

Buongiorno! Mi chiamo Danil Lipovoy, e il nostro team di Sbertech ha iniziato a utilizzare HBase come archivio di dati operativi. Durante lo studio di questo strumento, abbiamo accumulato esperienze che desideravamo sistematizzare e descrivere (speriamo che possano essere utili a molti). Tutti gli esperimenti riportati di seguito sono stati condotti con le versioni HBase 1.2.0-cdh5.14.2 e 2.0.0-cdh6.0.0-beta1.
- Architettura generale
- Scrittura di dati in HBASE
- Lettura di dati da HBASE
- Caching dei dati
- Elaborazione batch dei dati MultiGet/MultiPut
- Strategia di divisione delle tabelle in regioni (splitting)
- Tolleranza ai guasti, compattazione e località dei dati
- Impostazioni e prestazioni
- Carico di test
- Conclusioni
1. Architettura generale
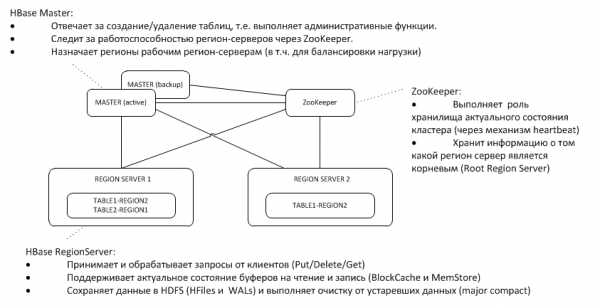
Un Master di riserva ascolta il heartbeat del Master attivo sul nodo ZooKeeper e, in caso di assenza, assume le funzioni di Master.
2. Scrittura di dati in HBASE
Iniziamo considerando il caso più semplice: la registrazione di un oggetto chiave-valore in una tabella tramite put(rowkey). Il client deve prima determinare dove si trova il server regionale principale (Root Region Server - RRS) che ospita la tabella hbase:meta. Questa informazione viene ottenuta da ZooKeeper. Successivamente, il client si rivolge al RRS e legge la tabella hbase:meta, dalla quale estrae informazioni su quale RegionServer (RS) è responsabile della memorizzazione dei dati per la chiave rowkey specificata nella tabella di interesse. A fini di utilizzo futuro, la tabella meta viene memorizzata nella cache dal client e pertanto le successive chiamate avvengono più rapidamente, direttamente al RS.
Successivamente, RS, ricevuta la richiesta, scrive per prima cosa nel WriteAheadLog (WAL), necessario per il ripristino in caso di guasti. Poi salva i dati nel MemStore. Questo è un buffer in memoria che contiene un insieme ordinato di chiavi per questa regione. La tabella può essere suddivisa in regioni (partizioni), ciascuna delle quali contiene un insieme di chiavi non sovrapposto. Ciò consente, distribuendo le regioni su server diversi, di ottenere prestazioni superiori. Tuttavia, nonostante l'evidenza di questa affermazione, vedremo in seguito che non funziona in tutti i casi.
Dopo aver posizionato la registrazione nel MemStore, viene restituita al cliente una risposta che indica che la registrazione è stata salvata con successo. In realtà, però, è conservata solo nel buffer e sarà trasferita su disco solo dopo un certo intervallo di tempo o quando verrà riempita con nuovi dati.
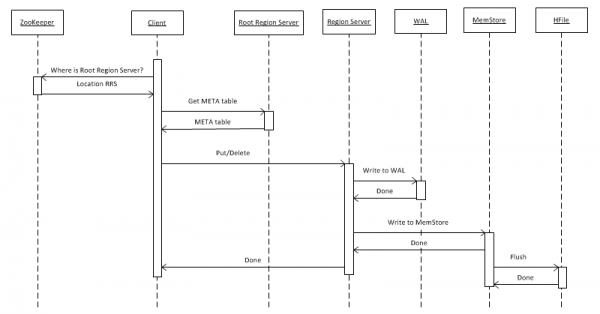
Durante l'operazione 'Delete' non avviene l'eliminazione fisica dei dati. Vengono semplicemente contrassegnati come eliminati, e la loro rimozione avviene al momento della chiamata alla funzione major compact, di cui si parla più dettagliatamente al punto 7.
I file in formato HFile si accumulano in HDFS e periodicamente viene avviato un processo di minor compact, che unisce semplicemente file piccoli in file più grandi, senza eliminare nulla. Col tempo, questo genera un problema che si manifesta solo durante la lettura dei dati (ne parleremo più avanti).
Oltre al processo di caricamento descritto sopra, esiste una procedura molto più efficiente, che costituisce forse il punto di forza principale di questo database: BulkLoad. Essa consiste nel creare autonomamente HFiles e scriverli su disco, il che consente di scalare in modo eccellente e di raggiungere velocità notevoli. In sostanza, il limite non è HBase, ma le capacità dell'hardware. Di seguito sono riportati i risultati del caricamento su un cluster composto da 16 RegionServer e 16 NodeManager YARN (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 thread), versione HBase 1.2.0-cdh5.14.2.
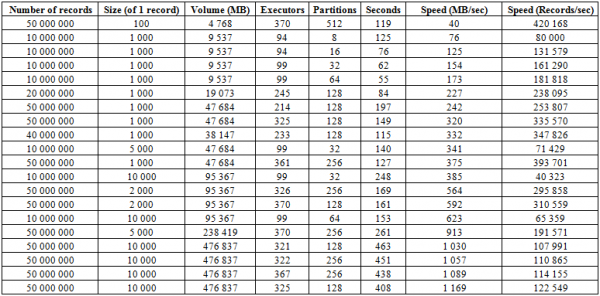
Qui si può vedere che aumentando il numero di partizioni (regioni) nella tabella, così come gli executor Spark, otteniamo un incremento della velocità di caricamento. Inoltre, la velocità dipende dal volume di scrittura. Blocchi grandi offrono un aumento in megabyte al secondo, mentre quelli piccoli aumentano il numero di record inseriti per unità di tempo, a parità di condizioni.
È possibile avviare il caricamento in due tabelle contemporaneamente, raddoppiando così la velocità. Di seguito si può vedere che la scrittura di blocchi da 10 KB in due tabelle avviene a una velocità di circa 600 MB/sec per ciascuna (complessivamente 1275 MB/sec), che corrisponde alla velocità di scrittura in una sola tabella di 623 MB/sec (vedi n. 11 sopra).

Il secondo avvio con registrazioni da 50 KB mostra che la velocità di caricamento aumenta solo lievemente, il che indica che ci si sta avvicinando ai valori massimi. Occorre inoltre tenere presente che non si crea praticamente alcun carico su HBASE; tutto ciò che è richiesto è prima restituire i dati da hbase:meta e, dopo l'inserimento degli HFiles, svuotare i dati BlockCache e salvare il buffer MemStore su disco, se non è vuoto.
3. Lettura dei dati da HBASE
Se si considera che il cliente ha già tutte le informazioni da hbase:meta (vedi punto 2), la richiesta viene inviata direttamente al RS che conserva la chiave necessaria. Inizialmente, la ricerca avviene in MemCache. Indipendentemente dal fatto che ci siano dati o meno, viene effettuata una ricerca anche nel buffer BlockCache e, se necessario, negli HFiles. Se vengono trovati dati nel file, vengono inseriti in BlockCache e la prossima volta saranno restituiti più rapidamente. La ricerca in HFile avviene piuttosto rapidamente grazie all'uso del filtro di Bloom, che determinando un piccolo volume di dati stabilisce subito se quel file contiene la chiave necessaria e, in caso contrario, passa al successivo.
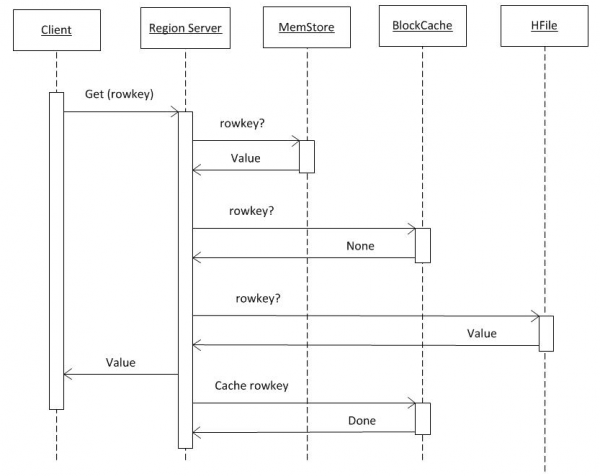
Ricevuti i dati da queste tre fonti, il RS forma la risposta. In particolare, può trasmettere più versioni dell'oggetto trovate se il cliente ha richiesto versioning.
4. Caching dei dati
I buffer MemStore e BlockCache occupano fino all'80% della memoria on-heap allocata per RS (il resto è riservato per compiti di servizio di RS). Se il modo tipico di utilizzo prevede che i processi scrivano e leggano immediatamente i medesimi dati, ha senso ridurre BlockCache e aumentare MemStore, poiché durante la scrittura i dati non vengono memorizzati nella cache per la lettura, quindi l'utilizzo di BlockCache avverrà meno frequentemente. Il buffer BlockCache è composto da due parti: LruBlockCache (sempre on-heap) e BucketCache (di solito off-heap o su SSD). È consigliabile utilizzare BucketCache quando ci sono molte richieste di lettura e non si riescono a memorizzare in LruBlockCache, causando un'attiva operazione del Garbage Collector. Tuttavia, non ci si può aspettare un aumento radicale delle prestazioni dall'uso della cache per la lettura, ma ne parleremo di nuovo al punto 8.
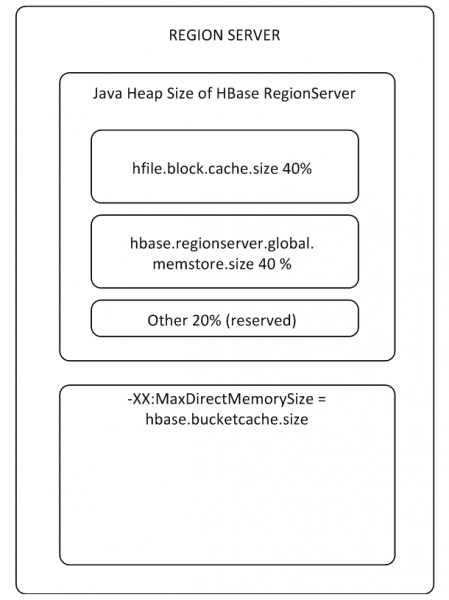
BlockCache è unico per tutto il RS, mentre MemStore è specifico per ciascuna tabella (uno per ogni Column Family).
Come In teoria, quando i dati vengono registrati, non vengono messi nella cache e, in effetti, i parametri CACHE_DATA_ON_WRITE per la tabella e "Cache DATA on Write" per RS sono impostati su false. Tuttavia, nella pratica, se si scrivono dati nel MemStore, poi lo si svuota su disco (così facendo), successivamente si elimina il file risultante, eseguendo quindi una richiesta get, riusciremo a ottenere i dati con successo. E anche se si disattiva completamente il BlockCache e si riempie la tabella con nuovi dati, poi si effettua il flush del MemStore su disco, li si elimina e si richiede da un'altra sessione, comunque verranno recuperati da qualche parte. Quindi HBase conserva non solo i dati, ma anche misteri enigmatici.
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
Il parametro "Cache DATA on Read" è impostato su false. Se avete idee, benvenuti a discuterne nei commenti.
5. Elaborazione batch dei dati MultiGet/MultiPut
L'elaborazione di richieste singole (Get/Put/Delete) è un'operazione piuttosto costosa, quindi è consigliabile raggrupparle in List o List quando possibile, il che può portare a un significativo miglioramento delle prestazioni. Questo vale in particolare per le operazioni di scrittura, mentre nella lettura c'è un altro aspetto critico. Nel grafico sottostante è mostrato il tempo di lettura di 50.000 registrazioni da MemStore. La lettura è stata effettuata in un singolo thread e sull'asse orizzontale è rappresentato il numero di chiavi nella richiesta. Si può osservare che aumentando a mille chiavi in un'unica richiesta, il tempo di esecuzione diminuisce, ovvero la velocità aumenta. Tuttavia, con la modalità MSLAB attivata di default, dopo questa soglia inizia un drastico calo delle prestazioni, e più è ampio il volume dei dati nella registrazione, più lungo è il tempo di esecuzione.
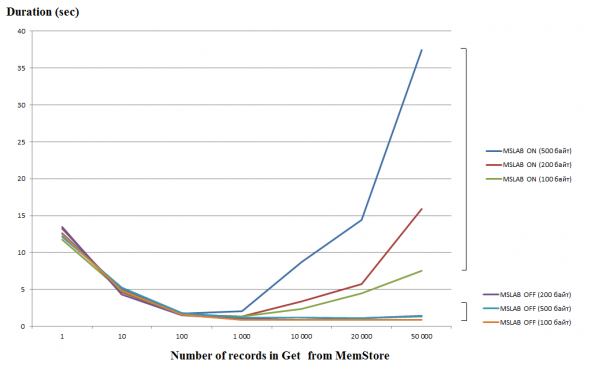
I test sono stati eseguiti su una macchina virtuale, 8 core, versione HBase 2.0.0-cdh6.0.0-beta1.
La modalità MSLAB è progettata per ridurre la frammentazione dell'heap, che si verifica a causa della mescolanza di dati di nuove e vecchie generazioni. Come soluzione al problema, quando MSLAB è attivato, i dati vengono immessi in celle (chunk) relativamente piccole e vengono elaborati a blocchi. Di conseguenza, quando il volume nel pacchetto di dati richiesto supera la dimensione allocata, le prestazioni subiscono un netto calo. D'altra parte, disattivare questa modalità non è desiderabile, poiché comporterebbe interruzioni a causa del GC nei momenti di intensa operazione con i dati. Un buon approccio potrebbe essere aumentare il volume della cella, nel caso di scrittura attiva tramite put contemporaneamente alla lettura. È importante notare che il problema non si presenta se, dopo la scrittura, si esegue il comando flush che scarica MemStore su disco o se si utilizza il caricamento tramite BulkLoad. Nella tabella sottostante è mostrato che le richieste da MemStore di dati di maggior volume (e quantità uguale) portano a un rallentamento. Tuttavia, aumentando il chunksize, si riporta il tempo di elaborazione alla normalità.
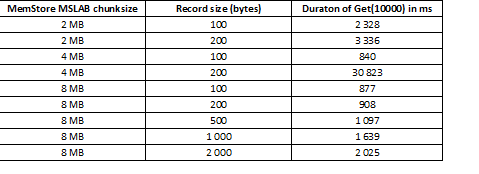
Oltre ad aumentare il chunksize, è utile suddividere i dati per regioni, ossia fare lo splitting delle tabelle. Questo porta a un numero inferiore di richieste per ciascuna regione e, se vengono inserite in una cella, la risposta rimane buona.
6. Strategia di suddivisione delle tabelle in regioni (splitting)
Poiché HBase è un archivio key-value e la partizione è effettuata in base alla chiave, è estremamente importante suddividere i dati uniformemente tra tutte le regioni. Ad esempio, partizionare questa tabella in tre parti porterà a dati distribuiti su tre regioni:
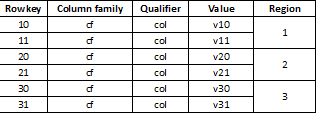
A volte ciò porta a un rallentamento drastico, se i dati caricati in seguito hanno valori long che iniziano per lo più con la stessa cifra, per esempio:
1000001
1000002
…
1100003
Poiché le chiavi sono memorizzate come array di byte, tutte inizieranno in modo identico e apparterranno a una regione #1 che memorizza questo intervallo di chiavi. Ci sono varie strategie di suddivisione:
HexStringSplit – Converte la chiave in una stringa con codifica esadecimale nell'intervallo «00000000» => «FFFFFFFF», riempiendo a sinistra con zeri.
UniformSplit – Trasforma una chiave in un array di byte con codifica esadecimale nell'intervallo "00" => "FF", riempiendo gli spazi a destra con zeri.
Inoltre, è possibile specificare qualsiasi intervallo o insieme di chiavi per la suddivisione e configurare l'auto-split. Tuttavia, uno degli approcci più semplici ed efficaci è UniformSplit e l'uso della concatenazione dell'hash, ad esempio la coppia di byte più significativa derivante dall'elaborazione della chiave tramite la funzione CRC32(rowkey) e la chiave stessa:
hash + rowkey
In questo modo, tutti i dati saranno distribuiti uniformemente tra le regioni. Durante la lettura, i primi due byte vengono semplicemente scartati e rimane la chiave originale. Inoltre, RS controlla la quantità di dati e chiavi nella regione e, al superamento dei limiti, la suddivide automaticamente in parti.
7. Resilienza e località dei dati
Poiché ogni insieme di chiavi è gestito da una sola regione, la soluzione ai problemi legati ai guasti di RS o all'interruzione del servizio è quella di memorizzare tutti i dati necessari in HDFS. In caso di guasto di un RS, il master lo rileva attraverso l'assenza di heartbeat nel nodo ZooKeeper. Allora assegna la regione a un altro RS e, poiché gli HFiles sono archiviati nel file system distribuito, il nuovo proprietario li legge e continua a servire i dati. Tuttavia, poiché parte dei dati potrebbe trovarsi in MemStore e non essere ancora stata trasferita in HFiles, per ripristinare la cronologia delle operazioni viene utilizzato il WAL, anch'esso archiviato in HDFS. Dopo aver applicato le modifiche, il RS è in grado di rispondere alle richieste, ma il trasloco comporta il rischio che parte dei dati e i processi ad essi associati si trovino su nodi diversi, riducendo così la locality.
La soluzione al problema è la major compaction: questa procedura sposta i file sui nodi che li gestiscono (dove sono ubicati i loro regioni), con un conseguente aumento significativo del carico sulla rete e sui dischi durante questa operazione. Tuttavia, in seguito, l'accesso ai dati risulta notevolmente più veloce. Inoltre, la major_compaction unisce tutti gli HFile in un unico file all'interno della regione e pulisce i dati in base alle impostazioni della tabella. Ad esempio, è possibile specificare il numero di versioni di un oggetto da mantenere o il tempo di vita dopo il quale l'oggetto viene eliminato fisicamente.
Questa procedura può avere un impatto molto positivo sul funzionamento di HBase. Nella figura sottostante si può vedere come le prestazioni siano deteriorate a causa della scrittura attiva di dati. Qui si può osservare come 40 flussi scrivano in una tabella mentre 40 flussi leggono dati simultaneamente. I flussi di scrittura generano un numero crescente di HFiles, che vengono letti dagli altri flussi. Di conseguenza, sempre più dati devono essere rimossi dalla memoria e alla fine inizia a funzionare il GC, che praticamente paralizza tutto il sistema. L'avvio di una major compaction ha portato alla pulizia delle congestioni accumulate e al ripristino delle prestazioni.
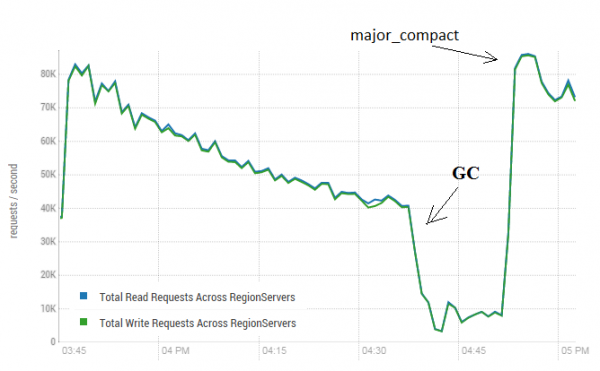
Il test è stato eseguito su 3 DataNode e 4 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 thread). Versione HBase 1.2.0-cdh5.14.2
È importante sottolineare che il processo di major compaction è stato eseguito su una tabella "vivente", in cui venivano attivamente scritti e letti dati. In rete si è sostenuto che ciò potrebbe portare a risposte errate durante la lettura dei dati. Per verificare, è stato avviato un processo che generava nuovi dati e li scriveva nella tabella. Successivamente, i dati venivano immediatamente letti e confrontati per vedere se il valore ottenuto corrispondesse a quello registrato. Durante l'esecuzione di questo processo, il major compaction è stato avviato circa 200 volte senza registrare alcun errore. È possibile che il problema si manifesti raramente e solo durante carichi elevati, quindi è più sicuro comunque fermare in modo programmato i processi di scrittura e lettura e eseguire la pulizia senza consentire tali cali di GC.
Inoltre, il major compaction non influisce sullo stato del MemStore; per svuotarlo su disco e compattarlo, è necessario utilizzare il flush (connection.getAdmin().flush(TableName.valueOf(tblName))).
8. Impostazioni e prestazioni
Come già detto, HBase ha un successo maggiore quando non deve eseguire operazioni, durante il BulkLoad. Tuttavia, questo vale per la maggior parte dei sistemi e delle persone. Questo strumento è più adatto per l'inserimento massivo di dati in blocchi, mentre, se il processo richiede l'esecuzione di molte richieste concorrenti di lettura e scrittura, vengono utilizzati i comandi Get e Put descritti precedentemente. Per determinare i parametri ottimali, sono stati eseguiti test con diverse combinazioni di parametri delle tabelle e impostazioni.
- Sono stati avviati 10 thread contemporaneamente per 3 volte di seguito (chiamiamo questo un blocco di thread).
- Il tempo di esecuzione di tutti i thread nel blocco è stato mediato e rappresenta il risultato finale del blocco.
- Tutti i thread lavoravano sulla stessa tabella.
- Prima di ciascun avvio del blocco di thread, veniva eseguita una major compaction.
- Ogni blocco eseguiva solo una delle seguenti operazioni:
— Put
— Get
— Get+Put
- Ogni blocco eseguiva 50.000 ripetizioni della propria operazione.
- La dimensione della scrittura nel blocco era di 100 byte, 1000 byte o 10000 byte (random).
- I blocchi venivano avviati con un numero variabile di chiavi richieste (o una chiave o 10).
- I blocchi venivano avviati con diverse impostazioni della tabella. I parametri modificati erano:
— BlockCache = attivato o disattivato
— BlockSize = 65 KB o 16 KB
— Partizioni = 1, 5 o 30
— MSLAB = attivato o disattivato
In questo modo, il blocco appare così:
a. La modalità MSLAB era attivata/disattivata.
b. Veniva creata una tabella con i seguenti parametri: BlockCache = true/none, BlockSize = 65/16 KB, Partizioni = 1/5/30.
c. Veniva impostata la compressione GZ.
d. Venivano avviati 10 thread contemporaneamente che eseguivano 1/10 operazioni put/get/get+put su questa tabella con registrazioni di 100/1000/10000 byte, effettuando 50.000 richieste consecutive (chiavi randomiche).
e. Il punto d veniva ripetuto tre volte.
f. Il tempo di esecuzione di tutti i thread veniva mediato.
Sono state verificate tutte le possibili combinazioni. È prevedibile che, con un aumento delle dimensioni delle registrazioni, la velocità diminuisca, o che disabilitare la cache porti a un rallentamento. Tuttavia, l'obiettivo era comprendere il grado e l'importanza dell'influenza di ciascun parametro, quindi i dati raccolti sono stati forniti come input a una funzione di regressione lineare, che consente di valutare l'affidabilità tramite la statistica t. Di seguito sono riportati i risultati degli incrementi delle operazioni Put. L'insieme completo delle combinazioni è pari a 2*2*3*2*3 = 144 varianti + 72 poiché alcune sono state eseguite due volte. Pertanto, in totale ci sono stati 216 esecuzioni:
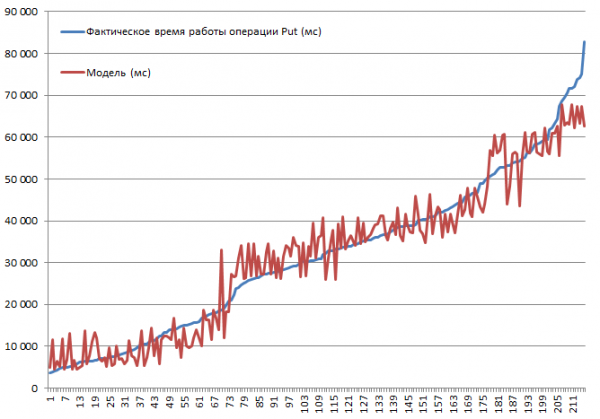
Il test è stato effettuato su un mini-cluster composto da 3 DataNode e 4 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 thread). Versione HBase 1.2.0-cdh5.14.2.
La velocità di inserimento più alta, 3.7 secondi, è stata ottenuta con la modalità MSLAB disabilitata, su una tabella con una sola partizione, con BlockCache attivato, BlockSize = 16, registrazioni di 100 byte in pacchetti da 10.
La velocità di inserimento più bassa, 82.8 secondi, è stata ottenuta con la modalità MSLAB attivata, su una tabella con una sola partizione, con BlockCache attivato, BlockSize = 16, registrazioni di 10000 byte per 1.
Ora diamo un'occhiata al modello. Vediamo una buona qualità del modello secondo R2, ma è chiaro che l'estrapolazione qui è sconsigliata. Il comportamento reale del sistema al variare dei parametri non sarà lineare; questo modello non è utile per previsioni, ma per comprendere cosa è accaduto entro i parametri stabiliti. Ad esempio, qui vediamo secondo il criterio di Student che per l'operazione Put i parametri BlockSize e BlockCache non hanno significato (cosa abbastanza prevedibile):

Tuttavia, il fatto che l'aumento del numero di partizioni porti a una diminuzione delle prestazioni è piuttosto inaspettato (avevamo già visto un impatto positivo dell'aumento delle partizioni durante il BulkLoad), sebbene sia spiegabile. In primo luogo, per l'elaborazione si devono formare richieste a 30 regioni anziché a una sola, e la quantità di dati non è tale da giustificare un guadagno. In secondo luogo, il tempo totale di esecuzione è determinato dal RS più lento, e poiché il numero di DataNode è inferiore a quello degli RS, alcune regioni hanno una località nulla. Andiamo a vedere i cinque leader:

Ora valutiamo i risultati dell'esecuzione dei blocchi Get:

Il numero di partizioni ha perso importanza, probabilmente perché i dati vengono ben memorizzati nella cache e la cache per la lettura è il parametro più significativo (statisticamente). Naturalmente, un aumento del numero di messaggi nella richiesta è anch'esso molto utile per le prestazioni. I migliori risultati:

E infine, diamo un'occhiata al modello del blocco che prima eseguiva il get e poi il put:

Qui tutti i parametri sono significativi. E i risultati dei leader:

9. Test di carico
Infine, eseguiremo un carico piuttosto consistente, ma è sempre più interessante avere qualcosa con cui confrontarsi. Sul sito di DataStax – il principale sviluppatore di Cassandra, c'è una gamma di archivi NoSQL, incluso HBase versione 0.98.6-1. Il caricamento è stato effettuato con 40 thread, dimensione dei dati 100 byte, dischi SSD. Il risultato del test delle operazioni Read-Modify-Write ha mostrato questi risultati.
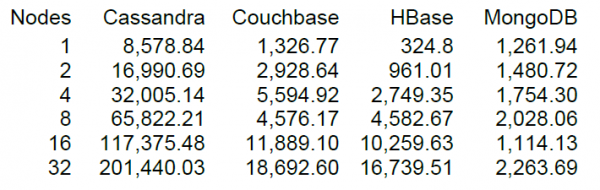
Da quanto ho capito, la lettura è stata effettuata in blocchi da 100 record e per 16 nodi HBase il test di DataStax ha mostrato una prestazione di 10.000 operazioni al secondo.
È positivo che nel nostro cluster ci siano anche 16 nodi, ma non è molto "positivo" che ci siano 64 core (thread) su ciascuno, mentre nel test di DataStax solo 4. D'altra parte, loro hanno dischi SSD, mentre noi HDD e una versione HBase più recente, e l'utilizzo della CPU durante il carico è aumentato solo di poco (visualmente del 5-10 percento). Tuttavia, proviamo a partire con questa configurazione. Le impostazioni delle tabelle sono quelle predefinite, e la lettura avviene nell'intervallo di chiavi da 0 a 50 milioni in modo casuale (cioè, sostanzialmente ogni volta è nuova). La tabella contiene 50 milioni di record, suddivisi in 64 partizioni. Le chiavi sono hashate tramite crc32. Le impostazioni delle tabelle sono predefinite, MSLAB è attivato. Avviamo 40 thread, ognuno dei quali legge un insieme di 100 chiavi casuali e immediatamente riscrive 100 byte generati su queste chiavi.
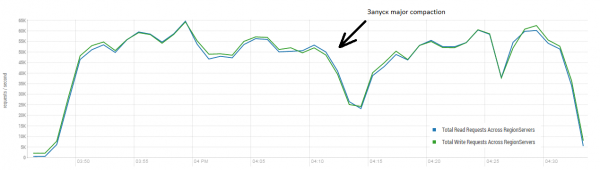
Stand: 16 DataNode e 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 thread). Versione HBase 1.2.0-cdh5.14.2.
Il risultato medio si avvicina a 40.000 operazioni al secondo, che è significativamente meglio rispetto al test di DataStax. Tuttavia, per scopi di esperimento, è possibile modificare leggermente le condizioni. È piuttosto improbabile che tutto il lavoro venga eseguito esclusivamente su una sola tabella e solo con chiavi uniche. Supponiamo che ci sia un certo insieme "caldo" di chiavi che genera il carico principale. Pertanto, proviamo a creare un carico con record più grandi (10 KB), anche a batch di 100, in 4 tabelle diverse e limitando il range delle chiavi richieste a 50.000. Nel grafico qui sotto viene mostrato il lancio di 40 thread, ogni thread legge un insieme di 100 chiavi e quindi scrive immediatamente 10 KB casuali su queste chiavi.
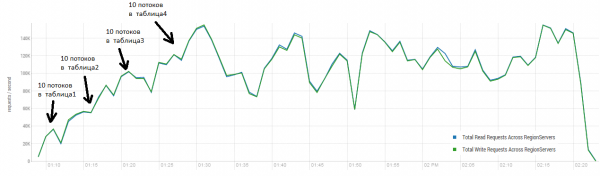
Stand: 16 DataNode e 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 thread). Versione HBase 1.2.0-cdh5.14.2.
Durante il carico, più volte è stata eseguita una major compaction; come mostrato sopra, senza questa procedura le prestazioni degraderanno gradualmente, tuttavia durante l'esecuzione si verifica anche un carico aggiuntivo. I cali di prestazione sono causati da diverse ragioni. A volte i thread terminavano il lavoro e mentre venivano riavviati si verificava una pausa, altre volte applicazioni esterne creavano un carico sul cluster.
La lettura e la scrittura immediata sono uno dei scenari di lavoro più gravosi per HBase. Se si effettuano solo richieste di put di piccole dimensioni, ad esempio di 100 byte, raggruppandole in pacchetti da 10.000 a 50.000, è possibile ottenere centinaia di migliaia di operazioni al secondo, ed è lo stesso per le richieste di sola lettura. È importante notare che i risultati sono radicalmente migliori rispetto a quelli ottenuti da DataStax, principalmente grazie alle richieste in blocco da 50.000.
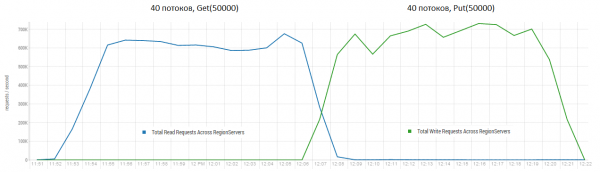
Stand: 16 DataNode e 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 thread). Versione HBase 1.2.0-cdh5.14.2.
10. Conclusioni
Questo sistema è abbastanza flessibile nella personalizzazione, ma rimane sconosciuto l'impatto di un gran numero di parametri. Alcuni di essi sono stati testati, ma non sono stati inclusi nel set di test risultante. Ad esempio, esperimenti preliminari hanno mostrato una significatività marginale di un parametro come DATA_BLOCK_ENCODING, che codifica informazioni utilizzando valori da celle vicine, cosa che è facilmente spiegabile per dati generati casualmente. Nel caso di un grande numero di oggetti ripetuti, i guadagni possono essere significativi. In generale, si può dire che HBase sembra un database piuttosto serio e ben progettato, che può essere molto performante nelle operazioni con grandi blocchi di dati, specialmente se c'è la possibilità di distribuire nel tempo i processi di lettura e scrittura.
Se qualcosa non è stato sufficientemente approfondito, sono disponibile a raccontare di più. Vi incoraggio a condividere la vostra esperienza o a discutere se non siete d'accordo su qualcosa.
Fonte: habr.com
