
I più «profondi» sottotrees:
WITH RECURSIVE T AS (
SELECT
id
, pid
, ARRAY[id] path
FROM
hier
WHERE
pid IS NULL
UNION ALL
SELECT
hier.id
, hier.pid
, T.path || hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T ORDER BY array_length(path, 1) DESC; id | pid | path
---------------------------------------------
7624 | 7623 | {7615,7620,7621,7622,7623,7624}
4995 | 4994 | {4983,4985,4988,4993,4994,4995}
4991 | 4990 | {4983,4985,4988,4989,4990,4991}
...I più «ampii» sottotrees:
...
SELECT
path[1] id
, count(*)
FROM
T
GROUP BY
1
ORDER BY
2 DESC;id | count
------------
5300 | 30
450 | 28
1239 | 27
1573 | 25
Per queste query, abbiamo utilizzato un tipico JOIN ricorsivo:
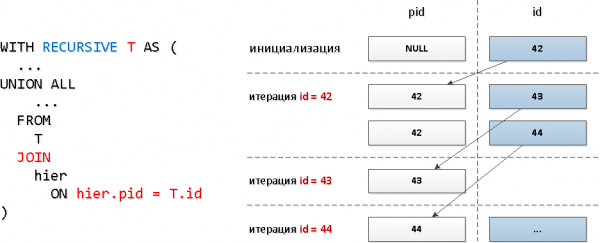
È chiaro che con un modello di query del genere il numero di iterazioni corrisponderà al numero totale di discendenti (che sono decine), e questo può richiedere risorse significative e, di conseguenza, tempo.
Verifichiamo sul sottotree "più ampio":
CON RECURSIONE T AS (
SELECT
id
FROM
hier
WHERE
id = 5300
UNIONE TUTTO
SELECT
hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABELLINA T; 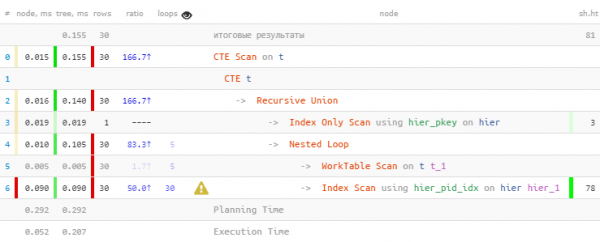
Come previsto, abbiamo trovato tutte le 30 voci. Ma abbiamo impiegato il 60% del tempo totale — perché nel frattempo abbiamo effettuato 30 ricerche nell'indice. E meno — è possibile?
Lettura massiva tramite indice
È necessario fare una richiesta separata all'indice per ogni nodo? A quanto pare no — possiamo leggere dall'indice immediatamente per più chiavi in un'unica richiesta utilizzando = ANY(array).
E per ogni raggruppamento di identificatori possiamo prendere tutti gli ID trovati nel passaggio precedente per i "nodi". Cioè ad ogni passaggio successivo cercheremo tutti i discendenti di un certo livello.
Solo, c'è un problema, nella selezione ricorsiva non è possibile riferirsi a se stessi nella sottoquery, e noi dobbiamo in qualche modo selezionare solo ciò che è stato trovato nel livello precedente… A quanto pare, fare una sottoquery su tutta la selezione — non è possibile, ma su un suo campo specifico — sì. E quel campo può essere anche un array — proprio quello di cui abbiamo bisogno per utilizzarlo. ANY.
Sembra un po' strano, ma nella scheda — è tutto semplice.
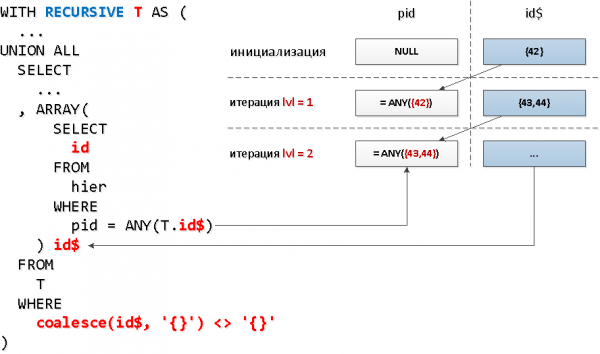
CON RICORSIONE T AS (
SELECT
ARRAY[id] id$
FROM
hier
WHERE
id = 5300
UNIONE TUTTO
SELECT
ARRAY(
SELECT
id
FROM
hier
WHERE
pid = ANY(T.id$)
) id$
FROM
T
WHERE
coalesce(id$, '{}') '{}' -- condizione di uscita dal ciclo - array vuoto
)
SELECT
unnest(id$) id
FROM
T; 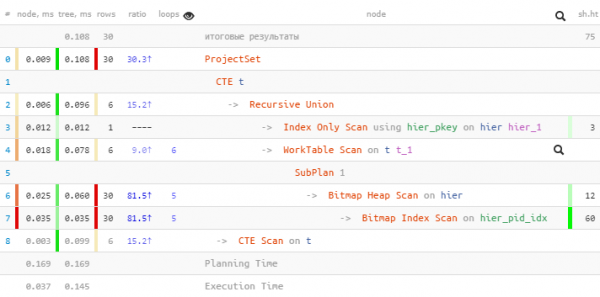
E qui la cosa più importante non è neanche un guadagno di 1,5 volte nel tempo, ma il fatto che abbiamo ridotto il numero di buffers, poiché le chiamate all'indice sono solo 5 invece di 30!
Un ulteriore vantaggio è che dopo il finale unnest, gli identificatori rimarranno ordinati per «livelli».
Caratteristica del nodo
Una considerazione successiva che aiuterà a migliorare le prestazioni è che le «foglie» non possono avere figli, cioè per loro non c'è assolutamente bisogno di cercare «in basso». Nel contesto del nostro problema questo significa che se siamo andati lungo la catena dei reparti e siamo arrivati a un dipendente, non ha senso cercare più avanti su quel ramo.
Introduciamo nella nostra tabella un campo booleanoaggiuntivo, che ci dirà subito se questo specifico record nel nostro albero è un «nodo» — cioè se può avere realmente discendenti.
ALTER TABLE hier
ADD COLUMN branch boolean;
UPDATE
hier T
SET
branch = TRUE
WHERE
EXISTS(
SELECT
NULL
FROM
hier
WHERE
pid = T.id
LIMIT 1
);
-- Query executed successfully: 3033 rows changed in 42 ms.Ottimo! Si scopre che solo poco più del 30% di tutti gli elementi dell'albero ha discendenti.
Ora applichiamo una meccanica un po' diversa — connessioni con la parte ricorsiva tramite LATERAL, che ci consentirà di accedere immediatamente ai campi della «tabella» ricorsiva, mentre la funzione aggregata con la condizione di filtraggio in base al criterio del nodo la utilizziamo per ridurre l'insieme delle chiavi:
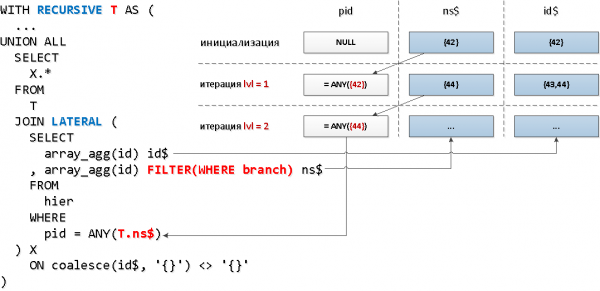
WITH RECURSIVE T AS (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
X.*
FROM
T
JOIN LATERAL (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
pid = ANY(T.ns$)
) X
ON coalesce(T.ns$, '{}') '{}'
)
SELECT
unnest(id$) id
FROM
T; 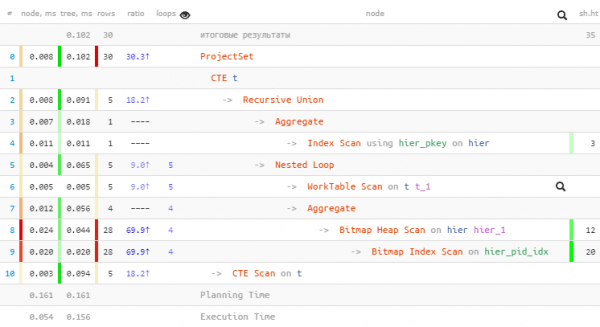
Siamo riusciti a ridurre un'altra chiamata all'indice e abbiamo guadagnato più di due volte in volume di lettura.
#2. Вернемся к корням
Questo algoritmo sarà utile se è necessario raccogliere registrazioni per tutti gli elementi "salendo nell'albero", mantenendo al contempo informazioni sul quale foglio originale (e con quali indicatori) ha causato il suo inserimento nel campione — ad esempio, per la creazione di un report aggregato sui nodi.
Il seguito va percepito esclusivamente come proof-of-concept, poiché la query diventa piuttosto ingombrante. Ma se domina nel tuo database, vale la pena considerare l'applicazione di tecniche simili.
Iniziamo con un paio di semplici affermazioni:
- Una stessa registrazione nel database è meglio leggerla solo una volta.
- Le registrazioni nel database si leggono più efficacemente "in blocco", piuttosto che singolarmente.
Ora proviamo a costruire la query di cui abbiamo bisogno.
Passo 1
È ovvio che all'inizio della ricorsione (dove altro poteva essere!) dovremo estrarre le registrazioni delle foglie stesse per un insieme di identificatori originali:
WITH RECURSIVE tree AS (
SELECT
rec -- questa è l'intera registrazione della tabella
, id::text chld -- questo è il "set" dei fogli originali che hanno portato qui
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
... Se a qualcuno è sembrato strano che un 'insieme' venga memorizzato come stringa anziché come array, c'è una spiegazione semplice. Esiste una funzione aggregante 'concatenatrice' incorporata per le stringhe string_agg, mentre per gli array non è così. Anche se non è complicato implementarla da soli. .
Passo 2
raggrupparli , mantenendo al contempo le informazioni sulle fonti-lettori.Ma qui ci aspettano tre problemi:
La parte 'sottorecursiva' della query non può contenere funzioni aggregate con
- L'accesso alla 'tabella' ricorsiva non può essere all'interno di una sottoquery.
GROUP BY. - La query nella parte ricorsiva non può contenere CTE.
- Fortunatamente, tutti questi problemi possono essere facilmente aggirati. Cominciamo dalla fine.
Il CTE nella parte ricorsiva
funziona:
Ecco come non WITH RECURSIVE tree AS ( ... UNION ALL WITH T (...) SELECT ... )
E così — funziona, le parentesi risolvono tutto!WITH RECURSIVE tree AS ( ... UNION ALL ( WITH T (...) SELECT ... ) )
Una query annidata alla 'tabella' ricorsivaВложенный запрос к рекурсивной «таблице»
Hmm... Un riferimento a un CTE ricorsivo non può essere in una sottoquery. Ma può essere all'interno di un CTE! E la sottoquery può già riferirsi a questo CTE!
GROUP BY all'interno della ricorsione
Scomodo, ma... Abbiamo un modo semplice per simulare GROUP BY utilizzando DISTINCT ON e funzioni di finestra!
SELECT
(rec).pid id
, string_agg(chld::text, ',') chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
GROUP BY 1 -- non funziona!Ma in questo modo — funziona!
SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULLOra vediamo perché l'ID numerico è stato convertito in testo — per poterli unire separandoli con una virgola!
Passo 3
Per il finale ci resta solo poco:
- estraiamo i record delle «sezioni» in base all'insieme di ID raggruppati
- mettiamo in corrispondenza le sezioni estratte con i «set» di fogli di partenza
- «sviluppiamo» la riga-insieme utilizzando
unnest(string_to_array(chld, ',')::integer[])
CON ALGORITMI DI RICORSIONE tree COME (
SELEZIONA
rec
, id::text chld
DA
gerarchia rec
DOVE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNIONE TUTTO
(
CON prnt COME (
SELEZIONA DISTINTI SU((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTIZIONE PER (rec).pid) chld
DA
tree
DOVE
(rec).pid È NON NULL
)
, nodi COME (
SELEZIONA
rec
DA
gerarchia rec
DOVE
id = ANY(ARRAY(
SELEZIONA
id
DA
prnt
))
)
SELEZIONA
nodi.rec
, prnt.chld
DA
prnt
UNISCI
nodi
SU (nodi.rec).id = prnt.id
)
)
SELEZIONA
unnest(string_to_array(chld, ',')::integer[]) foglia
, (rec).*
DA
tree; 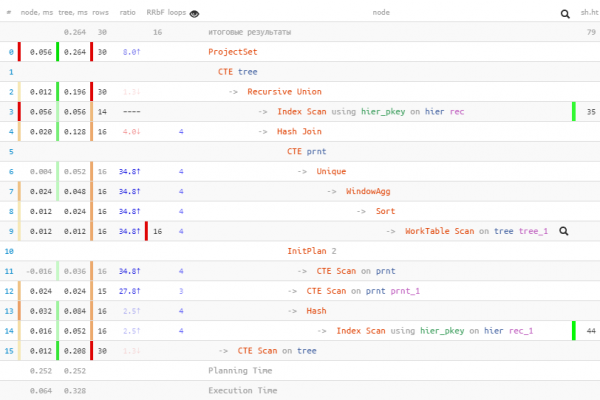
Fonte: habr.com
