


L'articolo affronta il problema della pulizia delle immagini accumulate nei registri dei container (Docker Registry e suoi analoghi) nel contesto degli attuali pipeline CI/CD per applicazioni cloud native distribuite su Kubernetes. Vengono presentati i principali criteri di rilevanza delle immagini e le conseguenti difficoltà nell'automatizzazione della pulizia, del risparmio di spazio e della soddisfazione delle esigenze dei team. Infine, attraverso un esempio di un progetto Open Source specifico, spiegheremo come superare queste difficoltà.
Introduzione
Il numero di immagini nel registro dei container può crescere rapidamente, occupando più spazio di archiviazione e, di conseguenza, aumentando significativamente i costi. Per controllare, limitare o mantenere una crescita accettabile dello spazio occupato nel registry, è consuetudine:
- utilizzare un numero fisso di tag per le immagini;
- pulire le immagini in qualche modo.
La prima limitazione è talvolta accettabile per piccoli team. Se agli sviluppatori bastano tag fissi (latest, main, test, boris e così via), il registro non si gonfierà e per lungo tempo non sarà necessario pensare alla pulizia. Infatti, tutte le immagini non più attuali vengono sovrascritte e non resta lavoro da fare per la pulizia (tutto viene gestito dal garbage collector standard).
Tuttavia, questo approccio limita fortemente lo sviluppo ed è raramente applicabile ai progetti CI/CD moderni. Una parte essenziale dello sviluppo è diventata automazione, che consente di testare, distribuire e fornire nuove funzionalità agli utenti in modo molto più veloce. Ad esempio, in tutti i nostri progetti viene automaticamente creato un pipeline CI ad ogni commit. In essa viene creato un'immagine, testata, distribuita in vari ambienti Kubernetes per debugging e controlli rimanenti, e se va tutto bene — le modifiche raggiungono l'utente finale. E non è più una rocket science, ma una consuetudine per molti — probabilmente anche per voi, dato che state leggendo questo articolo.
Poiché la correzione dei bug e lo sviluppo di nuove funzionalità avviene in parallelo, e i rilasci possono essere effettuati più volte al giorno, è evidente che il processo di sviluppo è accompagnato da un numero significativo di commit, il che significa — con un gran numero di immagini nel registry. Di conseguenza, emerge la questione di come organizzare una pulizia efficace del registry, cioè la rimozione delle immagini obsolete.
Ma come possiamo davvero determinare se un'immagine è ancora attuale?
Criteri di attualità dell'immagine
Nella stragrande maggioranza dei casi, i principali criteri saranno i seguenti:
1. Il primo (il più ovvio e critico di tutti) sono le immagini che sono attualmente utilizzate in Kubernetes. La rimozione di queste immagini potrebbe portare a costi significativi a causa dei tempi di inattività della produzione (ad esempio, le immagini potrebbero essere necessarie durante la replica) o vanificare gli sforzi del team che si occupa del debug su uno dei contorni. (Per questa ragione abbiamo persino creato un , che monitora l'assenza di tali immagini in qualsiasi cluster Kubernetes.)
2. Il secondo (meno ovvio, ma ancora molto importante e nuovamente relativo all'operatività) sono le immagini che sono necessarie per il rollback in caso di gravi problemi. nella versione attuale. Ad esempio, nel caso di Helm, si tratta delle immagini utilizzate nelle versioni salvate del rilascio. (A proposito, di default in Helm c'è un limite di 256 revisioni, ma difficilmente qualcuno ha davvero bisogno di salvarle molteplici versioni? ..) questo Dopotutto, noi, in particolare, memorizziamo le versioni affinché possano essere utilizzate in seguito, cioè per «tornare» a esse in caso di necessità.
3. Il terzo — le esigenze degli sviluppatori: tutte le immagini che sono correlate ai loro lavori attuali. Ad esempio, se consideriamo una PR, ha senso mantenere l'immagine corrispondente all'ultimo commit e, diciamo, al commit precedente: in questo modo lo sviluppatore potrà tornare rapidamente a qualsiasi attività e lavorare con le ultime modifiche.
4. Il quarto — le immagini che corrispondono alle versioni della nostra applicazione, cioè sono il prodotto finale: v1.0.0, 20.04.01, sierra, ecc.
NB: I criteri qui definiti sono stati elaborati sulla base dell'esperienza acquisita interagendo con decine di team di sviluppo provenienti da diverse aziende. Tuttavia, a seconda delle peculiarità nei processi di sviluppo e delle infrastrutture utilizzate (ad esempio, se Kubernetes non è in uso), questi criteri possono differire.
Criteri di conformità e soluzioni esistenti
I servizi popolari con container registry di solito offrono le proprie politiche di pulizia delle immagini: in esse puoi definire le condizioni in base alle quali un tag viene rimosso dal registry. Tuttavia, le possibilità di queste condizioni sono limitate a parametri come nomi, data di creazione e numero di tag*.
* Dipende dalle specifiche implementazioni del container registry. Abbiamo esaminato le funzionalità delle seguenti soluzioni: Azure CR, Docker Hub, ECR, GCR, GitHub Packages, GitLab Container Registry, Harbor Registry, JFrog Artifactory, Quay.io — al settembre 2020.
Un insieme di parametri del genere è più che sufficiente per soddisfare il quarto criterio, cioè quello di selezionare le immagini corrispondenti alle versioni. Tuttavia, per tutti gli altri criteri è necessario optare per una soluzione compromissoria (una politica più rigorosa o, al contrario, più indulgente), a seconda delle aspettative e delle risorse finanziarie.
Ad esempio, il terzo criterio, relativo alle esigenze degli sviluppatori, può essere affrontato attraverso l'organizzazione dei processi all'interno dei team: una denominazione specifica delle immagini, la gestione di liste di autorizzazione speciali e accordi interni. Ma alla fine è comunque necessario automatizzarlo. E se le soluzioni pronte non sono sufficienti, bisogna crearne di proprie.
La situazione è simile per i primi due criteri: non possono essere soddisfatti senza ricevere dati da un sistema esterno, quello in cui avviene il deployment delle applicazioni (nel nostro caso, Kubernetes).
Illustrazione del workflow in Git
Supponiamo che lavoriate più o meno secondo questo schema in Git:
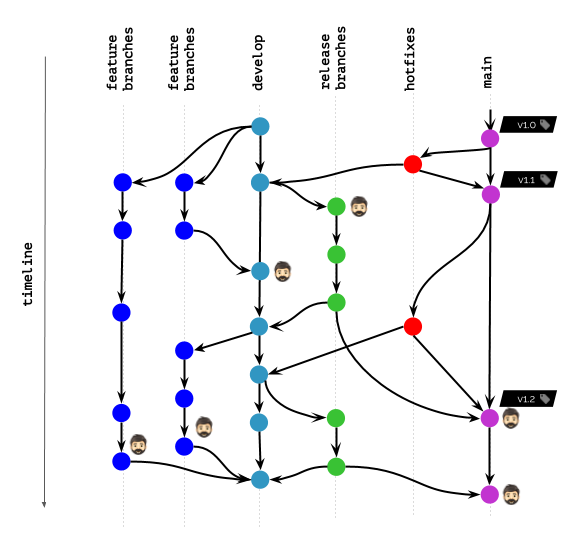
L'icona con la testa nello schema indica le immagini dei container che attualmente sono distribuite in Kubernetes per alcuni utenti (utenti finali, tester, manager, ecc.) o utilizzate dagli sviluppatori per il debug e scopi simili.
Cosa succederà se le politiche di pulizia consentono di mantenere (non eliminare) le immagini solo in base ai nomi dei tag specificati?
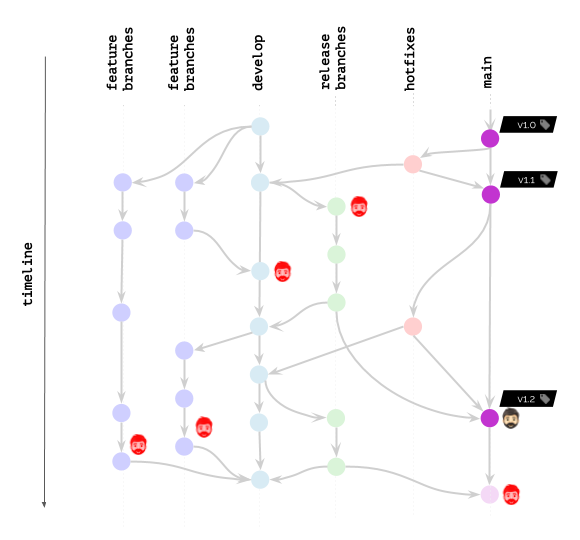
Ovviamente, uno scenario del genere non farà felice nessuno.
Cosa cambierà se le politiche consentono di non eliminare le immagini in base a un intervallo di tempo specifico / al numero degli ultimi commit?
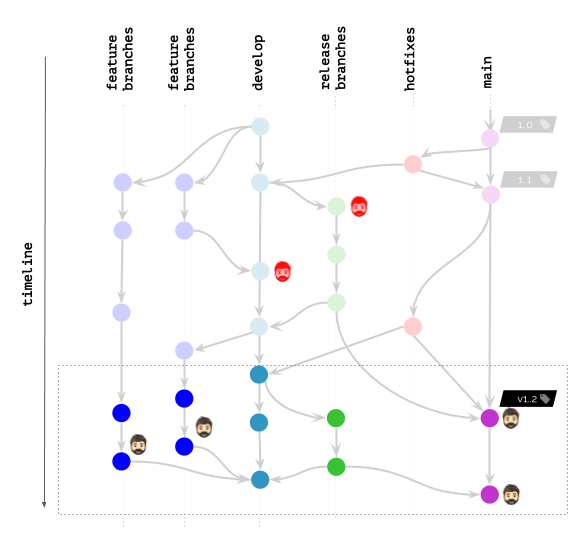
Il risultato è migliorato notevolmente, ma è comunque lontano dall'ideale. Infatti, abbiamo ancora sviluppatori che necessitano di immagini nel registro (o addirittura distribuite in K8s) per il debug dei bug...
Riassumendo la situazione attuale del mercato: le funzioni disponibili nei registri dei container non offrono la flessibilità necessaria nella pulizia, e la ragione principale è che non c'è possibilità di interagire con il mondo esterno. Dunque, i team che necessitano di tale flessibilità sono costretti a implementare autonomamente la rimozione delle immagini "dall'esterno", utilizzando l'API Docker Registry (o l'API nativa della relativa implementazione).
Tuttavia, stavamo cercando una soluzione universale che automatizzasse la pulizia delle immagini per diversi team che utilizzano registri diversi…
Il nostro percorso verso una pulizia universale delle immagini
Da dove proviene questa esigenza? Il fatto è che non siamo solo un gruppo di sviluppatori, ma un team che supporta molti di questi, aiutando a risolvere integralmente le questioni del CI/CD. E il principale strumento tecnico per fare ciò è un'utilità Open Source . La sua caratteristica principale è che non svolge una sola funzione, ma accompagna i processi di consegna continua in tutte le fasi: dalla costruzione al deployment.
La pubblicazione nel registro* delle immagini (subito dopo la loro costruzione) è una funzione ovvia di tale utilità. E poiché le immagini vengono archiviate, se il vostro deposito non è illimitato, è necessario occuparsi anche della loro successiva pulizia. Di come abbiamo avuto successo in questo, soddisfacendo tutti i criteri stabiliti, sarà parlato successivamente.
* Anche se i registry possono variare (Docker Registry, GitLab Container Registry, Harbor, ecc.), gli utenti affrontano gli stessi problemi. La soluzione universale nel nostro caso non dipende dall'implementazione del registry, poiché viene eseguita al di fuori dei registry stessi e offre un comportamento uniforme per tutti.
Sebbene utilizziamo werf come esempio di implementazione, speriamo che gli approcci usati possano essere utili anche ad altre squadre che si trovano ad affrontare difficoltà simili.
Quindi, ci siamo occupati di un'implementazione esterna del meccanismo per la pulizia delle immagini — invece delle funzionalità già integrate nei registry per i container. Il primo passo è stato utilizzare l'API di Docker Registry per creare le stesse politiche primitive riguardo al numero di tag e al loro tempo di creazione (menzionate sopra). A queste è stata aggiunta una lista di autorizzazione basata sulle immagini utilizzate nell'infrastruttura distribuita, cioè Kubernetes. Per quest'ultimo, è stato sufficiente scorrere tutte le risorse distribuite tramite l'API di Kubernetes e ottenere un elenco di valori. image.
Questa soluzione banale ha risolto il problema più critico (criterio n. 1), ma è stata solo l'inizio del nostro percorso di miglioramento del meccanismo di pulizia. Il passo successivo — e molto più interessante — è stato la soluzione per collegare le immagini pubblicate alla storia di Git.
Schemi di tagging
Per iniziare, abbiamo scelto un approccio in cui l'immagine finale deve conservare le informazioni necessarie per la pulizia e abbiamo strutturato il processo sugli schemi di tagging. Durante la pubblicazione dell'immagine, l'utente sceglieva un'opzione di tagging specifica (git-branch, git-commit o git-tag) e utilizzava il valore corrispondente. Nelle CI systems, l'impostazione di questi valori veniva eseguita automaticamente sulla base delle variabili d'ambiente. In sostanza l'immagine finale veniva collegata a un determinato primitivo Git, conservando i dati necessari per la pulizia nelle etichette.
Con questo approccio è stato creato un insieme di politiche che permetteva di utilizzare Git come unica fonte di verità:
- Quando un ramo/tag veniva eliminato in Git, anche le immagini associate venivano automaticamente rimosse dal registry.
- Il numero di immagini associate ai tag Git e ai commit poteva essere regolato dal numero di tag utilizzati nello schema selezionato e dal momento della creazione del commit associato.
In generale, la realizzazione risultante soddisfava le nostre esigenze, ma presto ci aspettava una nuova sfida. Infatti, durante l'uso degli schemi di tagging basati sui primitivi di Git, abbiamo riscontrato alcuni svantaggi. (Poiché la loro descrizione esula dall'argomento di questo articolo, tutti coloro che sono interessati possono trovare i dettagli .) Pertanto, decidendo di passare a un approccio di tagging più efficace (content-based tagging), abbiamo dovuto rivedere anche l'implementazione della pulizia delle immagini.
Il nuovo algoritmo
Perché? Con il tagging basato sul contenuto, ogni tag può soddisfare molti commit in Git. Nella pulizia delle immagini non si può più partire solo dall'commit in cui è stato aggiunto un nuovo tag al registro.
Per il nuovo algoritmo di pulizia, è stato deciso di abbandonare gli schemi di tagging e costruire il processo sui meta-immagini, ciascuna delle quali conserva un'associazione di:
- il commit in cui è stata eseguita la pubblicazione (indipendentemente dal fatto che l'immagine sia stata aggiunta, modificata o rimasta la stessa nel registro dei container);
- e il nostro identificatore interno corrispondente all'immagine costruita.
In altre parole, è stata garantita la connessione tra i tag pubblicati e i commit in Git.
La configurazione finale e l'algoritmo generale
Agli utenti, nella configurazione della pulizia, sono state rese disponibili le politiche mediante le quali vengono selezionate le immagini attuali. Ogni politica è definita da:
- un insieme di references, ossia i tag Git o i rami Git utilizzati durante la scansione;
- e da un limite di immagini cercate per ogni reference dell'insieme.
Per illustrare, ecco come appare la configurazione delle politiche predefinite:
cleanup:
keepPolicies:
- references:
tag: \/.*\/\
limit:
last: 10
- references:
branch: \/.*\/\
limit:
last: 10
in: 168h
operator: And
imagesPerReference:
last: 2
in: 168h
operator: And
- references:
branch: \/^(main|staging|production)$\/\
imagesPerReference:
last: 10
Questa configurazione contiene tre politiche che corrispondono alle seguenti regole:
- Mantenere l'immagine per i 10 ultimi tag Git (in base alla data di creazione del tag).
- Conservare non più di 2 immagini pubblicate nell'ultima settimana, per non più di 10 branch con attività nell'ultima settimana.
- Conservare 10 immagini per branch
main,stagingeproduzione.
L'algoritmo finale si riduce ai seguenti passaggi:
- Ottenere i manifesti dal container registry.
- Escludere le immagini utilizzate in Kubernetes, poiché sono già state selezionate, interrogando l'API di K8s.
- Scansione della cronologia di Git ed esclusione delle immagini secondo le politiche stabilite.
- Rimozione delle immagini rimanenti.
Ritornando alla nostra illustrazione, ecco cosa succede con werf:
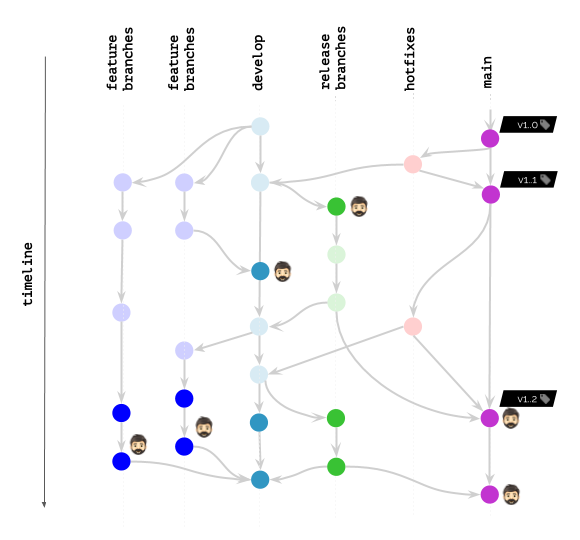
Tuttavia, anche se non si utilizza werf, un approccio simile alla pulizia avanzata delle immagini — in una forma o nell'altra (secondo l'approccio di tagging preferito delle immagini) — può essere applicato anche in altri sistemi/utilità. È sufficiente ricordare i problemi che sorgono e trovare quelle opportunità nel tuo stack che permettono di integrare la loro soluzione in modo più fluido. Ci auguriamo che il percorso che abbiamo intrapreso possa aiutarti a guardare il tuo caso specifico con nuove dettagli e pensieri.
Conclusione
- Prima o poi, la maggior parte dei team si scontra con il problema del sovraccarico del registry.
- Nella ricerca di soluzioni, è fondamentale stabilire i criteri di attualità delle immagini.
- Gli strumenti offerti dai servizi di container registry popolari consentono di organizzare una pulizia molto semplice, che non tiene conto del "mondo esterno": immagini utilizzate in Kubernetes e le peculiarità dei flussi di lavoro del team.
- Un algoritmo flessibile ed efficace deve comprendere i processi CI/CD e operare non solo con i dati delle immagini Docker.
P.S.
Leggete anche nel nostro blog:
- «»;
- «»;
- «»;
- «».
Fonte: habr.com
