

Ciao a tutti in questo blog! Questo è il terzo post di una serie che mostra come distribuire moderne applicazioni web su Red Hat OpenShift.

Nei due post precedenti, abbiamo spiegato come distribuire moderne applicazioni web in pochi passaggi e come utilizzare la nuova immagine S2I insieme a un'immagine HTTP server già pronta, come NGINX, con l'aiuto delle build concatenate per organizzare una distribuzione in produzione.
Oggi mostreremo come avviare un server di sviluppo per la tua applicazione sulla piattaforma OpenShift e sincronizzarlo con il file system locale, e parleremo anche di cosa sono le OpenShift Pipelines e come possono essere utilizzate come alternativa alle build concatenate.
OpenShift come ambiente di sviluppo
Flusso di lavoro di sviluppo
Come già menzionato nel , il processo tipico di sviluppo per le moderne applicazioni web è essenzialmente un "server di sviluppo" che monitora le modifiche nei file locali. Quando si verificano, viene avviata la build dell'applicazione e successivamente viene aggiornata nel browser.
Nella maggior parte dei moderni framework, un tale "server di sviluppo" è integrato negli strumenti della riga di comando corrispondenti.
Esempio locale
Per prima cosa, vediamo come funziona in caso di avvio locale delle applicazioni. Come esempio, utilizzERemo l'applicazione nelle precedenti articoli, sebbene praticamente gli stessi concetti di flusso di lavoro si applichino anche in tutti gli altri moderni framework.
Quindi, per avviare il "server di sviluppo" nel nostro esempio con React, inseriamo il seguente comando:
$ npm run start
Allora nella finestra del terminale vedremo qualcosa di simile:
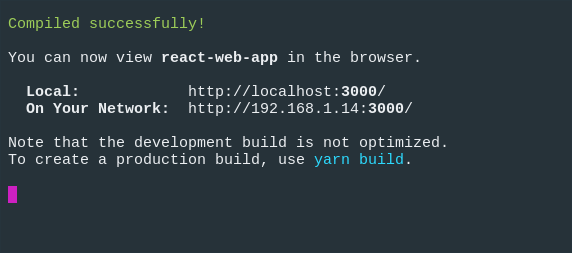
E la nostra applicazione si aprirà nel browser predefinito:

Ora, se apportiamo modifiche al file, l'applicazione dovrebbe aggiornarsi nel browser.
OK, lo sviluppo in modalità locale è chiaro, ma come ottenere lo stesso su OpenShift?
Server di sviluppo su OpenShift
Se vi ricordate, in , abbiamo esaminato il cosiddetto stadio di avvio (run phase) dell'immagine S2I e abbiamo visto che, per impostazione predefinita, il modulo serve gestisce la nostra applicazione web.
Tuttavia, se diamo un'occhiata più da vicino di quell'esempio, c'è una variabile d'ambiente $NPM_RUN che consente di eseguire il proprio comando.
Ad esempio, puoi utilizzare il modulo nodeshift per distribuire la nostra applicazione:
$ npx nodeshift --deploy.env NPM_RUN="yarn start" --dockerImage=nodeshift/ubi8-s2i-web-app
Nota: l'esempio sopra è riportato in forma abbreviata per illustrare l'idea generale.
Qui abbiamo aggiunto alla nostra distribuzione la variabile d'ambiente NPM_RUN, che indica al processo di esecuzione di avviare il comando yarn start, che avvia il server di sviluppo React all'interno del nostro pod OpenShift.
Se guardi il log del pod in funzione, ci sarà più o meno questo:
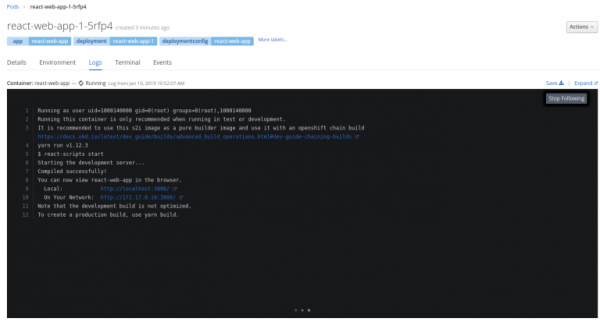
Certo, tutto ciò non avrà senso finché non riusciremo a sincronizzare il codice locale con quello che è anche monitorato per le modifiche, ma vive su un server remoto.
Sincronizzazione del codice remoto e locale
Fortunatamente, nodeshift semplifica la sincronizzazione e per monitorare le modifiche possiamo utilizzare il comando watch.
Dopo aver eseguito il comando per distribuire il server di sviluppo per la nostra applicazione, possiamo usare senza problemi questo comando:
$ npx nodeshift watch
Di conseguenza, verrà stabilita una connessione al pod avviato che abbiamo creato poco prima, attivando la sincronizzazione dei nostri file locali con il cluster remoto, e i file nella nostra sistema locale inizieranno a essere monitorati per eventuali modifiche.
Pertanto, se ora aggiorniamo il file src/App.js, il sistema reagirà a queste modifiche, le copierà sul cluster remoto e avvierà il server di sviluppo che poi aggiornerà la nostra applicazione nel browser.
Per completezza, mostreremo come appaiono questi comandi nella loro interezza:
$ npx nodeshift --strictSSL=false --dockerImage=nodeshift/ubi8-s2i-web-app --build.env YARN_ENABLED=true --expose --deploy.env NPM_RUN="yarn start" --deploy.port 3000
$ npx nodeshift watch --strictSSL=false
Il comando watch è un'astrazione sopra il comando oc rsync, maggiori informazioni su come funziona possono essere trovate .
Questo era un esempio per React, ma lo stesso metodo può essere utilizzato anche con altri framework, basta impostare correttamente la variabile ambientale NPM_RUN.
OpenShift Pipelines

In seguito parleremo di uno strumento chiamato OpenShift Pipelines e di come può essere utilizzato come alternativa alle build collegate chained build.
Che cos'è OpenShift Pipelines
OpenShift Pipelines è un sistema CI/CD basato su cloud per l'integrazione e la consegna continua, progettato per gestire pipeline utilizzando Tekton. Tekton è un framework CI/CD Kubernetes-native flessibile e open source che consente di automatizzare il deployment su diverse piattaforme (Kubernetes, serverless, macchine virtuali, ecc.) astrarre dal livello sottostante.
Per comprendere questo articolo sono necessarie alcune conoscenze sulle Pipelines, quindi ti consigliamo di iniziare a leggere il .
Impostazione dell'ambiente di lavoro
Per sperimentare con gli esempi di questo articolo, è necessario prima preparare l'ambiente di lavoro:
- Installare e configurare un cluster OpenShift 4. Nei nostri esempi utilizziamo CodeReady Containers (CRD), le istruzioni per l'installazione sono disponibili .
- Una volta che il cluster è pronto, dovrai installare il Pipeline Operator. Non preoccuparti, è semplice, e le istruzioni per l'installazione sono .
- Carica (tkn) .
- Esegui lo strumento da riga di comando create-react-app per creare un'applicazione che successivamente verrà distribuita (si tratta di un'applicazione semplice ).
- (Opzionale) Clona il repository per eseguire localmente l'applicazione usando il comando npm install e poi npm start.
Nel repository dell'applicazione ci sarà anche una cartella k8s, dove si troveranno i file YAML di Kubernetes/OpenShift usati per il deployment dell'applicazione. Qui ci saranno Tasks, ClusterTasks, Resources e Pipelines che creeremo in questo .
Iniziamo
Per il nostro esempio, dobbiamo prima creare un nuovo progetto nel cluster OpenShift. Chiamiamo questo progetto webapp-pipeline e creiamolo con il seguente comando:
$ oc new-project webapp-pipeline
Successivamente, questo nome del progetto verrà utilizzato nel codice, quindi, se decidete di chiamarlo diversamente, non dimenticate di correggere il codice degli esempi di conseguenza. A partire da questo punto, procederemo non dall'alto verso il basso, ma dal basso verso l'alto: cioè, prima creeremo tutte le componenti della pipeline, e solo dopo quella stessa.
Quindi, la prima cosa da fare…
Tasks
Creeremo un paio di attività (tasks) che aiuteranno a distribuire l'applicazione all'interno del nostro congegno pipeline. La prima attività – apply_manifests_task – si occupa di applicare i file YAML delle risorse Kubernetes (service, deployment e route) presenti nella cartella k8s della nostra applicazione. La seconda attività – update_deployment_task – è responsabile dell'aggiornamento dell'immagine già distribuita con quella che viene creata dal nostro congegno.
Non preoccuparti se non hai ancora ben chiaro. In effetti, queste attività sono simili a utility, e le esploreremo più nel dettaglio più avanti. Ma per ora creiamole semplicemente:
$ oc create -f https://raw.githubusercontent.com/nodeshift/webapp-pipeline-tutorial/master/tasks/update_deployment_task.yaml
$ oc create -f https://raw.githubusercontent.com/nodeshift/webapp-pipeline-tutorial/master/tasks/apply_manifests_task.yaml
Poi, con il comando tkn CLI, verifichiamo che le attività siano state create:
$ tkn task ls
NOME ETÀ
apply-manifests 1 minuto fa
update-deployment 1 minuto fa
Nota: queste sono attività locali del tuo progetto attuale.
Attività cluster Cluster tasks
I task cluster sono fondamentalmente la stessa cosa delle semplici attività. Cioè, si tratta di una collezione riutilizzabile di passaggi che vengono combinati in un modo o nell'altro quando si avvia un'attività specifica. La differenza è che i task cluster sono accessibili ovunque all'interno del cluster. Per vedere l'elenco dei task cluster che vengono creati automaticamente quando si aggiunge un Pipeline Operator, utilizziamo di nuovo il comando tkn CLI:
$ tkn clustertask ls
NOME ETÀ
buildah 1 giorno fa
buildah-v0-10-0 1 giorno fa
jib-maven 1 giorno fa
kn 1 giorno fa
maven 1 giorno fa
openshift-client 1 giorno fa
openshift-client-v0-10-0 1 giorno fa
s2i 1 giorno fa
s2i-go 1 giorno fa
s2i-go-v0-10-0 1 giorno fa
s2i-java-11 1 giorno fa
s2i-java-11-v0-10-0 1 giorno fa
s2i-java-8 1 giorno fa
s2i-java-8-v0-10-0 1 giorno fa
s2i-nodejs 1 giorno fa
s2i-nodejs-v0-10-0 1 giorno fa
s2i-perl 1 giorno fa
s2i-perl-v0-10-0 1 giorno fa
s2i-php 1 giorno fa
s2i-php-v0-10-0 1 giorno fa
s2i-python-3 1 giorno fa
s2i-python-3-v0-10-0 1 giorno fa
s2i-ruby 1 giorno fa
s2i-ruby-v0-10-0 1 giorno fa
s2i-v0-10-0 1 giorno fa
Ora creiamo due task di cluster. Il primo genererà un'immagine S2I e la invierà al registro interno di OpenShift; il secondo eseguirà la build della nostra immagine basata su NGINX, utilizzando come contenuto l'applicazione già costruita.
Creiamo e inviamo l'immagine
Creando la prima task, ripeteremo ciò che abbiamo già fatto nell'articolo precedente sulle build collegate. Ricordiamo che abbiamo utilizzato l'immagine S2I (ubi8-s2i-web-app) per "costruire" la nostra applicazione, e alla fine abbiamo ottenuto un'immagine archiviata nel registro interno di OpenShift. Ora utilizzeremo questa immagine S2I dell'applicazione web per creare un DockerFile per la nostra applicazione, e poi impiegheremo Buildah per effettuare la reale build e inviare l'immagine risultante al registro interno di OpenShift, poiché è esattamente ciò che OpenShift fa quando distribuite le vostre applicazioni tramite NodeShift.
Vi state chiedendo da dove abbiamo avuto tutte queste informazioni? Da , l'abbiamo semplicemente copiata e adattata alle nostre esigenze.
Bene, ora creiamo la task di cluster s2i-web-app:
$ oc create -f https://raw.githubusercontent.com/nodeshift/webapp-pipeline-tutorial/master/clustertasks/s2i-web-app-task.yaml
Non entreremo nei dettagli, ma ci soffermeremo solo sul parametro OUTPUT_DIR:
params:
- name: OUTPUT_DIR
description: La posizione della directory di output della build
default: build
Per impostazione predefinita, questo parametro è impostato su build, ed è qui che React salva i contenuti compilati. Altri framework utilizzano percorsi diversi, ad esempio, in Ember si usa dist. L'output del nostro primo compito di clustering sarà un'immagine contenente gli HTML, JavaScript e CSS che abbiamo raccolto.
Costruiremo un'immagine basata su NGINX
Per quanto riguarda il nostro secondo compito di clustering, questo deve costruire un'immagine basata su NGINX, utilizzando il contenuto dell'applicazione che abbiamo già compilato. Fondamentalmente, questa è la parte del precedente capitolo in cui abbiamo esaminato le build concatenate.
Per fare ciò, esattamente come sopra, creeremo il compito di clustering webapp-build-runtime:
$ oc create -f https://raw.githubusercontent.com/nodeshift/webapp-pipeline-tutorial/master/clustertasks/webapp-build-runtime-task.yaml
Analizzando il codice di questi task cluster, si nota che non viene specificato il repository Git con cui lavoriamo, né i nomi delle immagini che creiamo. Indichiamo solo cosa trasferiamo in Git o un’immagine dove salvare l’immagine finale. È per questo motivo che questi task cluster possono essere riutilizzati anche per altri applicativi.
E qui passiamo elegantemente al punto successivo…
Risorse
Quindi, poiché, come abbiamo appena detto, i task cluster devono essere il più generali possibile, dobbiamo creare risorse da usare in input (repository Git) e in output (immagini finali). La prima risorsa di cui abbiamo bisogno è Git, dove si trova la nostra applicazione, qualcosa del genere:
# This resource is the location of the git repo with the web application source
apiVersion: tekton.dev/v1alpha1
kind: PipelineResource
metadata:
name: web-application-repo
spec:
type: git
params:
- name: url
value: https://github.com/nodeshift-starters/react-pipeline-example
- name: revision
value: master
Qui, il PipelineResource è di tipo git. La chiave url nella sezione params indica il repository specifico e imposta il ramo master (opzionale, ma lo scriviamo per completezza).
Adesso dobbiamo creare una risorsa per l’immagine in cui verranno salvati i risultati dell'esecuzione del task s2i-web-app, ecco come fare:
# This resource is the result of running "npm run build", the resulting built files will be located in /opt/app-root/output
apiVersion: tekton.dev/v1alpha1
kind: PipelineResource
metadata:
name: built-web-application-image
spec:
type: image
params:
- name: url
value: image-registry.openshift-image-registry.svc:5000/webapp-pipeline/built-web-application:latest
Qui, PipelineResource è di tipo immagine, e il valore del parametro url indica il registro delle immagini interno di OpenShift, specificamente quello che si trova nello spazio dei nomi webapp-pipeline. Ricorda di modificare questo parametro se utilizzi un altro spazio dei nomi.
E infine, l'ultima risorsa di cui avremo bisogno avrà anch'essa tipo immagine e sarà l'immagine finale di NGINX, che verrà poi utilizzata durante il deployment:
# This resource is the image that will be just the static html, css, js files being run with nginx
apiVersion: tekton.dev/v1alpha1
kind: PipelineResource
metadata:
name: runtime-web-application-image
spec:
type: image
params:
- name: url
value: image-registry.openshift-image-registry.svc:5000/webapp-pipeline/runtime-web-application:latest
Inoltre, nota che questa risorsa salva l'immagine nel registro interno di OpenShift nello spazio dei nomi webapp-pipeline.
Per creare tutte queste risorse in una volta, useremo il comando create:
$ oc create -f https://raw.githubusercontent.com/nodeshift/webapp-pipeline-tutorial/master/resources/resource.yaml
Puoi verificare che le risorse siano state create in questo modo:
$ tkn resource ls
Pipeline
Ora che abbiamo tutti i componenti necessari, costruiamo il pipeline utilizzando il seguente comando:
$ oc create -f https://raw.githubusercontent.com/nodeshift/webapp-pipeline-tutorial/master/pipelines/build-and-deploy-react.yaml
Ma prima di eseguire questo comando, esaminiamo questi componenti. Il primo è il nome:
apiVersion: tekton.dev/v1alpha1
kind: Pipeline
metadata:
name: build-and-deploy-react
Successivamente, nella sezione spec vediamo l'indicazione delle risorse che abbiamo creato in precedenza:
spec:
resources:
- name: web-application-repo
type: git
- name: built-web-application-image
type: image
- name: runtime-web-application-image
type: image
Poi creiamo i compiti che il nostro pipeline deve eseguire. Prima di tutto, deve eseguire il compito s2i-web-app già creato:
tasks:
- name: build-web-application
taskRef:
name: s2i-web-app
kind: ClusterTask
Questo compito prende i parametri di input (risorsa gir) e di output (risorsa built-web-application-image). Passiamo anche un parametro speciale affinché non verifichi TLS, poiché utilizziamo certificati autofirmati:
resources:
inputs:
- name: source
resource: web-application-repo
outputs:
- name: image
resource: built-web-application-image
params:
- name: TLSVERIFY
value: "false"
Il compito successivo è quasi identico, solo che qui viene chiamato il compito cluster webapp-build-runtime già creato:
name: build-runtime-image
taskRef:
name: webapp-build-runtime
kind: ClusterTask
Come nella precedente attività, passiamo la risorsa, ma ora si tratta di un'immagine dell'applicazione web costruita (il risultato della nostra attività precedente). E come output di nuovo definiamo l'immagine. Poiché questa attività deve essere eseguita dopo la precedente, aggiungiamo il campo runAfter:
resources:
inputs:
- name: image
resource: built-web-application-image
outputs:
- name: image
resource: runtime-web-application-image
params:
- name: TLSVERIFY
value: "false"
runAfter:
- build-web-application
Le due attività successive sono responsabili dell'applicazione dei file YAML del servizio, del percorso e del deployment, che si trovano nella directory k8s della nostra applicazione web, e di aggiornare questo deployment quando vengono creati nuovi immagini. Queste due attività del cluster sono state definite all'inizio dell'articolo.
Avvio del pipeline
Quindi, tutte le parti del nostro pipeline sono state create, e lo avvieremo con il seguente comando:
$ tkn pipeline start build-and-deploy-react
A questo punto, la riga di comando viene utilizzata in modalità interattiva e bisogna selezionare le risorse appropriate in risposta a ciascuna delle sue richieste: per la risorsa git scegliamo web-application-repo, poi per la prima risorsa dell'immagine – built-web-application-image, e infine per la seconda risorsa dell'immagine – runtime-web-application-image:
? Choose the git resource to use for web-application-repo: web-application-repo (https://github.com/nodeshift-starters/react-pipeline-example)
? Choose the image resource to use for built-web-application-image: built-web-application-image (image-registry.openshift-image-registry.svc:5000/webapp-pipeline/built-web-
application:latest)
? Choose the image resource to use for runtime-web-application-image: runtime-web-application-image (image-registry.openshift-image-registry.svc:5000/webapp-pipeline/runtim
e-web-application:latest)
Pipelinerun started: build-and-deploy-react-run-4xwsr
Ora verificheremo lo stato della pipeline utilizzando il seguente comando:
$ tkn pipeline logs -f
Dopo che la pipeline è stata avviata e l'applicazione è stata distribuita, richiederemo il percorso pubblicato con il seguente comando:
$ oc get route react-pipeline-example --template='http://{{.spec.host}}'
Per maggiore chiarezza, possiamo visualizzare la nostra pipeline in modalità Developer nella console web nella sezione Pipeline, come mostrato nella Fig. 1.
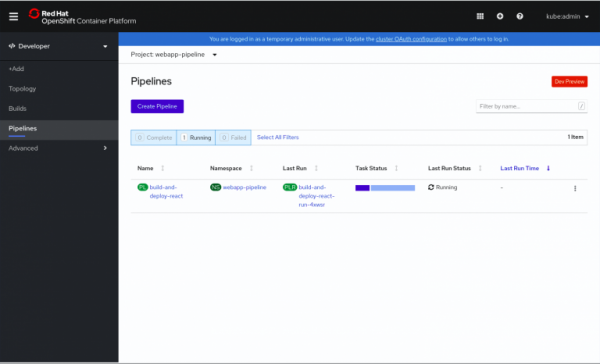
Fig. 1. Panoramica delle pipeline in esecuzione.
Cliccando sulla pipeline in esecuzione, verranno visualizzati ulteriori dettagli, come mostrato nella Fig. 2.
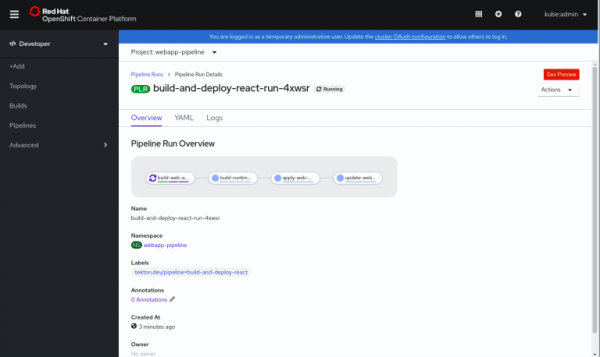
Fig. 2. Ulteriori dettagli sulla pipeline.
Dopo ulteriori dettagli, possiamo visualizzare le applicazioni in esecuzione nella vista Topology, come mostrato nella Fig. 3.
Fig. 3. Pod in esecuzione.
Cliccando sulla pallina nell'angolo in alto a destra dell'icona si apre la nostra applicazione, come mostrato nella Fig. 4.

Fig. 4. Applicazione React in esecuzione.
Conclusione
Quindi, abbiamo dimostrato come avviare un server di sviluppo OpenShift per la propria applicazione e sincronizzarlo con il file system locale. Abbiamo anche esaminato come simulare un template chained-build utilizzando OpenShift Pipelines. Tutti i codici degli esempi di questo articolo possono essere trovati .
Risorse aggiuntive (EN)
- Ebook gratuito
- Altri articoli su sul sito di Red Hat
Annunci di prossimi webinar
Iniziamo una serie di webinar del venerdì sull'esperienza nativa nell'utilizzo di Red Hat OpenShift Container Platform e Kubernetes:
Fonte: habr.com
