

Il pacchetto tidyr è incluso nel nucleo di una delle librerie più popolari nel linguaggio R — tidyverse.
Lo scopo principale del pacchetto è rendere i dati più ordinati.
Su Habr c'è già dedicata a questo pacchetto, ma risale al 2015. Oggi voglio parlare delle modifiche più rilevanti che il suo autore, Hadley Wickham, ha annunciato qualche giorno fa.
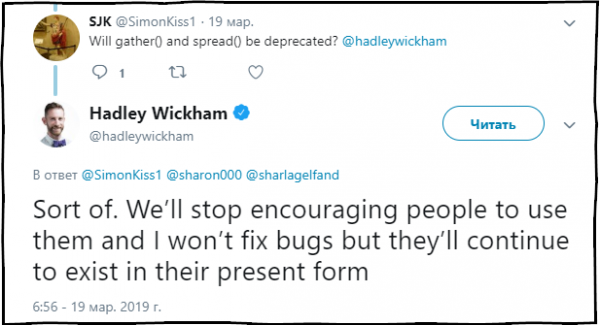
SJK: Le funzioni gather() e spread() saranno considerate obsolete?
Hadley Wickham: In parte sì. Smetteremo di consigliare l’uso di queste funzioni e correggere errori in esse, ma continueranno a essere presenti nel pacchetto nella loro attuale forma.
Contenuto
Se siete interessati all'analisi dei dati, potrebbero interessarvi i miei e canali. Gran parte dei contenuti è dedicata al linguaggio R.
Il concetto di TidyData
Obiettivo tidyr — aiutarvi a portare i dati in quello che viene chiamato un formato pulito. I dati puliti sono dati in cui:
- Ogni variabile è in una colonna.
- Ogni osservazione è una riga.
- Ogni valore è una cella.
Lavorare con dati che sono stati convertiti in dati puliti è decisamente più semplice e comodo durante l'analisi.
Funzioni principali incluse nel pacchetto tidyr
tidyr contiene un insieme di funzioni progettate per trasformare le tabelle:
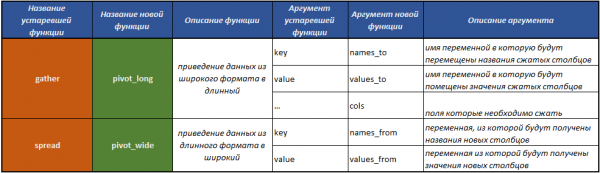
fill()— riempi i valori mancanti in una colonna con i valori precedenti;separate()— suddivide un campo in più campi utilizzando un separatore;unite()— esegue l'operazione di unione di più campi in uno, operazione inversa della funzioneseparate();pivot_longer()— funzione che trasforma i dati da un formato largo a uno lungo;pivot_wider()— funzione che trasforma i dati da un formato lungo a uno largo. Operazione inversa a quella fornita dalla funzionepivot_longer().gather()obsoleta — funzione che trasforma i dati da un formato largo a uno lungo;spread()obsoleta — funzione che trasforma i dati da un formato lungo a uno largo. Operazione inversa a quella fornita dalla funzionegather().
Nuovo concetto di trasformazione dei dati da formato largo a lungo e viceversa
In passato, per trasformazioni di questo tipo si utilizzavano funzioni gather() e spread(). Negli anni, è diventato chiaro che per la maggior parte degli utenti, incluso l'autore del pacchetto, i nomi di queste funzioni e dei loro argomenti non erano particolarmente intuitivi, causando difficoltà nel trovarli e comprendere quale di queste funzioni trasformasse un data frame da formato largo a lungo e viceversa.
Pertanto, in tidyr sono state aggiunte due nuove funzioni importanti, progettate per la trasformazione dei data frame.
Novità pivot_longer() e pivot_wider() sono state ispirate da alcune funzioni del pacchetto cdata, creato da John Mount e Nina Zumel.
Installazione dell'ultima versione di tidyr 0.8.3.9000
Per installare la versione più recente del pacchetto tidyr 0.8.3.9000, che include nuove funzioni, utilizza il seguente codice.
devtools::install_github("tidyverse/tidyr")
Al momento della scrittura di questo articolo, queste funzioni sono disponibili solo nella versione dev del pacchetto su GitHub.
Transizione verso le nuove funzioni
In realtà, non è difficile convertire i vecchi script per utilizzare le nuove funzioni; per una maggiore comprensione, prenderò un esempio dalla documentazione delle vecchie funzioni e mostrerò come queste stesse operazioni vengono eseguite usando le nuove pivot_*() funzioni.
Trasformazione da formato largo a lungo.
Esempio di codice dalla documentazione della funzione gather
# example
library(dplyr)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 0, 1),
Y = rnorm(10, 0, 2),
Z = rnorm(10, 0, 4)
)
# old
stocks_gather <- stocks %>% gather(key = stock,
value = price,
-time)
# new
stocks_long <- stocks %>% pivot_longer(cols = -time,
names_to = "stock",
values_to = "price")
Conversione da formato lungo a formato largo.
Esempio di codice dalla documentazione della funzione spread.
# old
stocks_spread <- stocks_gather %>% spread(key = stock,
value = price)
# new
stock_wide <- stocks_long %>% pivot_wider(names_from = "stock",
values_from = "price")
Poiché negli esempi precedenti si lavora con pivot_longer() e pivot_wider(), nella tabella originale stocks non ci sono colonne elencate negli argomenti names_to e values_to i loro nomi devono essere indicati tra virgolette.
Una tabella con cui sarà più semplice capire come lavorare con il nuovo concetto. tidyr.
Nota dell'autore
Tutto il testo qui di seguito è una traduzione adattiva, potrei persino dire libera. dal sito ufficiale della libreria tidyverse.
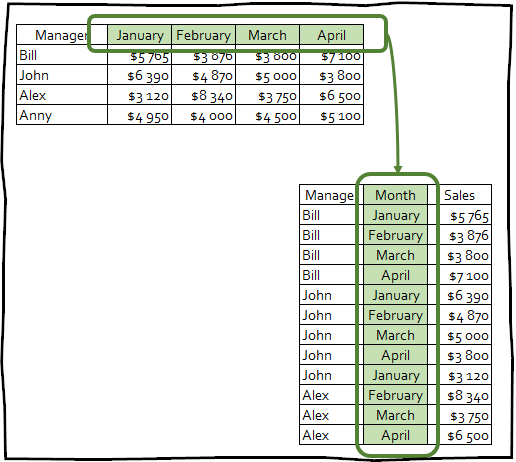
Un semplice esempio di trasformazione dei dati da formato largo a lungo
pivot_longer () rende i set di dati più lunghi, riducendo il numero di colonne e aumentando il numero di righe.
Per eseguire gli esempi presentati nell'articolo è necessario prima caricare i pacchetti richiesti:
library(tidyr)
library(dplyr)
library(readr)Supponiamo di avere una tabella con i risultati di un sondaggio, in cui (tra le altre cose) si chiedeva alle persone della loro religione e del loro reddito annuo:
#> # A tibble: 18 x 11
#> religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k`
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Agnostic 27 34 60 81 76 137
#> 2 Atheist 12 27 37 52 35 70
#> 3 Buddhist 27 21 30 34 33 58
#> 4 Catholic 418 617 732 670 638 1116
#> 5 Don’t k… 15 14 15 11 10 35
#> 6 Evangel… 575 869 1064 982 881 1486
#> 7 Hindu 1 9 7 9 11 34
#> 8 Histori… 228 244 236 238 197 223
#> 9 Jehovah… 20 27 24 24 21 30
#> 10 Jewish 19 19 25 25 30 95
#> # … with 8 more rows, and 4 more variables: `$75-100k` <dbl>,
#> # `$100-150k` <dbl>, `>150k` <dbl>, `Don't know/refused` <dbl>Questa tabella contiene dati sulla religione dei rispondenti nelle righe, mentre il livello di reddito è distribuito tra i nomi delle colonne. Il numero di rispondenti in ciascuna categoria è conservato nei valori delle celle all'incrocio tra religione e livello di reddito. Per formattare la tabella in modo ordinato e corretto, è sufficiente utilizzare pivot_longer():
pew %>%
pivot_longer(cols = -religion, names_to = "income", values_to = "count")pew %>%
pivot_longer(cols = -religion, names_to = "income", values_to = "count")
#> # A tibble: 180 x 3
#> religion income count
#>
#> 1 Agnostico 2 Agnostico 10-20k 34
#> 3 Agnostico 20-30k 60
#> 4 Agnostico 30-40k 81
#> 5 Agnostico 40-50k 76
#> 6 Agnostico 50-75k 137
#> 7 Agnostico 75-100k 122
#> 8 Agnostico 100-150k 109
#> 9 Agnostico >150k 84
#> 10 Agnostico Non so/rifiutato 96
#> # … con 170 ulteriori righeArgomenti della funzione pivot_longer()
- Primo argomento cols, descrive quali colonne devono essere unite. In questo caso, tutte le colonne tranne ora.
- Argomento names_to dà il nome alla variabile che sarà creata dagli nomi delle colonne unite.
- values_to dà il nome alla variabile che sarà creata dai dati memorizzati nei valori delle celle delle colonne unite.
Specifiche
Questa è una nuova funzionalità del pacchetto tidyr, che in precedenza non era disponibile durante l'uso di funzioni obsolete.
La specifica è un frame di dati, ogni riga del quale corrisponde a una colonna nel nuovo frame di output, e ci sono due colonne speciali che iniziano con:
- .name contiene il nome originale della colonna.
- .value contiene il nome della colonna in cui verranno inseriti i valori delle celle.
Le altre colonne della specifica riflettono come verrà visualizzato il nome delle colonne compresse nella nuova colonna di .name.
La specifica descrive i metadati memorizzati nel nome della colonna, con una riga per ogni colonna e una colonna per ogni variabile unita al nome della colonna, probabilmente questa definizione sembra confusa al momento, ma dopo aver esaminato alcuni esempi diventerà molto più chiara.
Il senso della specifica è che puoi estrarre, modificare e impostare nuovi metadati sul frame di dati trasformato.
Per lavorare con le specifiche durante la conversione da un formato wide a un formato long, si utilizza la funzione pivot_longer_spec().
Come funziona questa funzione? Prende un dataframe e forma i suoi metadati come descritto sopra.
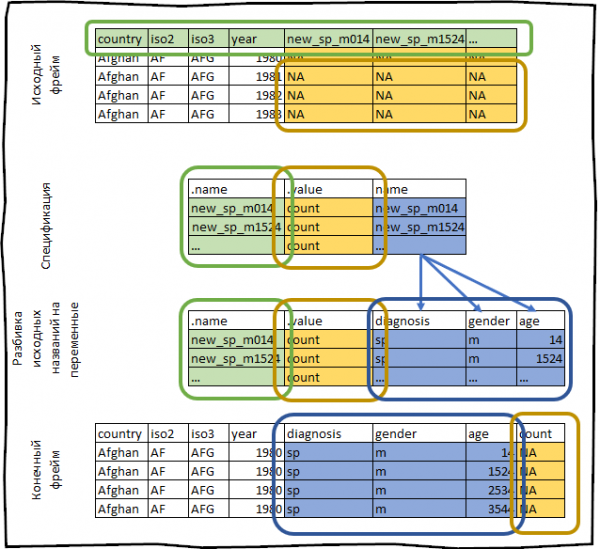
Per esempio, prendiamo il set di dati who, fornito insieme al pacchetto tidyr. Questo set di dati contiene informazioni fornite dall'Organizzazione Mondiale della Sanità sulla prevalenza della tubercolosi.
who
#># A tibble: 7,240 x 60
#># country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534
#>#
#># 1 Afghan… AF AFG 1980 NA NA NA
#># 2 Afghan… AF AFG 1981 NA NA NA
#># 3 Afghan… AF AFG 1982 NA NA NA
#># 4 Afghan… AF AFG 1983 NA NA NA
#># 5 Afghan… AF AFG 1984 NA NA NA
#># 6 Afghan… AF AFG 1985 NA NA NA
#># 7 Afghan… AF AFG 1986 NA NA NA
#># 8 Afghan… AF AFG 1987 NA NA NA
#># 9 Afghan… AF AFG 1988 NA NA NA
#># 10 Afghan… AF AFG 1989 NA NA NA
#># # … con 7,230 righe in più e 53 variabili aggiuntive.Costruiamo la sua specifica.
spec %
pivot_longer_spec(new_sp_m014:newrel_f65, values_to = "count")#> # A tibble: 56 x 3
#> .name .value name
#> <chr> <chr> <chr>
#> 1 new_sp_m014 count new_sp_m014
#> 2 new_sp_m1524 count new_sp_m1524
#> 3 new_sp_m2534 count new_sp_m2534
#> 4 new_sp_m3544 count new_sp_m3544
#> 5 new_sp_m4554 count new_sp_m4554
#> 6 new_sp_m5564 count new_sp_m5564
#> 7 new_sp_m65 count new_sp_m65
#> 8 new_sp_f014 count new_sp_f014
#> 9 new_sp_f1524 count new_sp_f1524
#> 10 new_sp_f2534 count new_sp_f2534
#> # … with 46 more rowsCampi country, iso2, iso3 sono già variabili. Il nostro compito è invertire le colonne con new_sp_m014 per newrel_f65.
Nei titoli di queste colonne è memorizzata la seguente informazione:
- Prefisso
new_indica che la colonna contiene dati sui nuovi casi di tubercolosi, il data frame attuale contiene informazioni solo sui nuovi casi, quindi questo prefisso nel contesto attuale non ha alcun significato. sp/rel/sp/epdescrive il metodo di diagnosi della malattia.m/fsesso del paziente.014/1524/2535/3544/4554/65fascia di età del paziente.
Possiamo separare queste colonne utilizzando la funzione extract(), usando un'espressione regolare.
spec %
extract(name, c("diagnosis", "gender", "age"), "new_?(.*)_(.)(.*)")#> # A tibble: 56 x 5
#> .name .value diagnosis gender age
#> <chr> <chr> <chr> <chr> <chr>
#> 1 new_sp_m014 count sp m 014
#> 2 new_sp_m1524 count sp m 1524
#> 3 new_sp_m2534 count sp m 2534
#> 4 new_sp_m3544 count sp m 3544
#> 5 new_sp_m4554 count sp m 4554
#> 6 new_sp_m5564 count sp m 5564
#> 7 new_sp_m65 count sp m 65
#> 8 new_sp_f014 count sp f 014
#> 9 new_sp_f1524 count sp f 1524
#> 10 new_sp_f2534 count sp f 2534
#> # … with 46 more rowsSi noti che la colonna .name deve rimanere invariata, poiché è il nostro indice nei nomi delle colonne del set di dati originale.
Il sesso e l'età (colonne gender e age) hanno valori fissi e noti, quindi si consiglia di trasformare queste colonne in fattori:
spec %
mutate(
gender = factor(gender, levels = c("f", "m")),
age = factor(age, levels = unique(age), ordered = TRUE)
) Infine, per applicare la specifica creata al data frame originale who dobbiamo utilizzare l'argomento spec nella funzione pivot_longer().
who %>% pivot_longer(spec = spec)
#> # A tibble: 405,440 x 8
#> country iso2 iso3 year diagnosis gender age count
#> <chr> <chr> <chr> <int> <chr> <fct> <ord> <int>
#> 1 Afghanistan AF AFG 1980 sp m 014 NA
#> 2 Afghanistan AF AFG 1980 sp m 1524 NA
#> 3 Afghanistan AF AFG 1980 sp m 2534 NA
#> 4 Afghanistan AF AFG 1980 sp m 3544 NA
#> 5 Afghanistan AF AFG 1980 sp m 4554 NA
#> 6 Afghanistan AF AFG 1980 sp m 5564 NA
#> 7 Afghanistan AF AFG 1980 sp m 65 NA
#> 8 Afghanistan AF AFG 1980 sp f 014 NA
#> 9 Afghanistan AF AFG 1980 sp f 1524 NA
#> 10 Afghanistan AF AFG 1980 sp f 2534 NA
#> # … with 405,430 more rowsTutto ciò che abbiamo appena fatto può essere schematicamente rappresentato come segue:
Specificazione utilizzando più valori (.value)
Nell'esempio sopra, la colonna delle specifiche .value contiene solo un valore, ed è così nella maggior parte dei casi.
Tuttavia, in rari casi potrebbe sorgere la necessità di raccogliere valori da colonne con tipi di dati diversi. Con la funzione obsoleta spread() sarebbe stata piuttosto difficile da realizzare.
L'esempio seguente è tratto da al pacchetto data.table.
Creiamo un dataframe di prova.
family <- tibble::tribble(
~family, ~dob_child1, ~dob_child2, ~gender_child1, ~gender_child2,
1L, "1998-11-26", "2000-01-29", 1L, 2L,
2L, "1996-06-22", NA, 2L, NA,
3L, "2002-07-11", "2004-04-05", 2L, 2L,
4L, "2004-10-10", "2009-08-27", 1L, 1L,
5L, "2000-12-05", "2005-02-28", 2L, 1L,
)
family % mutate_at(vars(starts_with("dob")), parse_date)#> # A tibble: 5 x 5
#> family dob_child1 dob_child2 gender_child1 gender_child2
#> <int> <date> <date> <int> <int>
#> 1 1 1998-11-26 2000-01-29 1 2
#> 2 2 1996-06-22 NA 2 NA
#> 3 3 2002-07-11 2004-04-05 2 2
#> 4 4 2004-10-10 2009-08-27 1 1
#> 5 5 2000-12-05 2005-02-28 2 1Il dataframe creato contiene in ogni riga i dati sui bambini di una stessa famiglia. Nelle famiglie possono esserci uno o due bambini. Per ciascun bambino sono forniti i dati relativi alla data di nascita e al sesso, con i dati per ogni bambino in colonne separate; il nostro obiettivo è convertire questi dati nel formato corretto per l'analisi.
Si prega di notare che abbiamo due variabili con informazioni su ogni bambino: il suo sesso e la data di nascita (le colonne con il prefisso dop contengono la data di nascita, le colonne con il prefisso gender contengono il sesso del bambino). Nel risultato atteso, questi dovrebbero essere in colonne separate. Possiamo farlo generando una specifica in cui la colonna .value avrà due valori diversi.
spec %
pivot_longer_spec(-family) %>%
separate(col = name, into = c(".value", "child"))%>%
mutate(child = parse_number(child))
#> # A tibble: 4 x 3
#> .name .value child
#> <chr> <chr> <dbl>
#> 1 dob_child1 dob 1
#> 2 dob_child2 dob 2
#> 3 gender_child1 gender 1
#> 4 gender_child2 gender 2Quindi, esaminiamo passo passo le azioni eseguite dal codice sopra riportato.
pivot_longer_spec(-family)— creiamo una specifica che comprime tutte le colonne esistenti, tranne la colonna family.separate(col = name, into = c(".value", "child"))— separiamo la colonna .name, che contiene i nomi dei campi originali, usando il carattere di sottolineatura e trasferiamo i valori ottenuti nelle colonne .value e child.mutate(child = parse_number(child))— convertiamo i valori del campo child da tipo di testo a tipo numerico.
Ora possiamo applicare alla tabella originale la specifica ottenuta e portare la tabella nel formato desiderato.
family %>%
pivot_longer(spec = spec, na.rm = T)#> # A tibble: 9 x 4
#> family child dob gender
#> <int> <dbl> <date> <int>
#> 1 1 1 1998-11-26 1
#> 2 1 2 2000-01-29 2
#> 3 2 1 1996-06-22 2
#> 4 3 1 2002-07-11 2
#> 5 3 2 2004-04-05 2
#> 6 4 1 2004-10-10 1
#> 7 4 2 2009-08-27 1
#> 8 5 1 2000-12-05 2
#> 9 5 2 2005-02-28 1Utilizziamo l'argomento na.rm = TRUE, perché l'attuale forma dei dati costringe a creare righe aggiuntive per osservazioni inesistenti. Poiché la famiglia 2 ha solo un bambino, na.rm = TRUE garantisce che la famiglia 2 avrà una riga nei dati di output.
Trasformazione di data frame da formato lungo a largo
pivot_wider() — è una trasformazione inversa, che aumenta il numero di colonne del dataframe riducendo il numero di righe.
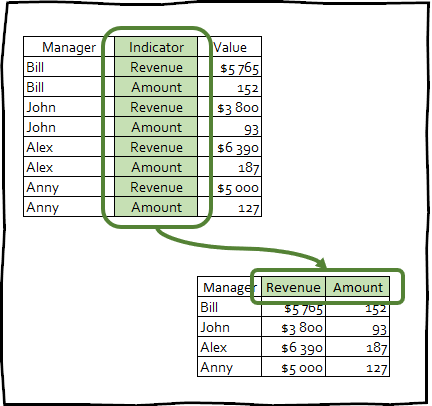
Questo tipo di trasformazione è raramente utilizzata per rendere i dati ordinati, tuttavia questa tecnica può essere utile per creare tabelle riassuntive utilizzate nelle presentazioni o per integrarsi con altri strumenti.
In realtà, le funzioni pivot_longer() e pivot_wider() sono simmetriche e svolgono azioni inverse l'una dell'altra, cioè: df %>% pivot_longer(spec = spec) %>% pivot_wider(spec = spec) e df %>% pivot_wider(spec = spec) %>% pivot_longer(spec = spec) restituirà il df originale.
Il più semplice esempio di conversione di una tabella in formato largo
Per dimostrare il funzionamento della funzione pivot_wider() utilizzeremo il dataset fish_encounters, che contiene informazioni su come diverse stazioni registrano il movimento dei pesci nel fiume.
#> # A tibble: 114 x 3
#> fish station seen
#> <fct> <fct> <int>
#> 1 4842 Release 1
#> 2 4842 I80_1 1
#> 3 4842 Lisbon 1
#> 4 4842 Rstr 1
#> 5 4842 Base_TD 1
#> 6 4842 BCE 1
#> 7 4842 BCW 1
#> 8 4842 BCE2 1
#> 9 4842 BCW2 1
#> 10 4842 MAE 1
#> # … with 104 more rowsNella maggior parte dei casi, questa tabella sarà più informativa e utile se informazioni su ciascuna stazione sono presentate in colonne separate.
fish_encounters %>% pivot_wider(names_from = station, values_from = seen)
fish_encounters %>% pivot_wider(names_from = station, values_from = seen)
#> # A tibble: 19 x 12
#> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE
#> & & & & & &
#> 1 4842 1 1 1 1 1 1 1 1 1 1
#> 2 4843 1 1 1 1 1 1 1 1 1 1
#> 3 4844 1 1 1 1 1 1 1 1 1 1
#> 4 4845 1 1 1 1 1 NA NA NA NA NA
#> 5 4847 1 1 1 NA NA NA NA NA NA NA
#> 6 4848 1 1 1 1 NA NA NA NA NA NA
#> 7 4849 1 1 NA NA NA NA NA NA NA NA
#> 8 4850 1 1 NA 1 1 1 1 NA NA NA
#> 9 4851 1 1 NA NA NA NA NA NA NA NA
#> 10 4854 1 1 NA NA NA NA NA NA NA NA
#> # … con altre 9 righe, e 1 variabile in più: MAWQuesto set di dati registra informazioni solo nei casi in cui un pesce sia stato osservato dalla stazione, cioè se alcun pesce non è stato registrato da una stazione, questi dati non saranno presenti nella tabella. Ciò significa che i risultati saranno riempiti con NA.
Tuttavia, in questo caso sappiamo che l'assenza di una registrazione significa che il pesce non è stato notato, quindi possiamo utilizzare l'argomento values_fill nella funzione pivot_wider() e riempire questi valori mancanti con zeri:
fish_encounters %>% pivot_wider(
names_from = station,
values_from = seen,
values_fill = list(seen = 0)
)#> # A tibble: 19 x 12
#> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE
#> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
#> 1 4842 1 1 1 1 1 1 1 1 1 1
#> 2 4843 1 1 1 1 1 1 1 1 1 1
#> 3 4844 1 1 1 1 1 1 1 1 1 1
#> 4 4845 1 1 1 1 1 0 0 0 0 0
#> 5 4847 1 1 1 0 0 0 0 0 0 0
#> 6 4848 1 1 1 1 0 0 0 0 0 0
#> 7 4849 1 1 0 0 0 0 0 0 0 0
#> 8 4850 1 1 0 1 1 1 1 0 0 0
#> 9 4851 1 1 0 0 0 0 0 0 0 0
#> 10 4854 1 1 0 0 0 0 0 0 0 0
#> # … with 9 more rows, and 1 more variable: MAW <int>Generazione del nome della colonna da più variabili originali
Immagina di avere una tabella che contiene combinazioni di prodotto, paese e anno. Per generare un dataframe di test, puoi eseguire il seguente codice:
df %
filter((product == "A" & country == "AI") | product == "B") %>%
mutate(value = rnorm(nrow(.)))#> # A tibble: 45 x 4
#> product country year value
#> <chr> <chr> <int> <dbl>
#> 1 A AI 2000 -2.05
#> 2 A AI 2001 -0.676
#> 3 A AI 2002 1.60
#> 4 A AI 2003 -0.353
#> 5 A AI 2004 -0.00530
#> 6 A AI 2005 0.442
#> 7 A AI 2006 -0.610
#> 8 A AI 2007 -2.77
#> 9 A AI 2008 0.899
#> 10 A AI 2009 -0.106
#> # … with 35 more rowsIl nostro compito è ampliare il dataframe in modo che una colonna contenga dati per ogni combinazione di prodotto e paese. Per farlo, basta passare come argomento names_from un vettore contenente i nomi dei campi da unire.
df %>% pivot_wider(names_from = c(product, country),
values_from = "value")#> # A tibble: 15 x 4
#> year A_AI B_AI B_EI
#> <int> <dbl> <dbl> <dbl>
#> 1 2000 -2.05 0.607 1.20
#> 2 2001 -0.676 1.65 -0.114
#> 3 2002 1.60 -0.0245 0.501
#> 4 2003 -0.353 1.30 -0.459
#> 5 2004 -0.00530 0.921 -0.0589
#> 6 2005 0.442 -1.55 0.594
#> 7 2006 -0.610 0.380 -1.28
#> 8 2007 -2.77 0.830 0.637
#> 9 2008 0.899 0.0175 -1.30
#> 10 2009 -0.106 -0.195 1.03
#> # … with 5 more rowsPuoi anche applicare specifiche alla funzione pivot_wider(). Ma quando si presenta in pivot_wider() la specifica esegue una trasformazione opposta pivot_longer(): vengono creati i campi specificati in .name, utilizzando i valori da .value e altri campi.
Per questo set di dati, è possibile generare una specifica personalizzata se si desidera che ogni possibile combinazione di paese e prodotto abbia il proprio campo, invece di avere solo quelli presenti nei dati:
spec %
expand(product, country, .value = "value") %>%
unite(".name", product, country, remove = FALSE)#> # A tibble: 4 x 4
#> .name product country .value
#> <chr> <chr> <chr> <chr>
#> 1 A_AI A AI value
#> 2 A_EI A EI value
#> 3 B_AI B AI value
#> 4 B_EI B EI valuedf %>% pivot_wider(spec = spec) %>% head()#> # A tibble: 6 x 5
#> year A_AI A_EI B_AI B_EI
#> <int> <dbl> <dbl> <dbl> <dbl>
#> 1 2000 -2.05 NA 0.607 1.20
#> 2 2001 -0.676 NA 1.65 -0.114
#> 3 2002 1.60 NA -0.0245 0.501
#> 4 2003 -0.353 NA 1.30 -0.459
#> 5 2004 -0.00530 NA 0.921 -0.0589
#> 6 2005 0.442 NA -1.55 0.594Alcuni esempi avanzati di lavoro con il nuovo concetto di tidyr
Preparazione dei dati in un formato pulito utilizzando il set di dati sul reddito e il canone di locazione negli Stati Uniti
Set di dati us_rent_income contiene informazioni sui redditi medi e sugli affitti per ogni stato degli Stati Uniti nel 2017 (il set di dati è disponibile nel pacchetto tidycensus).
us_rent_income
#> # A tibble: 104 x 5
#> GEOID NAME variable estimate moe
#>
#> 1 01 Alabama income 24476 136
#> 2 01 Alabama rent 747 3
#> 3 02 Alaska income 32940 508
#> 4 02 Alaska rent 1200 13
#> 5 04 Arizona income 27517 148
#> 6 04 Arizona rent 972 4
#> 7 05 Arkansas income 23789 165
#> 8 05 Arkansas rent 709 5
#> 9 06 California income 29454 109
#> 10 06 California rent 1358 3
#> # … con 94 righe in piùNella forma in cui i dati sono memorizzati nel set di dati us_rent_income lavorare con questi dati è estremamente scomodo, quindi vorremmo creare un set di dati con colonne: affitto, affitto_moe, venire, reddito_moe. Ci sono molti modi per creare questa specifica, ma il punto principale è che dobbiamo generare ogni combinazione di valori della variabile e stima/moe, e poi generare il nome della colonna.
spec %
expand(variable, .value = c("estimate", "moe")) %>%
mutate(
.name = paste0(variable, ifelse(.value == "moe", "_moe", ""))
)#> # A tibble: 4 x 3
#> variable .value .name
#> <chr> <chr> <chr>
#> 1 income estimate income
#> 2 income moe income_moe
#> 3 rent estimate rent
#> 4 rent moe rent_moeFornire questa specifica pivot_wider() ci dà il risultato che stiamo cercando:
us_rent_income %>% pivot_wider(spec = spec)
#> # A tibble: 52 x 6
#> GEOID NAME income income_moe rent rent_moe
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 01 Alabama 24476 136 747 3
#> 2 02 Alaska 32940 508 1200 13
#> 3 04 Arizona 27517 148 972 4
#> 4 05 Arkansas 23789 165 709 5
#> 5 06 California 29454 109 1358 3
#> 6 08 Colorado 32401 109 1125 5
#> 7 09 Connecticut 35326 195 1123 5
#> 8 10 Delaware 31560 247 1076 10
#> 9 11 District of Columbia 43198 681 1424 17
#> 10 12 Florida 25952 70 1077 3
#> # … with 42 more rowsBanca Mondiale
A volte, portare un set di dati nella forma desiderata richiede diversi passaggi.
Set di dati world_bank_pop contiene i dati della Banca Mondiale sulla popolazione di ogni paese nel periodo dal 2000 al 2018.
#> # A tibble: 1,056 x 20
#> country indicator `2000` `2001` `2002` `2003` `2004` `2005` `2006`
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 ABW SP.URB.T… 4.24e4 4.30e4 4.37e4 4.42e4 4.47e+4 4.49e+4 4.49e+4
#> 2 ABW SP.URB.G… 1.18e0 1.41e0 1.43e0 1.31e0 9.51e-1 4.91e-1 -1.78e-2
#> 3 ABW SP.POP.T… 9.09e4 9.29e4 9.50e4 9.70e4 9.87e+4 1.00e+5 1.01e+5
#> 4 ABW SP.POP.G… 2.06e0 2.23e0 2.23e0 2.11e0 1.76e+0 1.30e+0 7.98e-1
#> 5 AFG SP.URB.T… 4.44e6 4.65e6 4.89e6 5.16e6 5.43e+6 5.69e+6 5.93e+6
#> 6 AFG SP.URB.G… 3.91e0 4.66e0 5.13e0 5.23e0 5.12e+0 4.77e+0 4.12e+0
#> 7 AFG SP.POP.T… 2.01e7 2.10e7 2.20e7 2.31e7 2.41e+7 2.51e+7 2.59e+7
#> 8 AFG SP.POP.G… 3.49e0 4.25e0 4.72e0 4.82e0 4.47e+0 3.87e+0 3.23e+0
#> 9 AGO SP.URB.T… 8.23e6 8.71e6 9.22e6 9.77e6 1.03e+7 1.09e+7 1.15e+7
#> 10 AGO SP.URB.G… 5.44e0 5.59e0 5.70e0 5.76e0 5.75e+0 5.69e+0 4.92e+0
#> # … with 1,046 more rows, and 11 more variables: `2007` <dbl>,
#> # `2008` <dbl>, `2009` <dbl>, `2010` <dbl>, `2011` <dbl>, `2012` <dbl>,
#> # `2013` <dbl>, `2014` <dbl>, `2015` <dbl>, `2016` <dbl>, `2017` <dbl>Il nostro obiettivo è creare un set di dati ordinato, dove ogni variabile è in una colonna separata. Finora non è chiaro quali siano i passi necessari, ma iniziamo col problema più ovvio: l'anno è distribuito su più colonne.
Per correggerlo, è necessario utilizzare la funzione pivot_longer().
pop2 %
pivot_longer(`2000`:`2017`, names_to = "year")#> # A tibble: 19,008 x 4
#> country indicator year value
#> <chr> <chr> <chr> <dbl>
#> 1 ABW SP.URB.TOTL 2000 42444
#> 2 ABW SP.URB.TOTL 2001 43048
#> 3 ABW SP.URB.TOTL 2002 43670
#> 4 ABW SP.URB.TOTL 2003 44246
#> 5 ABW SP.URB.TOTL 2004 44669
#> 6 ABW SP.URB.TOTL 2005 44889
#> 7 ABW SP.URB.TOTL 2006 44881
#> 8 ABW SP.URB.TOTL 2007 44686
#> 9 ABW SP.URB.TOTL 2008 44375
#> 10 ABW SP.URB.TOTL 2009 44052
#> # … with 18,998 more rowsIl passo successivo è considerare la variabile indicator.
pop2 %>% count(indicator)
#> # A tibble: 4 x 2
#> indicator n
#> <chr> <int>
#> 1 SP.POP.GROW 4752
#> 2 SP.POP.TOTL 4752
#> 3 SP.URB.GROW 4752
#> 4 SP.URB.TOTL 4752Dove SP.POP.GROW indica l'incremento della popolazione, SP.POP.TOTL rappresenta la popolazione totale, mentre SP.URB. * è lo stesso, ma solo per le aree urbane. Dividiamo questi valori in due variabili: area — località (totale o urbana) e una variabile contenente i dati effettivi (popolazione o crescita):
pop3 %
separate(indicator, c(NA, "area", "variable"))#> # A tibble: 19,008 x 5
#> country area variable year value
#> <chr> <chr> <chr> <chr> <dbl>
#> 1 ABW URB TOTL 2000 42444
#> 2 ABW URB TOTL 2001 43048
#> 3 ABW URB TOTL 2002 43670
#> 4 ABW URB TOTL 2003 44246
#> 5 ABW URB TOTL 2004 44669
#> 6 ABW URB TOTL 2005 44889
#> 7 ABW URB TOTL 2006 44881
#> 8 ABW URB TOTL 2007 44686
#> 9 ABW URB TOTL 2008 44375
#> 10 ABW URB TOTL 2009 44052
#> # … with 18,998 more rowsOra dobbiamo solo dividere la variabile variable in due colonne:
pop3 %>%
pivot_wider(names_from = variable, values_from = value)#> # A tibble: 9,504 x 5
#> country area year TOTL GROW
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 ABW URB 2000 42444 1.18
#> 2 ABW URB 2001 43048 1.41
#> 3 ABW URB 2002 43670 1.43
#> 4 ABW URB 2003 44246 1.31
#> 5 ABW URB 2004 44669 0.951
#> 6 ABW URB 2005 44889 0.491
#> 7 ABW URB 2006 44881 -0.0178
#> 8 ABW URB 2007 44686 -0.435
#> 9 ABW URB 2008 44375 -0.698
#> 10 ABW URB 2009 44052 -0.731
#> # … with 9,494 more rowsLista dei contatti
Ultimo esempio, immaginate di avere un elenco di contatti che avete copiato e incollato da un sito web:
contacts <- tribble(
~field, ~value,
"name", "Jiena McLellan",
"company", "Toyota",
"name", "John Smith",
"company", "google",
"email", "john@google.com",
"name", "Huxley Ratcliffe"
)Portare questo elenco in formato tabellare è abbastanza difficile, perché non c'è una variabile che identifichi a quali dati appartiene ogni contatto. Possiamo risolvere ciò, notando che i dati per ogni nuovo contatto iniziano con il nome ("name"), quindi possiamo creare un identificatore unico e incrementarlo di uno ogni volta che nella colonna field appare il valore “name”:
contacts %
mutate(
person_id = cumsum(field == "name")
)
contacts#> # A tibble: 6 x 3
#> field value person_id
#> <chr> <chr> <int>
#> 1 name Jiena McLellan 1
#> 2 company Toyota 1
#> 3 name John Smith 2
#> 4 company google 2
#> 5 email john@google.com 2
#> 6 name Huxley Ratcliffe 3Ora che abbiamo un identificatore unico per ogni contatto, possiamo trasformare i campi e i valori in colonne:
contacts %>%
pivot_wider(names_from = field, values_from = value)#> # A tibble: 3 x 4
#> person_id name company email
#> <int> <chr> <chr> <chr>
#> 1 1 Jiena McLellan Toyota <NA>
#> 2 2 John Smith google john@google.com
#> 3 3 Huxley Ratcliffe <NA> <NA>Conclusione
Personalmente, credo che il nuovo concetto tidyr sia davvero intuitivamente più chiaro e superi di gran lunga le funzionalità delle funzioni obsolete. spread() e gather(). Spero che questo articolo ti abbia aiutato a capire pivot_longer() e pivot_wider().
Fonte: habr.com
