

Strutturazione di dati non strutturati con GROK
Se stai usando Elastic Stack (ELK) e sei interessato a mappare i log utente di Logstash con Elasticsearch, questo post fa per te.

Il stack ELK è un acronimo per tre progetti open source: Elasticsearch, Logstash e Kibana. Insieme formano una piattaforma per la gestione dei log.
- Elasticsearch è un sistema di ricerca e analisi.
- Logstash è un server di elaborazione dati che riceve dati da più fonti contemporaneamente, li trasforma e quindi li invia a un “deposito”, come Elasticsearch.
- Kibana consente agli utenti di visualizzare i dati tramite grafici e diagrammi in Elasticsearch.
Beats è stato introdotto in seguito ed è un leggero spedizioniere di dati. L'introduzione di Beats ha trasformato ELK Stack in Elastic Stack, ma questo non è il punto principale.
Questo articolo è dedicato a Grok, una funzionalità in Logstash che è in grado di trasformare i tuoi log prima che vengano inviati nell'archivio. Per i nostri scopi, parlerò solo dell'elaborazione dei dati da Logstash a Elasticsearch.

Grok è un filtro all'interno di Logstash utilizzato per analizzare dati non strutturati e convertirli in qualcosa di strutturato e interrogabile. Si basa sulle espressioni regolari (regex) e utilizza modelli di testo per abbinare le righe nei file di log.
Come vedremo nelle sezioni successive, l'uso di Grok è fondamentale per la gestione efficace dei log.
Senza Grok, i tuoi dati di log sono non strutturati.
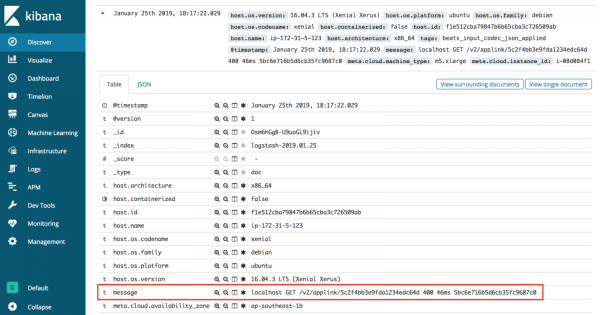
Senza Grok, quando i log vengono inviati da Logstash a Elasticsearch e visualizzati in Kibana, appaiono esclusivamente nel valore del messaggio.
La richiesta di informazioni significative in questa situazione è problematica, poiché tutti i dati di log sono memorizzati in un'unica chiave. Sarebbe meglio se i messaggi di log fossero organizzati in modo più efficiente.
Dati non strutturati dai log
localhost GET /v2/applink/5c2f4bb3e9fda1234edc64d 400 46ms 5bc6e716b5d6cb35fc9687c0Se guardi attentamente i dati grezzi, noterai che sono effettivamente composti da diverse parti, ciascuna delle quali è separata da uno spazio.
Per gli sviluppatori più esperti, probabilmente puoi intuire cosa significhi ciascuna parte e che si tratta di un messaggio di log da una chiamata API. La rappresentazione di ciascun punto è riportata di seguito.
Visione strutturata dei nostri dati
- localhost == ambiente
- GET == metodo
- /v2/applink/5c2f4bb3e9fda1234edc64d == url
- 400 == response_status
- 46ms == response_time
- 5bc6e716b5d6cb35fc9687c0 == user_id
Come vediamo nei dati strutturati, esiste un ordine per i log non strutturati. Il passo successivo è l'elaborazione programmatica dei dati grezzi. Qui è dove Grok brilla.
Modelli Grok
Template Grok incorporati
Logstash viene fornito con oltre 100 modelli incorporati per strutturare i dati non strutturati. Dovresti assolutamente sfruttare questo vantaggio quando possibile per log di sistema comuni, come apache, linux, haproxy, aws e così via.
Tuttavia, cosa succede quando hai log personalizzati, come nell'esempio sopra? Devi costruire il tuo stesso modello Grok.
Modelli personalizzati Grok
Devi provare per costruire il tuo modello Grok. Ho usato e .
Tieni presente che la sintassi dei modelli Grok è la seguente: %{SYNTAX:SEMANTIC}
La prima cosa che ho cercato di fare è stata passare alla scheda Scopri nel debugger Grok. Ho pensato sarebbe stato utile se questo strumento potesse generare automaticamente un modello Grok, ma non è stato molto utile, poiché ha trovato solo due corrispondenze.
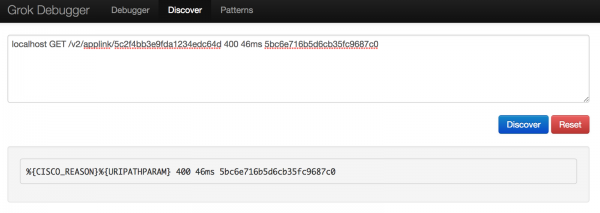
Usando questa scoperta, ho iniziato a creare il mio modello nel debugger Grok, utilizzando la sintassi trovata sulla pagina Github Elastic.
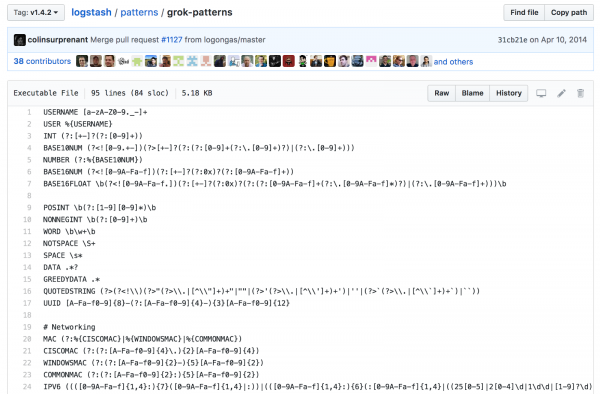
Sperimentando con diverse sintassi, sono finalmente riuscito a strutturare i dati di registro come desideravo.
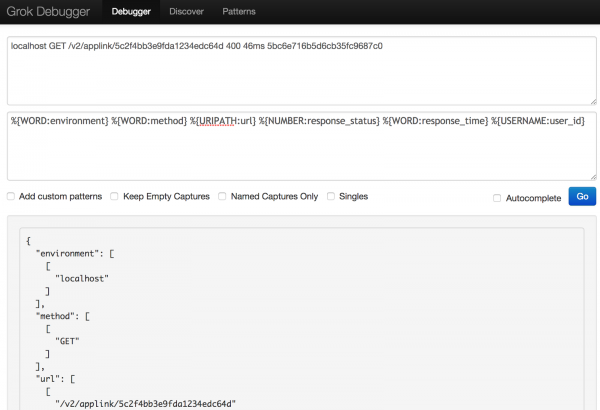
Collegamento al debugger Grok
Testo sorgente:
localhost GET /v2/applink/5c2f4bb3e9fda1234edc64d 400 46ms 5bc6e716b5d6cb35fc9687c0Modello:
%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id}Il risultato finale è stato
{
"environment": [
[
"localhost"
]
],
"method": [
[
"GET"
]
],
"url": [
[
"/v2/applink/5c2f4bb3e9fda1234edc64d"
]
],
"response_status": [
[
"400"
]
],
"BASE10NUM": [
[
"400"
]
],
"response_time": [
[
"46ms"
]
],
"user_id": [
[
"5bc6e716b5d6cb35fc9687c0"
]
]
}Con il template Grok e i dati mappati a disposizione, l'ultimo passo è aggiungerlo a Logstash.
Aggiornamento del file di configurazione Logstash.conf
Sul server su cui hai installato lo stack ELK, vai alla configurazione di Logstash:
sudo vi /etc/logstash/conf.d/logstash.confIncolla le modifiche.
input {
file {
path => "/your_logs/*.log"
}
}
filter{
grok {
match => { "message" => "%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id}"}
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}Dopo aver salvato le modifiche, riavvia Logstash e controlla il suo stato per assicurarti che funzioni ancora.
sudo service logstash restart
sudo service logstash statusInfine, per assicurarti che le modifiche abbiano avuto effetto, aggiorna l'indice Elasticsearch per Logstash in Kibana!
Con Grok i tuoi dati dai log sono strutturati!
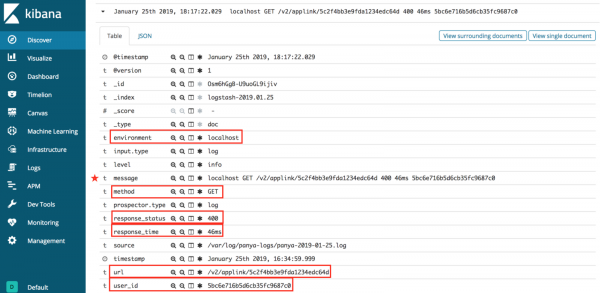
Come possiamo vedere nell'immagine sopra, Grok è in grado di mappare automaticamente i dati di log su Elasticsearch. Questo semplifica la gestione dei log e la rapida interrogazione delle informazioni. Invece di frugare nei file di log per il debug, puoi semplicemente filtrare ciò che stai cercando, come l'ambiente o l'URL.
Prova a dare una possibilità alle espressioni Grok! Se hai un altro modo per farlo o hai problemi con gli esempi sopra, lascia semplicemente un commento qui sotto per farmelo sapere.
Grazie per la lettura — e, per favore, seguimi qui su Medium per articoli più interessanti sulla programmazione!
Risorse
P.S
Canale Telegram su
Fonte: habr.com
