


A tutti un saluto!
Mi chiamo Nikita, sono il team leader del gruppo ingegneri di Cian. Una delle mie responsabilità in azienda è ridurre a zero il numero di incidenti legati all'infrastruttura in produzione.
Quello di cui parleremo è stato fonte di molti problemi per noi, e l'obiettivo di questo articolo è evitare che altre persone ripetano i nostri errori o almeno minimizzare il loro impatto.
Premessa
Molto tempo fa, quando Cian era costituito da monoliti e non c'erano ancora tracce di microservizi, misuravamo la disponibilità delle risorse controllando 3–5 pagine.
Se rispondevano — tutto bene, se non rispondevano per molto tempo — allerta. Quanto tempo devono rimanere non funzionanti affinché venga considerato un incidente, lo decidevano le persone nelle riunioni. Il team di ingegneri era sempre coinvolto nell'indagine sugli incidenti. Una volta conclusa l'indagine, veniva redatto un post-mortem — una sorta di rapporto inviato via email nel formato: cosa è successo, quanto è durato, cosa abbiamo fatto nel momento, cosa faremo in futuro.
Le pagine principali del sito o come capiamo di aver toccato il fondo
Per comprendere le priorità degli errori, abbiamo evidenziato le pagine più critiche per il funzionamento aziendale del sito. Su di esse calcoliamo il numero di richieste riuscite/ non riuscite e i timeout. In questo modo misuriamo l'uptime.
Supponiamo di aver identificato una serie di sezioni super importanti del sito, responsabili del servizio principale — ricerca e invio di annunci. Se il numero di richieste che si è concluso con un errore supera l'1% — è un incidente critico. Se durante le ore di punta, il tasso di errori supera lo 0,1% per 15 minuti — anche questo è considerato un incidente critico. Questi criteri coprono la maggior parte degli incidenti, mentre gli altri esulano da questo articolo.
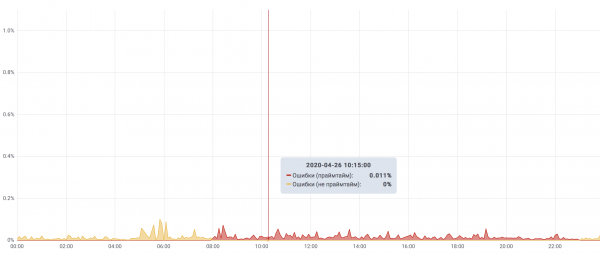
Top dei migliori incidenti di Cian
Quindi, abbiamo chiaramente imparato a determinare il verificarsi di un incidente.
Ora ogni incidente è descritto in dettaglio e registrato nell'epico di Jira. A proposito: abbiamo creato un progetto separato, lo abbiamo chiamato FAIL — in esso è possibile creare solo epic.
Se raccolgo tutti i fallimenti degli ultimi anni, i più frequenti sono:
- incidenti legati a mssql;
- incidenti causati da fattori esterni;
- errori dell'amministratore.
Analizziamo più nel dettaglio gli errori degli amministratori e alcuni altri fallimenti interessanti.
Quinto posto — "Mettiamo in ordine il DNS"
Era un martedì piovoso. Abbiamo deciso di mettere in ordine il nostro cluster DNS.
Abbiamo voluto migrare i server DNS interni da bind a powerdns, dedicando a questo server completamente separati, nei quali non c'era nient'altro che DNS.
Abbiamo collocato un server DNS in ciascuna delle nostre sedi, e arrivò il momento di trasferire le zone da bind a powerdns e di commutare l'infrastruttura sui nuovi server.
Nel bel mezzo della migrazione, di tutti server, che erano stati indicati nei bind locali in tutte le server, ne rimase solo uno, situato nel data center di San Pietroburgo. Questo data center era stato inizialmente dichiarato non critico per noi, ma improvvisamente divenne un singolo punto di failure.
Proprio in quel periodo di migrazione, cadde il collegamento tra Mosca e San Pietroburgo. Siamo rimasti praticamente senza DNS per cinque minuti, e siamo riemersi quando l'host sono stati risolti i problemi.
Conclusioni:
Se in passato trascuravamo i fattori esterni durante i preparativi per il lavoro, ora li abbiamo inclusi nella lista di ciò a cui ci stiamo preparando. E ora ci sforziamo affinché tutti i componenti siano riservati a n-2, e durante i lavori possiamo abbassare questo livello a n-1.
- Durante la stesura del piano d'azione, segnate i punti in cui il servizio potrebbe essere interrotto e pensate a uno scenario in cui tutto vada "peggio possibile" in anticipo.
- Distribuite i server DNS interni su diverse geolocalizzazioni/data center/rack/switch/ingressi.
- Su ogni server installate un server DNS cache locale che reindirizza le richieste ai server DNS principali e, in caso di inattività, risponderà dal cache.
Il quarto posto è "Rimettere in ordine Nginx"
Un bel giorno, il nostro team ha deciso che era ora di dire "basta" e ha avviato il processo di rifattorizzazione delle configurazioni di nginx. L'obiettivo principale era rendere le configurazioni facilmente comprensibili. In passato, tutto era "storicamente consolidato" e privo di logica. Ora, ogni server_name è stato spostato in un file con lo stesso nome e tutte le configurazioni sono state suddivise in cartelle. Per inciso, la configurazione contiene 253949 righe o 7836520 caratteri e occupa quasi 7 megabyte. Livello superiore della struttura:
Struttura di Nginx
├── access
│ ├── allow.list
...
│ └── whitelist.conf
├── geobase
│ ├── exclude.conf
...
│ └── geo_ip_to_region_id.conf
├── geodb
│ ├── GeoIP.dat
│ ├── GeoIP2-Country.mmdb
│ └── GeoLiteCity.dat
├── inc
│ ├── error.inc
...
│ └── proxy.inc
├── lists.d
│ ├── bot.conf
...
│ ├── dynamic
│ └── geo.conf
├── lua
│ ├── cookie.lua
│ ├── log
│ │ └── log.lua
│ ├── logics
│ │ ├── include.lua
│ │ ├── ...
│ │ └── utils.lua
│ └── prom
│ ├── stats.lua
│ └── stats_prometheus.lua
├── map.d
│ ├── access.conf
│ ├── ..
│ └── zones.conf
├── nginx.conf
├── robots.txt
├── server.d
│ ├── cian.ru
│ │ ├── cian.ru.conf
│ │ ├── ...
│ │ └── my.cian.ru.conf
├── service.d
│ ├── ...
│ └── status.conf
└── upstream.d
├── cian-mcs.conf
├── ...
└── wafserver.confÈ migliorato notevolmente, ma durante la rinominazione e la distribuzione delle configurazioni, alcune di esse avevano estensioni errate e non sono state incluse nella direttiva include *.conf. Di conseguenza, alcune host sono diventate inaccessibili e restituivano un 301 alla homepage. Poiché il codice di risposta non era 5xx/4xx, non ce ne siamo accorti subito, ma solo al mattino. Dopo di che abbiamo iniziato a scrivere test per controllare i componenti dell'infrastruttura.
Conclusioni:
- Struttura correttamente le configurazioni (non solo nginx) e pianifica la struttura fin dalle prime fasi del progetto. In questo modo le renderai più comprensibili per il team, il che a sua volta ridurrà il TTM.
- Per alcuni componenti dell'infrastruttura, scrivi dei test. Ad esempio: verifica che tutti i server_name chiave restituiscano lo stato corretto, + il corpo della risposta. È sufficiente avere a disposizione solo alcuni script che controllano le funzioni principali del componente, così da non dover ricordare in fretta a notte fonda cosa occorre verificare.
Terzo posto — «All'improvviso spazio esaurito in Cassandra»
I dati sono cresciuti gradualmente, e tutto andava bene fino a quando nel cluster di Cassandra hanno iniziato a fallire i repair di grandi keyspace, perché non può essere gestito il compaction.
In un giorno tempestoso, il cluster è quasi diventato una zucca, vale a dire:
- rimaneva circa il 20% di spazio totale nel cluster;
- non è possibile aggiungere nodi completamente, poiché non passa il cleanup dopo l'aggiunta di un nodo a causa della mancanza di spazio nelle partizioni;
- le prestazioni stanno lentamente diminuendo, poiché il compaction non è attivo;
- il cluster opera in modalità di emergenza.
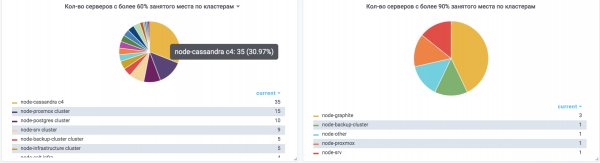
Uscita — sono state aggiunte altre 5 nodi senza cleanup, dopodiché si è iniziato a estrarre metodicamente dal cluster e reinserirli come nodi vuoti, nei quali non c'era più spazio. Il tempo speso è stato significativamente maggiore di quanto desiderato. C'era il rischio di parziale o totale indisponibilità del cluster.
Conclusioni:
- Su tutti i server Cassandra, non deve essere occupato più del 60% dello spazio su ciascuna partizione.
- Devono essere caricati a non più del 50% della CPU.
- Non bisogna trascurare il capacity planning e deve essere pianificato per ciascun componente, in base alla sua specificità.
- Più nodi ci sono nel cluster, meglio è. I server che contengono un piccolo volume di dati si ripristinano più rapidamente, e un cluster di questo tipo è più facile da riattivare.
Seconda posizione — «I dati sono scomparsi dallo storage consul key-value»
Per il service discovery, come molti, utilizziamo Consul. Tuttavia, il suo key-value è utilizzato anche per il deploy blue-green del monolite. Qui si trova l'informazione sugli upstream attivi e inattivi, che si alternano durante il deploy. A questo scopo, è stato scritto un servizio di deploy che interagiva con KV. A un certo punto, i dati da KV sono scomparsi. Abbiamo recuperato memorizzandoli, ma con alcuni errori. Di conseguenza, durante il deploy, il carico sugli upstream è stato distribuito in modo non uniforme e abbiamo ricevuto molti errori 502 a causa del sovraccarico dei backend per CPU. In definitiva, siamo passati da Consul KV a Postgres, da cui eliminarli non è così semplice.
Conclusioni:
- I servizi senza alcuna autorizzazione non dovrebbero contenere dati critici per il funzionamento del sito. Ad esempio, se non hai l'autorizzazione in ES, sarebbe meglio vietare l'accesso a livello di rete ovunque non sia necessario, mantenendo solo le connessioni necessarie e impostando anche action.destructive_requires_name: true.
- Sviluppa il meccanismo di backup e ripristino in anticipo. Ad esempio, crea un script (per esempio, in Python) che sia in grado di effettuare sia il backup che il ripristino.
Primo posto — 'Capitano ovvietà'
A un certo punto, abbiamo notato una distribuzione irregolare del carico sugli upstream di Nginx quando nel backend c'erano più di 10 server. Poiché il round-robin indirizzava le richieste dall'uno all'ultimo upstream in ordine, e ogni riavvio di Nginx iniziava da capo, i primi upstream ricevevano sempre più richieste rispetto agli altri. Di conseguenza, lavoravano più lentamente e l'intero sito ne soffriva. Questo diventava sempre più evidente con l'aumentare del traffico. Aggiornare semplicemente Nginx per abilitare random non è bastato; è stato necessario riscrivere un sacco di codice Lua che non funzionava con la versione 1.15 (all'epoca). Abbiamo dovuto patchare il nostro Nginx 1.14.2 per implementare il supporto random. Questo ha risolto il problema. Questo bug merita il premio per 'capitano dell'ovvietà'.
Conclusioni:
È stato molto interessante e coinvolgente esplorare questo bug).
- Impostate il monitoraggio in modo che aiuti a rilevare rapidamente tali fluttuazioni. Ad esempio, potete usare ELK per monitorare le rps su ogni backend di ogni upstream, osservando i tempi di risposta dal punto di vista di Nginx. In questo caso, ci ha aiutato a identificare il problema.
La maggior parte degli errori potrebbe essere evitata con un approccio più scrupoloso a ciò che si fa. È sempre bene ricordare la legge di Murphy: Qualsiasi cosa possa andare storta andrà storta, e progettare i componenti di conseguenza.
Fonte: habr.com
