

Nota di traduzione: è una traduzione di un post mortem pubblico dal blog ingegneristico dell'azienda . Descrive un problema con conntrack in un cluster Kubernetes, che ha portato a un parziale downtime di alcuni servizi di produzione.
Questo articolo può essere utile per chi desidera saperne di più sui post mortem o prevenire potenziali problemi con DNS in futuro.

Non è DNS
Non può essere che sia DNS
Era DNS
Un po' sui post mortem e i processi in Preply
Il post mortem descrive un guasto o un evento in produzione. Include una cronologia degli eventi, una descrizione dell'impatto sugli utenti, la causa principale, le azioni intraprese e le lezioni apprese.
Durante le riunioni settimanali con la pizza, nel nostro team tecnico, condividiamo diverse informazioni. Una delle parti più importanti di queste riunioni è rappresentata dai post mortem, che sono spesso accompagnati da presentazioni con diapositive e un'analisi più approfondita dell'incidente accaduto. Anche se non "applaudiamo" dopo i post mortem, cerchiamo di promuovere una cultura "senza colpe" (). Crediamo che la scrittura e la presentazione dei post-mortem possano aiutarci (e non solo) a prevenire incidenti simili in futuro, ed è proprio per questo che li condividiamo.
Le persone coinvolte nell'incidente devono sentirsi a loro agio nel raccontare i dettagli senza temere punizioni o ritorsioni. Niente biasimo! Scrivere un post-mortem non è una punizione, ma un'opportunità di apprendimento per tutta l'azienda.
Problemi DNS in Kubernetes. Post-mortem
Data: 28.02.2020
Autori: Amet U., Andrey S., Igor K., Alexey P.
Stato: Completato
In breve: Parziale inattività DNS (26 min) per alcuni servizi nel cluster Kubernetes
Impatto: 15000 eventi persi per i servizi A, B e C
Causa principale: Kube-proxy non è riuscito a rimuovere correttamente la vecchia voce dalla tabella conntrack, quindi alcuni servizi continuavano a provare a connettersi a pod inesistenti
E0228 20:13:53.795782 1 proxier.go:610] Impossibile eliminare le connessioni degli endpoint kube-system/kube-dns:dns, errore: errore nell'eliminazione delle voci conntrack per il peer UDP {100.64.0.10, 100.110.33.231}, errore: comando conntrack restiutito: ...Trigger: A causa del carico ridotto nel cluster Kubernetes, il CoreDNS-autoscaler ha ridotto il numero di pod nel deployment da tre a due
Soluzione: Un altro deployment dell'applicazione ha innescato la creazione di nuovi nodi, il CoreDNS-autoscaler ha aggiunto più pod per gestire il cluster, provocando la riscrittura della tabella conntrack
Rilevamento: Il monitoraggio di Prometheus ha rilevato un elevato numero di errori 5xx per i servizi A, B e C e ha attivato una chiamata agli ingegneri di guardia

Errori 5xx in Kibana
Azioni
Azione
Tipo
Responsabile
Compito
Disabilitare l'autoscaler per CoreDNS
prevenire
Amet U.
DEVOPS-695
Installare un server DNS cache
ridurre
Max V.
DEVOPS-665
Configurare il monitoraggio conntrack
prevenire
Amet U.
DEVOPS-674
Lezioni apprese
Cosa è andato bene:
- Il monitoraggio ha funzionato in modo chiaro. La risposta è stata rapida e organizzata
- Non siamo incappati in limiti sui nodi
Cosa non andava:
- La reale causa primaria è ancora sconosciuta, sembra essere in conntrack
- Tutte le azioni riparano solo le conseguenze, non la causa principale (bug)
- Sapevamo che prima o poi avremmo potuto avere problemi con DNS, ma non abbiamo priorizzato i compiti
Dove siamo stati fortunati:
- Un altro deployment ha attivato il CoreDNS-autoscaler, che ha riscritto la tabella conntrack
- Questo bug ha colpito solo una parte dei servizi
Cronologia (EET)
Tempo
Azione
22:13
CoreDNS-autoscaler ha ridotto il numero di pod da tre a due
22:18
Gli ingegneri di turno hanno cominciato a ricevere chiamate dal sistema di monitoraggio
22:21
Gli ingegneri di turno hanno iniziato a indagare sulle cause degli errori
22:39
Gli ingegneri di turno hanno iniziato a ripristinare uno degli ultimi servizi alla versione precedente
22:40
Gli errori 5xx hanno smesso di comparire, la situazione si è stabilizzata
- Tempo fino alla rilevazione: 4 min
- Tempo fino all'azione: 21 min
- Tempo fino alla correzione: 1 min
Informazioni aggiuntive
- Log di CoreDNS:
I0228 20:13:53.507780 1 event.go:221] Evento(v1.ObjectReference{Kind:"Deployment", Namespace:"kube-system", Name:"coredns", UID:"2493eb55-3dc0-11ea-b3a2-02bb48f8c230", APIVersion:"apps/v1", ResourceVersion:"132690686", FieldPath:""}): tipo: 'Normale' motivo: 'ScalingReplicaSet' Replica set coredns-6cbb6646c9 ridotto a 2 - Link a Kibana (rimosso), Grafana (rimosso)
Per minimizzare l'uso della CPU, il kernel Linux utilizza una cosa chiamata conntrack. In breve, è un'utilità che mantiene un elenco di registrazioni NAT, conservate in una tabella speciale. Quando il prossimo pacchetto arriva dallo stesso pod allo stesso pod di prima, l'indirizzo IP finale non verrà ricalcolato, ma verrà preso dalla tabella conntrack.
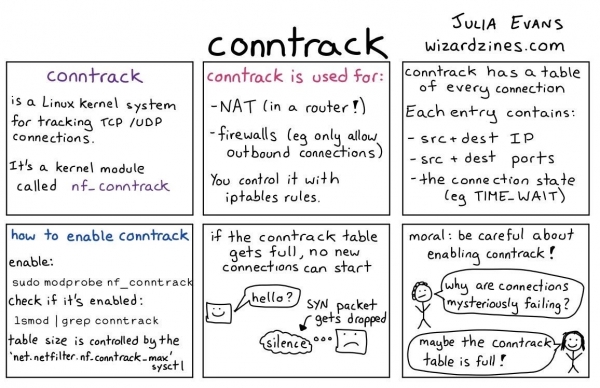
Come funziona conntrack
Risultati
Questo è stato un esempio di uno dei nostri post-mortem con alcuni link utili. In questo articolo condividiamo informazioni che potrebbero essere utili ad altre aziende. È per questo che non abbiamo paura di commettere errori e per questo motivo abbiamo reso pubblico uno dei nostri post-mortem. Ecco altri interessanti post-mortem pubblici:
- GitLab:
- Dropbox:
- Spotify:
- Molti altri di e repository
- Inoltre post-mortem pubblico con il SRE Book
Fonte: habr.com
