

Nell'articolo precedente, ho parlato delle basi del DATA VAULT, descrivendo gli elementi principali del DATA VAULT e il loro utilizzo. Tuttavia, non si può considerare esaurito l'argomento DATA VAULT; è necessario discutere le fasi successive dell'evoluzione del DATA VAULT.
In questo articolo, mi concentrerò sullo sviluppo del DATA VAULT e sulla transizione verso il BUSINESS DATA VAULT, o semplicemente BUSINESS VAULT.
Motivi della nascita del BUSINESS DATA VAULT
Va notato che, pur avendo alcuni punti di forza, il DATA VAULT non è privo di svantaggi. Uno di questi è la complessità nella scrittura di query analitiche. Le query presentano un numero significativo di JOIN, il codice diventa lungo e ingombrante. Inoltre, i dati che entrano nel DATA VAULT non subiscono alcuna trasformazione, quindi, dal punto di vista aziendale, il DATA VAULT in forma pura non ha un valore assoluto.
Proprio per affrontare queste carenze, la metodologia del DATA VAULT è stata ampliata con elementi come:
- tabelle PIT (point in time);
- tabelle BRIDGE;
- DERIVAZIONI PREDEFINITE.
Esaminiamo più nel dettaglio la funzione di questi elementi.
Tabelle PIT
In generale, un oggetto aziendale (HUB) può contenere dati con frequenze di aggiornamento diverse. Per esempio, se parliamo di dati che caratterizzano una persona, possiamo dire che le informazioni relative al numero di telefono, all'indirizzo o all'email hanno una frequenza di aggiornamento più alta rispetto ai dati come nome e cognome, numero di passaporto, stato civile o sesso.
Pertanto, quando si definiscono i satelliti, è importante tenere in considerazione la loro frequenza di aggiornamento. Perché è così importante?
Se in una tabella si memorizzano attributi con frequenze di aggiornamento diverse, dovremo aggiungere una riga alla tabella per ogni aggiornamento dell'attributo che cambia più frequentemente. Di conseguenza, avremo un aumento dello spazio su disco e un maggiore tempo di esecuzione delle query.
Ora che abbiamo suddiviso i satelliti per frequenza di aggiornamento e possiamo caricare i dati in modo indipendente, dobbiamo garantire la possibilità di ottenere dati aggiornati. È preferibile farlo senza utilizzare JOIN eccessivi.
Spiego, ad esempio, è necessario ottenere informazioni aggiornate (in base alla data dell'ultimo aggiornamento) da satelliti con frequenze di aggiornamento diverse. A tal fine, è necessario non solo effettuare un JOIN, ma anche creare diverse query annidate (per ciascun satellite contenente informazioni) con la selezione della data di aggiornamento massima MAX(Data di aggiornamento). Con ogni nuovo JOIN, tale codice si espande e diventa rapidamente complesso da comprendere.
La tabella PIT è progettata per semplificare tali richieste. Le tabelle PIT vengono compilate contemporaneamente alla registrazione di nuovi dati nel DATA VAULT. Tabella PIT:
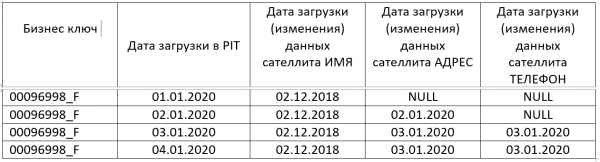
In questo modo abbiamo informazioni sulla validità dei dati per tutti i satelliti in ogni momento. Utilizzando JOIN con la tabella PIT, possiamo escludere completamente le query annidate, ovviamente con la condizione che la PIT venga riempita ogni giorno senza interruzioni. Anche se ci sono interruzioni nella PIT, è possibile ottenere dati aggiornati utilizzando solo una query annidata alla PIT stessa. Una query annidata funzionerà più velocemente rispetto a query annidate per ciascun satellite.
BRIDGE
Le tabelle di tipo BRIDGE sono utilizzate anche per semplificare le query analitiche. Tuttavia, a differenza delle PIT, servono a semplificare e velocizzare le richieste tra diversi hub, link e i loro satelliti.
La tabella contiene tutte le chiavi necessarie per tutti i satelliti che vengono frequentemente utilizzati nelle richieste. Inoltre, se necessario, le chiavi aziendali hash possono essere integrate con chiavi in forma testuale, se i nomi delle chiavi sono richiesti per l'analisi.
Il punto è che senza l'uso di BRIDGE, durante il recupero di dati situati in satelliti appartenenti a diversi hub, sarà necessario eseguire JOIN non solo tra i satelliti, ma anche tra i link che collegano gli hub.
La presenza o l'assenza di BRIDGE è determinata dalla configurazione del deposito e dalla necessità di ottimizzare la velocità di esecuzione delle query. È difficile trovare un esempio universale di BRIDGE.
DERIVAZIONI PREDEFINITE
Un altro tipo di oggetti che ci avvicina al BUSINESS DATA VAULT è rappresentato da tabelle contenenti indicatori calcolati in precedenza. Queste tabelle sono davvero importanti per le aziende, in quanto contengono informazioni aggregate secondo regole stabilite e consentono un accesso relativamente semplice.
Architettonicamente, le DERIVAZIONI PREDEFINITE non sono altro che un ulteriore satellite di un determinato hub. Proprio come un normale satellite, contiene una chiave aziendale e la data di creazione del record nel satellite. Tuttavia, le somiglianze finiscono qui. La composizione successiva degli attributi di questo 'satellite specializzato' è definita dagli utenti aziendali sulla base degli indicatori calcolati più richiesti.
Ad esempio, un hub che contiene informazioni sui dipendenti può includere un satellite con indicatori come:
- Stipendio minimo;
- Stipendio massimo;
- Stipendio medio;
- Totale accumulato dello stipendio corrisposto, ecc.
È logico includere le DERIVAZIONI PREDEFINITE nella tabella PIT di questo stesso hub, in modo da poter ottenere facilmente segmenti di dati sui dipendenti per una data specifica.
CONCLUSIONI
Come dimostra la pratica, l'uso di DATA VAULT da parte degli utenti aziendali presenta alcune difficoltà per diversi motivi:
- Il codice delle query è complesso e ingombrante;
- L'abbondanza di JOIN influisce sulle prestazioni delle query;
- Per scrivere query analitiche è necessaria una conoscenza approfondita della struttura del repository.
Per semplificare l'accesso ai dati, DATA VAULT viene ampliato con oggetti aggiuntivi:
- tabelle PIT (point in time);
- tabelle BRIDGE;
- DERIVAZIONI PREDEFINITE.
Nella prossima Intendo condividere, a mio avviso, le informazioni più interessanti per chi lavora con BI. Presenterò i metodi per creare tabelle dei fatti e tabelle delle dimensioni basate su DATA VAULT.
I materiali dell'articolo si basano su:
- Su Kenta Graziano, che contiene oltre a una descrizione dettagliata anche schemi del modello;
- Libro: «Building a Scalable Data Warehouse with DATA VAULT 2.0»;
- Articolo .
Fonte: habr.com
