

In questa ricerca, volevo esaminare quali miglioramenti delle prestazioni si possano ottenere utilizzando ClickHouse come fonte di dati anziché PostgreSQL. Sono consapevole dei vantaggi di prestazione che ottengo utilizzando ClickHouse. Questi vantaggi saranno mantenuti se accedo a ClickHouse da PostgreSQL attraverso un'estensione di dati esterna (FDW)?
Gli ambienti di database sotto analisi sono PostgreSQL v11, clickhousedb_fdw e il database ClickHouse. In definitiva, eseguiremo vari query SQL da PostgreSQL v11, instradate attraverso il nostro clickhousedb_fdw al database ClickHouse. In seguito, vedremo come le prestazioni di FDW si confrontano con le stesse query eseguite nel nativo PostgreSQL e nel nativo ClickHouse.
Database ClickHouse
ClickHouse è un sistema di gestione di database basato su colonne open-source, in grado di raggiungere prestazioni da 100 a 1000 volte più veloci rispetto ai tradizionali approcci ai database, capace di gestire più di un miliardo di righe in meno di un secondo.
clickhousedb_fdw
clickhousedb_fdw — il wrapper per i dati esterni del database ClickHouse, o FDW, è un progetto open source di Percona. .
.
Come vedrai, questo fornisce un FDW per ClickHouse che consente di SELECT from e INSERT INTO un database ClickHouse da un server PostgreSQL v11.
Il FDW supporta funzionalità avanzate come aggregate e join. Questo aumenta significativamente le prestazioni sfruttando le risorse del server remoto per queste operazioni ad alta intensità di risorse.
Ambiente di benchmark
- Server Supermicro:
- Intel® Xeon® CPU E5-2683 v3 @ 2.00GHz
- 2 socket / 28 core / 56 thread
- Memoria: 256GB di RAM
- Storage: Samsung SM863 1.9TB Enterprise SSD
- Filesystem: ext4/xfs
- OS: Linux smblade01 4.15.0-42-generic #45~16.04.1-Ubuntu
- PostgreSQL: versione 11
Test di benchmark
Invece di utilizzare un set di dati generato da una macchina per questo test, abbiamo usato i dati "Performance over Time reported by the operator's uptime" dal 1987 al 2018. Puoi accedere ai dati .
Dimensione del database di 85 GB, fornendo una tabella con 109 colonne.
Query di benchmark
Questi sono i query che ho utilizzato per confrontare ClickHouse, clickhousedb_fdw e PostgreSQL.
Q#
La query contiene aggregati e Group By
Q1
SELECT DayOfWeek, count(*) AS c FROM ontime WHERE Year >= 2000 AND Year <= 2008 GROUP BY DayOfWeek ORDER BY c DESC;
Q2
SELECT DayOfWeek, count(*) AS c FROM ontime WHERE DepDelay > 10 AND Year >= 2000 AND Year <= 2008 GROUP BY DayOfWeek ORDER BY c DESC;
Q3
SELECT Origin, count(*) AS c FROM ontime WHERE DepDelay > 10 AND Year >= 2000 AND Year <= 2008 GROUP BY Origin ORDER BY c DESC LIMIT 10;
Q4
SELECT Carrier, count() FROM ontime WHERE DepDelay > 10 AND Year = 2007 GROUP BY Carrier ORDER BY count() DESC;
Q5
SELECT a.Carrier, c, c2, c1000/c2 as c3 FROM ( SELECT Carrier, count() AS c FROM ontime WHERE DepDelay > 10 AND Year = 2007 GROUP BY Carrier ) a INNER JOIN ( SELECT Carrier, count(*) AS c2 FROM ontime WHERE Year = 2007 GROUP BY Carrier ) b on a.Carrier = b.Carrier ORDER BY c3 DESC;
Q6
SELECT a.Carrier, c, c2, c1000/c2 as c3 FROM ( SELECT Carrier, count() AS c FROM ontime WHERE DepDelay > 10 AND Year >= 2000 AND Year = 2000 AND Year <= 2008 GROUP BY Carrier ) b on a.Carrier = b.Carrier ORDER BY c3 DESC;
Q7
SELECT Carrier, avg(DepDelay) * 1000 AS c3 FROM ontime WHERE Year >= 2000 AND Year <= 2008 GROUP BY Carrier;
Q8
SELECT Year, avg(DepDelay) FROM ontime GROUP BY Year;
Q9
select Year, count(*) as c1 from ontime group by Year;
Q10
SELECT avg(cnt) FROM (SELECT Year, Month, count(*) AS cnt FROM ontime WHERE DepDel15 = 1 GROUP BY Year, Month) a;
Q11
select avg(c1) from (select Year, Month, count(*) as c1 from ontime group by Year, Month) a;
Q12
SELECT OriginCityName, DestCityName, count(*) AS c FROM ontime GROUP BY OriginCityName, DestCityName ORDER BY c DESC LIMIT 10;
Q13
SELECT OriginCityName, count(*) AS c FROM ontime GROUP BY OriginCityName ORDER BY c DESC LIMIT 10;
La query contiene join
Q14
SELEZIONA a.Year, c1/c2 DA (seleziona Anno, conta()1000 come c1 da ontime DOVE DepDelay>10 GRUPPA PER Anno) a UNISCI A (seleziona Anno, conta(*) come c2 da ontime GRUPPA PER Anno) b su a.Year=b.Year ORDINAMENTO PER a.Year;
Q15
SELEZIONA a.”Anno”, c1/c2 DA (seleziona “Anno”, conta()1000 come c1 DA fontime DOVE “DepDelay”>10 GRUPPA PER “Anno”) a UNISCI A (seleziona “Anno”, conta(*) come c2 DA fontime GRUPPA PER “Anno”) b su a.”Anno”=b.”Anno”;
Tabella-1: Query utilizzate nel benchmark
Esecuzioni di query
Ecco i risultati di ciascuna delle query eseguite con diverse configurazioni del database: PostgreSQL con e senza indici, ClickHouse e clickhousedb_fdw. Il tempo è mostrato in millisecondi.
Q#
PostgreSQL
PostgreSQL (Indicizzato)
ClickHouse
clickhousedb_fdw
Q1
27920
19634
23
57
Q2
35124
17301
50
80
Q3
34046
15618
67
115
Q4
31632
7667
25
37
Q5
47220
8976
27
60
Q6
58233
24368
55
153
Q7
30566
13256
52
91
Q8
38309
60511
112
179
Q9
20674
37979
31
81
Q10
34990
20102
56
148
Q11
30489
51658
37
155
Q12
39357
33742
186
1333
Q13
29912
30709
101
384
Q14
54126
39913
124
1364212
Q15
97258
30211
245
259
Tabella-1: Tempo impiegato per eseguire le query utilizzate nel benchmark
Visualizzazione dei risultati
Il grafico mostra il tempo di esecuzione della query in millisecondi, l'asse X mostra il numero della query dalle tabelle sopra, mentre l'asse Y mostra il tempo di esecuzione in millisecondi. I risultati di ClickHouse e i dati ottenuti da postgres tramite clickhousedb_fdw sono mostrati. Dalla tabella si evince che esiste una grande differenza tra PostgreSQL e ClickHouse, ma una minima differenza tra ClickHouse e clickhousedb_fdw.
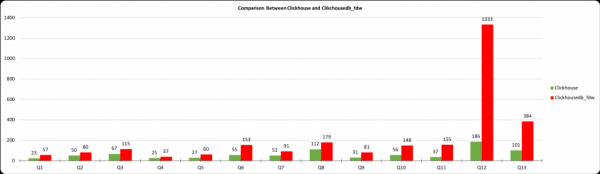
Questo grafico mostra la differenza tra ClickhouseDB e clickhousedb_fdw. Nella maggior parte delle interrogazioni, le spese generali di FDW non sono così elevate e risultano appena significative, tranne che per la Q12. Questa interrogazione include join e una clausola ORDER BY. A causa della clausola ORDER BY, GROUP/BY e ORDER BY non vengono omessi fino a ClickHouse.
Nella tabella 2 vediamo un picco nei tempi delle interrogazioni Q12 e Q13. Ripeto, questo è causato dalla clausola ORDER BY. Per confermare ciò, ho eseguito le interrogazioni Q-14 e Q-15 con e senza la clausola ORDER BY. Senza la clausola ORDER BY, il tempo di completamento è di 259 ms, mentre con la clausola ORDER BY è di 1364212. Per il debug di questa interrogazione, spiego entrambe le interrogazioni e qui sono riportati i risultati dell'analisi.
Q15: Senza clausola ORDER BY
bm=# EXPLAIN VERBOSE SELECT a."Year", c1/c2
FROM (SELECT "Year", count(*)*1000 AS c1 FROM fontime WHERE "DepDelay" > 10 GROUP BY "Year") a
INNER JOIN(SELECT "Year", count(*) AS c2 FROM fontime GROUP BY "Year") b ON a."Year"=b."Year";Q15: Interrogazione senza clausola ORDER BY
PIANO DI QUERY
Hash Join (costo=2250.00..128516.06 righe=50000000 larghezza=12)
Output: fontime."Year", (((count(*) * 1000)) / b.c2)
Unico interno: vero Condizione Hash: (fontime."Year" = b."Year")
-> Scansione Estera (costo=1.00..-1.00 righe=100000 larghezza=12)
Output: fontime."Year", ((count(*) * 1000))
Relazioni: Aggregato su (fontime)
SQL Remoto: SELECT "Year", (count(*) * 1000) FROM "default".ontime WHERE (("DepDelay" > 10)) GROUP BY "Year"
-> Hash (costo=999.00..999.00 righe=100000 larghezza=12)
Output: b.c2, b."Year"
-> Scansione Subquery su b (costo=1.00..999.00 righe=100000 larghezza=12)
Output: b.c2, b."Year"
-> Scansione Estera (costo=1.00..-1.00 righe=100000 larghezza=12)
Output: fontime_1."Year", (count(*))
Relazioni: Aggregato su (fontime)
SQL Remoto: SELECT "Year", count(*) FROM "default".ontime GROUP BY "Year"(16 righe)Q14: Query Con CLAUSOLA ORDER BY
bm=# EXPLAIN VERBOSE SELECT a."Year", c1/c2 FROM(SELECT "Year", count(*)*1000 AS c1 FROM fontime WHERE "DepDelay" > 10 GROUP BY "Year") a
INNER JOIN(SELECT "Year", count(*) as c2 FROM fontime GROUP BY "Year") b ON a."Year"= b."Year"
ORDER BY a."Year";Q14: Piano di Query con CLAUSOLA ORDER BY
PIANO DI QUERY
Merge Join (costo=2.00..628498.02 righe=50000000 larghezza=12)
Output: fontime."Year", (((count(*) * 1000)) / (count(*)))
Unico Interno: vero Condizione di Merge: (fontime."Year" = fontime_1."Year")
-> GroupAggregate (costo=1.00..499.01 righe=1 larghezza=12)
Output: fontime."Year", (count(*) * 1000)
Chiave di Gruppo: fontime."Year"
-> Scan Esterno su public.fontime (costo=1.00..-1.00 righe=100000 larghezza=4)
SQL Remoto: SELECT "Year" FROM "default".ontime WHERE (("DepDelay" > 10))
ORDER BY "Year" ASC
-> GroupAggregate (costo=1.00..499.01 righe=1 larghezza=12)
Output: fontime_1."Year", count(*) Chiave di Gruppo: fontime_1."Year"
-> Scan Esterno su public.fontime fontime_1 (costo=1.00..-1.00 righe=100000 larghezza=4)
SQL Remoto: SELECT "Year" FROM "default".ontime ORDER BY "Year" ASC(16 righe)Risultato
I risultati di questi esperimenti mostrano che ClickHouse offre davvero prestazioni elevate, e clickhousedb_fdw offre i vantaggi delle prestazioni di ClickHouse da PostgreSQL. Anche se ci sono alcune spese generali nell'uso di clickhousedb_fdw, esse sono trascurabili e comparabili alle prestazioni ottenute con l'esecuzione diretta nel database ClickHouse. Questo conferma anche che fdw in PostgreSQL produce risultati straordinari.
Chat Telegram su Clickhouse
Chat Telegram su PostgreSQL
Fonte: habr.com
