

Ricordiamo che l'Elastic Stack si basa sul database non relazionale Elasticsearch, sull'interfaccia web Kibana e su collettori ed elaboratori di dati (il più famoso Logstash, vari Beats, APM e altri). Una delle belle aggiunte all'intero stack di prodotti elencati è l'analisi dei dati utilizzando algoritmi di apprendimento automatico. Nell'articolo capiamo cosa sono questi algoritmi. Per favore, sotto cat.
L'apprendimento automatico è una funzionalità a pagamento dello shareware Elastic Stack ed è inclusa nell'X-Pack. Per iniziare ad usarlo basta attivare la prova di 30 giorni dopo l'installazione. Una volta scaduto il periodo di prova, puoi richiedere supporto per estenderlo o acquistare un abbonamento. Il costo di un abbonamento non viene calcolato in base al volume di dati, ma al numero di nodi utilizzati. No, il volume dei dati, ovviamente, influisce sul numero di nodi richiesti, ma questo approccio alla licenza è comunque più umano rispetto al budget dell'azienda. Se non è necessaria un'elevata produttività, puoi risparmiare denaro.
ML nell'Elastic Stack è scritto in C++ e viene eseguito all'esterno della JVM, in cui viene eseguito lo stesso Elasticsearch. Cioè, il processo (a proposito, si chiama rilevamento automatico) consuma tutto ciò che la JVM non ingoia. In uno stand dimostrativo questo non è così critico, ma in un ambiente di produzione è importante allocare nodi separati per le attività ML.
Gli algoritmi di apprendimento automatico rientrano in due categorie: − и . Nell’Elastic Stack, l’algoritmo rientra nella categoria “non supervisionata”. Di Puoi vedere l'apparato matematico degli algoritmi di apprendimento automatico.
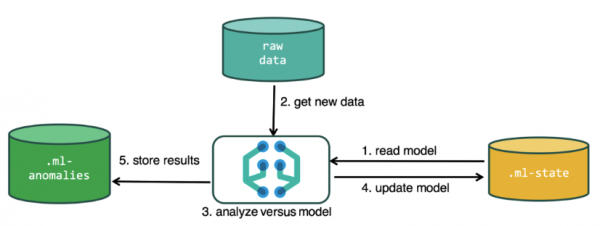
Per eseguire l'analisi, l'algoritmo di machine learning utilizza i dati archiviati negli indici Elasticsearch. Puoi creare attività per l'analisi sia dall'interfaccia Kibana che tramite l'API. Se lo fai tramite Kibana, non hai bisogno di sapere alcune cose. Ad esempio, indici aggiuntivi utilizzati dall'algoritmo durante il suo funzionamento.
Indici aggiuntivi utilizzati nel processo di analisi.ml-state: informazioni sui modelli statistici (impostazioni di analisi);
.ml-anomalies-*: risultati degli algoritmi ML;
.ml-notifications: impostazioni per le notifiche basate sui risultati dell'analisi.
La struttura dei dati nel database Elasticsearch è costituita da indici e documenti in essi archiviati. Rispetto a un database relazionale, un indice può essere paragonato a uno schema di database e un documento a un record in una tabella. Questo confronto è condizionato e viene fornito per semplificare la comprensione di ulteriore materiale per coloro che hanno solo sentito parlare di Elasticsearch.
La stessa funzionalità è disponibile tramite API come tramite l'interfaccia web, quindi per chiarezza e comprensione dei concetti, mostreremo come configurarla tramite Kibana. Nel menu a sinistra è presente una sezione Machine Learning in cui è possibile creare un nuovo Job. Nell'interfaccia Kibana appare come l'immagine qui sotto. Ora analizzeremo ciascun tipo di attività e mostreremo i tipi di analisi che possono essere costruiti qui.
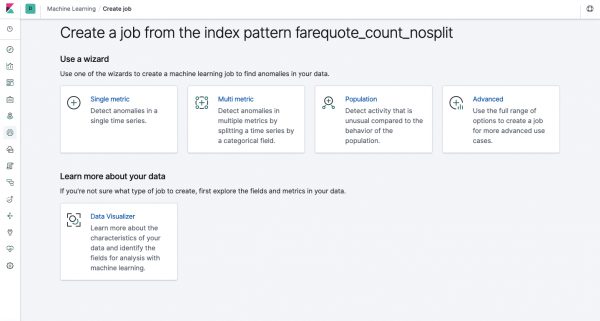
Metrica singola: analisi di una metrica, Multi metrica: analisi di due o più metriche. In entrambi i casi, ogni metrica viene analizzata in un ambiente isolato, vale a dire l'algoritmo non tiene conto del comportamento delle metriche analizzate parallelamente, come potrebbe sembrare nel caso di Multi Metric. Per eseguire calcoli tenendo conto della correlazione di varie metriche, è possibile utilizzare l'analisi della popolazione. E Advanced sta perfezionando gli algoritmi con opzioni aggiuntive per determinate attività.
Singola metrica
Analizzare i cambiamenti in una singola metrica è la cosa più semplice che si possa fare qui. Dopo aver fatto clic su Crea lavoro, l'algoritmo cercherà le anomalie.
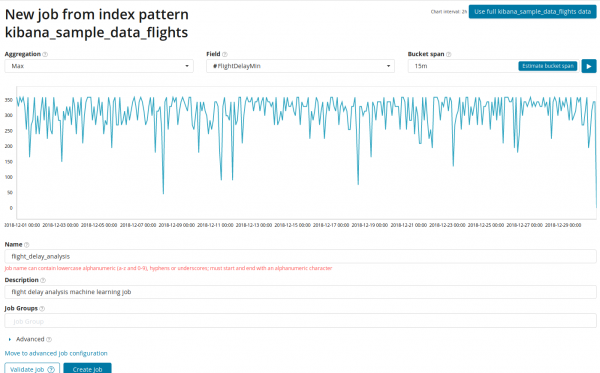
Nel campo Aggregazione puoi scegliere un approccio alla ricerca di anomalie. Ad esempio, quando Min valori inferiori ai valori tipici saranno considerati anomali. Mangiare Max, Alto, Medio, Basso, Medio, Distinto e altri. È possibile trovare le descrizioni di tutte le funzioni .
Nel campo Settore indica il campo numerico presente nel documento su cui effettueremo l'analisi.
Nel campo — granularità degli intervalli sulla sequenza temporale lungo i quali verrà effettuata l'analisi. Puoi fidarti dell'automazione o scegliere manualmente. L'immagine seguente è un esempio di granularità troppo bassa: potresti non notare l'anomalia. Utilizzando questa impostazione è possibile modificare la sensibilità dell'algoritmo alle anomalie.
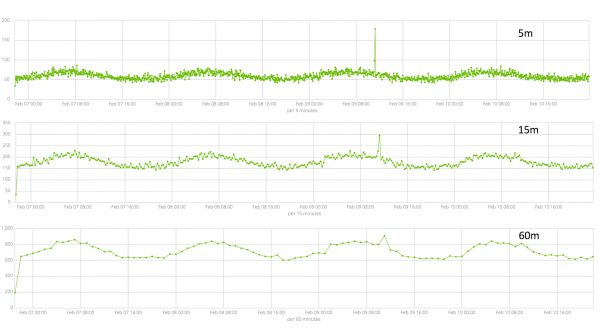
La durata dei dati raccolti è un fattore fondamentale che influisce sull’efficacia dell’analisi. Durante l'analisi, l'algoritmo identifica gli intervalli ripetuti, calcola gli intervalli di confidenza (linee di base) e identifica le anomalie - deviazioni atipiche dal comportamento abituale della metrica. Solo per esempio:
Linee di base con una piccola porzione di dati:
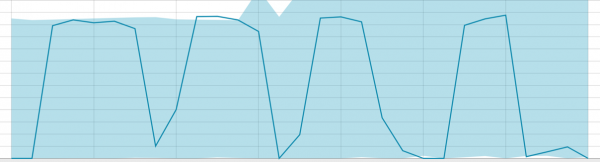
Quando l'algoritmo ha qualcosa da imparare, la linea di base assomiglia a questa:
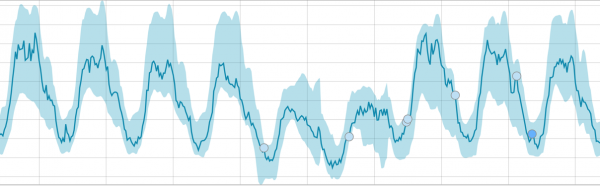
Dopo aver avviato l'attività, l'algoritmo determina le deviazioni anomale dalla norma e le classifica in base alla probabilità di un'anomalia (il colore dell'etichetta corrispondente è indicato tra parentesi):
Avvertimento (blu): meno di 25
Minore (giallo): 25-50
Maggiore (arancione): 50-75
Critico (rosso): 75-100
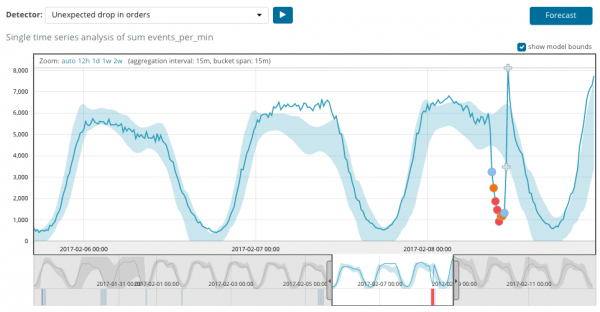
Il grafico sottostante mostra un esempio delle anomalie riscontrate.
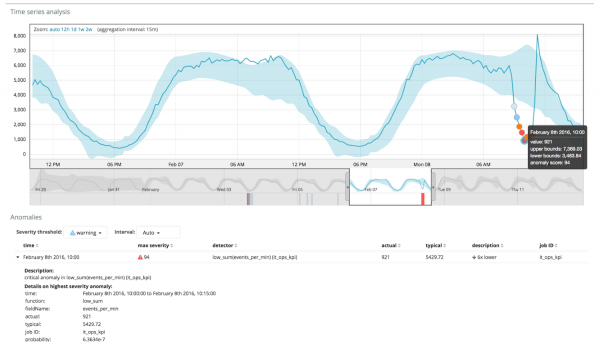
Qui puoi vedere il numero 94, che indica la probabilità di un'anomalia. È chiaro che poiché il valore è vicino a 100 significa che abbiamo un'anomalia. La colonna sotto il grafico mostra la probabilità peggiorativa pari allo 0.000063634% del valore della metrica che vi appare.
Oltre a cercare anomalie, puoi eseguire previsioni in Kibana. Questo viene fatto semplicemente e dalla stessa vista con le anomalie - pulsante Previsione nell'angolo in alto a destra.
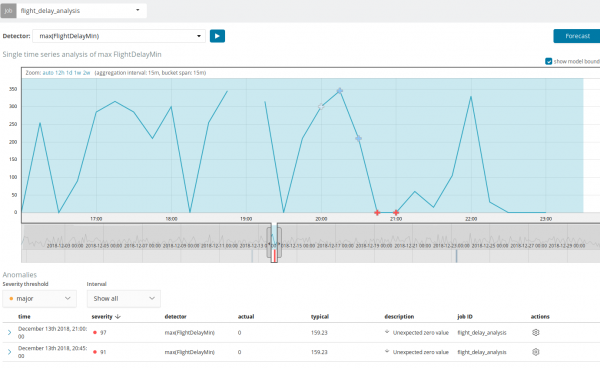
La previsione viene effettuata con un anticipo massimo di 8 settimane. Anche se lo desideri davvero, non è più possibile in base alla progettazione.
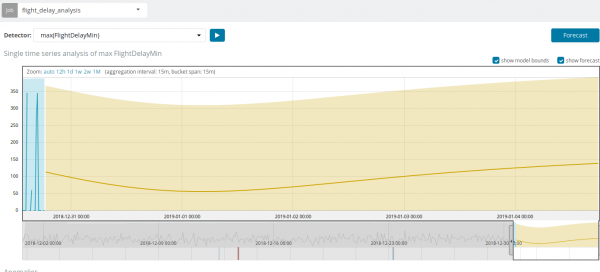
In alcune situazioni, la previsione sarà molto utile, ad esempio, quando si monitora il carico degli utenti sull'infrastruttura.
Multimetrico
Passiamo alla successiva funzionalità ML nell'Elastic Stack: analisi di diversi parametri in un unico batch. Ma ciò non significa che verrà analizzata la dipendenza di un parametro dall’altro. È uguale a Metrica singola, ma con più metriche su una schermata per un facile confronto dell'impatto di una sull'altra. Parleremo dell'analisi della dipendenza di una metrica da un'altra nella sezione Popolazione.
Dopo aver cliccato sul quadrato con Multi Metric, apparirà una finestra con le impostazioni. Diamo un'occhiata a loro in modo più dettagliato.
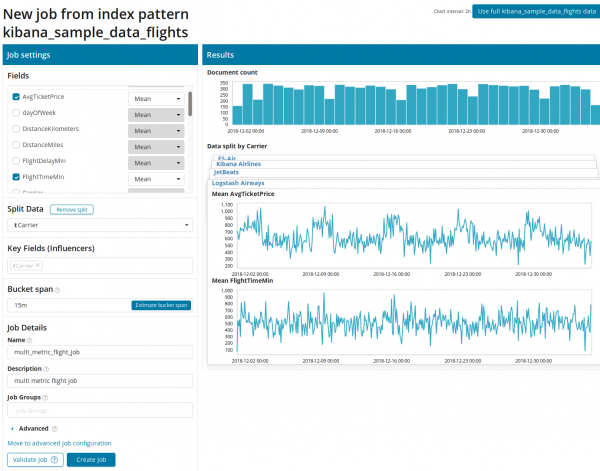
Per prima cosa è necessario selezionare i campi per l'analisi e l'aggregazione dei dati su di essi. Le opzioni di aggregazione qui sono le stesse di Metrica singola (Max, Alto, Medio, Basso, Medio, Distinto e altri). Inoltre, se lo si desidera, i dati vengono suddivisi in uno dei campi (campo Split Data). Nell'esempio, lo abbiamo fatto per campo ID aeroporto origine. Tieni presente che il grafico delle metriche sulla destra è ora presentato come grafici multipli.
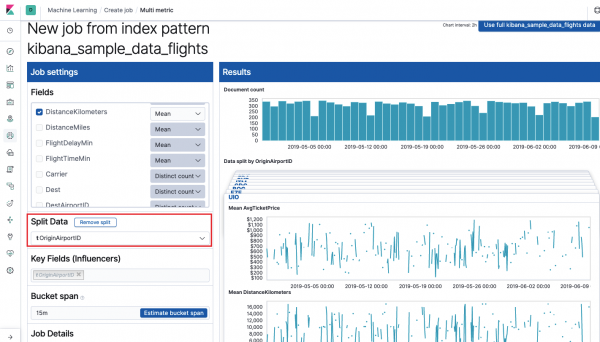
Campo Campi chiave (influencer) influisce direttamente sulle anomalie rilevate. Per impostazione predefinita ci sarà sempre almeno un valore qui e puoi aggiungerne altri. L'algoritmo terrà conto dell'influenza di questi campi durante l'analisi e mostrerà i valori più “influenti”.
Dopo il lancio, nell'interfaccia di Kibana apparirà qualcosa di simile.
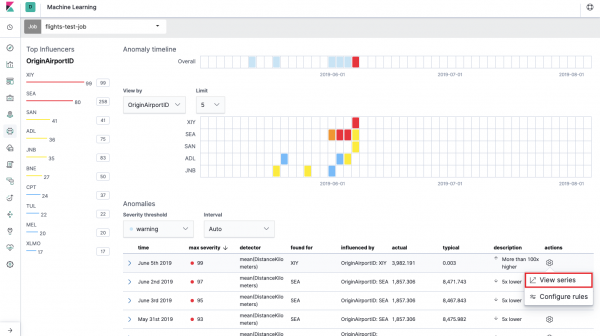
Questo è il cosiddetto mappa termica delle anomalie per ciascun valore di campo ID aeroporto origine, che abbiamo indicato in Split Data. Come nel caso della metrica singola, il colore indica il livello di deviazione anomala. Conviene fare un'analisi simile, ad esempio, sulle postazioni di lavoro per rintracciare quelle con un numero di autorizzazioni sospettosamente elevato, ecc. Abbiamo già scritto , che possono essere raccolti e analizzati anche qui.
Sotto la mappa termica è presente un elenco di anomalie, da ciascuna è possibile passare alla visualizzazione Metrica singola per un'analisi dettagliata.
Profilo demografico
Per cercare anomalie tra le correlazioni tra diversi parametri, Elastic Stack dispone di un'analisi specializzata della popolazione. È con il suo aiuto che si possono cercare valori anomali nel rendimento di un server rispetto ad altri quando, ad esempio, aumenta il numero di richieste al sistema di destinazione.
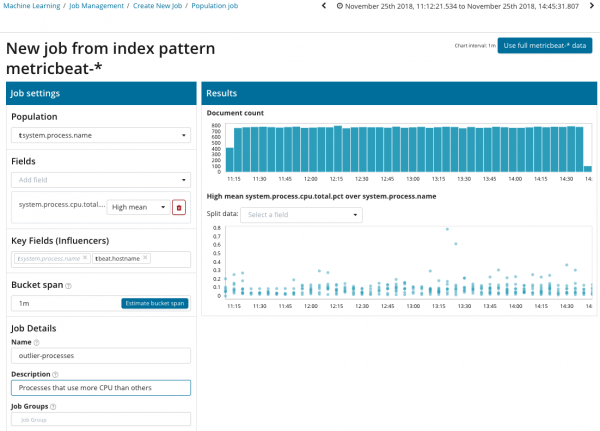
In questa illustrazione, il campo Popolazione indica il valore a cui si riferiranno le metriche analizzate. In questo caso è il nome del processo. Di conseguenza, vedremo come il carico del processore di ciascun processo si influenza a vicenda.
Si prega di notare che il grafico dei dati analizzati differisce dai casi con Single Metric e Multi Metric. Ciò è stato fatto a Kibana in base alla progettazione per una migliore percezione della distribuzione dei valori dei dati analizzati.
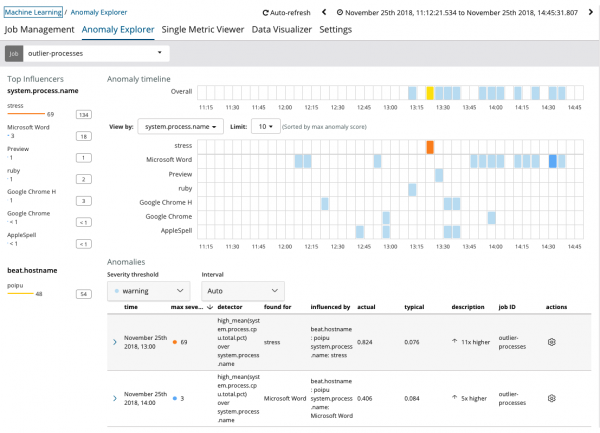
Il grafico mostra che il processo si è comportato in modo anomalo stress (a proposito, generato da un'utilità speciale) sul server poipu, che ha influenzato (o si è rivelato un influencer) il verificarsi di questa anomalia.
Filtri
Analisi con messa a punto. Con l'analisi avanzata, in Kibana vengono visualizzate impostazioni aggiuntive. Dopo aver fatto clic sul riquadro Avanzate nel menu di creazione, viene visualizzata questa finestra con schede. Tab Dettagli di lavoro L'abbiamo saltato di proposito, ci sono impostazioni di base non direttamente correlate all'impostazione dell'analisi.
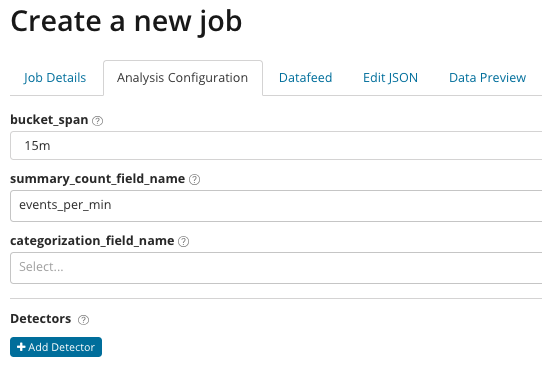
В summary_count_field_name Facoltativamente, è possibile specificare il nome di un campo da documenti contenenti valori aggregati. In questo esempio, il numero di eventi al minuto. IN indica il nome e il valore di un campo del documento che contiene un valore variabile. Utilizzando la maschera presente in questo campo è possibile suddividere i dati analizzati in sottoinsiemi. Presta attenzione al pulsante Aggiungi rilevatore nell'illustrazione precedente. Di seguito è riportato il risultato della selezione di questo pulsante.
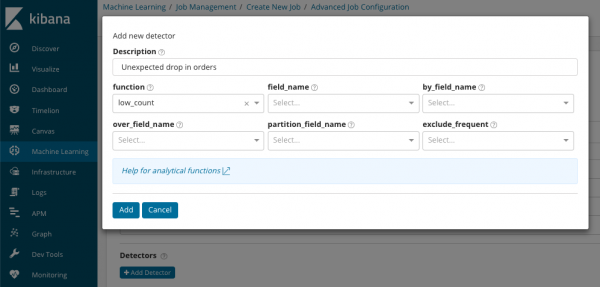
Ecco un ulteriore blocco di impostazioni per configurare il rilevatore di anomalie per un'attività specifica. Intendiamo discutere casi d'uso specifici (in particolare quelli di sicurezza) nei seguenti articoli. Per esempio, uno dei casi smontati. È associato alla ricerca di valori che appaiono raramente e viene implementato .
Nel campo funzione È possibile selezionare una funzione specifica per la ricerca delle anomalie. Tranne raro, ci sono un paio di funzioni più interessanti: . Identificano rispettivamente le anomalie nel comportamento dei parametri durante il giorno o la settimana. Altre funzioni di analisi .
В field_name indica il campo del documento su cui verrà effettuata l'analisi. Per_nome_campo può essere utilizzato per separare i risultati dell'analisi per ogni singolo valore del campo del documento qui specificato. Se riempi over_field_name ottieni l'analisi della popolazione di cui abbiamo discusso sopra. Se specifichi un valore in nome_campo_partizione, quindi per questo campo del documento verranno calcolate linee di base separate per ciascun valore (il valore può essere, ad esempio, il nome del server o del processo sul server). IN esclude_frequente può scegliere contro tutti i o nessuna, il che significa escludere (o includere) i valori dei campi del documento ricorrenti.
In questo articolo abbiamo cercato di dare un’idea quanto più sintetica possibile delle capacità del machine learning nell’Elastic Stack; ci sono ancora molti dettagli lasciati dietro le quinte. Raccontaci nei commenti quali casi sei riuscito a risolvere utilizzando Elastic Stack e per quali attività lo utilizzi. Per contattarci potete utilizzare i messaggi personali su Habré oppure .
Fonte: habr.com
