

За годы существования Pinterest 300 миллионов пользователей сервиса создали более 200 миллиардов пинов на более чем 4 миллиардов досок. Чтобы обслуживать эту армию пользователей и обширную контент-базу, портал разработал тысячи сервисов, начиная от микросервисов, с которыми может справиться несколько CPU, и заканчивая гигантскими монолитами, которые крутятся на целом парке виртуальных машин. И вот наступил момент, когда взгляд компании упал на k8s. Чем же «кубик» глянулся «Пинтересту»? Об этом вы узнаете из нашего перевода свежей статьи из .

Итак, сотни миллионов пользователей и сотни миллиардов пинов. Чтобы обслуживать эту армию пользователей и обширную контент-базу, мы разработали тысячи сервисов, начиная от микросервисов, с которыми может справиться несколько CPU, и заканчивая гигантскими монолитами, которые крутятся на целом парке виртуальных машин. Кроме того, у нас есть разнообразные фреймворки, которые также могут требовать ресурсов CPU, памяти или доступа к операциям ввода-вывода.
В ходе поддержки этого зоопарка инструментов команда разработки сталкивается с рядом проблем:
- У инженеров нет унифицированного способа запуска рабочей среды. Stateless-сервисы, Stateful-сервисы и находящиеся в стадии активной разработки проекты базируются на абсолютно разных технологических стеках. Это привело к созданию целого обучающего курса для инженеров, а также серьезно усложняет работу нашей инфраструктурной команды.
- Разработчики, имеющие в распоряжении собственный парк виртуальных машин, создают огромную нагрузку на внутренних администраторов. В итоге, такие простые операции, как обновление ОС или AMI, растягиваются на недели и месяцы. Это приводит к росту нагрузки в, казалось бы, абсолютно будничных ситуациях.
- Сложности с созданием глобальных инструментов управления инфраструктурой поверх уже существующих решений. Ситуация осложняется еще и тем, что найти владельцев виртуальных машин непросто. То есть мы не знаем, можно ли безопасно извлечь эти мощности для работы на других участках нашей инфраструктуры.
Контейнерные системы оркестрации — это способ унифицировать управление рабочей нагрузкой. Они открывают вам путь к повышению скорости разработки и упрощают управление инфраструктурой, так как все задействованные в проекте ресурсы управляются одной централизованной системой.
Рисунок 1: Приоритеты инфраструктуры (надежность, производительность разработчиков и эффективность).
Команда Cloud Management Platform в Pinterest познакомилась с K8s в 2017 году. К первой половине 2017 мы документировали большую часть наших производственных мощностей, в том числе, API и все наши веб-серверы. После мы провели внимательную оценку различных систем оркестрации контейнерных решений, построения кластеров и работы с ними. К концу 2017 года мы решили воспользоваться Kubernetes. Он был достаточно гибок и широко поддерживался в сообществе разработчиков.
К настоящему моменту мы создали собственные инструменты первичной загрузки кластера на основе Kops и перевели на Kubernetes существующие компоненты инфраструктуры — такие, как сеть, безопасность, метрики, ведение журналов, управление идентификацией и трафик. Также мы реализовали систему моделирования рабочих нагрузок для нашего ресурса, сложность которой скрыта от разработчиков. Сейчас мы сосредоточены на обеспечении стабильности кластера, его масштабировании и подключении новых клиентов.
Kubernetes: путь Pinterest
Начало работы с Kubernetes в масштабах Pinterest как с платформой, которая будет любима нашими инженерами, вылилось во множество трудностей.
Как крупная компания мы вложили значительные средства в инфраструктурные инструменты. В пример можно привести инструменты безопасности, которые обрабатывают сертификаты и распределяют ключи, компоненты контроля трафика, системы обнаружения сервисов, компоненты видимости и отправки журналов и метрик. Все это было собрано не просто так: мы прошли нормальный путь проб и ошибок, и потому хотелось интегрировать все это хозяйство в новую инфраструктуру на Kubernetes вместо того, чтобы заново изобретать старый велосипед на новой платформе. Такой подход в целом упростил миграцию, так как вся поддержка приложений уже существует, ее не надо создавать с нуля.
С другой стороны, моделей прогнозирования нагрузок в самом Kubernetes (например, развертывания, заданий и наборов Daemon) недостаточно для нашего проекта. Эти проблемы юзабилити являются огромными препятствиями на пути к переходу на Kubernetes. Например, мы слышали, как разработчики сервисов жалуются на отсутствие или некорректную настройку входа. Также мы сталкивались с неправильным использованием шаблонизаторов, когда создавались сотни копий с одинаковой спецификацией и заданием, что выливалось в кошмарные проблемы с отладкой.
Еще было очень сложно поддерживать разные версии в одном и том же кластере. Представьте себе сложность клиентской поддержки, если вам нужно работать сразу во множестве версий одной и той же среды исполнения, со всеми их проблемами, багами и апдейтами.
Пользовательские ресурсы и контроллеры Pinterest
Чтобы облегчить для наших инженеров процесс внедрения Kubernetes, а также упростить инфраструктуру и ускорить ее работу, мы разработали наши собственные определения пользовательских ресурсов (CRD).
CRD предоставляют следующие функциональные возможности:
- Объединение различных нативных ресурсов Kubernetes, чтобы они работали в качестве единой нагрузки. Например, ресурс PinterestService включает в себя развертывание, службу входа и конфигурационную карту. Это позволяет разработчикам не беспокоиться о настройке DNS.
- Внедрение необходимой поддержки приложений. Пользователь должен сосредоточиться только на спецификации контейнера согласно своей бизнес-логике, в то время как контроллер CRD внедряет все необходимые init-контейнеры, переменные среды и спецификации pod. Это обеспечивает принципиально иной уровень комфорта для разработчиков.
- Контроллеры CRD также управляют жизненным циклом собственных ресурсов и повышают доступность отладки. Это включает согласование желаемой и реальной спецификаций, обновление статуса CRD и ведение логов событий и не только. Без CRD разработчики были бы вынуждены управлять многочисленным набором ресурсов, что только повышало бы вероятность ошибки.
Вот пример PinterestService и внутреннего ресурса, который управляется нашим контроллером:

Как можно увидеть выше, для поддержки пользовательского контейнера нам необходимо интегрировать в него контейнер инициализации и несколько дополнений, чтобы обеспечить безопасность, видимость и работу с сетевым трафиком. Кроме того, мы создали шаблоны карт конфигурации и реализовали поддержку шаблонов PVC для пакетных заданий, а также трекинг множества переменных среды для отслеживания идентификации, потребления ресурсов и сбора «мусора».
Трудно представить, что разработчики захотят написать эти файлы конфигурации вручную без поддержки CRD, не говоря уже о дальнейшей поддержке и отладке конфигураций.
Воркфлоу деплоя приложений
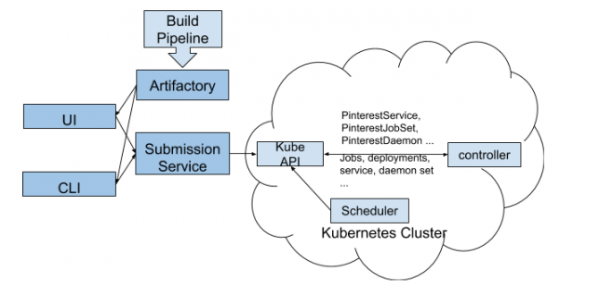
На рисунке выше показано, как развернуть пользовательский ресурс Pinterest в кластере Kubernetes:
- Разработчики взаимодействуют с нашим кластером Kubernetes через CLI и пользовательский интерфейс.
- Инструменты CLI / UI извлекают YAML-файлы конфигурации рабочего процесса и другие свойства сборки (тот же идентификатор версии) из Artifactory, после чего отправляют их в Job Submission Service. Этот шаг гарантирует, что в кластер будут поставлены только рабочие версии.
- JSS является шлюзом для различных платформ, включая Kubernetes. Тут происходит аутентификация пользователя, выдача квот и частичная проверка конфигурации нашего CRD.
- После проверки CRD на стороне JSS информация отправляется на API платформы k8s.
- Наш CRD-контроллер отслеживает события на всех пользовательских ресурсах. Он преобразует CR в нативные ресурсы k8s, добавляет необходимые модули, устанавливает соответствующие переменные среды и выполняет другие вспомогательные работы, чем гарантирует контейнерным пользовательским приложениям достаточную инфраструктурную поддержку.
- Затем контроллер CRD передает полученные данные в API Kubernetes для того, чтобы они были обработаны планировщиком и запущены в работу.
Nota: это предрелизное воркфлоу деплоя было создано для первых пользователей новой k8s-платформы. Сейчас мы находимся в процессе доработки этого процесса для того, чтобы полностью интегрироваться с нашей новой CI/CD. Это значит, что мы не можем рассказать всего связанного с Kubernetes. Мы с нетерпением ждем возможности поделиться нашим опытом и рассказать о прогрессе команды в данном направлении в нашей следующей блогозаписи «Building a CI/CD platform for Pinterest».
Виды специальных ресурсов
Исходя из конкретных потребностей Pinterest, мы разработали следующие CRD, которые подходят для различных рабочих процессов:
- PinterestService — это уже давно работающие stateless-сервисы. Многие наши основные системы базируются на наборе таких сервисов.
- PinterestJobSet моделирует пакетные задания полного цикла. В Pinterest есть распространенный сценарий, согласно которому несколько заданий запускают одни и те же контейнеры параллельно, причем вне зависимости от других подобных процессов.
- PinterestCronJob широко применяется в связке с небольшими периодическими нагрузками. Это оболочка для нативной работы cron с механизмами поддержки Pinterest, которые отвечают за безопасность, трафик, логи и метрики.
- PinterestDaemon включает в себя Daemon-ы инфраструктуры. Это семейство продолжает расти, поскольку мы добавляем все больше поддержки для наших кластеров.
- PinterestTrainingJob распространяется на процессы Tensorflow и Pytorch, обеспечивая тот же уровень поддержки во время работы, что и все другие CRD. Поскольку в Pinterest активно используется Tensorflow и другие системы машинного обучения, у нас был резон выстроить вокруг них отдельную CRD.
Также мы работаем над PinterestStatefulSet, который вскоре будет адаптирован для хранилищ данных и других stateful-систем.
Поддержка среды исполнения
Когда модуль приложений запускается в Kubernetes, он автоматически получает сертификат для идентификации самого себя. Этот сертификат используется для доступа к секретному хранилищу или для общения с другими службами через mTLS. Между тем, конфигуратор инициализации контейнеров и Daemon загрузят все необходимые зависимости до запуска контейнерного приложения. Когда все будет готово, sidecar трафика и Daemon зарегистрируют IP-адрес модуля в нашем Zookeeper, чтобы клиенты могли его обнаружить. Все это будет работать, так как сетевой модуль был настроен еще до запуска приложения.
Выше приведены типичные примеры поддержки рабочих нагрузок во время выполнения. Для других типов рабочих нагрузок может потребоваться немного другой саппорт, но все они представлены в виде sidecar уровня pod, узловыми или Daemon-ами уровня виртуальных машин. Мы следим за тем, чтобы все это было развернуто в рамках управляющей инфраструктуры и согласовано между приложениями, что в итоге значительно снижает нагрузку в плане технических работ и поддержки клиентов.
Тестирование и QA
Мы собрали end-to-end тестовый конвейер поверх уже имеющейся тестовой инфраструктуры Kubernetes. Эти тесты распространяются на все наши кластеры. Наш пайплайн пережил множество переделок, прежде чем стал частью продуктового кластера.
Помимо систем тестирования у нас есть системы мониторинга и оповещения, которые постоянно следят за состоянием компонентов системы, потреблением ресурсов и другими важными показателями, уведомляя нас только при необходимости человеческого вмешательства.
Alternative
Мы рассматривали некоторые альтернативы кастомных ресурсов, такие как мутационные контроллеры доступа и системы шаблонов. Однако все они сопряжены с серьезными трудностями в работе, так что мы выбрали путь CRD.
Мутационный контроллер допуска использовался для ввода сайдкаров, переменной среды и прочей поддержки во время исполнения. Тем не менее, он сталкивался с различными проблемами, например, со связыванием ресурсов и управлением их жизненным циклом, когда как в CRD таких проблем не возникает.
Nota: Системы шаблонов, такие как диаграммы Хелма, также широко используются для запуска приложений со схожими конфигурациями. Однако наши рабочие приложения слишком разнообразны, чтобы управлять ими с помощью шаблонов. Также во время непрерывного развертывания при использовании шаблонов будет возникать слишком много ошибок.
Грядущая работа
Сейчас мы имеем дело со смешанной нагрузкой на всех наших кластерах. Чтобы поддерживать подобные процессы разного типа и размера, мы работаем в следующих направлениях:
- Совокупность кластеров распределяет большие приложения по разным кластерам для обеспечения масштабируемости и стабильности.
- Обеспечение стабильности, масштабируемости и видимости кластера для создания связи приложения и его SLA.
- Управления ресурсами и квотами, чтобы приложения не конфликтовали между собой, а масштаб кластера контролировался с нашей стороны.
- Новая платформа CI/CD для поддержки и развертывания приложений в Kubernetes.
Fonte: habr.com
