

Annuncio
Colleghi, a metà estate prevedo di pubblicare un altro ciclo di articoli sul design dei sistemi di servizi di massa: “Esperimento VTrade” — un tentativo di scrivere un framework per sistemi di trading. Nel ciclo verrà esaminata sia la teoria che la pratica della creazione di una borsa, un'asta e un negozio. Alla fine dell'articolo invito a votare per gli argomenti che vi interessano di più.

Questo è l'ultimo articolo del ciclo sulle applicazioni reattive distribuite in Erlang/Elixir. Nel si possono trovare le basi teoriche dell'architettura reattiva. illustra i principali modelli e meccanismi per la costruzione di sistemi simili.
Oggi affronteremo questioni relative allo sviluppo del codice e ai progetti nel loro complesso.
Organizzazione dei servizi
Nella vita reale, durante lo sviluppo di un servizio, spesso è necessario combinare diversi modelli di interazione in un unico controller. Ad esempio, il servizio users, che gestisce i profili degli utenti del progetto, deve rispondere alle richieste req-resp e informare sugli aggiornamenti dei profili tramite pub-sub. Questo caso è piuttosto semplice: a gestire il messaging c'è un singolo controller che implementa la logica del servizio e pubblica gli aggiornamenti.
La situazione si complica quando dobbiamo realizzare un servizio distribuito e a prova di guasto. Immaginiamo che i requisiti per users siano cambiati:
- ora il servizio deve gestire le richieste su 5 nodi del cluster,
- essere in grado di eseguire compiti in background,
- e anche gestire dinamicamente le liste di iscrizione agli aggiornamenti dei profili.
Nota: Non consideriamo la questione della conservazione e replicazione consistente dei dati. Presumiamo che queste questioni siano state risolte in precedenza e che nella sistema esista già uno strato di memorizzazione affidabile e scalabile, mentre i gestori hanno meccanismi per interagire con esso.
La descrizione formale del servizio utenti è diventata più complessa. Dal punto di vista del programmatore, grazie all'uso del messaging, le modifiche sono minime. Per soddisfare il primo requisito, dobbiamo configurare il bilanciamento presso il punto di scambio req-resp.
La necessità di gestire i compiti in background si presenta frequentemente. Nel contesto degli utenti, questo può includere controlli sui documenti degli utenti, elaborazione di multimedia caricato o sincronizzazione dei dati con i social media. Queste attività devono essere distribuite all'interno del cluster e monitorate. Pertanto, abbiamo due opzioni: utilizzare il modello di distribuzione dei compiti dell'articolo precedente, oppure, se non si adatta, scrivere un pianificatore di compiti personalizzato che gestisca il pool di elaboratori nel modo necessario.
Il punto 3 richiede l'espansione del modello pub-sub. Per implementarlo, dopo aver creato il punto di scambio pub-sub, dobbiamo anche avviare un controller di quel punto all'interno del nostro servizio. In questo modo, sembrerebbe che trasferiamo la logica di gestione dell'iscrizione e delle disiscrizioni dallo strato messaging all'implementazione degli utenti.
Di conseguenza, la scomposizione del compito ha mostrato che per soddisfare i requisiti dobbiamo avviare 5 istanze del servizio su diversi nodi e creare un'entità aggiuntiva: un controller pub-sub, responsabile dell'iscrizione.
Per avviare 5 gestori non è necessario modificare il codice del servizio. L'unica azione aggiuntiva è configurare le regole di bilanciamento al punto di scambio, di cui parleremo più avanti.
Si è presentata anche un'ulteriore complessità: il controller pub-sub e il pianificatore di attività personalizzato devono funzionare in un'unica istanza. Ancora una volta, il servizio messaging, in quanto fondamentale, deve fornire un meccanismo di leadership.
Scelta del leader
Nei sistemi distribuiti, la selezione di un leader è la procedura di designazione di un unico processo responsabile della pianificazione dell'elaborazione distribuita di un certo carico.
Nei sistemi che non tendono alla centralizzazione, si applicano algoritmi generali e algoritmi basati sul consenso, come Paxos o Raft.
Poiché il messaging funge da broker e elemento centrale, è a conoscenza di tutti i controller del servizio che sono candidati a diventare leader. Il messaging può nominare un leader senza alcuna votazione.
Tutti i servizi, dopo l'avvio e la connessione al punto di scambio, ricevono un messaggio di sistema. #'$leader'{exchange = ?EXCHANGE, pid = LeaderPid, servers = Servers}. Nel caso in cui LeaderPid corrisponda al pid processo attuale, viene nominato leader e l'elenco Servers include tutti i nodi e i loro parametri.
Nel momento in cui appare un nuovo nodo e uno funzionante viene disattivato nel cluster, tutti i controller del servizio ricevono #'$slave_up'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} e #'$slave_down'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} rispettivamente.
In questo modo, tutti i componenti sono a conoscenza di tutte le modifiche e nel cluster è garantito un solo leader in ogni momento.
Intermediari
Per implementare processi distribuiti complessi e ottimizzare l'architettura esistente, è utile utilizzare intermediari.
Per non dover modificare il codice dei servizi e affrontare, ad esempio, la registrazione o la logistica dei messaggi, è possibile inserire un gestore proxy davanti al servizio, che eseguirà tutto il lavoro aggiuntivo.
Un classico esempio di ottimizzazione pub-sub è un'applicazione distribuita con un core di business che genera eventi di aggiornamento, come ad esempio una variazione del prezzo sul mercato, e uno strato di accesso costituito da N server che forniscono un'API websocket per i clienti web.
Se affrontiamo il problema in modo diretto, la gestione del cliente appare nel seguente modo:
- il cliente stabilisce le connessioni con la piattaforma. Sul lato server, dove termina il traffico, avviene l'avvio di un processo che gestisce questa connessione.
- nel contesto del processo di gestione, avviene l'autenticazione e la sottoscrizione agli aggiornamenti. Il processo chiama il metodo subscribe per i topic.
- dopo la generazione di un evento nel core, esso viene recapitato ai processi che gestiscono le connessioni.
Immaginiamo di avere 50000 iscritti al topic "news". Gli iscritti sono distribuiti uniformemente su 5 server. Di conseguenza, ogni aggiornamento, giungendo al punto di scambio, verrà replicato 50000 volte: 10000 volte su ciascun server, in base al numero di iscritti su di esso. Non è proprio un sistema efficiente, vero?
Per migliorare la situazione, introduciamo un proxy con lo stesso nome del punto di scambio. Il registrar dei nomi globali deve essere in grado di restituire il processo più vicino per nome, ed è fondamentale.
Avvieremo questo proxy sui server del layer di accesso, e tutti i nostri processi che gestiscono l'API websocket si iscriveranno a esso, anziché al punto di scambio pub-sub originale nel core. Il proxy si iscrive al core solo in caso di iscrizione unica e replica il messaggio ricevuto a tutti i suoi iscritti.
Di conseguenza, tra il core e i server di accesso verranno trasmessi 5 messaggi, invece di 50000.
Routing e bilanciamento
Req-Resp
Nell'attuale implementazione del messaging esistono 7 strategie di distribuzione delle richieste:
default. La richiesta viene inviata a tutti i controller.round-robin. Viene effettuato un ciclo e una distribuzione ciclica delle richieste tra i controller.consenso. I controller che servono il servizio sono divisi in un leader e dei subordinati. Le richieste vengono inviate solo al leader.consenso & round-robin. Nel gruppo c'è un leader, ma le richieste sono distribuite tra tutti i membri.sticky. Viene calcolata la funzione hash e associata a un determinato gestore. Le richieste successive con questa firma vengono indirizzate a questo stesso gestore.sticky-fun. Durante l'inizializzazione del punto di scambio viene inoltre fornita una funzione per il calcolo dell'hash perstickyil bilanciamento.divertimento. Simile a sticky-fun, ma consente anche di reindirizzare, rifiutare o pre-elaborare.
La strategia di distribuzione viene definita durante l'inizializzazione del punto di scambio.
Oltre al bilanciamento, il messaging consente di etichettare le entità. Esaminiamo i tipi di etichette nel sistema:
- Etichetta di connessione. Consente di capire attraverso quale connessione sono arrivati gli eventi. Viene utilizzata quando il processo del controller si connette a un singolo punto di scambio, ma con diverse chiavi di instradamento.
- Tag del servizio. Permette di raggruppare i gestori e di ampliare le funzionalità di instradamento e bilanciamento per un servizio. Per il pattern req-resp, l'instradamento è lineare. Inviamo la richiesta al punto di scambio, che la trasmette al servizio. Ma se dobbiamo suddividere i gestori in gruppi logici, il raggruppamento avviene tramite i tag. Specificando un tag, la richiesta verrà indirizzata a un gruppo specifico di controller.
- Tag della richiesta. Permette di distinguere le risposte. Poiché il nostro sistema è asincrono, per elaborare le risposte del servizio è necessario avere la possibilità di indicare il RequestTag quando si invia la richiesta. Grazie a questo, possiamo capire a quale richiesta è arrivata la risposta.
Pub-sub
Per pub-sub è tutto un po' più semplice. Abbiamo un punto di scambio al quale vengono pubblicati i messaggi. Il punto di scambio distribuisce i messaggi tra i sottoscrittori che si sono iscritti alle chiavi di instradamento di loro interesse (si può dire che è analogo ai temi).
Scalabilità e resilienza
La scalabilità del sistema nel suo complesso dipende dal grado di scalabilità dei livelli e dei componenti del sistema:
- I servizi si scalano aggiungendo ulteriori nodi con gestori di questo servizio al cluster. Durante l'operatività esperta, è possibile scegliere la politica di bilanciamento ottimale.
- Il servizio di messaging all'interno di un cluster separato, in generale, si scalano o spostando le aree di scambio particolarmente cariche su nodi separati del cluster, o aggiungendo processi proxy nelle zone di alta intensità del cluster.
- La scalabilità dell'intero sistema come caratteristica dipende dalla flessibilità dell'architettura e dalla possibilità di unire cluster singoli in un'entità logica comune.
Il successo del progetto spesso dipende dalla semplicità e rapidità di scalabilità. Il messaging nell'attuale implementazione cresce insieme all'applicazione. Anche se non abbiamo abbastanza cluster con 50-60 macchine, possiamo ricorrere alla federazione. Purtroppo, il tema della federazione esula da questo articolo.
Riserva
Quando abbiamo analizzato il bilanciamento del carico, abbiamo già discusso della ridondanza dei controller dei servizi. Tuttavia, anche il messaging deve essere ridondato. In caso di guasto di un nodo o di una macchina, il messaging deve riprendersi automaticamente nel più breve tempo possibile.
Nei miei progetti utilizzo nodi aggiuntivi che gestiscono il carico in caso di guasto. In Erlang esiste un'implementazione standard della modalità distribuita per le applicazioni OTP. La modalità distribuita consente proprio di ripristinare in caso di errore avviando l'applicazione che è andata in crash su un altro nodo preavviato. Il processo è trasparente, dopo un guasto l'applicazione si sposta automaticamente sul nodo di failover. Puoi leggere di più su questa funzionalità. .
Prestazioni
Proviamo a confrontare, anche se solo approssimativamente, le prestazioni di rabbitmq e del nostro sistema di messaggistica personalizzato.
Ho trovato dei test di rabbitmq effettuati dal team di openstack.
Nel punto 6.14.1.2.1.2.2. del documento originale è presentato il risultato di RPC CAST:
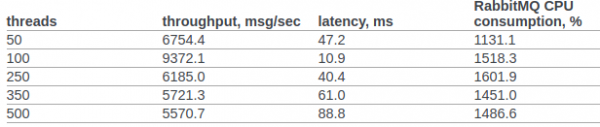
Inizialmente non apporteremo alcuna configurazione aggiuntiva al kernel OS o alla VM Erlang. Condizioni per il test:
- erl opts: +A1 +sbtu.
- Il test su un singolo nodo Erlang viene eseguito su un notebook con un vecchio i7 in versione mobile.
- I test del cluster si svolgono su server con rete 10G.
- Il codice funziona in contenitori Docker. Rete in modalità NAT.
Codice del test:
req_resp_bench(_) ->
W = perftest:comprehensive(10000,
fun() ->
messaging:request(?EXCHANGE, default, ping, self()),
receive
#'$msg'{message = pong} -> ok
after 5000 ->
throw(timeout)
end
end
),
true = lists:any(fun(E) -> E >= 30000 end, W),
ok.Scenario 1: Il test viene eseguito su un laptop con un vecchio processore i7 mobile. Il test, il messaging e il servizio vengono eseguiti su un singolo nodo all'interno dello stesso contenitore docker:
Cicli sequenziali da 10000 in ~0 secondi (26987 cicli/s)
Cicli sequenziali da 20000 in ~1 secondo (26915 cicli/s)
Cicli sequenziali da 100000 in ~4 secondi (26957 cicli/s)
Cicli paralleli da 2 100000 in ~2 secondi (44240 cicli/s)
Cicli paralleli da 4 100000 in ~2 secondi (53459 cicli/s)
Cicli paralleli da 10 100000 in ~2 secondi (52283 cicli/s)
Cicli paralleli da 100 100000 in ~3 secondi (49317 cicli/s)Scenario 2: 3 nodi avviati su macchine diverse sotto docker (NAT).
Cicli sequenziali da 10000 in ~1 secondo (8684 cicli/s)
Cicli sequenziali da 20000 in ~2 secondi (8424 cicli/s)
Cicli sequenziali da 100000 in ~12 secondi (8655 cicli/s)
Cicli paralleli da 2 100000 in ~7 secondi (15160 cicli/s)
Cicli paralleli da 4 100000 in ~5 secondi (19133 cicli/s)
Cicli paralleli da 10 100000 in ~4 secondi (24399 cicli/s)
Cicli paralleli da 100 100000 in ~3 secondi (34517 cicli/s)In tutti i casi, l'utilizzo della CPU non ha superato il 250%
Risultati
Spero che questo ciclo non sembri un flusso di coscienza e che la mia esperienza possa portare un reale beneficio sia ai ricercatori di sistemi distribuiti che ai praticanti che si trovano all'inizio del percorso di costruzione di architetture distribuite per i loro sistemi aziendali e guardano con interesse a Erlang/Elixir, ma si chiedono se ne valga la pena...
Foto
Solo gli utenti registrati possono partecipare al sondaggio. , per favore.
Quali temi dovrei approfondire maggiormente nel ciclo "Esperimento VTrade"?
Teoria: Mercati, ordini e il loro tempo di validità: DAY, GTD, GTC, IOC, FOK, MOO, MOC, LOO, LOC
Libro degli ordini. Teoria e pratica dell'implementazione del libro con raggruppamenti
Visualizzazione commerciale: Tick, barre, risoluzioni. Come memorizzare e come incollare
Back office. Pianificazione e sviluppo. Monitoraggio dei dipendenti e investigazione degli incidenti
API. Analizziamo quali interfacce servono e come realizzarle
Memorizzazione delle informazioni: PostgreSQL, Timescale, Tarantool nei sistemi di trading
Reattività nei sistemi di trading
Altro. Scriverò nei commenti
6 utenti hanno votato. 4 utenti si sono astenuti.
Fonte: habr.com
