

Ciao a tutti, amici!
* Questo articolo è ispirato a un workshop aperto di REBRAIN & Yandex.Cloud. Se preferite guardare un video, potete trovarlo a questo link —
Recentemente abbiamo avuto l'opportunità di esplorare Yandex.Cloud dal vivo. Poiché volevamo esaminare a fondo, abbiamo subito rinunciato all'idea di lanciare un semplice blog WordPress con una base dati nel cloud: troppo noioso. Dopo brevi riflessioni, abbiamo deciso di implementare qualcosa di simile a un'architettura di produzione per ricevere e analizzare eventi in modalità near real-time.
Sono assolutamente certo che la stragrande maggioranza delle attività online (e non solo) raccolga in qualche modo una grande quantità di informazioni sui propri utenti e le loro azioni. Almeno è necessario per prendere determinate decisioni: ad esempio, se gestite un gioco online, potete controllare le statistiche su quali livelli gli utenti si bloccano più frequentemente e abbandonano il vostro gioco. O perché gli utenti abbandonano il vostro sito senza acquistare nulla (saluti, Yandex.Metrica).
Quindi, la nostra storia: come abbiamo scritto un'applicazione in golang, testato kafka contro rabbitmq contro yqs, realizzato lo streaming dei dati in un cluster Clickhouse e visualizzato i dati utilizzando Yandex Datalens. Naturalmente, tutto questo è stato arricchito da raffinatezze infrastrutturali come docker, terraform, gitlab ci e, ovviamente, prometheus. Andiamo!
Ci tengo a precisare che non riusciremo a configurare tutto in un colpo solo: ci vorranno diversi articoli in questa serie. Un po' sulla struttura:
1ª parte (questa è quella che stai leggendo). Definiremo i requisiti e l'architettura della soluzione, e scriveremo un'applicazione in golang.
2ª parte. Lanciamo la nostra applicazione in produzione, rendiamola scalabile e testiamo il carico.
3ª parte. Cercheremo di capire perché sia necessario memorizzare i messaggi in un buffer piuttosto che in file, e confronteremo kafka, rabbitmq e Yandex Queue Service.
4ª parte. Procederemo all'implementazione di un cluster Clickhouse, scriveremo lo streaming per spostare i dati dal buffer a Clickhouse e configureremo la visualizzazione in Datalens.
5ª parte. Metteremo tutta l'infrastruttura in ordine: configureremo il ci/cd utilizzando gitlab ci, installeremo il monitoraggio e la scoperta dei servizi utilizzando prometheus e consul.
Requisiti
Iniziamo a formulare i requisiti tecnici — cosa vogliamo esattamente ottenere.
- Desideriamo avere un endpoint del tipo events.kis.im (kis.im è un dominio di test che utilizzeremo in tutti gli articoli), che deve accettare eventi tramite HTTPS.
- Gli eventi sono un semplice JSON del tipo: {"event": "view", "os": "linux", "browser": "chrome"}. Nella fase finale aggiungeremo qualche campo in più, ma non influirà significativamente. Se lo desiderate, si può passare a protobuf.
- Il servizio deve essere in grado di gestire 10.000 eventi al secondo.
- Deve essere possibile scalare orizzontalmente — semplicemente aggiungendo nuove istanze alla nostra soluzione. Sarebbe inoltre utile se potessimo distribuire la parte front-end in diverse geolocalizzazioni per ridurre la latenza nelle richieste dei clienti.
- Resilienza. La soluzione deve essere abbastanza stabile e in grado di sopravvivere al guasto di qualsiasi parte (fino a un certo numero, naturalmente).
Architettura
In effetti, per questo tipo di compiti sono state a lungo sviluppate architetture classiche che consentono di scalare efficacemente. Nella figura è mostrato un esempio della nostra soluzione.
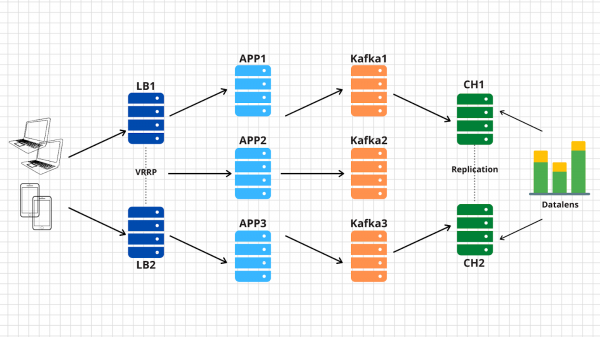
Quindi, cosa abbiamo?
1. A sinistra ci sono i nostri dispositivi che generano vari eventi, sia che si tratti del completamento di un livello da parte dei giocatori in un gioco per smartphone o della creazione di un ordine in un negozio online tramite un browser comune. L'evento, come specificato nel documento tecnico, è un semplice JSON che viene inviato al nostro endpoint — events.kis.im.
2. I primi due server sono bilanciatori semplici, le loro principali funzionalità sono:
- Essere sempre disponibili. Per garantirlo, si può utilizzare, ad esempio, keepalived, che trasferirà l'IP virtuale tra i nodi in caso di problemi.
- Terminare il TLS. Sì, il TLS verrà terminato proprio su di essi. In primo luogo, affinché la nostra soluzione rispetti il documento tecnico, e in secondo luogo, per alleviare il carico di instaurare una connessione crittografata dai nostri server backend.
- Bilanciare le richieste in ingresso sui server backend disponibili. La parola chiave qui è disponibili. Da ciò, comprendiamo che i bilanciatori di carico devono essere in grado di monitorare i nostri server con le applicazioni e smettere di bilanciare il traffico sulle nodi non disponibili.
3. Dietro i bilanciatori, abbiamo server applicativi su cui è in esecuzione un'applicazione piuttosto semplice. Deve essere in grado di ricevere richieste in entrata tramite HTTP, convalidare il JSON inviato e memorizzare i dati in un buffer.
4. Nello schema, come buffer è rappresentata Kafka, sebbene a questo livello si possano utilizzare anche altri servizi simili. Confronteremo Kafka, RabbitMQ e YQS nell'articolo tre.
5. Il penultimo punto della nostra architettura è Clickhouse, un database colonnare che consente di memorizzare e lavorare enormi volumi di dati. A questo livello, è necessario trasferire i dati dal buffer al sistema di archiviazione vero e proprio (se ne parlerà nell'articolo 4).
Questo schema ci consente di scalare orizzontalmente in modo indipendente ciascun livello. Se i server backend non ce la fanno, ne aggiungeremo altri, dato che sono applicazioni stateless, quindi questo può avvenire anche in modo automatico. Se il buffer in forma di Kafka non regge, aggiungeremo altri server e sposteremo su di essi alcune partizioni del nostro topic. Se Clickhouse non ce la fa, questo è impossibile 🙂 In realtà, aggiungeremo anche server e shardiamo i dati.
A proposito, se desideri implementare la parte opzionale del nostro progetto e realizzare la scalabilità in diverse geolocalizzazioni, non c'è niente di più semplice:
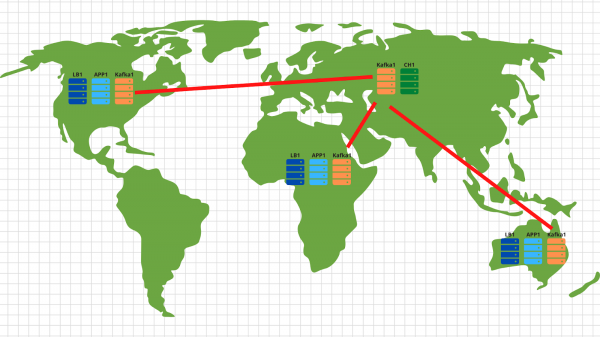
In ogni geolocalizzazione implementiamo un load balancer con application e kafka. In generale, sono sufficienti 2 server application, 3 nodi kafka e un bilanciatore cloud, ad esempio cloudflare, che verificherà la disponibilità dei nodi dell'applicazione e bilancerà le richieste per geolocalizzazione in base all'indirizzo IP del cliente. In questo modo, i dati inviati da un cliente americano atterreranno sui server americani. E i dati dall'Africa atterreranno su quelli africani.
Dopo tutto questo, è davvero semplice: utilizziamo lo strumento mirror dal set di kafki e copiamo tutti i dati da tutte le località nel nostro data center centrale situato in Russia. All'interno analizziamo i dati e li registriamo in Clickhouse per la successiva visualizzazione.
Quindi, chiarita l'architettura, iniziamo a testare Yandex.Cloud!
Scriviamo un'applicazione
Dovremo aspettare un po' di tempo per il Cloud e scrivere un servizio piuttosto semplice per elaborare gli eventi in ingresso. Utilizzeremo golang, perché si è dimostrato molto efficace come linguaggio per la scrittura di applicazioni di rete.
Dopo aver dedicato un'ora (o forse anche un paio d'ore), otteniamo circa questo risultato: .
Ecco i punti principali che vorrei evidenziare:
1. All'avvio dell'applicazione è possibile specificare due opzioni. Una serve per indicare la porta su cui ascolteremo le richieste http in entrata (-addr). L'altra è per l'indirizzo del server Kafka, dove registreremo i nostri eventi (-kafka):
addr = flag.String("addr", ":8080", "Indirizzo TCP da ascoltare")
kafka = flag.String("kafka", "127.0.0.1:9092", "Endpoint Kafka")2. L'applicazione utilizza la libreria sarama () per inviare messaggi al cluster Kafka. Abbiamo immediatamente impostato configurazioni mirate alla massima velocità di elaborazione:
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForLocal
config.Producer.Compression = sarama.CompressionSnappy
config.Producer.Return.Successes = true3. Inoltre, nella nostra applicazione è integrato un client Prometheus che raccoglie varie metriche, come:
- il numero di richieste alla nostra applicazione;
- il numero di errori durante l'esecuzione della richiesta (impossibile leggere la richiesta post, JSON danneggiato, impossibile scrivere in Kafka);
- il tempo di elaborazione di una richiesta da parte del cliente, incluso il tempo di scrittura del messaggio in Kafka.
4. Tre endpoint che la nostra applicazione gestisce:
- /status — просто возвращаем ok, чтобы показать, что мы живы. Хотя можно и добавить некоторые проверки, типа доступности кафка кластера.
- /metrics — по этому url prometheus client будет возвращать собранные им метрики.
- /post — основной endpoint, куда будут приходить POST запросы с json внутри. Наше приложение проверяет json на валидность и если все ок — записывает данные в кафка-кластер.
Preciso dire che il codice non è perfetto — può (e deve!) essere migliorato. Ad esempio, si può rinunciare all'uso del net/http integrato e passare a fasthttp, che è più veloce. Oppure si può risparmiare tempo di elaborazione e risorse CPU rinviando la verifica della validità del JSON a una fase successiva — quando i dati vengono trasferiti dal buffer al cluster ClickHouse.
Oltre alla parte di sviluppo, abbiamo subito pensato alla nostra futura infrastruttura e deciso di distribuire la nostra applicazione tramite Docker. Il Dockerfile finale per la costruzione dell'applicazione è — . In generale, è piuttosto semplice; l'unico aspetto su cui voglio mettere in evidenza è la costruzione multistadio, che consente di ridurre l'immagine finale del nostro container.
Primi passi nel cloud
Per prima cosa, ci registriamo su . Dopo aver compilato tutti i campi necessari, ci creeranno un account e ci forniranno un grant di un certo importo, che potrà essere utilizzato per testare i servizi cloud. Se desiderate ripetere tutti i passi del nostro articolo, questo grant dovrebbe essere sufficiente.
Dopo la registrazione, verrà creato un cloud separato e una directory predefinita, dove potrai iniziare a creare risorse cloud. In generale, la relazione tra le risorse in Yandex.Cloud è la seguente:
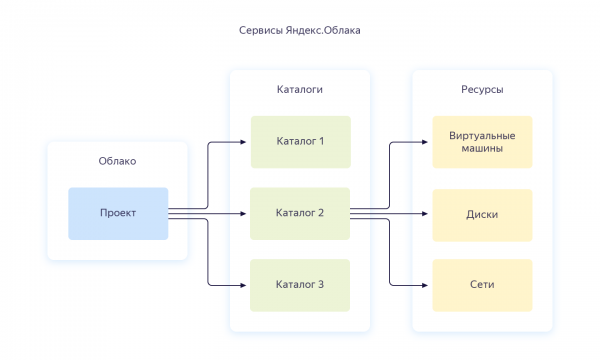
Puoi creare più cloud per un singolo account. All'interno di un cloud, puoi creare diverse directory per vari progetti aziendali. Puoi leggere di più su questo nella documentazione — . A proposito, mi riferirò spesso a essa più avanti nel testo. Quando ho configurato l'intera infrastruttura da zero, la documentazione mi ha aiutato più di una volta, quindi ti consiglio di studiarla.
Per gestire il cloud, puoi utilizzare sia l'interfaccia web che l'utility da console — yc. L'installazione avviene con un semplice comando (per Linux e Mac OS):
curl https://storage.yandexcloud.net/yandexcloud-yc/install.sh | bashSe sei preoccupato per l'esecuzione di script da Internet, puoi, in primo luogo, aprire lo script e leggerlo, e in secondo luogo, lo eseguiamo con il nostro utente — senza diritti di root.
Se vuoi installare il client per Windows, puoi seguire le istruzioni e poi eseguire yc init, per configurarlo completamente:
vozerov@mba:~ $ yc init
Benvenuto! Questo comando ti guiderà attraverso il processo di configurazione.
Per ottenere un token OAuth, vai su https://oauth.yandex.ru/authorize?response_type=token&client_id=.
Inserisci il token OAuth:
Seleziona il cloud da utilizzare:
[1] cloud-b1gv67ihgfu3bp (id = b1gv67ihgfu3bpt24o0q)
[2] fevlake-cloud (id = b1g6bvup3toribomnh30)
Inserisci la tua scelta numerica: 2
Il tuo cloud attuale è stato impostato su 'fevlake-cloud' (id = b1g6bvup3toribomnh30).
Scegli la cartella da utilizzare:
[1] default (id = b1g5r6h11knotfr8vjp7)
[2] Crea una nuova cartella
Inserisci la tua scelta numerica: 1
La tua cartella attuale è stata impostata su 'default' (id = b1g5r6h11knotfr8vjp7).
Vuoi configurare una zona Compute predefinita? [Y/n]
Quale zona vuoi utilizzare come predefinita per il profilo?
[1] ru-central1-a
[2] ru-central1-b
[3] ru-central1-c
[4] Non impostare la zona predefinita
Inserisci la tua scelta numerica: 1
La zona Compute predefinita del tuo profilo è stata impostata su 'ru-central1-a'.
vozerov@mba:~ $In linea di principio, il processo non è difficile: prima devi ottenere un token OAuth per gestire il cloud, selezionare il cloud e la cartella che intendi utilizzare.
Se hai più account o cartelle all'interno di un cloud, puoi creare profili aggiuntivi con impostazioni separate tramite yc config profile create e passarci sopra.
Oltre ai metodi sopra menzionati, il team di Yandex.Cloud ha scritto un ottimo per la gestione delle risorse cloud. Da parte mia, ho preparato un repository git dove ho descritto tutte le risorse che verranno create nell'articolo — . Ci interessa il ramo master, cloniamolo localmente:
vozerov@mba:~ $ git clone https://github.com/rebrainme/yandex-cloud-events/ events
Cloning into 'events'...
remote: Enumerating objects: 100, done.
remote: Counting objects: 100% (100/100), done.
remote: Compressing objects: 100% (68/68), done.
remote: Total 100 (delta 37), reused 89 (delta 26), pack-reused 0
Receiving objects: 100% (100/100), 25.65 KiB | 168.00 KiB/s, done.
Resolving deltas: 100% (37/37), done.
vozerov@mba:~ $ cd events/terraform/Tutte le principali variabili utilizzate in terraform sono definite nel file main.tf. Per cominciare, creiamo nella cartella terraform il file private.auto.tfvars con il seguente contenuto:
# Yandex Cloud Oauth token
yc_token = ""
# Yandex Cloud ID
yc_cloud_id = ""
# Yandex Cloud folder ID
yc_folder_id = ""
# Default Yandex Cloud Region
yc_region = "ru-central1-a"
# Cloudflare email
cf_email = ""
# Cloudflare token
cf_token = ""
# Cloudflare zone id
cf_zone_id = ""Tutte le variabili possono essere ottenute da yc config list, poiché abbiamo già configurato l'utilità della console. Consiglio di aggiungere subito private.auto.tfvars a .gitignore, per non pubblicare accidentalmente dati privati.
Nel private.auto.tfvars abbiamo anche specificato i dati di Cloudflare — per creare record DNS e per instradare il dominio principale events.kis.im sui nostri server. Se non desideri utilizzare Cloudflare, elimina l'inizializzazione del provider Cloudflare nel main.tf e il file dns.tf, responsabile della creazione dei necessari record DNS.
Nella nostra attività combineremo tutti e tre i metodi: l'interfaccia web, l'utilità da riga di comando e Terraform.
Reti virtuali
A dire il vero, questo passaggio potrebbe essere saltato, poiché quando si crea un nuovo cloud, verrà automaticamente creata una rete separata e 3 sottoreti, una per ogni zona di disponibilità. Tuttavia, ci piacerebbe creare una rete separata per il nostro progetto con la sua propria indirizzamento. Lo schema generale della rete in Yandex.Cloud è mostrato nel diagramma qui sotto (praticamente preso da )
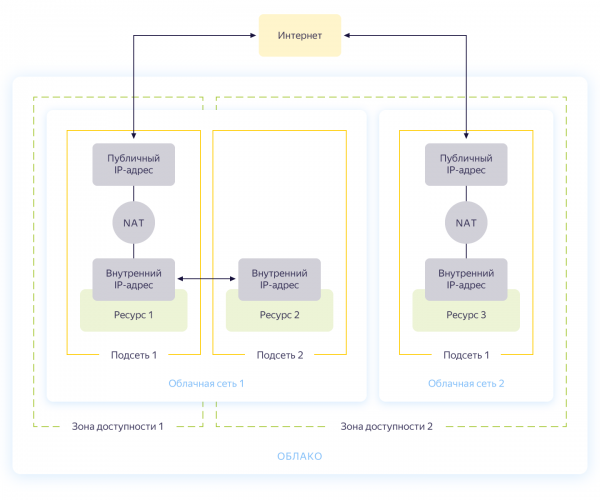
Quindi, stai creando una rete comune all'interno della quale le risorse possono comunicare tra loro. Per ogni zona di disponibilità viene creata una sottorete con il proprio indirizzamento e si collega alla rete comune. Di conseguenza, tutte le risorse nel cloud possono comunicare tra loro, anche se si trovano in diverse zone di disponibilità. Le risorse collegate a reti cloud diverse possono vedersi solo attraverso indirizzi esterni. A proposito, come funziona questa magia all'interno, .
La creazione della rete è descritta nel file network.tf del repository. Qui creiamo una rete privata comune chiamata internal e colleghiamo tre sottoreti in diverse zone di disponibilità: internal-a (172.16.1.0/24), internal-b (172.16.2.0/24), internal-c (172.16.3.0/24).
Inizializziamo terraform e creiamo le reti:
vozerov@mba:~/events/terraform (master) $ terraform init
... saltato ...
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_vpc_subnet.internal-a -target yandex_vpc_subnet.internal-b -target yandex_vpc_subnet.internal-c
... saltato ...
Piano: 4 da aggiungere, 0 da cambiare, 0 da distruggere.
Vuoi eseguire queste azioni?
Terraform eseguirà le azioni descritte sopra.
Solo 'sì' sarà accettato per approvare.
Inserisci un valore: sì
yandex_vpc_network.internal: Creazione in corso...
yandex_vpc_network.internal: Creazione completata dopo 3s [id=enp2g2rhile7gbqlbrkr]
yandex_vpc_subnet.internal-a: Creazione in corso...
yandex_vpc_subnet.internal-b: Creazione in corso...
yandex_vpc_subnet.internal-c: Creazione in corso...
yandex_vpc_subnet.internal-a: Creazione completata dopo 6s [id=e9b1dad6mgoj2v4funog]
yandex_vpc_subnet.internal-b: Creazione completata dopo 7s [id=e2liv5i4amu52p64ac9p]
yandex_vpc_subnet.internal-c: Ancora in creazione... [10s trascorsi]
yandex_vpc_subnet.internal-c: Creazione completata dopo 10s [id=b0c2qhsj2vranoc9vhcq]
Applicazione completata! Risorse: 4 aggiunte, 0 cambiate, 0 distrutte.Ottimo! Abbiamo creato la nostra rete e ora siamo pronti a costruire i nostri servizi interni.
Creazione di macchine virtuali
Per testare l'applicazione, sarà sufficiente creare due macchine virtuali: la prima ci servirà per costruire e avviare l'applicazione, la seconda per avviare Kafka, che utilizzeremo per memorizzare i messaggi in arrivo. Creeremo anche un'altra macchina, dove configureremo Prometheus per il monitoraggio dell'applicazione.
Le macchine virtuali saranno configurate utilizzando Ansible, quindi prima di avviare Terraform assicurati di avere installata una delle ultime versioni di Ansible. Installa anche i ruoli necessari da Ansible Galaxy:
vozerov@mba:~/events/terraform (master) $ cd ../ansible/
vozerov@mba:~/events/ansible (master) $ ansible-galaxy install -r requirements.yml
- cloudalchemy-prometheus (master) è già installato, salto.
- cloudalchemy-grafana (master) è già installato, salto.
- sansible.kafka (master) è già installato, salto.
- sansible.zookeeper (master) è già installato, salto.
- geerlingguy.docker (master) è già installato, salto.
vozerov@mba:~/events/ansible (master) $Dentro la cartella Ansible c'è un esempio di file di configurazione .ansible.cfg che utilizzo. Potrebbe tornare utile.
Prima di creare le macchine virtuali, assicurati che l'ssh-agent sia in esecuzione e che la chiave ssh sia stata aggiunta, altrimenti Terraform non riuscirà a connettersi alle macchine create. Naturalmente, ho incontrato un bug in OS X: . Per evitare che la stessa situazione si ripeta, aggiungete una piccola variabile nell'env prima di avviare Terraform:
vozerov@mba:~/events/terraform (master) $ export OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YESNella cartella di Terraform, creiamo le risorse necessarie:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_compute_instance.build -target yandex_compute_instance.monitoring -target yandex_compute_instance.kafka
yandex_vpc_network.internal: Aggiornamento stato... [id=enp2g2rhile7gbqlbrkr]
data.yandex_compute_image.ubuntu_image: Aggiornamento stato...
yandex_vpc_subnet.internal-a: Aggiornamento stato... [id=e9b1dad6mgoj2v4funog]
È stato generato un piano di esecuzione, riportato di seguito.
Le azioni delle risorse sono indicate con i seguenti simboli:
+ crea
... saltato ...
Piano: 3 da aggiungere, 0 da cambiare, 0 da distruggere.
... saltato ...Se tutto è andato a buon fine (e così deve essere), avremo tre macchine virtuali:
- build — una macchina per testare e costruire l'applicazione. Docker è stato installato automaticamente dall'ansible.
- monitoring — una macchina per il monitoraggio — su di essa sono stati installati prometheus & grafana. Login / password standard: admin / admin
- kafka — una piccola macchina con kafka installato, accessibile sulla porta 9092.
Verifichiamo che siano tutte al loro posto:
vozerov@mba:~/events (master) $ yc compute instance list
+----------------------+------------+---------------+---------+---------------+-------------+
| ID | NAME | ZONE ID | STATUS | EXTERNAL IP | INTERNAL IP |
+----------------------+------------+---------------+---------+---------------+-------------+
| fhm081u8bkbqf1pa5kgj | monitoring | ru-central1-a | RUNNING | 84.201.159.71 | 172.16.1.35 |
| fhmf37k03oobgu9jmd7p | kafka | ru-central1-a | RUNNING | 84.201.173.41 | 172.16.1.31 |
| fhmt9pl1i8sf7ga6flgp | build | ru-central1-a | RUNNING | 84.201.132.3 | 172.16.1.26 |
+----------------------+------------+---------------+---------+---------------+-------------+ Le risorse sono disponibili e da qui possiamo estrarre i loro indirizzi IP. Da qui in poi utilizzerò gli indirizzi IP per connettermi tramite SSH e testare l'applicazione. Se hai un'account su Cloudflare collegato a Terraform, sentiti libero di utilizzare i nomi DNS appena creati.
A proposito, quando si crea una macchina virtuale, viene fornito un indirizzo IP interno e un nome DNS interno, così si può accedere ai server all'interno della rete per nome:
ubuntu@build:~$ ping kafka.ru-central1.internal
PING kafka.ru-central1.internal (172.16.1.31) 56(84) bytes of data.
64 bytes from kafka.ru-central1.internal (172.16.1.31): icmp_seq=1 ttl=63 time=1.23 ms
64 bytes from kafka.ru-central1.internal (172.16.1.31): icmp_seq=2 ttl=63 time=0.625 ms
^C
--- kafka.ru-central1.internal ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.625/0.931/1.238/0.308 msQuesto sarà utile per indicare all'applicazione l'endpoint di Kafka.
Costruiamo l'applicazione
Ottimo, abbiamo i server e l'applicazione — ora resta solo da compilarla e pubblicarla. Per la compilazione utilizzeremo un normale docker build, mentre come repository delle immagini utilizzeremo il servizio di Yandex — container registry. Ma andiamo con ordine.
Copiamo l'applicazione sulla macchina di build, accediamo via ssh e compiliamo l'immagine:
vozerov@mba:~/events/terraform (master) $ cd ..
vozerov@mba:~/events (master) $ rsync -av app/ ubuntu@84.201.132.3:app/
... saltato ...
inviati 3849 byte ricevuti 70 byte 7838.00 byte/sec
dimensione totale 3644 velocità di aumento 0.93
vozerov@mba:~/events (master) $ ssh 84.201.132.3 -l ubuntu
ubuntu@build:~$ cd app
ubuntu@build:~/app$ sudo docker build -t app .
Invio del contesto di build al daemon Docker 6.144kB
Passaggio 1/9 : FROM golang:latest AS build
... saltato ...
Compilazione completata con successo 9760afd8ef65
Tag app:latest creato con successoFatto metà del lavoro — ora possiamo verificare che l'applicazione funzioni, avviandola e collegandola a kafka:
ubuntu@build:~/app$ sudo docker run --name app -d -p 8080:8080 app /app/app -kafka=kafka.ru-central1.internal:9092Dalla macchina locale possiamo inviare un evento di prova e osservare la risposta:vozerov@mba:~/events (master) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://84.201.132.3:8080/post HTTP/1.1 200 OK Content-Type: application/json Date: Lun, 13 Apr 2020 13:53:54 GMT Content-Length: 41 {"status":"ok","partition":0,"Offset":0} vozerov@mba:~/events (master) $
L'applicazione ha risposto con successo alla registrazione, indicando l'id della partizione e l'offset in cui è stato inserito il messaggio. Non resta che creare un registry in Yandex.Cloud e caricarvi la nostra immagine (come fare utilizzando tre righe è descritto nel file registry.tf). Creiamo lo storage:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_container_registry.events
... saltato ...
Piano: 1 da aggiungere, 0 da modificare, 0 da distruggere.
... saltato ...
Applicazione completata! Risorse: 1 aggiunta, 0 modificate, 0 distrutte.Per l'autenticazione nel container registry ci sono diversi metodi — utilizzando un token oauth, un token iam o una chiave di un account di servizio. Maggiori dettagli su questi metodi — nella documentazione . Utilizzeremo la chiave dell'account di servizio, quindi creiamo l'account:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_iam_service_account.docker -target yandex_resourcemanager_folder_iam_binding.puller -target yandex_resourcemanager_folder_iam_binding.pusher
... saltato ...
Applicazione completata! Risorse: 3 aggiunte, 0 modificate, 0 distrutte.Ora rimane da creare la chiave:
vozerov@mba:~/events/terraform (master) $ yc iam key create --service-account-name docker -o key.json
id: ajej8a06kdfbehbrh91p
service_account_id: ajep6d38k895srp9osij
created_at: "2020-04-13T14:00:30Z"
key_algorithm: RSA_2048Otteniamo informazioni sull'id del nostro storage, trasferiamo la chiave e ci autentichiamo:
vozerov@mba:~/events/terraform (master) $ scp key.json ubuntu@84.201.132.3:
key.json 100% 2392 215.1KB/s 00:00
vozerov@mba:~/events/terraform (master) $ ssh 84.201.132.3 -l ubuntu
ubuntu@build:~$ cat key.json | sudo docker login --username json_key --password-stdin cr.yandex
AVVISO! La tua password sarà memorizzata in chiaro in /home/ubuntu/.docker/config.json.
Configura un helper per le credenziali per rimuovere questo avviso. Vedi
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Accesso riuscito
ubuntu@build:~$Per caricare l'immagine nel registro ci servirà l'ID del container registry, lo prendiamo dall'utility yc:
vozerov@mba:~ $ yc container registry get events
id: crpdgj6c9umdhgaqjfmm
folder_id:
name: events
status: ATTIVO
created_at: "2020-04-13T13:56:41.914Z"Dopo di ciò, etichettiamo la nostra immagine con un nuovo nome e carichiamo:
ubuntu@build:~$ sudo docker tag app cr.yandex/crpdgj6c9umdhgaqjfmm/events:v1
ubuntu@build:~$ sudo docker push cr.yandex/crpdgj6c9umdhgaqjfmm/events:v1
Il caricamento si riferisce al repository [cr.yandex/crpdgj6c9umdhgaqjfmm/events]
8c286e154c6e: Caricato
477c318b05cb: Caricato
beee9f30bc1f: Caricato
v1: digest: sha256:1dd5aaa9dbdde2f60d833be0bed1c352724be3ea3158bcac3cdee41d47c5e380 dimensione: 946Possiamo assicurarci che l'immagine sia stata caricata con successo:
vozerov@mba:~/events/terraform (master) $ yc container repository list
+----------------------+-----------------------------+
| ID | NAME |
+----------------------+-----------------------------+
| crpe8mqtrgmuq07accvn | crpdgj6c9umdhgaqjfmm/events |
+----------------------+-----------------------------+Inoltre, se installate l'utility yc su una macchina con Linux, potete usare il comando
yc container registry configure-dockerper configurare Docker.
Conclusione
Abbiamo fatto un grande e difficile lavoro e il risultato è stato:
- Abbiamo ideato l'architettura del nostro futuro servizio.
- Abbiamo scritto un'applicazione in Golang che implementa la nostra logica aziendale.
- L'abbiamo costruita e pubblicata in un container registry privato.
Nella prossima parte passeremo a qualcosa di interessante — pubblicheremo la nostra applicazione in produzione e la testeremo finalmente. Non cambiate canale!
Questo materiale è disponibile come registrazione video del workshop aperto REBRAIN & Yandex.Cloud: Gestiamo 10.000 richieste al secondo su Yandex Cloud —
Se vi interessa partecipare a eventi simili online e fare domande in tempo reale, unitevi a.
Un ringraziamento particolare va a Yandex.Cloud per la possibilità di organizzare un evento del genere. Ecco il link per loro —
Se hai bisogno di migrare al cloud o hai domande sulla tua infrastruttura, .
P.S. Abbiamo 2 audit gratuiti al mese, e magari il tuo progetto sarà tra questi.
Fonte: habr.com
