


Le tecnologie e i modelli per il nostro futuro sistema di visione artificiale sono stati creati e perfezionati gradualmente attraverso diversi progetti della nostra azienda — in Posta, Cloud, Ricerca. Hanno maturato come un buon formaggio o un cognac. Un giorno ci siamo resi conto che le nostre reti neurali mostrano ottimi risultati nel riconoscimento e abbiamo deciso di unirle in un unico prodotto B2B — Vision, che ora utilizziamo e offriamo a voi.
Oggi la nostra tecnologia di visione artificiale sulla piattaforma Mail.Ru Cloud Solutions lavora con successo e affronta compiti pratici molto complessi. Alla sua base ci sono una serie di reti neurali che sono state addestrate sui nostri dataset e si specializzano nella risoluzione di compiti applicativi. Tutti i servizi girano sulle nostre capacità server. Potete integrare nelle vostre applicazioni l'API pubblica di Vision, attraverso la quale sono disponibili tutte le funzionalità del servizio. L'API è veloce — grazie ai server GPU, il tempo medio di risposta all'interno della nostra rete è di circa 100 ms.
Visitate il post per una dettagliata spiegazione e molti esempi di come funziona Vision.
Come esempio di servizio, in cui utilizziamo le tecnologie di riconoscimento facciale menzionate, possiamo citare . Uno dei componenti sono i photobooth Vision, che posizioniamo in diverse conferenze. Se ti avvicini a un photobooth di questo tipo, ti fotograferai con la camera integrata e inserirai la tua email, il sistema troverà immediatamente tra le fotografie quelle in cui sei stato catturato dai fotografi ufficiali della conferenza e, se lo desideri, ti invierà le foto trovate via email. Si tratta di fotografie reali, non di scatti in posa: Vision ti riconosce anche sullo sfondo tra la folla dei visitatori. Naturalmente, non sono i photobooth a riconoscerti; sono semplicemente tablet in eleganti supporti, che fotografano gli ospiti con le loro fotocamere integrate e inviano le informazioni ai server, dove avviene tutta la magia del riconoscimento. Abbiamo visto più volte quanto sorprendente sia l'efficacia della tecnologia, anche per gli esperti di riconoscimento delle immagini. Di seguito parleremo di alcuni esempi.

1. Il nostro modello di Riconoscimento Facciale
1.1. Rete neurale e velocità di elaborazione
Per il riconoscimento utilizziamo una modifica del modello di rete neurale ResNet 101. L'Average Pooling finale è stato sostituito con un layer fully connected, proprio come in ArcFace. Tuttavia, la dimensione delle rappresentazioni vettoriali è pari a 128 e non a 512. Il nostro campione di addestramento contiene circa 10 milioni di fotografie di 273.593 persone.
Il modello funziona molto velocemente grazie a un'architettura di configurazione server attentamente selezionata e ai calcoli effettuati su GPU. Il tempo per ricevere una risposta dall'API nelle nostre reti interne è compreso tra 100 ms — questo include il rilevamento del volto (identificazione del volto nella foto), il riconoscimento e il ritorno del PersonID nella risposta API. Con un grande volume di dati in entrata — fotografie e video — il tempo necessario per trasmettere i dati al servizio e ricevere la risposta sarà significativamente maggiore.
1.2. Valutazione dell'efficacia del modello
La definizione dell'efficacia del lavoro delle reti neurali è un compito molto ambiguo. La qualità del loro lavoro dipende dai dataset su cui sono state addestrate e se sono state ottimizzate per lavorare con dati specifici.
Оценивать точность своей модели мы начинали с популярного верификационного теста LFW, но он слишком маленький и простой. После достижения 99,8 % точности от него уже нет толка. Есть хорошее соревнование для оценки моделей распознавания — Megaface на нем мы постепенно добрались до 82 % rank 1. Тест Megaface состоит из миллиона фотографий — дистракторов, — и модель должна уметь хорошо отличать несколько тысяч фотографий знаменитостей из датасета Facescrub от дистракторов. Однако, очистив тест Megaface от ошибок, мы выяснили, что на очищенном варианте достигаем точности 98 % rank 1 (фотографии знаменитостей вообще довольно специфичны). Поэтому создали отдельный идентификационный тест, похожий на Megaface, но c фотографиями «обычных» людей. Дальше улучшали точность распознавания на своих датасетах и ушли далеко вперед. Кроме того, мы используем тест качества кластеризации, который состоит из нескольких тысяч фотографий; он симулирует разметку лиц в облаке пользователя. В данном случае кластеры — это группы похожих лиц, по группе на каждого распознаваемого человека. Качество работы мы проверяли на настоящих группах (истинных).
Certo, gli errori di riconoscimento possono verificarsi con qualsiasi modello. Ma queste situazioni vengono spesso risolte con una taratura fine delle soglie per condizioni specifiche (utilizziamo le stesse soglie per tutte le conferenze, mentre, ad esempio, per il controllo degli accessi dobbiamo alzare notevolmente le soglie per ridurre i falsi positivi). La stragrande maggioranza dei partecipanti alle conferenze è stata riconosciuta correttamente dai nostri chioschi fotografici Vision. A volte qualcuno guardava l'anteprima ritagliata e diceva: "Il vostro sistema ha sbagliato, non sono io". Allora aprivamo la foto completa e si scopriva che il visitatore era effettivamente presente nella foto, solo che non stavamo riprendendo lui, ma qualcun altro, e la persona era semplicemente comparsa casualmente sullo sfondo nella zona sfocata. Inoltre, la rete neurale spesso riconosce correttamente anche quando parte del viso non è visibile, o la persona è di profilo, e a volte anche di tre quarti. Il sistema può riconoscere una persona anche se il viso è stato catturato nell'area di distorsione ottica, ad esempio, quando si utilizza un obiettivo grandangolare.
1.3. Esempi di test in situazioni complesse
Di seguito sono riportati esempi di funzionamento della nostra rete neurale. Vengono fornite fotografie che devono essere etichettate con un PersonID — un identificatore unico per il volto. Se due o più immagini hanno lo stesso identificatore, significa che, secondo i modelli, in queste fotografie è rappresentata la stessa persona.
Ci teniamo a sottolineare che durante i test abbiamo accesso a vari parametri e soglie dei modelli, che possiamo regolare per ottenere risultati specifici. L'API pubblica è ottimizzata per la massima precisione nei casi generali.
Iniziamo con il compito più semplice, il riconoscimento del volto di fronte.

Ecco, questo era troppo facile. Rendi le cose più difficili, aggiungiamo una barba e un po' di vento.

Qualcuno potrebbe dire che non è stata nemmeno troppo difficile, dato che in entrambi i casi il volto è completamente visibile e l'algoritmo ha accesso a molte informazioni su di esso. Va bene, giriamo Tom Hardy di profilo. Questo compito è molto più difficile e abbiamo speso molte energie per risolverlo con un basso tasso di errori: abbiamo selezionato un campione di addestramento, progettato l'architettura della rete neurale, affinato le funzioni di perdita e perfezionato il pre-processing delle foto.
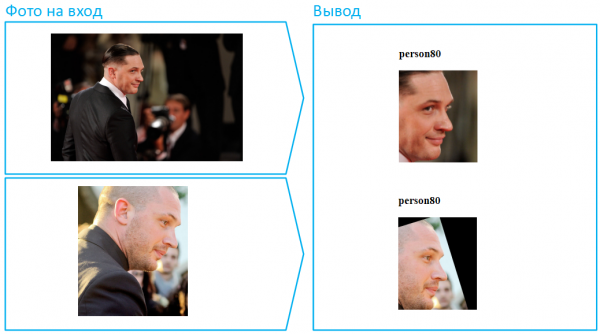
Mettiamogli un copricapo:

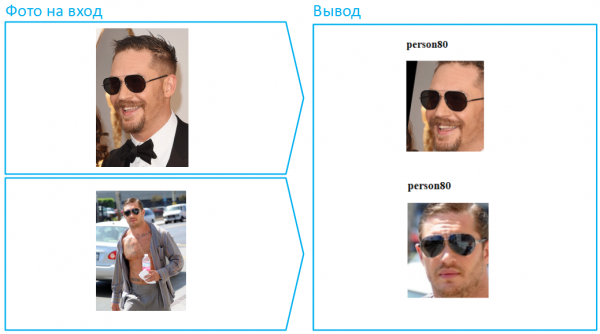
A proposito, questo è un esempio di una situazione particolarmente complessa, poiché qui il volto è molto coperto e nella foto inferiore c'è anche un'ombra profonda che nasconde gli occhi. Nella vita reale, le persone cambiano spesso il loro aspetto indossando occhiali da sole scuri. Facciamo lo stesso con Tom.
Bene, proviamo a raccogliere foto di diverse età e questa volta mettiamo in evidenza la nostra esperienza su un attore diverso. Prenderemo un esempio molto più complesso, in cui i cambiamenti di età sono particolarmente evidenti. Non si tratta di una situazione inventata, è comune dover confrontare una foto del passaporto con il viso del presentatore. Infatti, la prima foto nel passaporto viene messa quando il proprietario ha 20 anni, e a 45 anni una persona può trasformarsi notevolmente.

Pensate che il principale esperto in missioni impossibili non sia molto cambiato con l'età? Credo che anche poche persone riuscirebbero a collegare le foto di sopra e di sotto, il ragazzo è cambiato così tanto negli anni.

Le reti neurali affrontano i cambiamenti nell'aspetto molto più spesso. Ad esempio, a volte le donne possono cambiare notevolmente il loro look con il trucco:

Ora complicheremo ulteriormente il compito: sulle varie foto sono coperte parti diverse del viso. In questi casi, l'algoritmo non può confrontare i campioni interamente. Tuttavia, Vision gestisce bene situazioni simili.
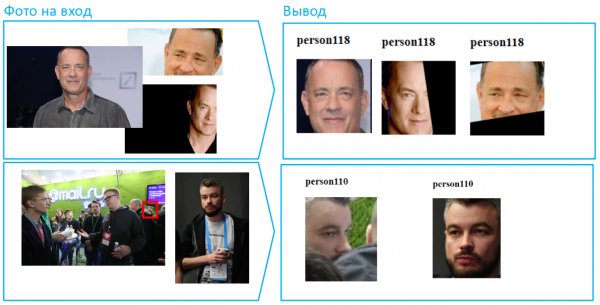
A proposito, nelle fotografie ci possono essere molte facce; ad esempio, in una foto di gruppo possono stare oltre 100 persone. Questa è una situazione complessa per le reti neurali, poiché molti volti possono essere illuminati in modo diverso, e qualcuno può essere fuori fuoco. Tuttavia, se la foto è scattata con una risoluzione e qualità sufficienti (almeno 75 pixel per quadrato che copre il viso), Vision sarà in grado di identificarlo e riconoscerlo.

La caratteristica delle fotografie di reportage e delle immagini provenienti da telecamere di sorveglianza è che le persone appaiono spesso sfocate, poiché si trovano fuori fuoco o si muovono in quel momento:

Anche l'intensità dell'illuminazione può variare notevolmente da un'immagine all'altra. Questo diventa spesso un ostacolo, molti algoritmi incontrano grandi difficoltà nel trattare correttamente immagini troppo scure e troppo chiare, per non parlare della corrispondenza precisa. Ricordo che per ottenere un tale risultato è necessario impostare determinati limiti, questa possibilità non è ancora disponibile al pubblico. Per tutti i clienti utilizziamo la stessa rete neurale, con limiti adatti alla maggior parte delle esigenze pratiche.

Di recente abbiamo lanciato una nuova versione del modello, in grado di riconoscere i volti asiatici con alta precisione. In passato, questo era un grande problema, definito addirittura "razzismo dell'apprendimento automatico" (o delle "reti neurali"). Le reti neurali europee e americane riconoscevano bene i volti euroasiatici, mentre con quelli mongoloidi e negroidi la situazione era molto peggio. Probabilmente, la situazione era esattamente l'opposto in Cina. Tutto dipende dagli insiemi di dati di addestramento, che riflettono i tipi di volti predominanti in un dato paese. Tuttavia, le cose stanno cambiando e oggi questo problema non è più così pressante. Vision non ha alcuna difficoltà con rappresentanti di diverse razze.

Il riconoscimento facciale è solo una delle molte applicazioni della nostra tecnologia. Vision può essere addestrato a riconoscere qualsiasi cosa. Ad esempio, le targhe automobilistiche, anche in condizioni difficili per gli algoritmi: angoli acuti, targhe sporche e difficili da leggere.

2. Esempi pratici di utilizzo
2.1. Controllo dell'accesso fisico: quando due persone entrano con un solo pass
Con Vision è possibile implementare sistemi di monitoraggio delle presenze e delle uscite dei dipendenti. Un sistema tradizionale basato su badge elettronici presenta evidenti svantaggi, come la possibilità di far passare due persone con un solo badge. Tuttavia, se il sistema di accesso (SKUD) viene integrato con Vision, registrerà in modo accurato chi e quando è entrato o uscito.
2.2. Monitoraggio del tempo di lavoro
Questo scenario di utilizzo di Vision è strettamente correlato al precedente. Se si integra il sistema di accesso con il nostro servizio di riconoscimento facciale, potrà non solo rilevare le violazioni delle norme di accesso, ma anche registrare la presenza effettiva dei dipendenti all'interno dell'edificio o del sito. In altre parole, Vision aiuterà a monitorare in modo onesto chi e a che ora è arrivato al lavoro e quando l'ha lasciato, e chi ha effettivamente fatto assente, anche se i colleghi lo coprivano davanti al capo.
2.3. Videoanalisi: monitoraggio delle persone e sicurezza
Monitorando le persone con Vision puoi valutare accuratamente il reale afflusso in aree commerciali, stazioni, passaggi, strade e in molti altri luoghi pubblici. Inoltre, il nostro tracciamento può essere molto utile nel controllo degli accessi, per esempio, in magazzini o in altre aree aziendali critiche. E naturalmente, il monitoraggio di persone e volti aiuta a risolvere questioni di sicurezza. Hai catturato qualcuno mentre rubava nel tuo negozio? Aggiungi il suo PersonID fornito da Vision alla lista nera del tuo software di videoanalisi, e la prossima volta il sistema avviserà immediatamente la sicurezza se quella persona appare di nuovo.
2.4. Nel commercio
Il retail e i vari servizi sono interessati al riconoscimento delle code. Con Vision è possibile riconoscere che non si tratta di un'aggregazione casuale di persone, ma di una vera e propria coda, e determinare la sua lunghezza. Successivamente, il sistema informa i responsabili dell'insorgenza della coda, affinché possano intervenire: o si tratta di un afflusso di visitatori che richiede l'intervento di personale aggiuntivo, o qualcuno non sta adempiendo ai propri compiti.
Un'altra interessante sfida è separare i dipendenti dell'azienda dai visitatori nella sala. Di solito, il sistema viene addestrato a distinguere oggetti in abbigliamento specifico (dress code) o con qualche segno distintivo (foulard aziendale, badge sul petto, ecc.). Questo aiuta a valutare più precisamente la presenza (affinché i dipendenti non 'gonfiano' le statistiche sulla presenza delle persone in sala).
Grazie al riconoscimento facciale, puoi valutare anche il tuo pubblico: qual è la fedeltà dei visitatori, cioè quante persone ritornano nel tuo locale e con quale frequenza. Conta quanti visitatori unici vengono da te in un mese. Per ottimizzare i costi di acquisizione e mantenimento, puoi anche scoprire come varia la affluenza in base al giorno della settimana e persino all'orario.
I franchisor e le aziende in rete possono richiedere una valutazione attraverso foto della qualità del branding di vari punti vendita: presenza di loghi, insegne, manifesti, striscioni e così via.
2.5. Nei trasporti
Un altro esempio di sicurezza tramite videoanalisi è l'identificazione di oggetti abbandonati in aeroporti o stazioni. Vision può essere addestrato a riconoscere oggetti di centinaia di categorie: mobili, borse, valigie, ombrelli, vari tipi di abbigliamento, bottiglie e così via. Se il tuo sistema di videoanalisi rileva un oggetto sospetto e lo riconosce tramite Vision, invia un segnale al servizio di sicurezza. Un compito simile è legato all'individuazione automatica di situazioni anomale in luoghi pubblici: qualcuno si sente male, qualcuno fuma in un luogo proibito, oppure una persona è caduta sui binari, e così via — tutti questi schemi possono essere riconosciuti dal sistema di videoanalisi tramite l'API Vision.
2.6. Documentazione
Un'altra interessante applicazione futura di Vision che stiamo attualmente sviluppando è il riconoscimento dei documenti e la loro elaborazione automatica nei database. Invece di inserire manualmente (o, peggio, trascrivere) infinite serie di numeri, date di emissione, numeri di conto, dati bancari, date e luoghi di nascita e molti altri dati formalizzati, sarà possibile scannerizzare i documenti e inviarli automaticamente tramite un canale protetto attraverso API nel cloud, dove il sistema riconoscerà e parserà i documenti in tempo reale e restituirà una risposta con i dati nel formato richiesto per l'inserimento automatico nel database. Oggi Vision è già in grado di classificare i documenti (inclusi quelli in PDF) — riconosce passaporti, SNILS, INN, certificati di nascita, di matrimonio e altro.
Naturalmente, tutte queste situazioni non possono essere gestite dalla rete neurale out-of-the-box. In ogni caso, viene costruito un nuovo modello specifico per il cliente, considerando molti fattori, sfumature e requisiti, selezionando i dataset e conducendo iterazioni di addestramento-test-non so.
3. Schema di funzionamento dell'API
Le « porte d'ingresso » di Vision per gli utenti è l'API REST. Può ricevere fotografie, video e flussi da telecamere di rete (flussi RTSP).
Per utilizzare Vision, è necessario nel servizio Mail.ru Cloud Solutions e ottenere i token di accesso (client_id + client_secret). L'autenticazione degli utenti avviene tramite il protocollo OAuth. I dati originali nei corpi delle richieste POST vengono inviati all'API. In risposta, il client riceve dall'API il risultato del riconoscimento in formato JSON, e la risposta è strutturata: contiene informazioni sugli oggetti trovati e le loro coordinate.
Esempio di risposta
{
"status":200,
"body":{
"objects":[
{
"status":0,
"name":"file_0"
},
{
"status":0,
"name":"file_2",
"persons":[
{
"tag":"person9",
"coord":[149,60,234,181],
"confidence":0.9999,
"awesomeness":0.45
},
{
"tag":"person10",
"coord":[159,70,224,171],
"confidence":0.9998,
"awesomeness":0.32
}
]
},
{
"status":0,
"name":"file_3",
"persons":[
{
"tag":"person11",
"coord":[157,60,232,111],
"aliases":["person12", "person13"],
"confidence":0.9998,
"awesomeness":0.32
}
]
},
{
"status":0,
"name":"file_4",
"persons":[
{
"tag":"undefined",
"coord":[147,50,222,121],
"confidence":0.9997,
"awesomeness":0.26
}
]
}
],
"aliases_changed":false
},
"htmlencoded":false,
"last_modified":0
}Nella risposta c'è un parametro interessante chiamato awesomeness, che rappresenta la "fregolezza" di una persona nella foto. Questo valore ci aiuta a scegliere il miglior scatto del volto da una sequenza. Abbiamo addestrato una rete neurale a prevedere la probabilità che una foto riceva un "like" sui social media. Maggiore è la qualità dello scatto e più sorridente è il viso, maggiore sarà l'awesomeness.
Nell'API Vision si utilizza il concetto di space. È uno strumento per creare diversi set di volti. Esempi di spazi includono liste nere e bianche, elenchi di visitatori, dipendenti, clienti, ecc. Per ogni token in Vision è possibile creare fino a 10 spazi, in ciascuno dei quali possono esserci fino a 50.000 PersonID, ovvero fino a 500.000 per un singolo token. Non c'è limite al numero di token per un singolo account.
Oggi l'API supporta i seguenti metodi di identificazione e riconoscimento:
- Recognize/Set — identificazione e riconoscimento dei volti. Assegna automaticamente un PersonID a ciascun volto unico e restituisce il PersonID e le coordinate dei volti trovati.
- Delete — rimozione di un specifico PersonID dal database delle persone.
- Truncate — pulizia di tutto lo space da PersonID, utile se è stato utilizzato come test e si desidera azzerare il database per la produzione.
- Detect — identificazione di oggetti, scene, numeri di targa, monumenti, code, ecc. Restituisce la classe degli oggetti trovati e le loro coordinate.
- Detect per documenti — rileva specifici tipi di documenti della Federazione Russa (distingue passaporto, SNILS, TIN, ecc.).
Stiamo anche per completare i metodi per l'OCR, la determinazione del sesso, dell'età e delle emozioni, oltre a soluzioni per il merchandising, ovvero per il controllo automatico della disposizione dei prodotti nei negozi. Troverete la documentazione completa sull'API qui:
4. Conclusione
Attualmente, attraverso l'API pubblica, è possibile accedere al riconoscimento facciale in foto e video, supportando la riconoscenza di vari oggetti, targhe automobilistiche, monumenti, documenti e intere scene. Ci sono moltissimi scenari di applicazione. Venite, testate il nostro servizio e ponetegli le sfide più difficili. Le prime 5000 transazioni sono gratuite. Potrebbe rivelarsi l'«ingrediente mancante» per i vostri progetti.
L'accesso all'API può essere ottenuto immediatamente al momento della registrazione e della connessione . A tutti gli utenti di Habr — un codice promozionale per transazioni aggiuntive. Scrivete in privato l'indirizzo email con cui avete registrato l'account!
Fonte: habr.com
