

Ti suggerisco di familiarizzare con la trascrizione del rapporto dell'inizio del 2019 di Andrey Borodin "Copie di backup con WAL-G. Cosa c'è nel 2019?"

Ciao a tutti! Mi chiamo Andrey Borodin. Sono uno sviluppatore di Yandex. Sono interessato a PostgreSQL dal 2016, dopo aver parlato con gli sviluppatori e mi hanno detto che tutto è semplice: prendi il codice sorgente e lo costruisci e tutto funzionerà. E da allora non posso fermarmi: scrivo ogni sorta di cose diverse.
 Una delle cose che faccio è un sistema di backup. . In generale, in Yandex ci occupiamo da molto tempo di sistemi di backup in PostgreSQL. E puoi trovare su Internet una serie di sei rapporti su come realizziamo sistemi di backup. E ogni anno si evolvono un po ', si sviluppano un po', diventano più affidabili.
Una delle cose che faccio è un sistema di backup. . In generale, in Yandex ci occupiamo da molto tempo di sistemi di backup in PostgreSQL. E puoi trovare su Internet una serie di sei rapporti su come realizziamo sistemi di backup. E ogni anno si evolvono un po ', si sviluppano un po', diventano più affidabili.
Ma la relazione di oggi non riguarda solo ciò che abbiamo fatto, ma anche quanto sia semplice tutto e ciò che è. Quanti di voi hanno già visto i miei discorsi su WAL-G? È positivo che molte persone non abbiano guardato perché inizierò con la cosa più semplice.

Se all'improvviso hai un cluster PostgreSQL e penso che tutti ne abbiano un paio con sé e all'improvviso non esiste ancora un sistema di backup, allora devi ottenere uno spazio di archiviazione S3 o compatibile con Google Cloud.

Ad esempio, puoi venire al nostro stand e prendere un codice promozionale per Yandex Object Storage, che è compatibile con S3.
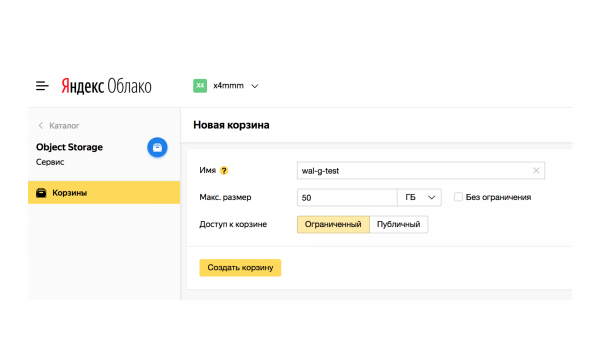
Quindi crea Bucket. È solo un contenitore di informazioni.
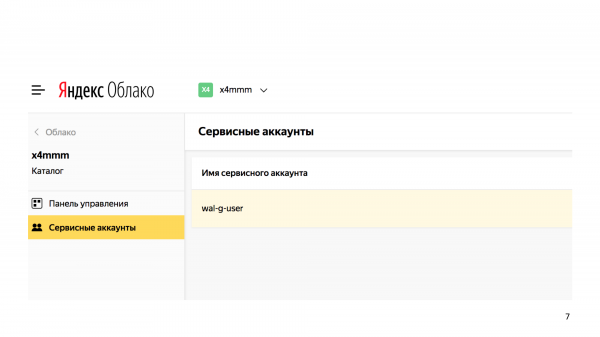
Creare un utente del servizio.
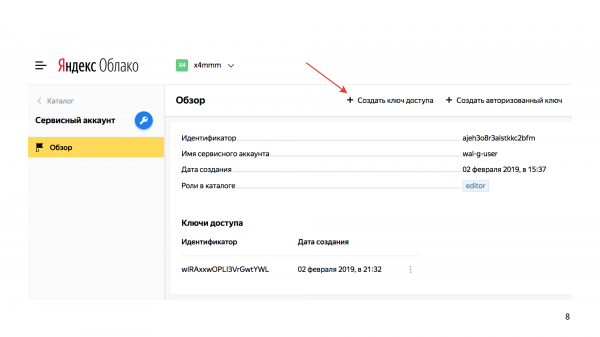
Crea una chiave di accesso utente del servizio aws-s3-key.
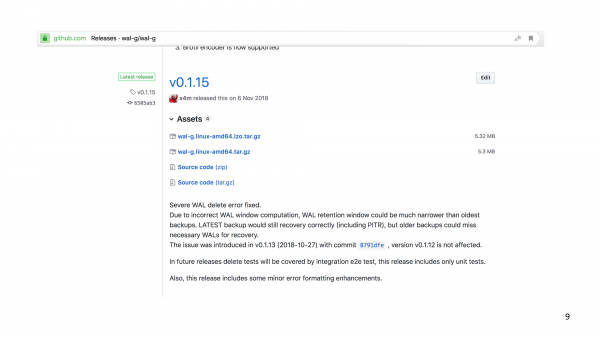
Scarica l'ultima versione stabile di WAL-G.
In che modo le nostre versioni preliminari differiscono dalle versioni? Spesso mi viene chiesto di rilasciare in anticipo. E se non ci sono bug nella versione per un tempo sufficiente, ad esempio un mese, rilascio la versione. Ecco la versione di novembre. E questo significa che ogni mese abbiamo riscontrato una sorta di bug, di solito in funzionalità non critiche, ma finora non abbiamo rilasciato una versione. La versione precedente è solo novembre. Non ci sono bug a noi noti, ad es. sono stati aggiunti bug durante lo sviluppo del progetto.
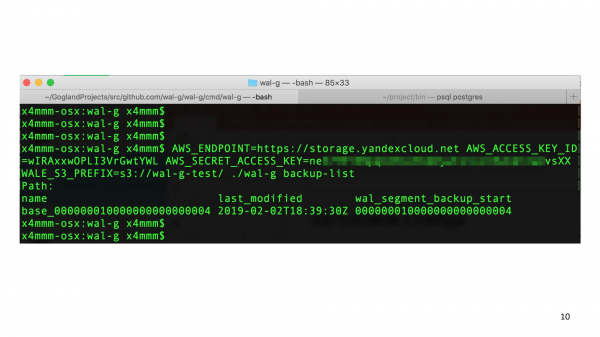
Dopo aver scaricato WAL-G, puoi eseguire un semplice comando "backup list" passando le variabili d'ambiente. E si collegherà a Object Storage e ti dirà quali backup hai. All'inizio, ovviamente, non dovresti avere backup. Lo scopo di questa diapositiva è mostrare che tutto è abbastanza semplice. Questo è un comando della console che accetta le variabili di ambiente ed esegue i sottocomandi.
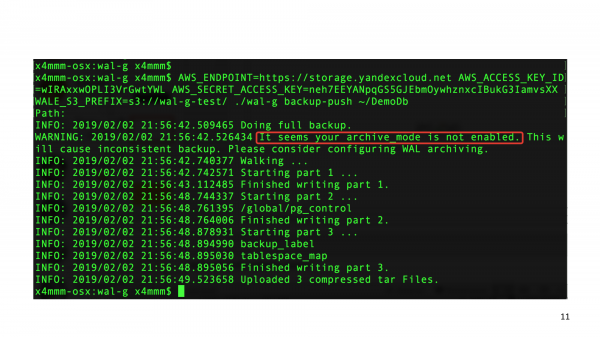
Successivamente, puoi eseguire il tuo primo backup. Pronuncia "backup-push" in WAL-G e punta WAL-G alla posizione dei pgdata del tuo cluster. E molto probabilmente PostgreSQL ti dirà se non hai già un sistema di backup che devi abilitare la "modalità archivio".
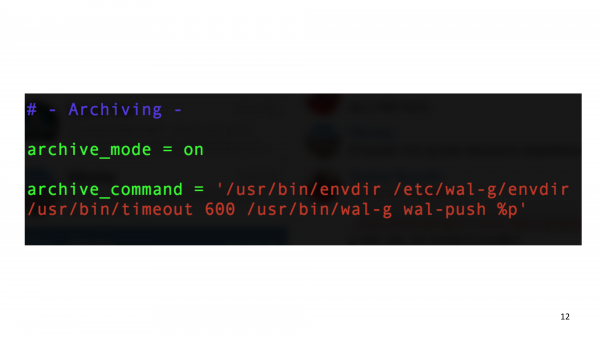
Ciò significa entrare nelle impostazioni e attivare "archive_mode=on" e aggiungere "archive_command" che è esattamente lo stesso di un sottocomando in WAL-G. Ma in questo argomento, le persone spesso per qualche motivo usano gli script a barre e creano un legame attorno a WAL-G. Per favore, non farlo. Usa la funzionalità che è in WAL-G. Se ti manca qualcosa, allora scrivi a . WAL-G presuppone che sia l'unico programma che gira su archive_command.

Utilizziamo WAL-G principalmente per creare un cluster ad alta disponibilità nella gestione del database Yandex.
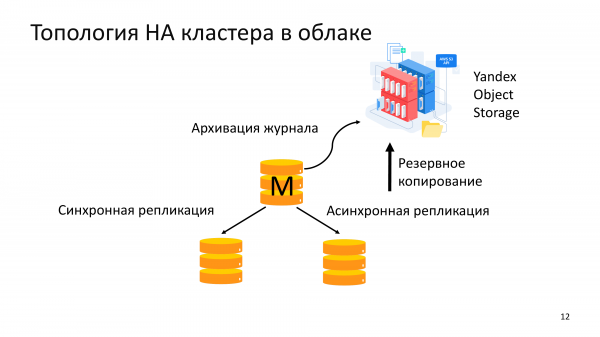
E di solito viene utilizzato in una topologia di un master e diverse repliche. Allo stesso tempo, crea una copia di backup in Yandex Object Storage.
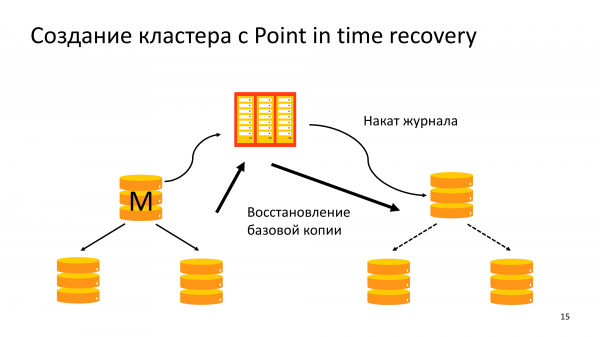
Gli scenari più comuni sono la creazione di copie del cluster utilizzando il ripristino temporizzato. Ma in questo caso, le prestazioni del sistema di backup non sono così importanti per noi. Abbiamo solo bisogno di versare un nuovo cluster dal backup.
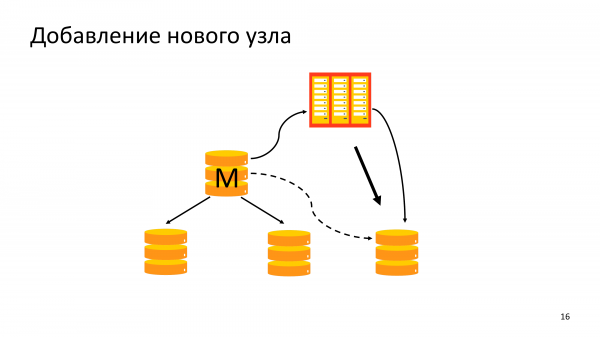
Di solito, abbiamo bisogno delle prestazioni del sistema di backup quando aggiungiamo un nuovo nodo. Perché è importante? Di solito le persone aggiungono un nuovo nodo a un cluster perché il cluster esistente non è in grado di gestire il carico di lettura. Devono aggiungere una nuova replica. Se aggiungiamo un carico da pg_basebackup al Master, allora il Master può sommarsi. Pertanto, era molto importante per noi poter rapidamente versare un nuovo nodo dall'archivio, creando un carico minimo sul Master.
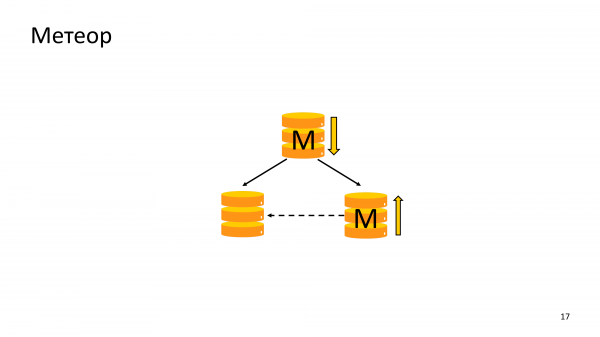
E un'altra situazione simile. Si tratta della necessità di ricaricare il vecchio Master dopo aver cambiato il Master del cluster dal Data Center con il quale si è persa la connettività.

- Di conseguenza, durante la formulazione dei requisiti per il sistema di backup, ci siamo resi conto che pg_basebackup non è adatto a noi quando operiamo nel cloud.
- Volevamo essere in grado di comprimere i nostri dati. Ma quasi tutti i sistemi di backup forniranno la compressione dei dati, tranne ciò che è nella confezione.
- Volevamo parallelizzare tutto, perché l'utente nel cloud acquista un gran numero di core del processore. Ma se non abbiamo il parallelismo in qualche operazione, allora un gran numero di core diventa inutile.
- Abbiamo bisogno della crittografia perché spesso questi non sono i nostri dati e non possono essere archiviati in chiaro. A proposito, il nostro contributo a WAL-G è iniziato con la crittografia. Abbiamo completato la crittografia in WAL-G, dopodiché ci è stato chiesto: "Forse uno di noi svilupperà il progetto?". E da allora lavoro con WAL-G da più di un anno.
- Avevamo anche bisogno di una limitazione delle risorse, perché durante il funzionamento del cloud abbiamo scoperto che a volte le persone hanno un carico di generi alimentari importante durante la notte e questo carico non dovrebbe essere interferito. Pertanto, abbiamo aggiunto la limitazione delle risorse.
- Così come l'elenco e la gestione.
- E verifica.

Abbiamo coperto molti strumenti diversi. Fortunatamente, abbiamo una vasta selezione in PostgreSQL. E ovunque ci mancava qualcosa, qualche piccola caratteristica, qualche piccola caratteristica.

E dopo aver considerato i sistemi esistenti, siamo giunti al fatto che svilupperemo WAL-G. Era quindi un nuovo progetto. È stato abbastanza facile influenzare lo sviluppo verso l'infrastruttura cloud del sistema di backup.

L'ideologia principale a cui aderiamo è che WAL-G dovrebbe essere semplice come una balalaika.

Ci sono 4 comandi in WAL-G. Questo:
WAL-PUSH - archivia l'albero.
WAL-FETCH - prendi un albero.
BACKUP-PUSH - effettua un backup.
BACKUP-FETCH - ottiene un backup dal sistema di backup.

WAL-G, infatti, ha anche la gestione di questi backup, cioè elencare e cancellare dalla cronologia gli alberi e i backup, che al momento non servono più.
Una delle funzioni importanti per noi è la funzione di creare copie delta.
Le copie delta significano che non creiamo un backup completo dell'intero cluster, ma vengono create solo pagine modificate di file modificati nel cluster. Sembrerebbe che funzionalmente questo sia molto simile alla possibilità di ripristinare utilizzando WAL. Ma WAL-single-thread, delta-backup, possiamo eseguire il roll in parallelo. Di conseguenza, quando abbiamo un backup di base eseguito sabato, i backup delta sono giornalieri e giovedì falliamo, quindi dobbiamo eseguire 4 backup delta e 10 ore di WAL. Ci vorrà all'incirca lo stesso tempo, perché i backup delta vengono eseguiti in parallelo.
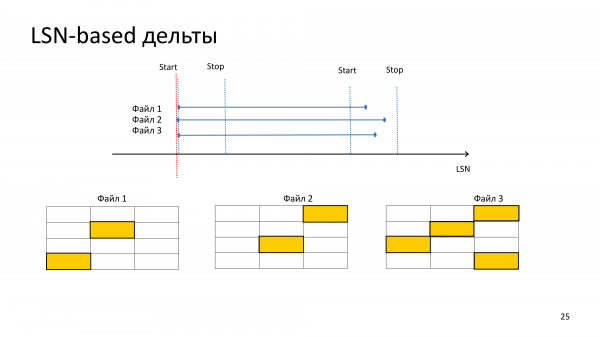
Delta basati su LSN: ciò significa che durante la creazione di un backup, dovremo combinare ciascuna pagina e controllare il suo LSN con l'LSN del backup precedente per capire che è cambiato. Qualsiasi pagina che potrebbe potenzialmente contenere dati modificati dovrebbe essere presente nel backup delta.

Come ho detto, è stata prestata molta attenzione al parallelismo.

Ma l'API di archivio in PostgreSQL è coerente. PostgreSQL archivia un file WAL e richiede un file WAL durante il ripristino. Ma quando il database ha richiesto un file WAL utilizzando il comando WAL-FETCH, chiamiamo il comando WAL-PREFETCH, che prepara altri 8 alberi per recuperare i dati dall'object store in parallelo.
 E quando il database ci chiede di archiviare un albero, esaminiamo archive_status e vediamo se ci sono altri file WAL. E stiamo anche cercando di caricare WAL in parallelo. Ciò offre un notevole guadagno in termini di prestazioni, riducendo significativamente la distanza nel numero di WAL non archiviati. Molti sviluppatori di sistemi di backup ritengono che questo sia un sistema così rischioso perché ci affidiamo alla nostra conoscenza dell'interno del codice che non è un'API PostgreSQL. PostgreSQL non garantisce la presenza della cartella archive_status e non garantisce la semantica, la presenza di segnali pronti per i file WAL lì. Tuttavia, studiamo il codice sorgente, vediamo che è così e proviamo a sfruttarlo. E controlliamo in quale direzione si sta sviluppando PostgreSQL, se improvvisamente questo meccanismo viene interrotto, smetteremo di usarlo.
E quando il database ci chiede di archiviare un albero, esaminiamo archive_status e vediamo se ci sono altri file WAL. E stiamo anche cercando di caricare WAL in parallelo. Ciò offre un notevole guadagno in termini di prestazioni, riducendo significativamente la distanza nel numero di WAL non archiviati. Molti sviluppatori di sistemi di backup ritengono che questo sia un sistema così rischioso perché ci affidiamo alla nostra conoscenza dell'interno del codice che non è un'API PostgreSQL. PostgreSQL non garantisce la presenza della cartella archive_status e non garantisce la semantica, la presenza di segnali pronti per i file WAL lì. Tuttavia, studiamo il codice sorgente, vediamo che è così e proviamo a sfruttarlo. E controlliamo in quale direzione si sta sviluppando PostgreSQL, se improvvisamente questo meccanismo viene interrotto, smetteremo di usarlo.

Nella sua forma più pura, il delta WAL basato su LSN richiede la lettura di qualsiasi file cluster la cui modalità-ora nel file system è cambiata rispetto al backup precedente. Ci abbiamo vissuto a lungo, quasi un anno. E alla fine, siamo giunti alla conclusione che abbiamo delta WAL.
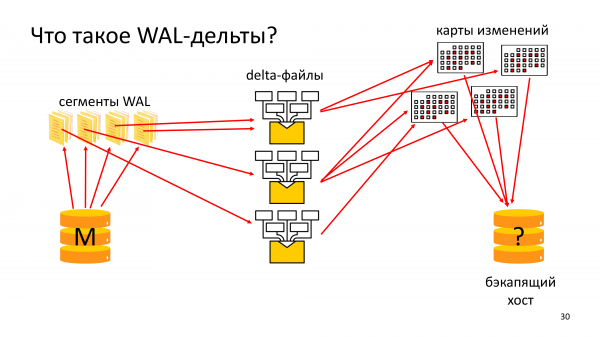 Ciò significa che ogni volta che archiviamo WAL sul Master, non solo lo comprimiamo, lo criptiamo e lo inviamo alla rete, ma contemporaneamente lo leggiamo. Analizziamo, leggiamo i record in esso. Comprendiamo quali blocchi sono cambiati e raccogliamo file delta.
Ciò significa che ogni volta che archiviamo WAL sul Master, non solo lo comprimiamo, lo criptiamo e lo inviamo alla rete, ma contemporaneamente lo leggiamo. Analizziamo, leggiamo i record in esso. Comprendiamo quali blocchi sono cambiati e raccogliamo file delta.
Il file delta descrive un intervallo di file WAL, descrive le informazioni su quali blocchi sono stati modificati in questo intervallo WAL. E poi anche questi file delta vengono archiviati.
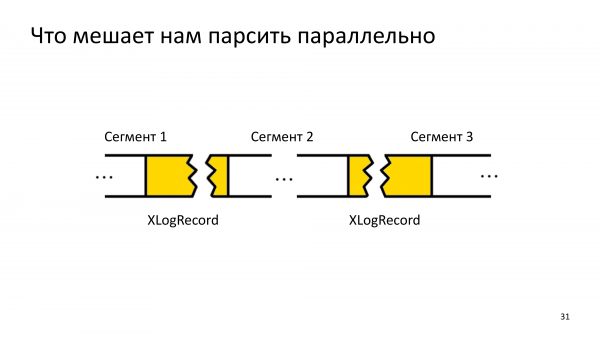
Qui ci troviamo di fronte al fatto che abbiamo parallelizzato tutto abbastanza velocemente, ma non possiamo leggere una cronologia sequenziale in parallelo, perché in un certo segmento potremmo incontrare la fine del precedente record WAL, che finora non abbiamo nulla da abbinare, perché la lettura parallela ha portato a che prima analizziamo il futuro, che non ha ancora un passato.
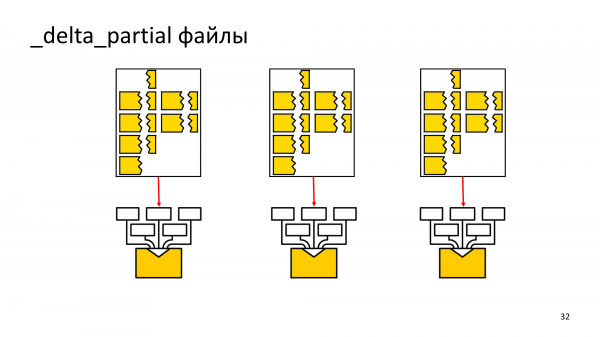
Di conseguenza, abbiamo dovuto inserire pezzi incomprensibili in file _delta_partial. Di conseguenza, quando torneremo al passato, incolleremo i pezzi del record WAL in uno, dopodiché lo analizzeremo e capiremo cosa è cambiato in esso.
Se si forma almeno un punto nella storia della nostra analisi dell'albero in cui non capiamo cosa sia successo, allora, di conseguenza, al prossimo backup dovremo rileggere l'intero cluster, proprio come abbiamo fatto con il solito LSN-based delta.
Di conseguenza, tutta la nostra sofferenza ha portato al fatto che abbiamo reso eccessivamente opensource la libreria di analisi WAL-G. Per quanto ne so, nessuno lo sta ancora usando, ma se qualcuno vuole scriverlo e usarlo, è di pubblico dominio. (Link aggiornato )
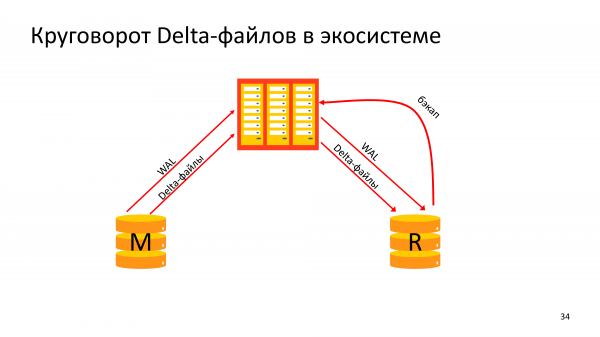
Di conseguenza, tutti i flussi di informazioni sembrano piuttosto complicati. Il nostro Master archivia l'albero e archivia i file delta. E una replica che esegue un backup deve ricevere file delta per il tempo trascorso tra i backup. Allo stesso tempo, parti della storia dovranno essere ricevute alla rinfusa e analizzate, perché non l'intera storia si adatta a grandi segmenti. E solo dopo, la replica può archiviare un backup delta completo.
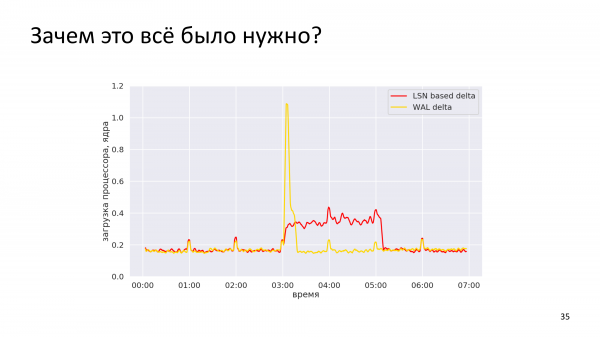
Sulle classifiche, tutto sembra molto più semplice. Questo è un avvio da uno dei nostri veri cluster. Abbiamo basato su LSN, realizzato in un giorno. E vediamo che il backup delta basato su LSN è passato dalle tre del mattino alle cinque del mattino. Questo è il carico nel numero di core del processore. WAL-delta ci ha impiegato circa 20 minuti qui, ovvero è diventato molto più veloce, ma allo stesso tempo c'è stato uno scambio più intenso sulla rete.

Poiché disponiamo di informazioni su quali blocchi sono stati modificati e in quale momento nella cronologia del database, siamo andati avanti e abbiamo deciso di integrare la funzionalità: un'estensione PostgreSQL chiamata "pg_prefaulter"
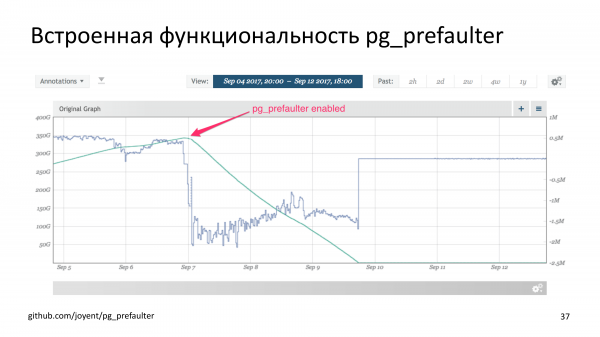
Ciò significa che quando una base Stand-by emette un comando di ripristino, comunica a WAL-G di recuperare il file WAL successivo. Comprendiamo approssimativamente a quali blocchi di dati accederà il processo di ripristino WAL nel prossimo futuro e avviamo un'operazione di lettura su questi blocchi. Questo viene fatto per migliorare le prestazioni dei controller SSD. Perché il rollover WAL raggiungerà la pagina che deve essere modificata. Questa pagina è su disco e non è nella cache della pagina. E aspetterà in modo sincrono l'arrivo di questa pagina. Ma accanto c'è WAL-G, che sa che nelle prossime centinaia di megabyte di WAL avremo bisogno di determinate pagine e parallelamente inizia a scaldarle. Avvia molti accessi al disco in modo che vengano eseguiti in parallelo. Funziona bene su unità SSD, ma, sfortunatamente, questo non è assolutamente applicabile a un disco rigido, perché interferiamo solo con i nostri suggerimenti.
Questo è ciò che è nel codice ora.

Ci sono caratteristiche che vorremmo aggiungere.
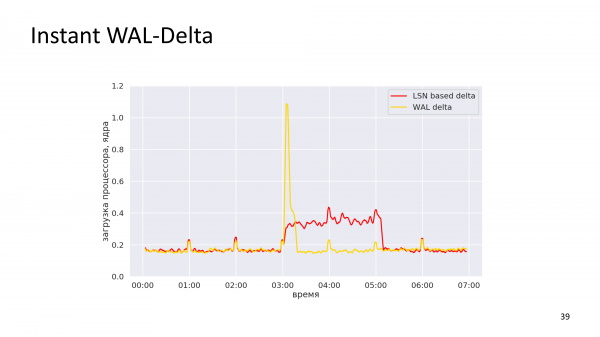
In questa immagine, puoi vedere che WAL-delta richiede un tempo relativamente breve. E questa è una lettura dei cambiamenti avvenuti nel database durante la giornata. Potremmo fare WAL-delta non solo di notte, perché non è più una fonte significativa di carico. Possiamo leggere WAL-delta ogni minuto perché costa poco. In un minuto, possiamo analizzare tutte le modifiche apportate al cluster. E questo potrebbe essere chiamato "WAL-delta istantaneo".

La linea di fondo è che quando ripristiniamo il cluster, riduciamo il numero di storie che dobbiamo eseguire in sequenza. In altre parole, la quantità di WAL che PostgreSQL esegue il roll dovrebbe essere ridotta, poiché richiede una notevole quantità di tempo.
Ma non è tutto. Se sappiamo che qualche blocco verrà modificato prima del punto di coerenza del backup, non possiamo modificarlo in passato. Cioè, ora abbiamo l'ottimizzazione roll forward WAL-delta file per file. Ciò significa che se, ad esempio, martedì, una tabella è stata completamente eliminata o alcuni file sono stati completamente eliminati dalla tabella, quando il delta viene aggiornato lunedì e pg_basebackup viene ripristinato sabato, non creeremo nemmeno questi dati.
Vogliamo estendere questa tecnologia a livello di pagina. Cioè, se una parte del file cambia lunedì, ma verrà sovrascritta mercoledì, quando si esegue il ripristino a un punto giovedì, non è necessario scrivere le prime versioni delle pagine su disco.
Ma questa è ancora un'idea che viene discussa attivamente dentro di noi, ma il codice non è ancora arrivato.

Vogliamo creare un'altra caratteristica in WAL-G. Vogliamo renderlo estensibile perché abbiamo bisogno di supportare diversi database e vorremmo essere in grado di affrontare la gestione dei backup allo stesso modo. Ma il problema è che le API MySQL sono radicalmente diverse. Il PITR di MySQL non si basa su un log WAL fisico, ma su binlog. E non abbiamo un sistema di archiviazione in MySQL che dica a un sistema esterno che questo binlog è finito e deve essere archiviato. Dobbiamo stare da qualche parte in cron con la base e controllare se c'è qualcosa di pronto?
E allo stesso modo, durante il ripristino di MySQL, non esiste alcun comando di ripristino che possa dire al sistema che ho bisogno di file così e così. Prima di iniziare a ripristinare un cluster, devi sapere di quali file hai bisogno. Tu stesso devi indovinare di quali file hai bisogno. Ma questi problemi, forse, possono essere in qualche modo aggirati. (Chiarimento: MySQL è già supportato)

Nel rapporto, volevo anche parlare di quei casi in cui WAL-G non è adatto a te.

Se non si dispone di una replica sincrona, WAL-G non garantisce che l'ultimo hop verrà salvato. E se l'archiviazione è in ritardo rispetto agli ultimi segmenti della storia, questo è un rischio. In assenza di una replica sincrona, non consiglierei di utilizzare WAL-G. Tuttavia, è progettato principalmente per un'installazione cloud, il che implica una soluzione ad alta disponibilità con una replica sincrona, responsabile della sicurezza degli ultimi byte impegnati.

Vedo spesso persone che cercano di sfruttare sia WAL-G che WAL-E contemporaneamente. Supportiamo la retrocompatibilità nel senso che WAL-G può ripristinare un pozzo da WAL-E e può ripristinare un backup realizzato in WAL-E. Ma poiché entrambi questi sistemi utilizzano wal-push paralleli, iniziano a rubarsi file l'uno dall'altro. Se lo risolviamo in WAL-G, rimarrà comunque in WAL-E. In WAL-E, guarda lo stato dell'archivio, vede i file finiti e li archivia, mentre altri sistemi semplicemente non sanno che questo file WAL esisteva, perché PostgreSQL non tenterà di archiviarlo una seconda volta.
Cosa stiamo aggiustando qui sul lato WAL-G? Non informeremo PostgreSQL che questo file è stato portato via in parallelo, e quando PostgreSQL ci chiederà di archiviarlo, sapremo già che tale file con tale tempo di modalità e con tale md5 è già stato archiviato e diremo semplicemente PostgreSQL - OK , tutto è pronto, infatti, senza fare nulla.
Ma sul lato WAL-E, è improbabile che questo problema venga risolto, quindi è impossibile eseguire un comando di archiviazione che archivierà il file sia in WAL-G che in WAL-E.
Inoltre, ci sono casi in cui WAL-G non è adatto a te ora, ma lo ripareremo sicuramente.
 In primo luogo, al momento non disponiamo di una verifica del backup integrata. Non abbiamo verifica né durante il backup né durante il ripristino. Naturalmente, questo è implementato nel cloud. Ma questo viene implementato semplicemente pre-verificando, semplicemente ripristinando il cluster. Sarebbe auspicabile fornire tale funzionalità agli utenti. Ma in fase di verifica, immagino che WAL-G sarà in grado di ripristinare il cluster, avviarlo ed eseguire test di fumo: pg_dumpall su /dev/null e amcheck per verificare gli indici.
In primo luogo, al momento non disponiamo di una verifica del backup integrata. Non abbiamo verifica né durante il backup né durante il ripristino. Naturalmente, questo è implementato nel cloud. Ma questo viene implementato semplicemente pre-verificando, semplicemente ripristinando il cluster. Sarebbe auspicabile fornire tale funzionalità agli utenti. Ma in fase di verifica, immagino che WAL-G sarà in grado di ripristinare il cluster, avviarlo ed eseguire test di fumo: pg_dumpall su /dev/null e amcheck per verificare gli indici.

Al momento non è possibile in WAL-G rinviare un backup da WAL. Cioè, supportiamo alcuni window. Ad esempio, conservare gli ultimi sette giorni, conservare gli ultimi dieci backup, conservare gli ultimi tre backup completi. Molto spesso le persone vengono e dicono: "Abbiamo bisogno di un backup di quello che è successo a Capodanno e vogliamo conservarlo per sempre". WAL-G non sa ancora come farlo. (Nota: questo problema è già stato risolto. Ulteriori dettagli: l'opzione contrassegno di backup in )

E non disponiamo di controlli di checksum della pagina e controlli di integrità per tutti i segmenti dell'albero durante la convalida PITR.

Da tutto questo ho realizzato un progetto per Google Summer of Code. Se conosci studenti intelligenti che vorrebbero scrivere qualcosa in Go e ottenere diverse migliaia di dollari da un'azienda con la lettera "G", allora consiglia loro il nostro progetto. Farò da mentore a questo progetto, loro possono farlo. Se non ci sono studenti, lo prenderò e lo farò da solo in estate.

E abbiamo molti altri piccoli problemi su cui stiamo gradualmente lavorando. E succedono cose piuttosto strane.
Ad esempio, se fornisci un backup vuoto in WAL-G, cadrà semplicemente. Ad esempio, se gli dici che devi eseguire il backup di una cartella vuota. Non ci sarà un file pg_control. E penserà di non capire qualcosa. In teoria, in questo caso, è necessario scrivere un normale messaggio all'utente per spiegargli come utilizzare lo strumento. Ma questa non è nemmeno una caratteristica della programmazione, ma una caratteristica di un buon linguaggio comprensibile.
Non sappiamo come eseguire il backup offline. Se la base mente, non possiamo salvarla. Ma qui tutto è molto semplice. Nominiamo i backup in base a LSN quando è stato avviato. L'LSN della base sottostante deve essere letto dal file di controllo. E questa è una caratteristica così non realizzata. Molti sistemi di backup sono in grado di eseguire il backup di un database bugiardo. Ed è conveniente.
Al momento non stiamo elaborando normalmente la mancanza di spazio per il backup. Perché di solito lavoriamo con backup di grandi dimensioni a casa. E le mani non sono arrivate a questo punto. Ma se qualcuno vuole programmare in Go in questo momento, aggiungi una gestione degli errori fuori dal bucket. Verificherò sicuramente la richiesta pull.
E la cosa più importante che ci preoccupa è che vogliamo il maggior numero possibile di test di integrazione docker che testano diversi scenari. In questo momento stiamo testando solo scenari di base. Ad ogni commit, ma vogliamo controllare tutte le funzionalità che supportiamo per commit. In particolare, ad esempio, avremo un supporto sufficiente per PostgreSQL 9.4-9.5. Li supportiamo perché la comunità supporta PostgreSQL, ma non controlliamo per commit per assicurarci che non sia ancora rotto. E penso che sia un rischio piuttosto serio.

WAL-G lavora per noi su più di mille cluster nella gestione del database Yandex. E ogni giorno esegue il backup di diverse centinaia di terabyte di dati.
Abbiamo un sacco di TODO nel nostro codice. Se vuoi programmare, vieni, stiamo aspettando una richiesta pull, stiamo aspettando domande.

domande
Buonasera! Grazie! La mia ipotesi è che se stai usando WAL-delta, probabilmente stai facendo molto affidamento sulle scritture a pagina intera. E se sì, hai fatto il test? Hai mostrato un bellissimo grafico. Quanto diventa più bello se FPW è disattivato?
Abbiamo abilitato le scritture a pagina intera, non abbiamo provato a disattivarlo. Cioè, io, come sviluppatore, non ho provato a spegnerlo. Gli amministratori di sistema che hanno effettuato ricerche hanno probabilmente svolto ricerche su questo problema. Ma abbiamo bisogno di FPW. Quasi nessuno lo spegne, perché altrimenti è impossibile eseguire un backup dalla replica.
Grazie per la segnalazione! Ho due domande. La prima domanda è: cosa accadrà ai tablespace?
Stiamo aspettando una richiesta pull. I nostri database risiedono su dischi SSD e NMVE e non abbiamo davvero bisogno di questa funzionalità. In questo momento non sono pronto a dedicare del tempo serio a farlo bene. Sono tutto per sostenere questo. Ci sono persone che lo hanno sostenuto, ma lo hanno sostenuto nel modo che gli si addice. Hanno biforcato, ma non fanno una richiesta pull. (Aggiunto nella versione 0.2.13)
E la seconda domanda. All'inizio hai detto che WAL-G presuppone che funzioni da solo e che i wrapper non siano necessari. Io stesso uso gli involucri. Perché non dovrebbero essere usati?
Vogliamo che sia semplice come una balalaika. Ciò significa che non hai bisogno di nulla, tranne una balalaika. Vogliamo che il sistema sia semplice. Se hai una funzionalità che devi creare in uno script, vieni a dircelo: lo faremo in Go.
Buonasera! Grazie per la segnalazione! Non siamo riusciti a far funzionare WAL-G con la decrittazione GPG. Crittografa normalmente, non vuole decrittografare. Qualcosa non ha funzionato per noi? La situazione è deprimente.
Crea un problema su GitHub, scopriamolo.
Cioè, hai riscontrato questo?
C'è una funzione di segnalazione degli errori che quando WAL-G non capisce cosa sia un file, chiede "Forse è crittografato?". Forse il problema non è affatto nella crittografia. Voglio correggere la registrazione su questo argomento. Deve decifrare. Attualmente stiamo lavorando su questo argomento, nel senso che non ci piace molto come è organizzato il sistema di ottenimento delle chiavi pubbliche e private. Perché chiamiamo un GPG esterno in modo che ci dia le sue chiavi. E poi prendiamo queste chiavi e le passiamo al GPG interno, che è un PGP aperto, che è compilato per noi all'interno di WAL-G, e lì chiamiamo crittografia. A questo proposito, vogliamo migliorare il sistema e supportare la crittografia Libsodium (aggiunta nella versione 0.2.15). Ovviamente, la decodifica dovrebbe funzionare, scopriamolo: sono necessari più sintomi di un paio di parole. Puoi in qualche modo riunirti nella stanza dell'oratore e guardare il sistema. (Crittografia PGP senza GPG esterno - v0.2.9)
Ciao! Grazie per la segnalazione! Ho due domande. Ho uno strano desiderio di fare pg_basebackup e WAL accedere a due provider, ad es. Voglio un cloud e un altro. C'è un modo per farlo?
Adesso non esiste, ma è un'idea interessante.
Semplicemente non mi fido di un fornitore, voglio averne un altro per ogni evenienza.
L'idea è interessante. Tecnicamente, questo non è difficile da implementare. Affinché l'idea non vada persa, posso chiedere di fare un problema su GitHub?
Sì, certo.
E poi, quando gli studenti verranno al Google Summer of Code, li aggiungeremo al progetto in modo che ci sia più lavoro, per ottenere di più da loro.
E la seconda domanda. C'è un problema su GitHub. Penso che sia già chiuso. C'è il panico al ripristino. E per sconfiggerlo, hai fatto un'assemblea separata. Si trova proprio nelle questioni. Inoltre c'è una variante che un ambiente variabile in un flusso da fare. E quindi funziona molto lentamente. E abbiamo avuto questo problema, e finora non è stato risolto.
Il problema è che per qualche motivo l'archiviazione (CEPH) ripristina la connessione quando ci arriviamo con molto parallelismo. Cosa si può fare al riguardo? La logica dei tentativi è simile a questa. Stiamo tentando di caricare nuovamente il file. In un passaggio, alcuni file non sono stati caricati per noi, ne faremo un secondo per tutti coloro che non sono entrati. E finché viene caricato almeno un file per iterazione, ripetiamo e ripetiamo e ripetiamo. Abbiamo finalizzato la logica del nuovo tentativo: backoff esponenziale. Ma non è del tutto chiaro cosa fare con il fatto che la connessione si interrompe semplicemente dal lato del sistema di archiviazione. Cioè, quando carichiamo su un flusso, non interrompiamo queste connessioni. Cosa possiamo migliorare qui? Abbiamo la limitazione della rete, possiamo limitare ogni connessione in base al numero di byte che invia. Per quanto riguarda il resto, non so come affrontare il fatto che l'object storage non ci consente di scaricare o scaricare da esso in parallelo.
Non c'è SLA? Non è scritto in loro come si lasciano torturare?
La linea di fondo è che le persone che si presentano con questa domanda di solito hanno il proprio repository. Cioè, nessuno viene da Amazon o Google Cloud o Yandex Object Storage.
Forse la domanda non è per te?
La domanda qui in questo caso non è importante per chi. Se ci sono idee su come affrontare questo problema, facciamolo in WAL-G. Ma finora non ho buone idee su come affrontarlo. Esistono alcuni archivi di oggetti che supportano l'elenco dei backup in modo diverso. Chiedi loro di elencare gli oggetti e aggiungono un'altra cartella lì. WAL-G si spaventa allo stesso tempo: c'è qualcosa qui che non è un file, non posso ripristinarlo, il che significa che il backup non è stato ripristinato. Cioè, in effetti, hai un cluster completamente ripristinato, ma ti restituisce uno stato errato, perché Object Storage ha restituito alcune strane informazioni che non comprendeva completamente.
È nella nuvola di posta che si verifica una cosa del genere.
Se è possibile costruire una riproduzione...
È costantemente riproducibile...
Se c'è la riproduzione, penso che sperimenteremo strategie di ripetizione e scopriremo come riprovare e capire cosa ci richiede il cloud. Forse sarà stabile per noi su tre connessioni e non interromperà la connessione, quindi raggiungeremo attentamente tre. Perché ora stiamo interrompendo la connessione molto rapidamente, ad es. se abbiamo avviato il ripristino in 16 thread, dopo il primo tentativo ci saranno 8 thread, 4 thread, 2 thread e uno. E poi tirerà il file in un flusso. Se ci sono alcuni valori magici come 7,5 flussi che sono i migliori per il pompaggio, allora ci soffermeremo su di essi e proveremo a fare altri 7,5 flussi. C'è un'idea del genere.
Grazie per la segnalazione! Che aspetto ha un flusso di lavoro WAL-G completo? Ad esempio, in uno stupido caso in cui non c'è delta nelle pagine. E prendiamo e rimuoviamo il backup iniziale, quindi archiviamo il pozzo finché non diventiamo blu. Qui, a quanto ho capito, c'è un guasto. Ad un certo punto, è necessario eseguire un backup delta delle pagine, ad es. è un processo esterno che lo guida o come avviene?
L'API delta backup è piuttosto semplice. C'è un numero lì - max delta steps, sembra che si chiami così. Il valore predefinito è zero. Ciò significa che ogni volta che esegui un push di backup, verrà inviato un backup completo. Se lo modifichi in qualsiasi numero positivo, ad esempio in 3, la volta successiva che esegui un push di backup, esamina la cronologia dei backup precedenti. Vede che non superi la catena di 3 delta e fa un delta.
Quindi ogni volta che eseguiamo WAL-G, tenta di eseguire un backup completo?
No, stiamo eseguendo WAL-G e sta tentando di delta se le tue politiche lo consentono.
In parole povere, se lo esegui da zero ogni volta, si comporterà come pg_basebackup?
No, funzionerà comunque più velocemente perché utilizza la compressione e il parallelismo. Pg_basebackup metterà un albero accanto a te. WAL-G si basa sul fatto che hai configurato l'archiviazione. E emetterà un avviso se non è configurato.
pg_basebackup può essere eseguito senza alberi.
Sì, allora si comporteranno quasi allo stesso modo. pg_basebackup copia nel file system. A proposito, abbiamo una nuova funzionalità che ho dimenticato di menzionare. Ora possiamo eseguire il backup da pg_basebackup al file system. Non so perché sia necessario, ma c'è.
Ad esempio, su CephFS. Non tutti vogliono configurare Object Storage.
Sì, questo è probabilmente il motivo per cui hanno posto una domanda su questa funzione in modo che potessimo farlo. E ce l'abbiamo fatta.
Grazie per la segnalazione! C'è solo una domanda sulla copia nel file system. Per impostazione predefinita, ora supporti la copia nell'archiviazione remota, ad esempio, se è presente una sorta di scaffale nel data center o qualcos'altro?
In questa formulazione, è una domanda difficile. Sì, lo supportiamo, ma questa funzionalità non è ancora inclusa in nessuna versione. Cioè, tutte le pre-release lo supportano, ma le versioni di rilascio no. Questa funzionalità è stata aggiunta nella versione 0.2. Sarà sicuramente presto disponibile, non appena avremo risolto tutti i bug noti. Ma in questo momento, questo può essere fatto solo in pre-rilascio. Ci sono due bug nella pre-release. Problema con il ripristino WAL-E, non l'abbiamo risolto. E nell'ultima pre-release è stato aggiunto un bug sul delta-backup. Pertanto, consigliamo a tutti di utilizzare le versioni di rilascio. Non appena non ci saranno più bug nella versione preliminare, possiamo dire che supportiamo Google Cloud, cose compatibili con S3 e archiviazione di file.
Salve, grazie per la segnalazione. A quanto ho capito, WAL-G non è una specie di sistema centralizzato come i barman? Hai intenzione di muoverti in questa direzione?
Il problema è che ci siamo allontanati da questa direzione. WAL-G vive sull'host di base, sull'host del cluster e su tutti gli host del cluster. Quando ci siamo trasferiti in diverse migliaia di cluster, avevamo molte installazioni di barman. E ogni volta che qualcosa va in pezzi in loro, è un grosso problema. Poiché devono essere riparati, è necessario comprendere quali cluster non dispongono di backup in questo momento. Nella direzione dell'hardware fisico per i sistemi di backup, non ho intenzione di sviluppare WAL-G. Se la comunità vuole qualche funzionalità qui, non mi dispiace affatto.
Abbiamo squadre responsabili dell'archiviazione. E ci sentiamo così bene che non siamo noi, che ci sono persone speciali che mettono i nostri file dove i file sono al sicuro. Eseguono ogni sorta di codifica complicata per resistere alla perdita di un certo numero di file. Sono responsabili della larghezza di banda della rete. Quando hai un barista, potresti improvvisamente scoprire che piccoli database con traffico elevato si sono riuniti nello stesso server. Sembra che tu abbia molto spazio su di esso, ma per qualche motivo tutto non si adatta alla rete. Potrebbe risultare il contrario. Ci sono molte reti lì, ci sono core del processore, ma i dischi sono finiti qui. E ci siamo stancati di questa necessità di destreggiarci con qualcosa, e siamo passati al fatto che l'archiviazione dei dati è un servizio separato, di cui sono responsabili persone speciali separate.
PS È stata rilasciata una nuova versione , che per impostazione predefinita può usare il file di configurazione .walg.json che si trova nella home directory di postgres. Puoi disattivare gli script bash. Un esempio di .walg.json è in questo numero
Video:

Fonte: habr.com
