

Ciao, membri di Habr. Come abbiamo già scritto, questo mese OTUS lancia due corsi di machine learning, ovvero e . Pertanto, continuiamo a condividere materiale utile.
L'obiettivo di questo articolo è raccontare la nostra prima esperienza con .
Inizieremo con la review del suo server di tracking e possiamo registrare tutte le iterazioni della ricerca. Poi condivideremo l'esperienza di collegare Spark a MLflow tramite UDF.
Contesto
Noi di utilizza machine learning e intelligenza artificiale per dare alle persone la possibilità di prendersi cura della propria salute e benessere. Pertanto, i modelli di machine learning sono alla base dei prodotti di trattamento dati che sviluppiamo, ed è per questo che abbiamo prestato attenzione a MLflow: una piattaforma open source che copre tutti gli aspetti del ciclo di vita del machine learning.
MLflow
L'obiettivo principale di MLflow è fornire uno strato aggiuntivo sopra il machine learning, che consenta agli specialisti di data science di lavorare praticamente con qualsiasi libreria di machine learning (, , , , e ), portando il suo lavoro a un livello superiore.
MLflow offre tre componenti:
- Tracking – registrazione e richieste per esperimenti: codice, dati, configurazione e risultati. È molto importante monitorare il processo di creazione del modello.
- Progetti – formato di packaging per l'esecuzione su qualsiasi piattaforma (ad esempio, )
- Modelli – formato generale per l'invio di modelli a diversi strumenti di distribuzione.
MLflow (al momento della scrittura è in versione alpha) è una piattaforma open-source che consente di gestire il ciclo di vita del machine learning, compresi esperimenti, riutilizzo e distribuzione.
Configurazione di MLflow
Per utilizzare MLflow, è necessario prima configurare l'intero ambiente Python, a tal fine utilizzeremo (per installare Python su Mac, consulta ). In questo modo possiamo creare un ambiente virtuale in cui installeremo tutte le librerie necessarie per l'esecuzione.
`
pyenv install 3.7.0
pyenv global 3.7.0 # Usa Python 3.7
mkvirtualenv mlflow # Crea un ambiente virtuale con Python 3.7
workon mlflow
`Installeremo le librerie richieste.
`
pip install mlflow==0.7.0
Cython==0.29
numpy==1.14.5
pandas==0.23.4
pyarrow==0.11.0
`Nota: utilizziamo PyArrow per eseguire modelli come UDF. Le versioni di PyArrow e Numpy devono essere corrette, poiché le ultime versioni erano in conflitto tra loro.
Avviamo Tracking UI
MLflow Tracking ci consente di registrare e interrogare gli esperimenti utilizzando Python e API. Inoltre, è possibile definire dove memorizzare gli artifact del modello (localhost, , , o ). Poiché in Alpha Health utilizziamo AWS, S3 sarà il nostro storage per gli artifact.
# Running a Tracking Server
mlflow server
--file-store /tmp/mlflow/fileStore
--default-artifact-root s3://<bucket>/mlflow/artifacts/
--host localhost
--port 5000 MLflow consiglia di utilizzare uno storage di file persistente. Lo storage di file è il luogo dove il server memorizzerà i metadati delle esecuzioni e degli esperimenti. Quando avvii il server, assicurati che punti a uno storage di file persistente. Per questo esperimento useremo semplicemente /tmp.
Ricorda che, se vogliamo utilizzare il server mlflow per eseguire vecchi esperimenti, devono essere presenti nello storage di file. Tuttavia, anche senza questo, potremmo utilizzarli in UDF, poiché abbiamo solo bisogno del percorso verso il modello.
Nota: Tieni presente che Tracking UI e il client del modello devono avere accesso alla posizione dell'artifact. Ciò significa che, indipendentemente dal fatto che Tracking UI si trovi in un'istanza EC2, quando MLflow viene avviato localmente, la macchina deve avere accesso diretto a S3 per scrivere gli artifact dei modelli.
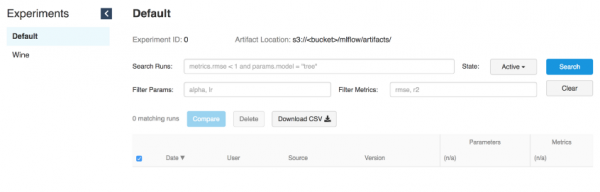
L'interfaccia di tracciamento conserva gli artefatti nel bucket S3
Avvio dei modelli
Non appena il server di tracciamento sarà operativo, sarà possibile iniziare ad addestrare i modelli.
Come esempio, utilizzeremo la modifica wine dall'esempio MLflow in .
MLFLOW_TRACKING_URI=http://localhost:5000 python wine_quality.py
--alpha 0.9
--l1_ratio 0.5
--wine_file ./data/winequality-red.csvCome abbiamo già detto, MLflow consente di registrare parametri, metriche e artefatti dei modelli per monitorare come si sviluppano nel corso delle iterazioni. Questa funzionalità è estremamente utile in quanto ci permette di riprodurre il miglior modello, consultando il server di tracciamento o comprendendo quale codice ha eseguito l'iterazione necessaria, utilizzando i log degli hash dei commit di git.
with mlflow.start_run():
... model ...
mlflow.log_param("source", wine_path)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.set_tag('domain', 'wine')
mlflow.set_tag('predict', 'quality')
mlflow.sklearn.log_model(lr, "model") 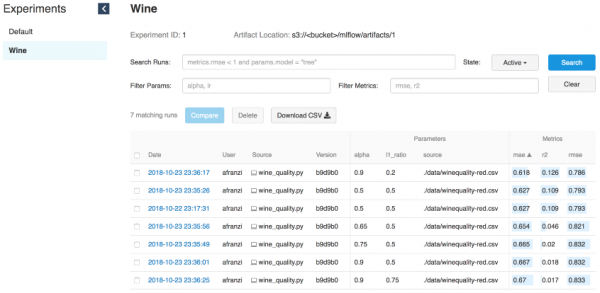
Iterazioni wine
Backend per il modello
Il server di monitoraggio MLflow, avviato con il comando “mlflow server”, dispone di un'API REST per tenere traccia delle esecuzioni e registrare i dati nel file system locale. Puoi specificare l'indirizzo del server di monitoraggio tramite la variabile ambiente «MLFLOW_TRACKING_URI» e l'API di monitoraggio di MLflow si collegherà automaticamente al server di monitoraggio all'indirizzo fornito per creare/ottenere informazioni sulle esecuzioni, metriche log e così via.
Fonte:
Per servire un modello, abbiamo bisogno di un server di monitoraggio avviato (vedi interfaccia di avvio) e dell'ID dell'esecuzione del modello.

ID dell'esecuzione
# Serve a sklearn model through 127.0.0.0:5005
MLFLOW_TRACKING_URI=http://0.0.0.0:5000 mlflow sklearn serve
--port 5005
--run_id 0f8691808e914d1087cf097a08730f17
--model-path model Per gestire i modelli tramite la funzionalità MLflow serve, abbiamo bisogno di accesso all'interfaccia utente di monitoraggio, per ottenere informazioni sul modello semplicemente specificando --run_id.
Una volta che il modello si collega al server di monitoraggio, possiamo ottenere un nuovo endpoint per il modello.
# Query Tracking Server Endpoint
curl -X POST
http://127.0.0.1:5005/invocations
-H 'Content-Type: application/json'
-d '[
{
"fixed acidity": 3.42,
"volatile acidity": 1.66,
"citric acid": 0.48,
"residual sugar": 4.2,
"chloridessssss": 0.229,
"free sulfur dsioxide": 19,
"total sulfur dioxide": 25,
"density": 1.98,
"pH": 5.33,
"sulphates": 4.39,
"alcohol": 10.8
}
]'
> {"predictions": [5.825055635303461]}Esecuzione di modelli da Spark
Sebbene il server di monitoraggio sia abbastanza potente per servire modelli in tempo reale, il loro addestramento e utilizzo della funzionalità serve (fonte: ), l'uso di Spark (batch o streaming) è una soluzione ancora più potente grazie alla sua distribuzione.
Immagina di aver appena completato un allenamento offline e poi applicato il modello risultante a tutti i tuoi dati. È qui che Spark e MLflow mostrano il loro meglio.
Installiamo PySpark + Jupyter + Spark
Fonte:
Per mostrare come applichiamo i modelli MLflow ai dataframe di Spark, dobbiamo configurare la collaborazione tra Jupyter notebooks e PySpark.
Inizia installando l'ultima versione stabile :
cd ~/Downloads/
tar -xzf spark-2.4.3-bin-hadoop2.7.tgz
mv ~/Downloads/spark-2.4.3-bin-hadoop2.7 ~/
ln -s ~/spark-2.4.3-bin-hadoop2.7 ~/sparkInstalla PySpark e Jupyter in un ambiente virtuale:
pip install pyspark jupyterConfigura le variabili di ambiente:
export SPARK_HOME=~/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook --notebook-dir=${HOME}/Projects/notebooks" Definendo notebook-dir, saremo in grado di archiviare i nostri notebook nella cartella desiderata.
Avviamo Jupyter da PySpark
Poiché siamo riusciti a configurare Jupiter come driver PySpark, ora possiamo eseguire il Jupyter notebook nel contesto di PySpark.
(mlflow) afranzi:~$ pyspark
[I 19:05:01.572 NotebookApp] estensione sparkmagic abilitata!
[I 19:05:01.573 NotebookApp] Servendo notebook dalla directory locale: /Users/afranzi/Projects/notebooks
[I 19:05:01.573 NotebookApp] Il Jupyter Notebook è in esecuzione su:
[I 19:05:01.573 NotebookApp] http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
[I 19:05:01.573 NotebookApp] Usa Control-C per fermare questo server e chiudere tutti i kernel (due volte per saltare la conferma).
[C 19:05:01.574 NotebookApp]
Copia/incolla questo URL nel tuo browser quando ti connetti per la prima volta,
per accedere con un token:
http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745 
Come menzionato sopra, MLflow offre la funzionalità di logging degli artefatti del modello in S3. Una volta che abbiamo a disposizione il modello selezionato, abbiamo la possibilità di importarlo come UDF utilizzando il modulo mlflow.pyfunc.
import mlflow.pyfunc
model_path = 's3:///mlflow/artifacts/1/0f8691808e914d1087cf097a08730f17/artifacts/model'
wine_path = '/Users/afranzi/Projects/data/winequality-red.csv'
wine_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = spark.read.format("csv").option("header", "true").option('delimiter', ';').load(wine_path)
columns = [ "fixed acidity", "volatile acidity", "citric acid",
"residual sugar", "chlorides", "free sulfur dioxide",
"total sulfur dioxide", "density", "pH",
"sulphates", "alcohol"
]
df.withColumn('prediction', wine_udf(*columns)).show(100, False) 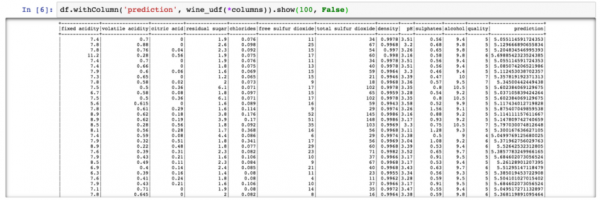
PySpark – Previsione della qualità del vino
Fino ad ora abbiamo parlato di come utilizzare PySpark con MLflow, eseguendo previsioni sulla qualità del vino su tutto il dataset del vino. Ma cosa fare se è necessario utilizzare i moduli Python MLflow da Scala Spark?
Abbiamo testato anche questo, dividendo il contesto Spark tra Scala e Python. In altre parole, abbiamo registrato un UDF MLflow in Python e l'abbiamo utilizzato da Scala (sì, potrebbe non essere la soluzione migliore, ma è ciò che abbiamo).
Scala Spark + MLflow
Per questo esempio, aggiungeremo nel nostro Jupyter esistente.
Installiamo Spark + Toree + Jupyter
pip install toree
jupyter toree install --spark_home=${SPARK_HOME} --sys-prefix
jupyter kernelspec list
```
```
Kernel disponibili:
apache_toree_scala /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/apache_toree_scala
python3 /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/python3
```Come si può vedere dal notebook allegato, l'UDF viene utilizzato sia da Spark che da PySpark. Ci auguriamo che questa parte sarà utile a chi ama Scala e desidera distribuire modelli di machine learning in produzione.
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{Column, DataFrame}
import scala.util.matching.Regex
val FirstAtRe: Regex = "^_".r
val AliasRe: Regex = "[\s_.:@]+".r
def getFieldAlias(field_name: String): String = {
FirstAtRe.replaceAllIn(AliasRe.replaceAllIn(field_name, "_"), "")
}
def selectFieldsNormalized(columns: List[String])(df: DataFrame): DataFrame = {
val fieldsToSelect: List[Column] = columns.map(field =>
col(field).as(getFieldAlias(field))
)
df.select(fieldsToSelect: _*)
}
def normalizeSchema(df: DataFrame): DataFrame = {
val schema = df.columns.toList
df.transform(selectFieldsNormalized(schema))
}
FirstAtRe = ^_
AliasRe = [s_.:@]+
getFieldAlias: (field_name: String)String
selectFieldsNormalized: (columns: List[String])(df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
normalizeSchema: (df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
Out[1]:
[s_.:@]+
In [2]:
val winePath = "~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv"
val modelPath = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
winePath = ~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv
modelPath = /tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
Out[2]:
/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
In [3]:
val df = spark.read
.format("csv")
.option("header", "true")
.option("delimiter", ";")
.load(winePath)
.transform(normalizeSchema)
df = [fixed_acidity: string, volatile_acidity: string ... 10 more fields]
Out[3]:
[fixed_acidity: string, volatile_acidity: string ... 10 more fields]
In [4]:
%%PySpark
import mlflow
from mlflow import pyfunc
model_path = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
wine_quality_udf = mlflow.pyfunc.spark_udf(spark, model_path)
spark.udf.register("wineQuality", wine_quality_udf)
Out[4]:
<function spark_udf..predict at 0x1116a98c8>
In [6]:
df.createOrReplaceTempView("wines")
In [10]:
%%SQL
SELECT
quality,
wineQuality(
fixed_acidity,
volatile_acidity,
citric_acid,
residual_sugar,
chlorides,
free_sulfur_dioxide,
total_sulfur_dioxide,
density,
pH,
sulphates,
alcohol
) AS prediction
FROM wines
LIMIT 10
Out[10]:
+-------+------------------+
|quality| prediction|
+-------+------------------+
| 5| 5.576883967129615|
| 5| 5.50664776916154|
| 5| 5.525504822954496|
| 6| 5.504311247097457|
| 5| 5.576883967129615|
| 5|5.5556903912725755|
| 5| 5.467882654744997|
| 7| 5.710602976324739|
| 7| 5.657319539336507|
| 5| 5.345098606538708|
+-------+------------------+
In [17]:
spark.catalog.listFunctions.filter('name like "%wineQuality%").show(20, false)
+-----------+--------+-----------+---------+-----------+
|name |database|description|className|isTemporary|
+-----------+--------+-----------+---------+-----------+
|wineQuality|null |null |null |true |
+-----------+--------+-----------+---------+-----------+
Prossimi passi
Nonostante al momento della scrittura di questo articolo MLflow si trovi in versione Alpha, appare piuttosto promettente. La possibilità di eseguire più framework di machine learning e utilizzarli da un unico endpoint porta i sistemi di raccomandazione a un nuovo livello.
Inoltre, MLflow avvicina gli ingegneri dei dati e i professionisti del Data Science, creando uno strato comune tra loro.
Dopo questa ricerca su MLflow, siamo certi che continueremo a utilizzarlo per i nostri pipeline Spark e nei sistemi di raccomandazione.
Sarebbe utile sincronizzare lo storage dei file con un database, invece di una semplice file system. In questo modo dovremmo ottenere diversi endpoint che possono utilizzare lo stesso storage. Ad esempio, utilizzare più istanze e con lo stesso Glue metastore.
In conclusione, vogliamo ringraziare la comunità MLFlow per rendere il nostro lavoro con i dati più interessante.
Se stai esplorando MLflow, non esitare a scriverci e raccontarci come lo utilizzi, specialmente se lo stai usando in produzione.
Scopri di più sui corsi:
Leggi di più:
Fonte: habr.com
