


Ho caricato su Github .
Questa è una semplice tabella hash per GPU, in grado di gestire centinaia di milioni di inserimenti al secondo. Sul mio laptop con NVIDIA GTX 1060, il codice inserisce circa 64 milioni di coppie chiave-valore generate casualmente in circa 210 ms e rimuove 32 milioni di coppie in circa 64 ms.
Quindi, la velocità sul laptop è di circa 300 milioni di inserimenti/secondo e 500 milioni di rimozioni/secondo.
La tabella è scritta in CUDA, ma la stessa metodologia può essere applicata a HLSL o GLSL. L'implementazione presenta alcune limitazioni che assicurano alte prestazioni sulla scheda grafica:
- Vengono elaborati solo chiavi e valori a 32 bit.
- La tabella hash ha una dimensione fissa.
- E questa dimensione deve essere uguale a una potenza di due.
Per le chiavi e i valori è necessario riservare un semplice marcatore di separazione (nel codice fornito è 0xffffffff).
Tabella hash senza blocchi
Nella tabella hash si utilizza l'indirizzamento aperto con , ovvero è semplicemente un array di coppie chiave-valore, che viene memorizzato in memoria e offre un'ottima prestazione della cache. Questo non è vero per il chaining, che implica la ricerca di un puntatore in una lista collegata. Una tabella hash è un semplice array che memorizza gli elementi. KeyValue:
struct KeyValue
{
uint32_t key;
uint32_t value;
};
La dimensione della tabella è una potenza di due, e non un numero primo, perché per applicare una maschera pow2/AND è suffissa una rapida istruzione, mentre l'operatore modulo è molto più lento. Questo è importante nel caso di sondaggio lineare, poiché quando si effettua una ricerca lineare nella tabella, l'indice della slot deve essere avvolto in ogni slot. E di conseguenza, viene aggiunto il costo dell'operazione modulo in ogni slot.
La tabella memorizza solo la chiave e il valore per ciascun elemento, e non l'hash della chiave. Poiché la tabella memorizza solo chiavi a 32 bit, l'hash viene calcolato molto rapidamente. Nel codice fornito viene utilizzato l'hash Murmur3, che esegue solo alcuni spostamenti, XOR e moltiplicazioni.
Nella tabella hash viene applicata una tecnica di protezione dai blocchi che non dipende dall'ordine di memorizzazione in memoria. Anche se alcune operazioni di scrittura violano la sequenza di altre operazioni, la tabella hash manterrà comunque uno stato corretto. Ne parleremo più avanti. Questa tecnica funziona perfettamente con le schede grafiche in cui migliaia di thread vengono eseguiti in parallelo.
Le chiavi e i valori nella tabella hash vengono inizializzati come vuoti.
Il codice può essere modificato per gestire sia chiavi che valori a 64 bit. Per le chiavi sono necessarie operazioni atomiche di lettura, scrittura e confronto con scambio (compare-and-swap). Per i valori sono necessarie operazioni atomiche di lettura e scrittura. Fortunatamente, in CUDA le operazioni di lettura-scrittura per valori a 32 e 64 bit sono atomiche fintanto che sono allineate in modo naturale (vedi ), e le moderne schede grafiche supportano operazioni atomiche a 64 bit per il confronto e lo scambio. Naturalmente, passando a 64 bit, le prestazioni diminuiscono leggermente.
Stato della tabella hash
Ogni coppia chiave-valore nella tabella hash può avere uno dei quattro stati:
- La chiave e il valore sono vuoti. In questo stato, la tabella hash viene inizializzata.
- La chiave è stata scritta, ma il valore non ancora. Se un altro thread sta leggendo i dati in questo momento, restituirà un valore vuoto. Questo è normale; lo stesso accadrebbe se un altro thread avesse eseguito prima, dato che stiamo parlando di una struttura dati concorrente.
- Sia la chiave che il valore sono stati scritti.
- Il valore è disponibile per altri thread, mentre la chiave non lo è ancora. Questo può accadere perché il modello di programmazione in CUDA implica un modello di memoria debolmente ordinata. Questo è normale, in ogni caso la chiave è ancora vuota, anche se il valore non lo è più.
Un punto importante è che, una volta che la chiave è stata scritta nello slot, essa non viene più spostata — anche se la chiave viene rimossa, ne parleremo più avanti.
Il codice della tabella hash funziona anche con modelli di memoria debolmente ordinati, in cui non si conosce l'ordine di lettura e scrittura in memoria. Quando discuteremo di inserimenti, ricerche e cancellazioni nella tabella hash, ricordate che ogni coppia chiave-valore si trova in uno dei quattro stati sopra descritti.
Inserimento in una tabella hash
La funzione CUDA che inserisce coppie chiave-valore nella tabella hash appare nel seguente modo:
void gpu_hashtable_insert(KeyValue* hashtable, uint32_t key, uint32_t value)
{
uint32_t slot = hash(key);
while (true)
{
uint32_t prev = atomicCAS(&hashtable[slot].key, kEmpty, key);
if (prev == kEmpty || prev == key)
{
hashtable[slot].value = value;
break;
}
slot = (slot + 1) & (kHashTableCapacity-1);
}
}
Per inserire la chiave, il codice itera attraverso l'array della tabella hash a partire dall'hash della chiave da inserire. In ogni slot dell'array viene eseguita un'operazione atomica di confronto e scambio, in cui la chiave in questo slot viene confrontata con il valore vuoto. Se viene trovata una discrepanza, la chiave nello slot viene aggiornata con la chiave da inserire, e poi viene restituita la chiave originale dello slot. Se questa chiave originale era vuota o corrispondeva alla chiave da inserire, significa che il codice ha trovato uno slot idoneo per l'inserimento e vi inserisce il valore.
Se in una singola chiamata al kernel gpu_hashtable_insert() Ci sono diversi elementi con la stessa chiave, quindi qualsiasi valore di essi può essere scritto nello slot della chiave. Questo è considerato normale: una delle operazioni di scrittura chiave-valore durante la chiamata avrà successo, ma poiché tutto ciò avviene in parallelo all'interno di più thread di esecuzione, non possiamo prevedere quale operazione di scrittura in memoria sarà l'ultima.
Ricerca nella tabella hash
Codice per cercare chiavi:
uint32_t gpu_hashtable_lookup(KeyValue* hashtable, uint32_t key)
{
uint32_t slot = hash(key);
while (true)
{
if (hashtable[slot].key == key)
{
return hashtable[slot].value;
}
if (hashtable[slot].key == kEmpty)
{
return kEmpty;
}
slot = (slot + 1) & (kHashTableCapacity - 1);
}
}
Per trovare il valore di una chiave memorizzata nella tabella, itereamo attraverso l'array a partire dall'hash della chiave cercata. In ogni slot controlliamo se la chiave è quella che stiamo cercando e, se sì, restituiamo il suo valore. Controlliamo anche se la chiave è vuota e, se sì, interrompiamo la ricerca.
Se non riusciamo a trovare la chiave, il codice restituisce un valore vuoto.
Tutte queste operazioni di ricerca possono essere eseguite in modo concorrente durante le inserzioni e le cancellazioni. Ogni coppia nella tabella avrà per il thread uno dei quattro stati sopra descritti.
Cancellazione nella tabella hash
Codice per la cancellazione delle chiavi:
void gpu_hashtable_delete(KeyValue* hashtable, uint32_t key, uint32_t value)
{
uint32_t slot = hash(key);
while (true)
{
if (hashtable[slot].key == key)
{
hashtable[slot].value = kEmpty;
return;
}
if (hashtable[slot].key == kEmpty)
{
return;
}
slot = (slot + 1) & (kHashTableCapacity - 1);
}
}
La cancellazione di una chiave avviene in modo atipico: lasciamo la chiave nella tabella e segniamo il suo valore (non la chiave stessa) come vuoto. Questo codice è molto simile a lookup(), tranne per il fatto che, al momento della corrispondenza della chiave, rende il suo valore vuoto.
Come accennato in precedenza, una volta che la chiave è stata scritta nello slot, non si sposta più. Anche quando un elemento viene cancellato dalla tabella, la chiave rimane al suo posto; il suo valore diventa semplicemente vuoto. Ciò significa che non dobbiamo utilizzare un'operazione atomica per scrivere il valore dello slot, poiché non importa se il valore corrente è vuoto o meno: diventerà comunque vuoto.
Ridimensionamento della tabella hash
La dimensione della tabella hash può essere modificata creando una tabella più grande e inserendo in essa gli elementi non vuoti dalla tabella precedente. Non ho implementato questa funzionalità perché volevo mantenere il campione di codice semplice. Inoltre, nelle applicazioni CUDA, l'allocazione della memoria viene spesso eseguita nel codice host, e non nel kernel CUDA.
Nell'articolo descrive come modificare una struttura dati del genere, protetta da blocchi.
Concorrenza
Nei frammenti di codice sopra riportati, le funzioni gpu_hashtable_insert(), _lookup() e _delete() gestiscono una coppia chiave-valore alla volta. Sotto, gpu_hashtable_insert(), _lookup() e _delete() gestiscono un array di coppie in parallelo, ogni coppia in un singolo thread GPU:
// CPU code to invoke the CUDA kernel on the GPU
uint32_t threadblocksize = 1024;
uint32_t gridsize = (numkvs + threadblocksize - 1) / threadblocksize;
gpu_hashtable_insert_kernel<<<gridsize, threadblocksize>>>(hashtable, kvs, numkvs);
// GPU code to process numkvs key/values in parallel
void gpu_hashtable_insert_kernel(KeyValue* hashtable, const KeyValue* kvs, unsigned int numkvs)
{
unsigned int threadid = blockIdx.x*blockDim.x + threadIdx.x;
if (threadid < numkvs)
{
gpu_hashtable_insert(hashtable, kvs[threadid].key, kvs[threadid].value);
}
}
Una tabella hash protetta da blocchi supporta inserimenti, ricerche e cancellazioni concorrenti. Poiché le coppie chiave-valore si trovano sempre in uno dei quattro stati e le chiavi non si spostano, la tabella garantisce la correttezza anche quando varie operazioni vengono utilizzate simultaneamente.
Tuttavia, se elaboriamo parallelamente un pacchetto di inserimenti e cancellazioni e se l'array di input di coppie contiene chiavi duplicate, non saremo in grado di prevedere quali coppie 'vinceranno' e verranno scritte nell'hash table per ultime. Supponiamo di aver chiamato il codice di inserimento con un array di input di coppie. A/0 B/1 A/2 C/3 A/4. Quando il codice termina, le coppie B/1 e C/3 saranno garantite nella tabella, ma in essa si troverà qualsiasi coppia A/0, A/2 o A/4. Questo può essere un problema o meno — dipende dall'applicazione. Puoi sapere in anticipo che non ci sono chiavi duplicate nell'array di input, oppure potrebbe non importarti quale valore è stato registrato per ultimo.
Se questo è un problema per te, allora devi separare le coppie duplicate in diverse chiamate di sistema CUDA. In CUDA, qualsiasi operazione con una chiamata al kernel termina sempre prima della successiva chiamata al kernel (almeno all'interno di un singolo thread; nei thread diversi, i kernel vengono eseguiti in parallelo). Se nell'esempio sopra chiamassi un kernel con A/0 B/1 A/2 C/3, e un altro con A/4, allora la chiave A riceverà il valore 4.
Ora parliamo di se le funzioni lookup() e delete() utilizzare un puntatore semplice (plain) o volatile a un array di coppie in una tabella hash. afferma che:
Il compilatore può ottimizzare a sua discrezione le operazioni di lettura e scrittura nella memoria globale o condivisa... Tali ottimizzazioni possono essere disattivate utilizzando la parola chiave
volatile: ... ogni riferimento a questa variabile viene compilato in un'istruzione reale di lettura o scrittura in memoria.
Le considerazioni di correttezza non richiedono l'applicazione volatile. Se un thread di esecuzione utilizza un valore memorizzato da un'operazione di lettura precedente, ciò significa che utilizzerà qualche informazione leggermente obsoleta. Tuttavia, si tratta di informazioni provenienti da uno stato valido della tabella hash in un dato momento della chiamata al kernel. Se hai bisogno di utilizzare le informazioni più recenti, puoi utilizzare un puntatore volatile, ma questo ridurrà leggermente le prestazioni: dai miei test, eliminando 32 milioni di elementi, la velocità è scesa da 500 milioni di eliminazioni/s a 450 milioni di eliminazioni/s.
Prestazioni
Nel test di inserimento di 64 milioni di elementi e eliminazione di 32 milioni, la competizione tra std::unordered_map e la tabella hash per GPU è praticamente assente:
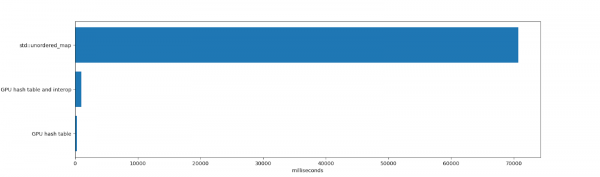
std::unordered_map ho impiegato 70.691 ms per inserire e rimuovere elementi, con successiva liberazione unordered_map (la liberazione di milioni di elementi richiede un bel po' di tempo, perché al suo interno unordered_map vengono effettuate numerose allocazioni di memoria). A dire il vero, la std:unordered_map ha limitazioni completamente diverse. Si tratta di un'unica esecuzione su thread CPU, supporta coppie chiave-valore di qualsiasi dimensione, funziona bene con elevati fattori di utilizzo e mostra prestazioni stabili dopo numerosi eliminazioni.
La durata del lavoro della tabella hash per GPU e per l'interazione tra programmi è stata di 984 ms. Questo include il tempo speso per allocare la tabella in memoria e per la sua rimozione (un'allocazione singola di 1 GB di memoria, che in CUDA richiede un certo tempo), l'inserimento e la rimozione degli elementi, nonché l'iterazione su di essi. Sono stati considerati anche tutti i copia dalla e verso la memoria della scheda grafica.
Il funzionamento della tabella hash ha richiesto 271 ms. Questo include il tempo speso dalla scheda grafica per l'inserimento e la rimozione degli elementi, senza considerare il tempo per la copia in memoria e l'iterazione sulla tabella risultante. Se la tabella GPU rimane attiva a lungo, o se la tabella hash è interamente contenuta nella memoria della scheda grafica (ad esempio, per creare una tabella hash che sarà utilizzata da altro codice GPU anziché dalla CPU), il risultato del test è rilevante.
La tabella hash per schede grafiche dimostra alte prestazioni grazie all'ampia larghezza di banda e alla paralizzazione attiva.
Svantaggi
L'architettura della tabella hash ha alcune problematiche da considerare:
- La clusterizzazione ostacola il sondaggio lineare, portando a una disposizione dei chiavi nella tabella non ottimale.
- Le chiavi non vengono rimosse usando la funzione
eliminae nel tempo ingombrano la tabella.
Di conseguenza, le prestazioni della tabella hash possono diminuire gradualmente, soprattutto se esiste da lungo tempo e subisce numerosi inserimenti ed eliminazioni. Uno dei modi per mitigare questi inconvenienti è il rehashing in una nuova tabella con un fattore di utilizzo sufficientemente basso e la filtrazione delle chiavi eliminate durante il rehashing.
Per illustrare i problemi descritti, utilizzerò il codice sopra per creare una tabella con 128 milioni di elementi, inserendo ciclicamente 4 milioni di elementi finché non riempio 124 milioni di slot (fattore di utilizzo circa 0,96). Ecco la tabella dei risultati, ogni riga rappresenta una chiamata al kernel CUDA con l'inserimento di 4 milioni di nuovi elementi in una tabella hash:
Fattore di utilizzo
Durata dell'inserimento di 4 194 304 elementi
0,00
11,608448 ms (361,314798 milioni di chiavi/s)
0,03
11,751424 ms (356,918799 milioni di chiavi/s)
0,06
11,942592 ms (351,205515 milioni di chiavi/s)
0,09
12,081120 ms (347,178429 milioni di chiavi/s)
0,12
12,242560 ms (342,600233 milioni di chiavi/s)
0,16
12,396448 ms (338,347235 milioni di chiavi/s)
0,19
12,533024 ms (334,660176 milioni di chiavi/s)
0,22
12,703328 ms (330,173626 milioni di chiavi/s)
0,25
12,884512 ms (325,530693 milioni di chiavi/s)
0,28
13,033472 ms (321,810182 milioni di chiavi/s)
0,31
13,239296 ms (316,807174 milioni di chiavi/sec.)
0,34
13,392448 ms (313,184256 milioni di chiavi/sec.)
0,37
13,624000 ms (307,861434 milioni di chiavi/sec.)
0,41
13,875520 ms (302,280855 milioni di chiavi/sec.)
0,44
14,126528 ms (296,909756 milioni di chiavi/sec.)
0,47
14,399328 ms (291,284699 milioni di chiavi/sec.)
0,50
14,690304 ms (285,515123 milioni di chiavi/sec.)
0,53
15,039136 ms (278,892623 milioni di chiavi/sec.)
0,56
15,478656 ms (270,973402 milioni di chiavi/sec.)
0,59
15,985664 ms (262,379092 milioni di chiavi/sec.)
0,62
16,668673 ms (251,627968 milioni di chiavi/sec.)
0,66
17,587200 ms (238,486174 milioni di chiavi/sec.)
0,69
18,690048 ms (224,413765 milioni di chiavi/sec.)
0,72
20,278816 ms (206,831789 milioni di chiavi/sec.)
0,75
22,545408 ms (186,038058 milioni di chiavi/sec.)
0,78
26,053312 ms (160,989275 milioni di chiavi/sec.)
0,81
31,895008 ms (131,503463 milioni di chiavi/sec.)
0,84
42,103294 ms (99,619378 milioni di chiavi/sec.)
0,87
61,849056 ms (67,815164 milioni di chiavi/sec.)
0,90
105,695999 ms (39,682713 milioni di chiavi/sec.)
0,94
240,204636 ms (17,461378 milioni di chiavi/sec.)
Con l'aumento del tasso di utilizzo, le prestazioni diminuiscono. Questo è indesiderabile nella maggior parte dei casi. Se un'applicazione inserisce elementi in una tabella e poi li scarta (ad esempio, nel conteggio delle parole in un libro), non è un problema. Ma se l'applicazione utilizza una tabella hash a lungo termine (ad esempio, in un editor grafico per memorizzare porzioni non vuote di immagini, quando l'utente inserisce e rimuove informazioni frequentemente), questo comportamento può causare inconvenienti.
Ho misurato la profondità di sondaggio della tabella hash dopo 64 milioni di inserimenti (tasso di utilizzo 0,5). La profondità media era di 0,4774, quindi la maggior parte delle chiavi si trovava o nella migliore posizione possibile, o a un solo slot dalla posizione ottimale. La profondità massima di sondaggio era di 60.
Successivamente, ho misurato la profondità di sondaggio in una tabella con 124 milioni di inserimenti (tasso di utilizzo 0,97). La profondità media era già di 10,1757, mentre la massima era di 6474 (!!). Le prestazioni del sondaggio lineare diminuiscono drasticamente con alti tassi di utilizzo.
È consigliabile mantenere un basso fattore di utilizzo per questa hash table. Tuttavia, ciò comporta un aumento della memoria utilizzata. Fortunatamente, nel caso di chiavi e valori a 32 bit, questo può essere giustificato. Se nel precedente esempio la tabella, che supporta 128 milioni di elementi, mantiene un fattore di utilizzo di 0,25, possiamo memorizzare al massimo 32 milioni di elementi, mentre i restanti 96 milioni di slot andranno persi — 8 byte per ogni coppia, 768 MB di memoria persa.
È importante notare che si tratta di perdita di memoria della scheda video, che è una risorsa più preziosa rispetto alla memoria di sistema. Sebbene la maggior parte delle moderne schede grafiche desktop che supportano CUDA dispongano di almeno 4 GB di memoria (al momento della scrittura, la NVIDIA 2080 Ti ha 11 GB), perdere tali quantità non sarà la scelta più saggia.
In seguito scriverò in dettaglio sulla creazione di hash table per schede grafiche che non hanno problemi di profondità di sondaggio, nonché sui modi per riutilizzare slot rimossi.
Misurazione della profondità di sondaggio
Per determinare la profondità di sondaggio della chiave, possiamo estrarre l'hash della chiave (il suo indice ideale nella tabella) dal suo effettivo indice tabellare:
// get_key_index() -> index of key in hash table
uint32_t probelength = (get_key_index(key) - hash(key)) & (hashtablecapacity-1);
A causa della magia dei due numeri binari in complemento a due e del fatto che la capacità della tabella hash è pari a due elevato alla potenza, questo approccio funzionerà anche quando l'indice della chiave viene spostato all'inizio della tabella. Prendiamo una chiave che si hash a 1, ma inserita nello slot 3. Quindi, per una tabella con capacità 4 otteniamo (3 — 1) & 3, che è equivalente a 2.
Conclusione
Se hai domande o commenti, scrivimi a o apri un nuovo argomento in.
Questo codice è stato scritto sotto l'ispirazione di articoli meravigliosi:
In futuro continuerò a scrivere sulle implementazioni delle tabelle hash per le schede grafiche e analizzerò le loro prestazioni. Nei miei piani ci sono la concatenazione, l'hashing di Robin Hood e l'hashing a cuculo utilizzando operazioni atomiche in strutture dati ottimizzate per schede grafiche.
Fonte: habr.com
