


Non molto tempo fa, mi sono trovato di fronte a un compito piuttosto insolito di configurazione della routazione per MetalLB. Di solito non sono necessarie azioni aggiuntive per MetalLB, ma nel nostro caso abbiamo un cluster abbastanza grande con una configurazione di rete piuttosto semplice.
In questo articolo spiegherò come configurare il routing basato su sorgente e policy per la rete esterna del tuo cluster.
Non mi soffermerò sui dettagli dell'installazione e configurazione di MetalLB, poiché presumo tu abbia già un po' di esperienza. Passiamo subito al dunque, ovvero la configurazione della routazione. Abbiamo quindi quattro casi:
Caso 1: Quando non è necessaria la configurazione
Analizziamo un caso semplice.
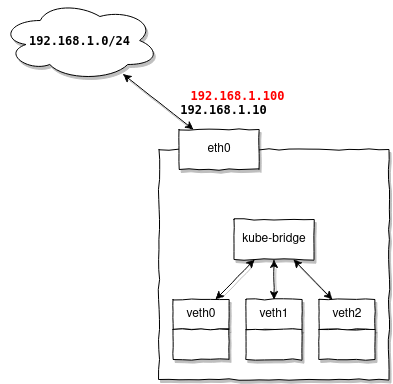
Ulteriore configurazione della routazione non è necessaria quando gli indirizzi forniti da MetalLB si trovano nella stessa subnet degli indirizzi dei tuoi nodi.
Ad esempio, hai una subnet 192.168.1.0/24, c’è un router 192.168.1.1, e i tuoi nodi ricevono indirizzi: 192.168.1.10-30, allora per MetalLB puoi configurare l'intervallo 192.168.1.100-120 e essere sicuro che funzionerà senza alcuna configurazione aggiuntiva.
Perché? Perché i tuoi nodi hanno già delle route configurate:
# ip route
default via 192.168.1.1 dev eth0 onlink
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.10E gli indirizzi dello stesso range verranno riutilizzati senza ulteriori complicazioni.
Caso 2: Quando è necessaria una configurazione aggiuntiva
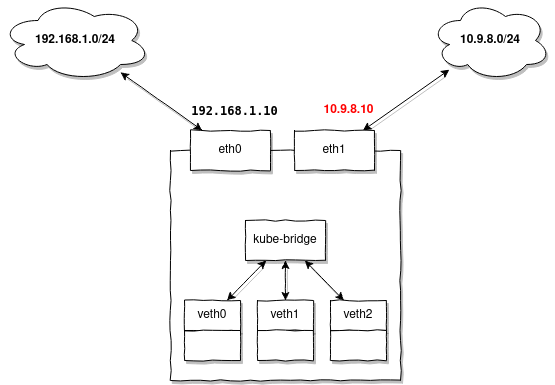
Dovresti configurare ulteriori percorsi ogni volta che le tue nodi non hanno un percorso configurato Indirizzi IP o un percorso nella subnet per la quale MetalLB assegna gli indirizzi.
Spiegherò un po' più nel dettaglio. Ogni volta che MetalLB assegna un indirizzo, questo può essere paragonato a una semplice assegnazione del tipo:
ip addr add 10.9.8.7/32 dev loNota bene:
- a) L'indirizzo viene assegnato con un prefisso
/32quindi il percorso nella subnet per esso non verrà aggiunto automaticamente (è solo un indirizzo) - b) L'indirizzo è assegnato a qualsiasi interfaccia del nodo (ad esempio, loopback). Qui vale la pena menzionare una peculiarità dello stack di rete Linux. Non importa a quale interfaccia aggiungi l'indirizzo, il kernel gestirà sempre le richieste ARP e invierà risposte ARP su qualsiasi di esse, questo comportamento è considerato corretto e, inoltre, è abbastanza ampiamente utilizzato in un ambiente dinamico come Kubernetes.
Questo comportamento può essere configurato, ad esempio, abilitando strict arp:
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announceIn questo caso, le risposte ARP verranno inviate solo se l'interfaccia contiene esplicitamente un indirizzo IP specifico. Questa impostazione è obbligatoria se si prevede di utilizzare MetalLB e se il proprio kube-proxy è in modalità IPVS.
Tuttavia, MetalLB non utilizza il kernel per gestire le richieste ARP, ma lo fa autonomamente in user-space; pertanto, questa opzione non influenzerà il funzionamento di MetalLB.
Torniamo al nostro compito. Se non esiste una route per gli indirizzi assegnati sui tuoi nodi, aggiungila in anticipo a tutti i nodi:
ip route add 10.9.8.0/24 dev eth1Caso 3: Quando è necessario il routing basato sulla sorgente
Il routing basato sulla sorgente sarà necessario configurarlo quando si ricevono pacchetti tramite un gateway separato, diverso da quello impostato per default; quindi, i pacchetti di risposta devono anche uscire tramite lo stesso gateway.
Ad esempio, hai ancora la stessa sottorete 192.168.1.0/24 dedicata ai tuoi nodi, ma desideri emettere indirizzi esterni utilizzando MetalLB. Supponiamo che tu abbia diversi indirizzi della sottorete 1.2.3.0/24 che si trovano nella VLAN 100, e desideri utilizzarli per accedere ai servizi Kubernetes dall'esterno.
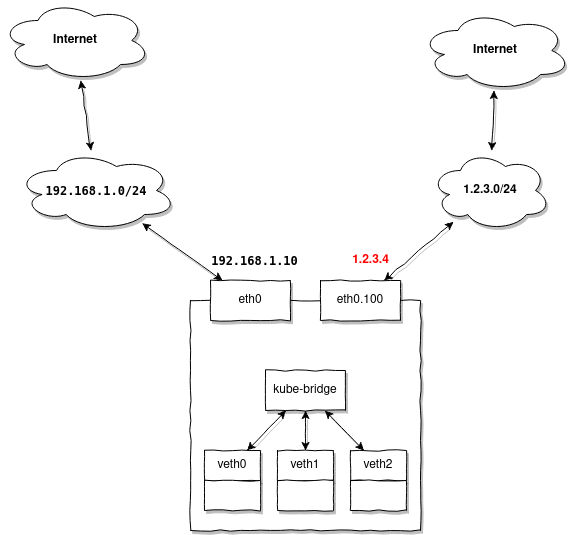
Quando ti colleghi a 1.2.3.4 effettuerai richieste da un'altra sottorete rispetto a 1.2.3.0/24 e attendere una risposta. Il nodo attualmente designato come master per l'indirizzo MetalLB assegnato 1.2.3.4, riceverà un pacchetto dal router 1.2.3.1, ma la risposta deve obbligatoriamente seguire lo stesso percorso, attraverso 1.2.3.1.
Poiché il nostro nodo ha già un gateway predefinito configurato 192.168.1.1, la risposta andrà per impostazione predefinita a lui, e non a 1.2.3.1, attraverso il quale abbiamo ricevuto il pacchetto.
Come affrontare questa situazione?
In questo caso, è necessario preparare tutti i vostri nodi in modo che siano pronti a gestire indirizzi esterni senza configurazioni aggiuntive. Cioè, per l'esempio sopra, dovete creare in anticipo un'interfaccia VLAN sul nodo:
ip link add link eth0 name eth0.100 type vlan id 100
ip link set eth0.100 upE poi aggiungere le rotte:
ip route add 1.2.3.0/24 dev eth0.100 table 100
ip route add default via 1.2.3.1 table 100Si noti che le rotte vengono aggiunte in una tabella di routing separata 100 che conterrà solo due rotte necessarie per inviare il pacchetto di risposta attraverso il gateway 1.2.3.1, situato dietro l'interfaccia eth0.100.
Ora dobbiamo aggiungere una semplice regola:
ip rule add from 1.2.3.0/24 lookup 100che dice esplicitamente: se l'indirizzo di origine del pacchetto si trova in 1.2.3.0/24, bisogna utilizzare la tabella di routing 100. All'interno abbiamo già descritto un percorso che lo invierà attraverso 1.2.3.1
Caso 4: Quando sarà necessario il routing basato su policy
Topologia della rete come nell'esempio precedente, ma supponiamo che tu voglia anche avere la possibilità di accedere a indirizzi esterni del pool 1.2.3.0/24 dai tuoi pod:
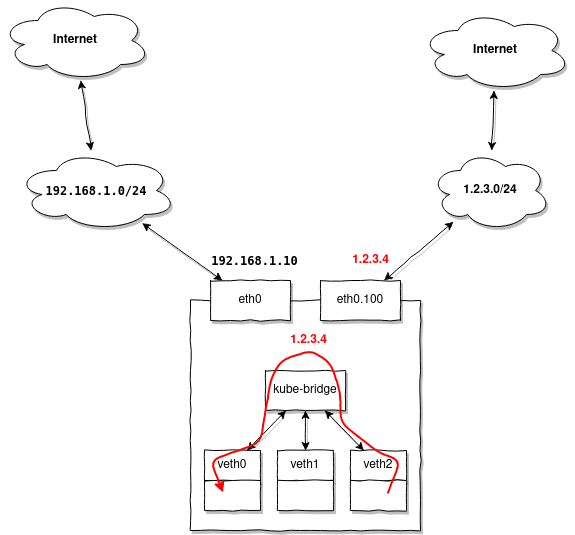
La particolarità è che quando si accede a qualsiasi indirizzo in 1.2.3.0/24, il pacchetto di risposta, arrivando su un nodo e avendo un indirizzo sorgente nell'intervallo 1.2.3.0/24 verrà obbedientemente inviato a eth0.100, ma noi vogliamo che Kubernetes lo reindirizzi al nostro primo pod, che ha generato la richiesta iniziale.
Risolgere questo problema si è rivelato non facile, ma è stato reso possibile grazie al routing basato su policy:
Per una maggiore comprensione del processo, presenterò uno schema a blocchi di netfilter:
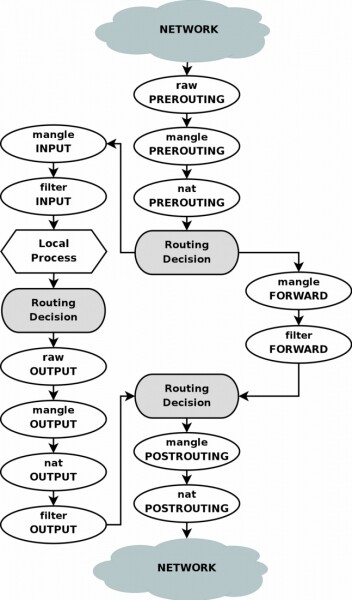
Per prima cosa, come nell'esempio precedente, creeremo una tabella di routing aggiuntiva:
ip route add 1.2.3.0/24 dev eth0.100 table 100
ip route add default via 1.2.3.1 table 100Ora aggiungiamo alcune regole in iptables:
iptables -t mangle -A PREROUTING -i eth0.100 -j CONNMARK --set-mark 0x100
iptables -t mangle -A PREROUTING -j CONNMARK --restore-mark
iptables -t mangle -A PREROUTING -m mark ! --mark 0 -j RETURN
iptables -t mangle -A POSTROUTING -j CONNMARK --save-markQueste regole contrassegneranno le connessioni in ingresso sull'interfaccia eth0.100, contrassegnando tutti i pacchetti con il tag 0x100, lo stesso tag sarà utilizzato anche per le risposte all'interno di una singola connessione.
Ora possiamo aggiungere una regola di routing:
ip rule add from 1.2.3.0/24 fwmark 0x100 lookup 100Cioè, tutti i pacchetti con indirizzo sorgente 1.2.3.0/24 e il tag 0x100 devono essere instradati utilizzando la tabella 100.
In questo modo, altri pacchetti ricevuti su un'altra interfaccia non rientrano in questa regola, permettendo così di essere instradati con i normali mezzi di Kubernetes.
C'è però un altro aspetto: in Linux esiste quello che si chiama filtro di percorso inverso, che rovina tutto e svolge un semplice controllo: per tutti i pacchetti in entrata cambia l'indirizzo sorgente del pacchetto con l'indirizzo del mittente e verifica se il pacchetto possa uscire tramite lo stesso interfaccia sulla quale è stato ricevuto; se no, lo filtra.
Il problema è che nel nostro caso non funzionerà correttamente, ma possiamo disabilitarlo:
echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter
echo 0 > /proc/sys/net/ipv4/conf/eth0.100/rp_filterNota che il primo comando controlla il comportamento globale di rp_filter; se non viene disabilitato, il secondo comando non avrà alcun effetto. Tuttavia, le altre interfacce rimarranno con rp_filter attivato.
Per non limitare completamente il funzionamento del filtro, possiamo utilizzare l'implementazione di rp_filter per netfilter. Usando rpfilter come modulo iptables, è possibile configurare regole abbastanza flessibili, ad esempio:
iptables -t raw -A PREROUTING -i eth0.100 -d 1.2.3.0/24 -j RETURN
iptables -t raw -A PREROUTING -i eth0.100 -m rpfilter --invert -j DROPattivare rp_filter sull'interfaccia eth0.100 per tutti gli indirizzi tranne 1.2.3.0/24.
Fonte: habr.com
