

Nota del traduttore.: L'autrice di questo articolo è Cindy Sridharan, ingegnere di imgix, che si occupa di sviluppo API e, in particolare, di test dei microservizi. In questo articolo condivide la sua visione approfondita delle problematiche attuali nel campo del tracciamento distribuito, dove, secondo lei, manca davvero strumenti efficaci per affrontare le questioni urgenti.
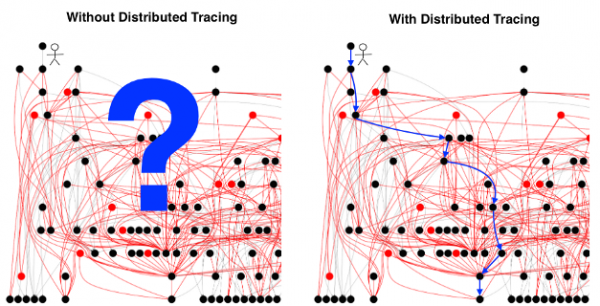
[L'illustrazione è presa da sul tracciamento distribuito.]
Si ritiene che sia difficile da implementare, e il ritorno su di esso . La "problematicità" del tracciamento è spiegata da molteplici motivi, e spesso si fa riferimento alla complessità di configurare ogni componente del sistema per trasmettere gli appropriati header insieme a ogni richiesta. Sebbene questo problema sia reale, non può essere definito insormontabile. D'altra parte, non spiega perché gli sviluppatori non siano particolarmente favorevoli al tracciamento (anche quello già in funzione).
La principale difficoltà nella tracciatura distribuita non è la raccolta dei dati, la standardizzazione dei formati di distribuzione e presentazione dei risultati, né la definizione di quando, dove e come effettuare il campionamento. Non intendo assolutamente presentare banali queste «problematiche di usabilità» — in realtà, esistono significative sfide tecniche e (se consideriamo veramente standard e ) politiche che devono essere superate affinché queste problematiche possano essere considerate risolte.
Tuttavia, ponendo l'ipotesi che tutti questi problemi siano risolti, è molto probabile che non ci siano cambiamenti sostanziali dal punto di vista dell'esperienza dell'utente finale. La tracciatura potrebbe comunque non fornire un'utilità pratica nei più comuni scenari di debug — anche dopo la sua implementazione.
Una tracciatura così particolare
La tracciatura distribuita comprende diversi componenti disgiunti:
- l'integrazione delle applicazioni e del middleware con strumenti di controllo;
- la trasmissione del contesto distribuito;
- la raccolta delle tracciature;
- il salvataggio delle tracciature;
- il loro recupero e visualizzazione.
Molti discorsi sulla tracciatura distribuita si riducono a considerarla come un'operazione unaria il cui unico scopo è aiutare nella diagnosi completa del sistema. Questo è in gran parte legato al modo in cui storicamente si sono formate le concezioni sulla tracciatura distribuita. Nel libro che era lanciato quando sono stati aperti i sorgenti di Zipkin, veniva menzionato che esso [Zipkin] rende Twitter più veloce. Le prime offerte commerciali per la tracciatura sono state anche promosse come .
Nota del traduttore.: Per una migliore comprensione del testo successivo, definiamo due termini di base secondo la :
- Span è l'elemento base della tracciatura distribuita. Rappresenta la descrizione di un certo processo di lavoro (ad esempio, una richiesta al database) con un nome, un orario di inizio e di fine, tag, log e contesto.
- Gli span di solito contengono riferimenti ad altri span, il che consente di unire diversi span in Trace la visualizzazione della vita di una richiesta mentre si sposta attraverso un sistema distribuito.
Le trace contengono dati incredibilmente preziosi che possono essere utili in attività come: test in produzione, esecuzione di test di ripristino, test con l’introduzione di errori, ecc. In effetti, alcune aziende già utilizzano il tracciamento per tali scopi. Iniziamo con il fatto che ha altre applicazioni oltre al semplice trasferimento di span nei sistemi di archiviazione:
- Ad esempio, Uber utilizza i risultati del tracciamento per distinguere il traffico di test da quello di produzione.
- Facebook dati di tracciamento per analizzare il percorso critico e per deviare il traffico durante i test di ripristino regolari.
- Inoltre, il social network notebooks Jupyter, che permettono agli sviluppatori di eseguire query arbitrarie sui risultati di tracciamento.
- I sostenitori di (Lineage Driven Failure Injection) tracce distribuite per testare l’inserimento di errori.
Nessuna delle opzioni menzionate sopra riguarda completamente lo scenario di debug, in cui un ingegnere cerca di risolvere un problema esaminando il tracciamento.
Quando si tratta comunque di uno scenario di debug, l’interfaccia principale rimane il diagramma traceview (anche se alcuni la chiamano anche «diagramma di Gantt» o «diagramma a cascata»). Per traceview io tutti gli span e i metadati associati che insieme costituiscono un trace. Ogni sistema di tracciamento open source, così come ogni soluzione commerciale di tracciamento, offre un traceview interfaccia utente per la visualizzazione, la dettagliatura e il filtraggio dei trace.
Il problema con tutti i sistemi di tracciamento che ho esaminato fino ad ora è che la visualizzazione finale (traceview) riflette quasi completamente le caratteristiche del processo di generazione del trace. Anche quando vengono offerte visualizzazioni alternative: mappe di intensità (heatmap), topologie di servizi, istogrammi di latenza, — alla fine si riducono tutte a traceview.
In passato ho che la maggior parte delle «innovazioni» nel campo del tracciamento riguardo all'UI/UX sembra limitarsi di metadati aggiuntivi nei trace, includendo informazioni ad alta cardinalità (high-cardinality) o fornendo la possibilità di dettagliere specifici span o eseguire query. tracciamento inter- e intraprocessi. In questo contesto, traceview rimane il principale strumento di visualizzazione. Fintanto che questa situazione persiste, il tracciamento distribuito occupa (nel migliore dei casi) il quarto posto come strumento di debug, dopo le metriche, i log e gli stack trace, e nel peggiore dei casi diventa una perdita di denaro e tempo.
Problema con traceview
Scopo traceview — fornire un quadro completo del movimento di una singola richiesta attraverso tutti i componenti del sistema distribuito a cui è collegata. Alcuni sistemi di tracciamento più avanzati consentono di dettagliare singoli span e visualizzare la suddivisione temporale all'interno di un processo (quando gli span hanno confini funzionali).
La base dell'architettura dei microservizi è l'idea che la struttura organizzativa cresca insieme alle esigenze dell'azienda. I sostenitori dei microservizi sostengono che separare diverse attività aziendali in servizi distinti consente a piccoli team autonomi di sviluppatori di gestire l'intero ciclo di vita di tali servizi, permettendo loro di creare, testare e distribuire questi servizi in modo indipendente. Tuttavia, una svantaggio di questa separazione è la perdita di informazioni su come ogni servizio interagisce con gli altri. In queste circostanze, il tracciamento distribuito si propone come uno strumento indispensabile per di debug interazioni complesse tra i servizi.
Se hai davvero , nessuna persona è in grado di tenere a mente il suo quadro completo. In effetti, sviluppare uno strumento partendo dall'assunto che ciò sia possibile è piuttosto un anti-pattern (un approccio inefficace e improduttivo). Idealmente, per il debug è necessario uno strumento che aiuti a restringere l'area di ricerca, in modo che gli ingegneri possano concentrarsi su un sottoinsieme di misurazioni (servizi / utenti / host, ecc.) pertinenti allo scenario del problema in esame. Nella determinazione della causa del malfunzionamento, gli ingegneri non devono districarsi in ciò che stava accadendo in tutti i servizi contemporaneamente, poiché tale richiesta contraddirebbe l'idea stessa dell'architettura a microservizi.
Tuttavia, traceview rappresenta esattamente questo. Sì, alcuni sistemi di tracciamento offrono traceview condensati, quando il numero di span nel trace è così elevato che non può essere visualizzato all'interno di una sola visualizzazione. Tuttavia, a causa dell'ampio volume di informazioni contenute anche in una visualizzazione ridotta, gli ingegneri sono comunque costretti a "setacciare" i dati, restringendo manualmente il campione a un insieme di servizi sorgente del problema. Purtroppo, in questo ambito, le macchine risultano molto più rapide degli esseri umani, meno soggette a errori e i loro risultati sono più ripetibili.
Un'altra ragione per cui considero il metodo traceview inadeguato è che non si presta bene al debug basato su ipotesi. Alla base, il debugging è iterativo un processo che inizia con un'ipotesi, seguito dalla verifica di varie osservazioni e fatti derivati dal sistema lungo diversi vettori, conclusioni / generalizzazioni e una valutazione successiva della verità dell'ipotesi.
Possibilità rapido ed economico testare le ipotesi e migliorare di conseguenza il modello mentale è la pietra angolare del debugging. Qualsiasi strumento di debugging deve essere interattivo e restringere lo spazio di ricerca oppure, in caso di falso segnale, permettere all'utente di tornare indietro e concentrarsi su un'altra area del sistema. Lo strumento ideale farebbe questo in anticipo, attirando immediatamente l'attenzione dell'utente su aree potenzialmente problematiche.
Purtroppo, traceview non si può considerare uno strumento con un'interfaccia interattiva. Il massimo che ci si può aspettare nel suo utilizzo è scoprire una certa fonte di ritardi maggiorati e visionare vari tag e log associati. Questo non aiuta l'ingegnere a individuare pattern nel traffico, come le specificità della distribuzione dei ritardi, o a scoprire correlazioni tra diverse misurazioni. può aiutare a superare alcuni di questi problemi. In effetti, di analisi di successo utilizzando machine learning per identificare anomalie nei span e identificare un sottoinsieme di tag che potrebbero essere correlati a comportamenti anomali. Tuttavia, finora non ho visto visualizzazioni convincenti delle scoperte fatte attraverso machine learning o analisi dei dati applicati agli span, che differissero significativamente da traceview o DAG (grafico aciclico diretto).
Gli span sono troppo a basso livello
Il problema fondamentale con traceview è che gli span sono troppo a livello primitivo sia per l'analisi delle latenze (latency) che per l'analisi delle cause principali. È come analizzare singole istruzioni della CPU nel tentativo di risolvere un'eccezione, sapendo che ci sono strumenti a un livello molto più alto come backtrace, con cui è significativamente più semplice lavorare.
Inoltre, mi prendo la libertà di affermare quanto segue: idealmente, non abbiamo affatto bisogno di una visione completa durante il ciclo di vita della richiesta, che sono fornite dagli strumenti moderni per il tracciamento. Invece, è necessaria una forma di astrazione a un livello superiore, contenente informazioni su cosa è andato storto (analogamente a un backtrace), insieme a un certo contesto. Piuttosto che osservare l'intero tracciato, preferisco vedere la sua parte, dove accade qualcosa di interessante o insolito. Attualmente, la ricerca viene effettuata manualmente: l’ingegnere riceve il tracciato e analizza da solo gli span alla ricerca di qualcosa di interessante. L'approccio in cui le persone esaminano gli span in singoli tracciati nella speranza di scoprire attività sospette non è affatto scalabile (soprattutto quando devono elaborare tutti i metadati codificati in vari span, come l'ID dello span, il nome del metodo RPC, la durata dello span, i log, i tag, ecc.).
Alternative a traceview
I risultati del tracciamento sono più utili quando possono essere visualizzati in modo da fornire una rappresentazione non banale di ciò che sta accadendo nelle parti interconnesse del sistema. Fino a quando ciò non avviene, il processo di debug rimane in gran parte inerte e dipende dalla capacità dell'utente di notare le giuste correlazioni, controllare le parti corrette del sistema o mettere insieme i pezzi di un puzzle, a differenza di uno strumento, che aiuta l'utente a formulare queste ipotesi.
Non sono un designer visivo né un esperto di UX, tuttavia nella sezione seguente voglio condividere alcune idee su come potrebbero apparire tali visualizzazioni.
Focus su servizi specifici
In un contesto in cui l'industria si sta consolidando attorno alle idee , sembra ragionevole che i singoli team debbano prima di tutto monitorare la corrispondenza dei loro servizi con questi obiettivi. Ne consegue che una visualizzazione orientata al servizio è più adatta per tali team.
I trace, specialmente quelli senza campionamento, sono una miniera d'informazioni su ogni componente di un sistema distribuito. Queste informazioni possono essere utilizzate da un elaboratore intelligente che fornisce agli utenti orientato ai servizi scoperte. Possono essere identificate in anticipo — prima che l'utente guardi i trace:
- Diagrammi di distribuzione delle latenze solo per richieste anomale (richieste outlier);
- Diagrammi di distribuzione delle latenze per i casi in cui non vengono raggiunti gli obiettivi SLO del servizio;
- I tag più "comuni", "interessanti" e "strani" nelle richieste che si ripetono più frequentemente ripetuti;
- Suddivisione delle latenze per i casi in cui le dipendenze del servizio non raggiungono gli obiettivi SLO stabiliti;
- Suddivisione delle latenze per vari servizi downstream.
Alcune di queste domande non possono essere risposte semplicemente con metriche integrate, costringendo gli utenti a studiare attentamente gli span. Di conseguenza, abbiamo un meccanismo estremamente ostile per l'utente.
Di conseguenza, sorge la domanda: cosa dire delle interazioni complesse tra diversi servizi controllati da team diversi? Non è che traceview non è considerato lo strumento più adatto per illuminare situazioni simili?
Gli sviluppatori mobili, i proprietari di servizi stateless, i proprietari di servizi stateful gestiti (come i database) e i proprietari di piattaforme potrebbero essere interessati a un'altra rappresentazione di un sistema distribuito; traceview è una soluzione troppo universale per queste esigenze fondamentalmente diverse. Anche in un'architettura microservizi molto complessa, ai proprietari del servizio non servono conoscenze approfondite su più di due o tre servizi upstream e downstream. In sostanza, nella maggior parte degli scenari, gli utenti devono semplicemente rispondere a domande riguardanti un insieme limitato di servizi..
È come osservare un piccolo sottoinsieme di servizi attraverso una lente d'ingrandimento per uno studio scrupoloso. Questo consentirà all'utente di porre domande più urgenti riguardanti l'interazione complessa tra questi servizi e le loro dipendenze immediate. È simile a un backtrace nel mondo dei servizi, dove l'ingegnere sa cosa non va e ha anche una certa comprensione di ciò che sta accadendo nei servizi circostanti per capire perché.
Il mio approccio è completamente opposto a quello "top-down" basato su traceview, in cui l'analisi inizia dall'intero trace e poi scende gradualmente ai singoli span. Al contrario, l'approccio "bottom-up" inizia analizzando una piccola area vicina alla potenziale causa dell'incidente e poi espande il campo di ricerca se necessario (con la possibile collaborazione di altri team per analizzare un'ampia gamma di servizi). Questo secondo approccio è meglio adattato per verifiche rapide delle ipotesi iniziali. Una volta ottenuti risultati concreti, si può passare a un'analisi più mirata e dettagliata.
Costruzione della topologia
Rappresentazioni legate a un servizio specifico possono essere incredibilmente utili se l'utente sa quale servizio o gruppo di servizi è responsabile dell'aumento delle latenze o è la fonte di errori. Tuttavia, in un sistema complesso, identificare il servizio colpevole può rivelarsi un compito non triviale durante un guasto, specialmente se non ci sono messaggi di errore dai servizi.
La costruzione di una topologia dei servizi può aiutare notevolmente a identificare quale servizio presenta un picco nella frequenza degli errori o un aumento della latenza, che comportano un deterioramento significativo delle prestazioni del servizio. Parlando di costruzione della topologia, non mi riferisco a una mappa dei servizi, che mostra ogni servizio esistente nel sistema e noto per le sue . Questa rappresentazione non è migliore di un traceview basato su un grafo diretto aciclico. Preferirei invece vedere una topologia dei servizi generata dinamicamente, basata su determinati attributi, come la frequenza degli errori, il tempo di risposta o qualsiasi parametro fornito dall'utente che aiuti a chiarire la situazione con specifici servizi sospetti.
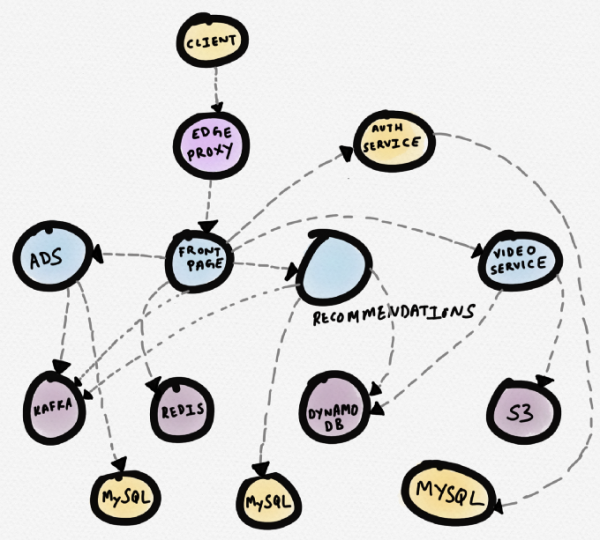
Facciamo un esempio. Immaginiamo un ipotetico sito di notizie. Il servizio della homepage (front page) scambia dati con Redis, con il servizio di raccomandazione, con il servizio pubblicitario e il servizio video. Il servizio video prende i video da S3, mentre i metadati provengono da DynamoDB. Il servizio di raccomandazione riceve metadati da DynamoDB, carica dati da Redis e MySQL, e scrive messaggi in Kafka. Il servizio pubblicitario riceve dati da MySQL e scrive messaggi in Kafka.
Di seguito è riportata un'immagine schematica di questa topologia (molti programmi commerciali per il tracciamento costruiscono topologie simili). Può essere utile se hai bisogno di comprendere le dipendenze dei servizi. Tuttavia, durante di debug, quando un certo servizio (ad esempio, il servizio video) mostra un tempo di risposta aumentato, una topologia del genere non è molto utile.
Schema dei servizi di un ipotetico sito di notizie
Sarebbe stata più appropriata una diagramma, raffigurato qui sotto. In esso, il servizio problematico (video) è rappresentato proprio al centro. L'utente lo nota subito. Da questa visualizzazione diventa chiaro che il servizio video funziona in modo anomalo a causa dell'aumento del tempo di risposta di S3, il che influisce sulla velocità di caricamento di una parte della homepage.
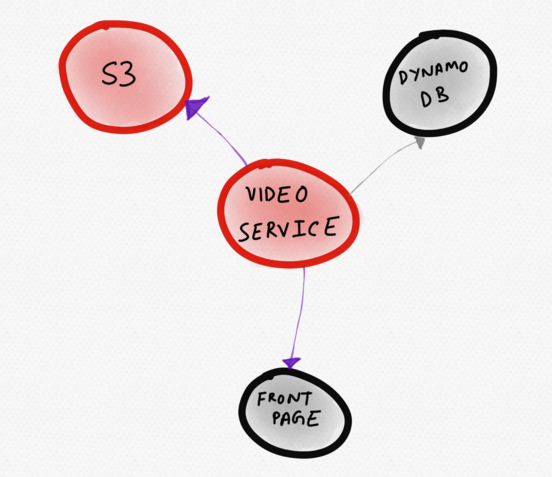
Topologia dinamica che mostra solo i servizi "interessanti"
Le diagrammi topologici generati dinamicamente possono risultare più efficienti rispetto alle mappe statiche dei servizi, soprattutto in infrastrutture elastiche e auto-scalabili. La possibilità di confrontare e mettere a confronto le topologie dei servizi permette all'utente di porre domande più pertinenti. Domande più precise sul sistema portano con maggiore probabilità a una migliore comprensione di come funziona il sistema.
Visualizzazione comparativa
Un'altra visualizzazione utile sarà la visualizzazione comparativa. Attualmente, i trace non si prestano molto bene al confronto affiancato, quindi di solito vengono comparati gli span. E l'idea principale di questo articolo è che gli span sono troppo a basso livello per estrarre le informazioni più preziose dai risultati delle tracce.
Il confronto di due trace non richiede nuove visualizzazioni fondamentali. In realtà, è sufficiente qualcosa come un istogramma che rappresenti le stesse informazioni di traceview. È sorprendente, ma anche questo metodo semplice può portare risultati molto migliori rispetto all'analisi di due trace separatamente. Sarebbe ancora più potente la possibilità di visualizzare il confronto delle trace nel complesso. Sarebbe estremamente utile vedere come un recente cambiamento di configurazione del database con l'inclusione del GC (garbage collection) influisce sui tempi di risposta del servizio downstream su un periodo di diverse ore. Se ciò che descrivo qui sembra simile a un'analisi A/B dell'impatto dei cambiamenti infrastrutturali in molteplici servizi , attraverso i risultati della tracciatura, non sei troppo lontano dalla verità.
Conclusione
Non metto in dubbio l'utilità del tracciamento stesso. Credo sinceramente che non esista un altro metodo per raccogliere dati così ricchi, informali e contestuali come quelli contenuti nel trace. Tuttavia, considero anche che tutte le soluzioni di tracciamento utilizzino questi dati in modo estremamente inefficace. Finché gli strumenti di tracciamento saranno bloccati nella visualizzazione traceview, saranno limitati nella loro capacità di sfruttare al massimo le informazioni preziose che possono essere estratte dai dati contenuti nei trace. Inoltre, c'è il rischio di sviluppare un'interfaccia visuale completamente poco user-friendly e poco intuitiva, che limiterà notevolmente la capacità dell'utente di risolvere i problemi nell'applicazione.
Il debugging di sistemi complessi, anche con l'uso degli strumenti più recenti, è incredibilmente difficile. Gli strumenti dovrebbero aiutare gli sviluppatori a formulare e testare ipotesi, fornendo attivamente informazioni rilevanti, identificando picchi e notando caratteristiche nella distribuzione dei ritardi. Affinché il tracing diventi lo strumento preferito dagli sviluppatori per risolvere i guasti in produzione o affrontare problemi che coinvolgono vari servizi, è necessario avere interfacce utente originali e visualizzazioni più in linea con il modello mentale degli sviluppatori che creano e gestiscono questi servizi.
Saranno necessarie notevoli capacità mentali per progettare un sistema in grado di presentare i diversi segnali disponibili nei risultati del tracing in un modo ottimizzato per facilitare l'analisi e il ragionamento. È necessario riflettere su come astrarre la topologia del sistema durante il debugging in modo da aiutare l'utente a superare le aree cieche, senza dover esaminare singoli trace o span.
Abbiamo bisogno di buone opportunità di astrazione e suddivisione a livelli (soprattutto nell'interfaccia utente). Queste dovrebbero integrarsi bene nel processo di debugging basato su ipotesi, dove è possibile porre domande in modo iterativo e verificare le ipotesi. Non risolveranno automaticamente tutti i problemi di osservabilità, ma aiuteranno gli utenti a raffinare l'intuizione e a formulare domande più ponderate. Invito a un approccio più riflessivo e innovativo nel campo della visualizzazione. Qui c'è una reale opportunità di ampliare gli orizzonti.
P.S. dal traduttore
Leggete anche nel nostro blog:
- «»;
- «»;
- «».
Fonte: habr.com
