


Il kube-scheduler è un componente fondamentale di Kubernetes, responsabile della pianificazione dei pod sui nodi in base alle politiche definite. Spesso, durante l'operazione di un cluster Kubernetes, non ci si sofferma sulle politiche esatte secondo cui i pod vengono pianificati, poiché il set di politiche predefinito del kube-scheduler si adatta alla maggior parte delle attività quotidiane. Tuttavia, ci sono situazioni in cui diventa importante gestire in modo preciso il processo di distribuzione dei pod, e per affrontare questa sfida ci sono due strade:
- Creare un kube-scheduler con un set di regole personalizzato
- Scrivere il proprio scheduler e istruirlo a lavorare con le richieste dell'API server
In questo articolo descriverò l'implementazione del primo punto per risolvere il problema della pianificazione disomogenea dei pod in uno dei nostri progetti.
Una breve introduzione al funzionamento del kube-scheduler
È importante notare che kube-scheduler non si occupa della pianificazione diretta dei pod; si occupa solo di determinare il nodo su cui posizionare un pod. In altre parole, il risultato del lavoro di kube-scheduler è il nome del nodo che restituisce al server API su richiesta di pianificazione, e a questo punto il suo lavoro finisce.
In primo luogo, kube-scheduler compila un elenco di nodi sui quali può essere pianificato un pod in base alle politiche di predicates. Successivamente, ogni nodo di questo elenco riceve un certo numero di punti in base alle politiche di priorities. Alla fine, viene scelto il nodo che ha ottenuto il punteggio massimo. Se ci sono nodi con punteggi massimi identici, viene selezionato casualmente uno di essi. Puoi trovare l'elenco e la descrizione delle politiche di predicates (filtering) e priorities (scoring) in .
Descrizione del corpo del problema
Nonostante la grande quantità di diversi cluster Kubernetes in gestione da Nixys, ci siamo imbattuti nel problema della pianificazione dei pod solo di recente, quando uno dei nostri progetti ha richiesto l'esecuzione di un gran numero di attività periodiche (~100 entità CronJob). Per semplificare al massimo la descrizione del problema, prendiamo come esempio un microservizio, all'interno del quale un'attività cron viene eseguita ogni minuto, generando un certo carico sulla CPU. Per l'esecuzione dell'attività cron sono state allocate tre nodi assolutamente identici nelle loro caratteristiche (24 vCPU ciascuno).
Non si può dire con precisione quanto tempo prenderà l'esecuzione del CronJob, poiché il volume dei dati in ingresso varia continuamente. In media, con il corretto funzionamento di kube-scheduler, su ogni nodo vengono eseguiti 3-4 esemplari del task, che generano circa il 20-30% del carico sulla CPU di ciascun nodo:
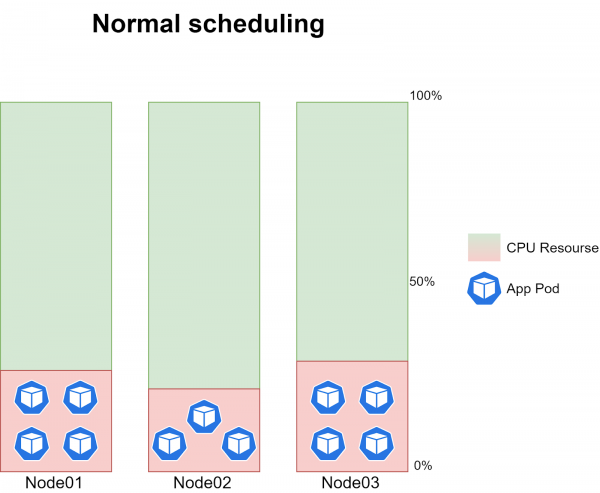
Il problema principale è che a volte i pod delle cron job smettevano di essere programmati su uno dei tre nodi. In altre parole, a un certo punto, non veniva programmato alcun pod su uno dei nodi, mentre sugli altri due nodi venivano eseguiti da 6 a 8 esemplari del compito, creando un carico di ~40-60% sulla CPU:
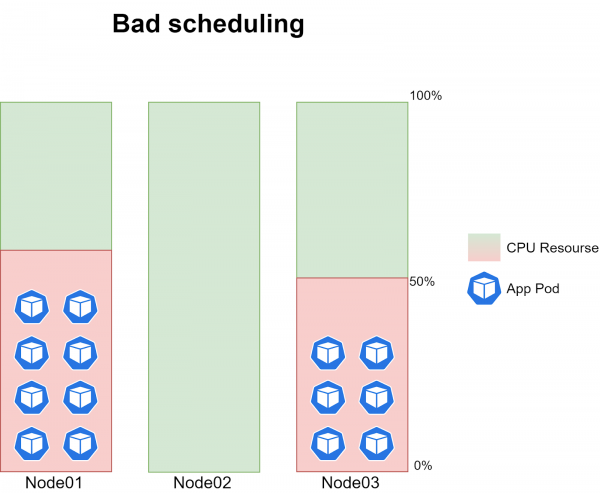
Il problema si ripeteva con una periodicità assolutamente casuale e raramente correlava con il momento del rilascio di una nuova versione del codice.
Aumentando il livello di registrazione del kube-scheduler a 10 (-v=10), abbiamo iniziato a registrare quanti punti otteneva ogni nodo nel processo di valutazione. Durante un normale funzionamento della pianificazione, nei log si poteva vedere la seguente informazione:
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node03: BalancedResourceAllocation, capacità 23900 millicores 67167186944 byte di memoria, richiesta totale 1387 millicores 4161694720 byte di memoria, punteggio 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node02: BalancedResourceAllocation, capacità 23900 millicores 67167186944 byte di memoria, richiesta totale 1347 millicores 4444810240 byte di memoria, punteggio 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node03: LeastResourceAllocation, capacità 23900 millicores 67167186944 byte di memoria, richiesta totale 1387 millicores 4161694720 byte di memoria, punteggio 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node01: BalancedResourceAllocation, capacità 23900 millicores 67167186944 byte di memoria, richiesta totale 1687 millicores 4790840320 byte di memoria, punteggio 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node02: LeastResourceAllocation, capacità 23900 millicores 67167186944 byte di memoria, richiesta totale 1347 millicores 4444810240 byte di memoria, punteggio 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node01: LeastResourceAllocation, capacità 23900 millicores 67167186944 byte di memoria, richiesta totale 1687 millicores 4790840320 byte di memoria, punteggio 9
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node01: NodeAffinityPriority, Punteggio: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node02: NodeAffinityPriority, Punteggio: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node03: NodeAffinityPriority, Punteggio: (0)
interpod_affinity.go:237] cronjob-1574828880-mn7m4 -> Node01: InterPodAffinityPriority, Punteggio: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node01: TaintTolerationPriority, Punteggio: (10)
interpod_affinity.go:237] cronjob-1574828880-mn7m4 -> Node02: InterPodAffinityPriority, Punteggio: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node02: TaintTolerationPriority, Punteggio: (10)
selector_spreading.go:146] cronjob-1574828880-mn7m4 -> Node01: SelectorSpreadPriority, Punteggio: (10)
interpod_affinity.go:237] cronjob-1574828880-mn7m4 -> Node03: InterPodAffinityPriority, Punteggio: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node03: TaintTolerationPriority, Punteggio: (10)
selector_spreading.go:146] cronjob-1574828880-mn7m4 -> Node02: SelectorSpreadPriority, Punteggio: (10)
selector_spreading.go:146] cronjob-1574828880-mn7m4 -> Node03: SelectorSpreadPriority, Punteggio: (10)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node01: SelectorSpreadPriority, Punteggio: (10)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node02: SelectorSpreadPriority, Punteggio: (10)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node03: SelectorSpreadPriority, Punteggio: (10)
generic_scheduler.go:781] Host Node01 -> Punteggio 100043
generic_scheduler.go:781] Host Node02 -> Punteggio 100043
generic_scheduler.go:781] Host Node03 -> Punteggio 100043Cioè, a giudicare dalle informazioni ottenute dai log, ciascuna delle nodi ha accumulato un numero uguale di punti finali e per la pianificazione è stata scelta casualmente. Al momento della pianificazione problematica, i log apparivano come segue:
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node02: BalancedResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1587 millicores 4581125120 memory bytes, score 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node03: BalancedResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1087 millicores 3532549120 memory bytes, score 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node02: LeastResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1587 millicores 4581125120 memory bytes, score 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node01: BalancedResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 987 millicores 3322833920 memory bytes, score 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node01: LeastResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 987 millicores 3322833920 memory bytes, score 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node03: LeastResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1087 millicores 3532549120 memory bytes, score 9
interpod_affinity.go:237] cronjob-1574211360-bzfkr -> Node03: InterPodAffinityPriority, Score: (0)
interpod_affinity.go:237] cronjob-1574211360-bzfkr -> Node02: InterPodAffinityPriority, Score: (0)
interpod_affinity.go:237] cronjob-1574211360-bzfkr -> Node01: InterPodAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node03: TaintTolerationPriority, Score: (10)
selector_spreading.go:146] cronjob-1574211360-bzfkr -> Node03: SelectorSpreadPriority, Score: (10)
selector_spreading.go:146] cronjob-1574211360-bzfkr -> Node02: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node02: TaintTolerationPriority, Score: (10)
selector_spreading.go:146] cronjob-1574211360-bzfkr -> Node01: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node03: NodeAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node03: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node02: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node01: TaintTolerationPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node02: NodeAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node01: NodeAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node01: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:781] Host Node03 -> Score 100041
generic_scheduler.go:781] Host Node02 -> Score 100041
generic_scheduler.go:781] Host Node01 -> Score 100038Da cui sembra che uno dei nodi abbia totalizzato meno punti rispetto agli altri, e pertanto la pianificazione è avvenuta solo su due nodi che hanno ottenuto il punteggio massimo. In questo modo abbiamo potuto confermare con certezza che il problema risiede proprio nella pianificazione dei pod.
Il successivo algoritmo per risolvere il problema era per noi ovvio: analizzare i log, comprendere secondo quale priorità il nodo non ha ottenuto i punti e, se necessario, correggere le politiche del kube-scheduler predefinito. Tuttavia, qui ci siamo trovati di fronte a due difficoltà sostanziali:
- A livello massimo di registrazione (10) viene visualizzato un insieme di punti solo per alcuni privilegi. Nell'estratto di log qui sopra si può notare che per tutti i privilegi presenti nei log, i nodi accumulano lo stesso numero di punti sia nella pianificazione normale sia in quella problematica, tuttavia il risultato finale in caso di pianificazione problematica è diverso. Pertanto, si può concludere che per alcuni privilegi il conteggio dei punti avviene “fuori scena”, e non abbiamo modo di capire per quale privilegio il nodo non ha accumulato punti. Abbiamo descritto questo problema in dettaglio nel repository di Kubernetes su Github. Al momento della scrittura dell'articolo, abbiamo ricevuto una risposta dagli sviluppatori che il supporto per il logging sarà aggiunto negli aggiornamenti di Kubernetes v1.15, v1.16 e v1.17.
- Non c'è un modo semplice per capire con quale specifico insieme di politiche sta attualmente lavorando kube-scheduler. Sì, in questo elenco è menzionato, ma non contiene informazioni su quali pesi specifici siano stati assegnati a ciascuna delle politiche prioritarie. È possibile vedere i pesi o modificare le politiche del kube-scheduler predefinito solo nei .
Vale la pena notare che ci è capitato una volta di rilevare che un nodo non accumulava punti secondo la politica ImageLocalityPriority, che assegna punti a un nodo se su di esso è già presente un'immagine necessaria per eseguire l'applicazione. Cioè, al momento del rilascio della nuova versione dell'applicazione, il job cron riusciva ad avviarsi su due nodi, scaricando su di essi la nuova immagine dal registry Docker, e in questo modo due nodi ottenevano un punteggio finale maggiore rispetto al terzo.
Come ho già scritto sopra, nei log non vediamo informazioni sulla valutazione della politica ImageLocalityPriority. Pertanto, per verificare la mia ipotesi, abbiamo spostato l'immagine con la nuova versione dell'applicazione sul terzo nodo, dopodiché la pianificazione ha iniziato a funzionare correttamente. Proprio a causa della politica ImageLocalityPriority, il problema di pianificazione si è verificato piuttosto raramente, mentre più spesso era legato a qualcos'altro. Poiché non riuscivamo a debuggare in modo completo ciascuna delle politiche nella lista delle priorità del kube-scheduler predefinito, ci è emersa la necessità di una gestione flessibile delle politiche di pianificazione dei pod.
Definizione del compito
Volevamo che la soluzione al problema fosse estremamente mirata, cioè che le entità principali di Kubernetes (in questo caso, il kube-scheduler predefinito) rimanessero inalterate. Non volevamo risolvere un problema in un luogo e crearne uno nuovo in un altro. Pertanto, siamo giunti a due opzioni per affrontare il problema, come accennato nell'introduzione dell'articolo: creare un scheduler aggiuntivo o scrivere il nostro. Il principale requisito per la pianificazione delle attività cron è una distribuzione uniforme del carico su tre nodi. Questo requisito può essere soddisfatto dalle politiche già esistenti del kube-scheduler, quindi non ha senso scrivere il nostro scheduler per risolvere il nostro compito.
Le istruzioni per la creazione e il Deployment di un kube-scheduler aggiuntivo sono descritte in . Tuttavia, ci è sembrato che le entità Deployment non siano sufficienti a garantire l'affidabilità operativa di un servizio critico come il kube-scheduler, quindi abbiamo deciso di implementare un nuovo kube-scheduler come Static Pod, monitorato direttamente da Kubelet. Pertanto, abbiamo definito i seguenti requisiti per il nuovo kube-scheduler:
- Il servizio deve essere implementato come Static Pod su tutti i master del cluster
- È necessario prevedere la tolleranza ai guasti nel caso di inattività del pod attivo con kube-scheduler.
- La priorità principale nella pianificazione deve essere la quantità di risorse disponibili sul nodo (LeastRequestedPriority).
Implementazione della soluzione.
Vale la pena notare che tutti i lavori saranno eseguiti su Kubernetes v1.14.7, poiché è stata proprio questa versione utilizzata nel progetto. Iniziamo scrivendo il manifesto per il nostro nuovo kube-scheduler. Prendiamo come base il manifesto predefinito (/etc/kubernetes/manifests/kube-scheduler.yaml) e lo porteremo alla seguente forma:
kind: Pod
metadata:
labels:
component: scheduler
tier: control-plane
name: kube-scheduler-cron
namespace: kube-system
spec:
containers:
- command:
- /usr/local/bin/kube-scheduler
- --address=0.0.0.0
- --port=10151
- --secure-port=10159
- --config=/etc/kubernetes/scheduler-custom.conf
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --v=2
image: gcr.io/google-containers/kube-scheduler:v1.14.7
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /healthz
port: 10151
scheme: HTTP
initialDelaySeconds: 15
timeoutSeconds: 15
name: kube-scheduler-cron-container
resources:
requests:
cpu: '0.1'
volumeMounts:
- mountPath: /etc/kubernetes/scheduler.conf
name: kube-config
readOnly: true
- mountPath: /etc/localtime
name: localtime
readOnly: true
- mountPath: /etc/kubernetes/scheduler-custom.conf
name: scheduler-config
readOnly: true
- mountPath: /etc/kubernetes/scheduler-custom-policy-config.json
name: policy-config
readOnly: true
hostNetwork: true
priorityClassName: system-cluster-critical
volumes:
- hostPath:
path: /etc/kubernetes/scheduler.conf
type: FileOrCreate
name: kube-config
- hostPath:
path: /etc/localtime
name: localtime
- hostPath:
path: /etc/kubernetes/scheduler-custom.conf
type: FileOrCreate
name: scheduler-config
- hostPath:
path: /etc/kubernetes/scheduler-custom-policy-config.json
type: FileOrCreate
name: policy-configIn breve, le principali modifiche:
- Modificato il nome del pod e del contenitore in kube-scheduler-cron
- Abbiamo specificato l'uso delle porte 10151 e 10159 poiché è stata definita un'opzione
hostNetwork: truee non possiamo utilizzare le stesse porte del kube-scheduler predefinito (10251 e 10259) - Utilizzando il parametro —config, abbiamo specificato il file di configurazione con cui avviare il servizio
- Configurato il montaggio del file di configurazione (scheduler-custom.conf) e del file delle politiche di pianificazione (scheduler-custom-policy-config.json) dall'host
Non dimentichiamo che il nostro kube-scheduler avrà bisogno di permessi simili a quelli predefiniti. Modifichiamo il suo ruolo di cluster:
kubectl edit clusterrole system:kube-scheduler...
resourceNames:
- kube-scheduler
- kube-scheduler-cron
...Ora parliamo di cosa deve contenere il file di configurazione e il file con le politiche di pianificazione:
- File di configurazione (scheduler-custom.conf)
Per ottenere la configurazione del kube-scheduler predefinito è necessario utilizzare il parametro--write-config-todi . Posizioneremo la configurazione ottenuta nel file /etc/kubernetes/scheduler-custom.conf e la trasformeremo nel seguente formato:
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
schedulerName: kube-scheduler-cron
bindTimeoutSeconds: 600
clientConnection:
acceptContentTypes: ""
burst: 100
contentType: application/vnd.kubernetes.protobuf
kubeconfig: /etc/kubernetes/scheduler.conf
qps: 50
disablePreemption: false
enableContentionProfiling: false
enableProfiling: false
failureDomains: kubernetes.io/hostname,failure-domain.beta.kubernetes.io/zone,failure-domain.beta.kubernetes.io/region
hardPodAffinitySymmetricWeight: 1
healthzBindAddress: 0.0.0.0:10151
leaderElection:
leaderElect: true
leaseDuration: 15s
lockObjectName: kube-scheduler-cron
lockObjectNamespace: kube-system
renewDeadline: 10s
resourceLock: endpoints
retryPeriod: 2s
metricsBindAddress: 0.0.0.0:10151
percentageOfNodesToScore: 0
algorithmSource:
policy:
file:
path: "/etc/kubernetes/scheduler-custom-policy-config.json"In breve, le principali modifiche:
- Abbiamo impostato nel schedulerName il nome del nostro servizio kube-scheduler-cron.
- Nel parametro
lockObjectNameè necessario anche impostare il nome del nostro servizio e assicurarsi che il parametroleaderElectsia impostato su true (se hai un solo nodo master, puoi impostarlo su false). - Abbiamo specificato il percorso del file con la descrizione delle politiche di scheduling nel parametro
algorithmSource.
Vale la pena soffermarsi di più sul secondo punto, dove modifichiamo le impostazioni per la chiave leaderElection. Per garantire l'alta disponibilità, abbiamo attivato (leaderElect) il processo di elezione del leader (master) tra i pod del nostro kube-scheduler utilizzando un endpoint comune per essi (resourceLock) con il nome kube-scheduler-cron (lockObjectName) nello spazio dei nomi kube-system (lockObjectNamespace). Per scoprire come Kubernetes garantisce un'elevata disponibilità dei componenti principali (compreso kube-scheduler) puoi consultare .
- Il file delle politiche di pianificazione (scheduler-custom-policy-config.json)
Come ho già scritto in precedenza, possiamo conoscere le politiche specifiche su cui funziona il kube-scheduler predefinito solo analizzando il suo codice. Non possiamo quindi ottenere un file con le politiche di pianificazione del kube-scheduler predefinito come facciamo con il file di configurazione. Descriveremo le politiche di pianificazione di nostro interesse nel file /etc/kubernetes/scheduler-custom-policy-config.json nel seguente modo:
{
"kind": "Policy",
"apiVersion": "v1",
"predicates": [
{
"name": "GeneralPredicates"
}
],
"priorities": [
{
"name": "ServiceSpreadingPriority",
"weight": 1
},
{
"name": "EqualPriority",
"weight": 1
},
{
"name": "LeastRequestedPriority",
"weight": 1
},
{
"name": "NodePreferAvoidPodsPriority",
"weight": 10000
},
{
"name": "NodeAffinityPriority",
"weight": 1
}
],
"hardPodAffinitySymmetricWeight" : 10,
"alwaysCheckAllPredicates" : false
}Pertanto, il kube-scheduler crea inizialmente un elenco di nodi su cui un pod può essere programmato in base alla policy GeneralPredicates (che include un insieme di politiche PodFitsResources, PodFitsHostPorts, HostName e MatchNodeSelector). Successivamente, viene valutato ogni nodo in base a un insieme di politiche nell'array priorities. Per soddisfare i requisiti della nostra applicazione, abbiamo ritenuto che tale insieme di politiche fosse la soluzione ottimale. Ricordo che l'insieme di politiche con una loro descrizione dettagliata è disponibile in . Per portare a termine il tuo obiettivo, puoi semplicemente modificare l'insieme di politiche utilizzate e assegnare loro i pesi appropriati.
Il manifesto del nuovo kube-scheduler che abbiamo creato all'inizio del capitolo lo chiameremo kube-scheduler-custom.yaml e lo posizioneremo nel seguente percorso /etc/kubernetes/manifests su tre nodi master. Se tutto è stato eseguito correttamente, Kubelet su ogni nodo avvierà il pod e nei log del nostro nuovo kube-scheduler vedremo informazioni che indicano che il nostro file con le politiche è stato applicato con successo:
Creazione dello scheduler dalla configurazione: {{ } [{GeneralPredicates }] [{ServiceSpreadingPriority 1 } {EqualPriority 1 } {LeastRequestedPriority 1 } {NodePreferAvoidPodsPriority 10000 } {NodeAffinityPriority 1 }] [] 10 false}
Registrazione del predicato: GeneralPredicates
Tipo di predicato GeneralPredicates già registrato, in uso.
Registrazione della priorità: ServiceSpreadingPriority
Tipo di priorità ServiceSpreadingPriority già registrato, in uso.
Registrazione della priorità: EqualPriority
Tipo di priorità EqualPriority già registrato, in uso.
Registrazione della priorità: LeastRequestedPriority
Tipo di priorità LeastRequestedPriority già registrato, in uso.
Registrazione della priorità: NodePreferAvoidPodsPriority
Tipo di priorità NodePreferAvoidPodsPriority già registrato, in uso.
Registrazione della priorità: NodeAffinityPriority
Tipo di priorità NodeAffinityPriority già registrato, in uso.
Creazione dello scheduler con i predicati di compatibilità 'map[GeneralPredicates:{}]' e le funzioni di priorità 'map[EqualPriority:{} LeastRequestedPriority:{} NodeAffinityPriority:{} NodePreferAvoidPodsPriority:{} ServiceSpreadingPriority:{}]'Ora è sufficiente specificare nello spec della nostra CronJob che tutte le richieste per pianificare i suoi pod devono essere gestite dal nostro nuovo kube-scheduler:
...
jobTemplate:
spec:
template:
spec:
schedulerName: kube-scheduler-cron
...Conclusione
Alla fine abbiamo ottenuto un kube-scheduler aggiuntivo con un insieme unico di politiche di pianificazione, il cui funzionamento è monitorato direttamente da kubelet. Inoltre, abbiamo configurato le elezioni di un nuovo leader tra i pod del nostro kube-scheduler nel caso in cui il vecchio leader diventi indisponibile per qualche motivo.
Le applicazioni e i servizi ordinari continuano a essere pianificati tramite il kube-scheduler predefinito, mentre tutte le attività cron sono state completamente migrate al nuovo. Il carico generato dalle attività cron è ora distribuito uniformemente su tutti i nodi. Considerando che la maggior parte delle attività cron viene eseguita sugli stessi nodi delle applicazioni principali del progetto, ciò ha ridotto significativamente il rischio di migrazione dei pod a causa di carenze di risorse. Dopo l'implementazione del kube-scheduler aggiuntivo, non ci sono più stati problemi di pianificazione irregolare delle attività cron.
Leggi anche altri articoli nel nostro blog:
Fonte: habr.com
