

Qualche mese fa — un servizio pubblico per PostgreSQL.
Nel tempo trascorso, lo avete già utilizzato oltre 6000 volte, ma una delle funzionalità comode potrebbe essere rimasta inosservata: si tratta di suggerimenti strutturali, che appaiono più o meno così:
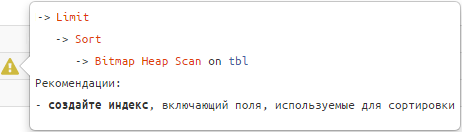
Seguitele e le vostre query diventeranno "lisce e setose". 🙂
E seriamente, molte situazioni che rendono una query lenta e "affamata" di risorse sono tipiche e possono essere riconosciute dalla struttura e dai dati del piano..
In questo caso, non sarà necessario per ogni singolo sviluppatore cercare un'opzione di ottimizzazione da solo, basandosi esclusivamente sulla propria esperienza: possiamo indicargli cosa sta succedendo, quale potrebbe essere la causa, e come avvicinarsi alla soluzione. E così abbiamo fatto.

Esaminiamo un po' più da vicino questi casi: come vengono identificati e quali raccomandazioni portano.
Per un migliore approfondimento, prima potete ascoltare il blocco corrispondente del , e poi passare all'analisi dettagliata di ogni esempio:

#1: индексная «недосортировка»
Quando si presenta
Mostra l'ultima fattura del cliente «ООО Колокольчик».
Come identificare
-> Limit
-> Sort
-> Index [Only] Scan [Backward] | Bitmap Heap Scan
Raccomandazioni
Indice utilizzato espandere i campi di ordinamento.
Esempio:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "fatti"
, (random() * 1000)::integer fk_cli; -- 1K chiavi esterne diverse
CREATE INDEX ON tbl(fk_cli); -- indice per la foreign key
SELECT
*
FROM
tbl
WHERE
fk_cli = 1 -- selezione per un legame specifico
ORDER BY
pk DESC -- vogliamo solo un "ultimo" record
LIMIT 1; 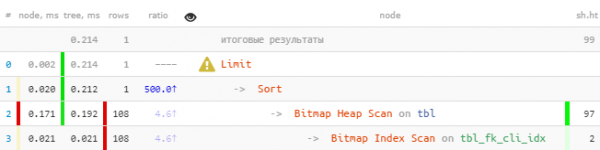
Si può subito notare che attraverso l'indice sono stati letti più di 100 record, che sono stati poi tutti ordinati, per poi lasciarne solo uno.
Correggiamo:
DROP INDEX tbl_fk_cli_idx;
CREATE INDEX ON tbl(fk_cli, pk DESC); -- aggiunto chiave di ordinamento

Anche su un campione così primitivo — 8,5 volte più veloce e 33 volte meno letture. L'effetto sarà tanto più evidente quanto più avete «fatti» per ogni valore fk.
Osservo che un tale indice funzionerà come un «indice prefissato» non peggio di prima anche su altre query con fk, dove non c'era e non c'è ordinamento per pk (è possibile leggere di più ). Inoltre, assicurerà anche un normale supporto esplicito per la foreign key su questo campo.
#2: пересечение индексов (BitmapAnd)
Quando si presenta
Mostra tutti i contratti del cliente «ООО Колокольчик», stipulati a nome di «НАО Лютик».
Come identificare
-> BitmapAnd
-> Bitmap Index Scan
-> Bitmap Index ScanRaccomandazioni
Crea indice composito sui campi di entrambi gli originali o espandere uno degli esistenti con campi dall'altro.
Esempio:
CREA TABELLA tbl COME
SELEZIONA
generate_series(1, 100000) pk -- 100K "fatti"
, (random() * 100)::integer fk_org -- 100 chiavi esterne diverse
, (random() * 1000)::integer fk_cli; -- 1K chiavi esterne diverse
CREA INDICE SU tbl(fk_org); -- indice per chiave esterna
CREA INDICE SU tbl(fk_cli); -- indice per chiave esterna
SELEZIONA
*
DA
tbl
DOVE
(fk_org, fk_cli) = (1, 999); -- filtro per una coppia specifica 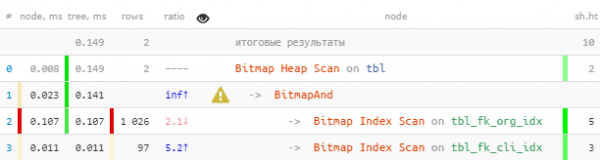
Correggiamo:
DROP INDEX tbl_fk_org_idx;
CREA INDICE SU tbl(fk_org, fk_cli);

Qui il guadagno è minore, poiché il Bitmap Heap Scan è già abbastanza efficace di per sé. Ma comunque è 7 volte più veloce e 2.5 volte meno letture.
#3: объединение индексов (BitmapOr)
Quando si presenta
Mostra i primi 20 «propri» o richieste non assegnate per l'elaborazione, dando priorità a quelle proprie.
Come identificare
-> BitmapOr
-> Bitmap Index Scan
-> Bitmap Index ScanRaccomandazioni
Usa UNIONE [TUTTE] per unire le sottoquery in ciascuno dei blocchi di condizioni OR.
Esempio:
CREA UNA TABELLA tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "fatti"
, CASE
WHEN random() < 1::real/16 THEN NULL -- con probabilità 1:16 inserimento "pareggio"
ELSE (random() * 100)::integer -- 100 chiavi esterne diverse
END fk_own;
CREA INDICE SU tbl(fk_own, pk); -- indice con ordinamento "apparentemente appropriato"
SELECT
*
FROM
tbl
WHERE
fk_own = 1 OR -- propri
fk_own IS NULL -- ... oppure "pareggi"
ORDER BY
pk
, (fk_own = 1) DESC -- prima "propri"
LIMIT 20;
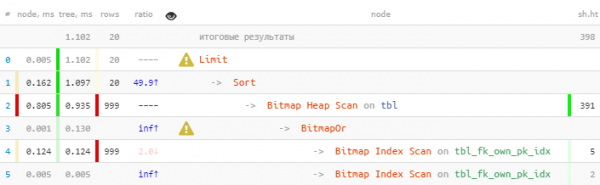
Correggiamo:
(
SELECT
*
FROM
tbl
WHERE
fk_own = 1 -- prima "propri" 20
ORDER BY
pk
LIMIT 20
)
UNIONE TUTTO
(
SELECT
*
FROM
tbl
WHERE
fk_own IS NULL -- poi "pareggi" 20
ORDER BY
pk
LIMIT 20
)
LIMIT 20; -- ma in totale - 20, non serve di più 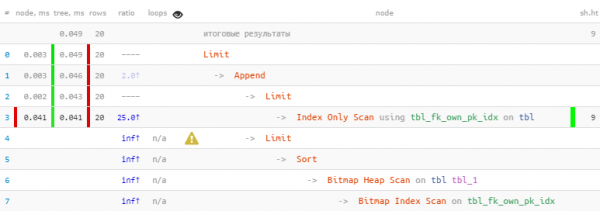
Abbiamo sfruttato il fatto che tutte le 20 righe necessarie sono state ottenute immediatamente nel primo blocco, quindi il secondo, con un Bitmap Heap Scan più "costoso", non è stato nemmeno eseguito — di conseguenza 22 volte più veloce, 44 volte meno letture!
Una spiegazione più dettagliata di questo metodo di ottimizzazione con esempi specifici può essere letta negli articoli e .
Una variante generalizzata di selezione ordinata per più chiavi (e non solo per una coppia const/NULL) è trattata nell'articolo .
#4: читаем много лишнего
Quando si presenta
Di norma, si presenta quando si desidera "aggiungere un altro filtro" a una query già esistente.
"Ma non avete qualcosa di simile, ma con bottoni perlati?» film "La mano di diamante"
Ad esempio, modificando il compito sopra, mostrare le prime 20 richieste "critiche" più vecchie da elaborare, indipendentemente dalla loro assegnazione.
Come identificare
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& 5 × righe < RRbF -- filtrato >80% di quanto letto
&& cicli × RRbF > 100 -- e comunque più di 100 record in totale
Raccomandazioni
Creare [un] indice più specializzato con una condizione WHERE o includere campi aggiuntivi nell'indice.
Se la condizione di filtraggio è "statica" per le tue operazioni — cioè non prevede l'ampliamento dell'elenco dei valori in futuro — è meglio utilizzare un indice WHERE. Questa categoria si adatta bene a diversi stati booleani/enumerativi.
Se la condizione di filtraggio può assumere valori diversi, è meglio ampliare l'indice con questi campi — come nella situazione con BitmapAnd sopra.
Esempio:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "fatti"
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer -- 100 diversi chiavi esterne
END fk_own
, (random() < 1::real/50) critical; -- 1:50, che la richiesta è "critica"
CREATE INDEX ON tbl(pk);
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
critical
ORDER BY
pk
LIMIT 20; 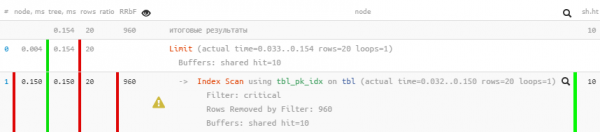
Correggiamo:
CREATE INDEX ON tbl(pk)
WHERE critical; -- aggiunto "una" condizione di filtraggio "statica"

Come possiamo vedere, la filtrazione dal piano è completamente scomparsa e la richiesta è diventata 5 volte più veloce.
#5: разреженная таблица
Quando si presenta
Vari tentativi di creare una coda di lavoro propria, quando un gran numero di aggiornamenti/cancellazioni di record nella tabella porta a una situazione con un gran numero di record 'morti'.
Come identificare
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& loops × (rows + RRbF) 64
Raccomandazioni
Eseguire regolarmente a mano VACUUM [FULL] o garantire una lavorazione sufficientemente frequente tramite un'adeguata configurazione dei suoi parametri, incluso .
In molti casi, tali problemi si rivelano causati da una cattiva strutturazione delle query nelle chiamate dalla logica di business, come quelle esaminate in .
Ma bisogna capire che anche VACUUM FULL può non sempre aiutare. Per tali casi, è utile consultare l'algoritmo dell'articolo .
#6: чтение с «середины» индекса
Quando si presenta
Sembra che abbiamo letto un po', e tutto tramite indice, e non abbiamo filtrato nessuno extra — eppure sono state lette notevolmente più pagine di quanto ci si aspettasse.
Come identificare
-> Indice [Solo] Scansione [Indietro]
&& cicli × (righe + RRbF) 64
Raccomandazioni
Esaminare attentamente la struttura dell'indice utilizzato e i campi chiave specificati nella richiesta — molto probabilmente, parte dell'indice non è specificata. Molto probabilmente, sarà necessario creare un indice simile, ma senza i campi prefissi o .
Esempio:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "fatti"
, (random() * 100)::integer fk_org -- 100 chiavi esterne diverse
, (random() * 1000)::integer fk_cli; -- 1K chiavi esterne diverse
CREATE INDEX ON tbl(fk_org, fk_cli); -- tutto quasi come in #2
-- solo che un indice separato su fk_cli lo abbiamo già considerato superfluo e rimosso
SELECT
*
FROM
tbl
WHERE
fk_cli = 999 -- ma fk_org non è specificato, anche se è presente nell'indice prima
LIMIT 20; 
Sembra tutto a posto, anche per l'indice, ma è un po' sospetto — per ognuno dei 20 record letti è stato necessario leggere 4 pagine di dati, 32KB per record — non è un po' troppo? E anche il nome dell'indice tbl_fk_org_fk_cli_idx fa riflettere.
Correggiamo:
CREATE INDEX ON tbl(fk_cli); 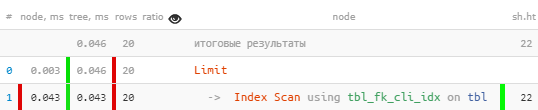
Improvvisamente — 10 volte più veloce e 4 volte meno da leggere!
Altri esempi di situazioni di uso inefficiente degli indici possono essere visti nell'articolo .
#7: CTE × CTE
Quando si presenta
Nella query abbiamo creato CTE 'grassi' da diverse tabelle, e poi abbiamo deciso di fare tra di loro JOIN.
Il caso è attuale per versioni inferiori alla v12 o per query che utilizziamo con WITH MATERIALIZED.
Come identificare
-> Analisi CTE
&& cicli > 10
&& cicli × (righe + RRbF) > 10000
-- prodotto cartesiano CTE troppo grande
Raccomandazioni
Analizzare attentamente la query — e ? Если все-таки да, то applicare 'dizionari' in hstore/json secondo il modello descritto in .
#8: swap на диск (temp written)
Quando si presenta
Un trattamento singolo (ordinamento o univocizzazione) di un grande numero di registrazioni non può rientrare nella memoria dedicata per questo.
Come identificare
-> *
&& temporaneo scritto > 0Raccomandazioni
Se la quantità di memoria utilizzata dall'operazione non supera di molto il valore impostato del parametro , è consigliabile regolarlo. Puoi farlo direttamente nel file di configurazione per tutti, oppure tramite SET [LOCAL] per una specifica query/transazione.
Esempio:
SHOW work_mem;
-- "16MB"
SELECT
random()
FROM
generate_series(1, 1000000)
ORDER BY
1; 
Correggiamo:
SET work_mem = '128MB'; -- prima di eseguire la query 
Per ovvi motivi, se utilizzi solo la memoria e non il disco, la query verrà eseguita molto più velocemente. Inoltre, parte del carico viene alleviato dal HDD.
Ma è fondamentale capire che non è sempre possibile assegnare molta memoria — semplicemente non basta per tutti.
#9: неактуальная статистика
Quando si presenta
Sono stati immessi molti dati, ma non sono stati elaborati in tempo. ANALIZZA.
Come identificare
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& ratio >> 10Raccomandazioni
Procedere ANALIZZA.
Maggiore dettaglio su questa situazione è descritto in .
#10: «что-то пошло не так»
Quando si presenta
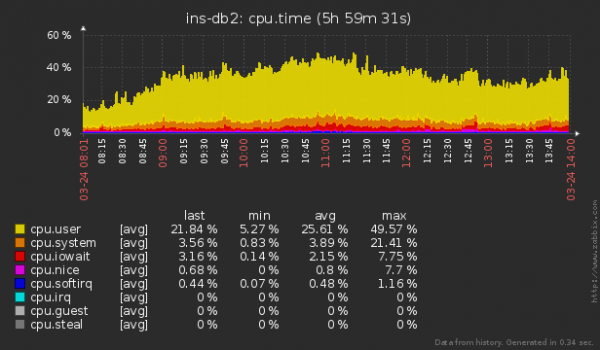
Si è verificato un timeout a causa di un blocco imposto da una query concorrente, oppure non sono state sufficienti le risorse hardware CPU/ipervisor.
Come identificare
-> *
&& (shared hit / 8K) + (shared read / 1K) < time / 1000
-- RAM hit = 64MB/s, HDD read = 8MB/s
&& time > 100ms -- abbiamo letto poco, ma troppo a lungo
Raccomandazioni
Utilizza un sistema esterno di monitoraggio del server per verificare la presenza di blocchi o l'uso anomalo delle risorse. Abbiamo già parlato della nostra modalità di organizzazione di questo processo per centinaia di server. e .
Fonte: habr.com
