


Nei nostri progetti utilizziamo un'architettura a microservizi. Quando si verificano colli di bottiglia nelle prestazioni, spesso si perde molto tempo nel monitoraggio e nell'analisi dei log. Registrare i tempi delle singole operazioni in un file di log rende difficile comprendere cosa abbia portato alla chiamata di queste operazioni, seguire la sequenza di azioni o il ritardo temporale di un'operazione rispetto a un'altra tra diversi servizi.
Per ridurre il lavoro manuale, abbiamo deciso di utilizzare uno degli strumenti di tracciamento. In questo articolo parleremo di come e perché utilizzare il tracciamento e di come lo abbiamo fatto noi.
Quali problemi possono essere risolti con il tracciamento
- Identificare i colli di bottiglia nelle prestazioni sia all'interno di un singolo servizio che nell'intero albero di esecuzione tra tutti i servizi coinvolti. Per esempio:
- Molte chiamate brevi e consecutive tra servizi, come nel caso della geocodifica o del database.
- Attese lunghe per input/output, come il trasferimento di dati tramite rete o la lettura da disco.
- Lunga elaborazione dei dati.
- Operazioni lunghe che richiedono CPU.
- Codici che non sono necessari per ottenere il risultato finale e possono essere rimossi o eseguiti in modo posticipato.
- Comprendere visivamente in quale sequenza vengono chiamati i processi e cosa accade quando viene eseguita un'operazione.

Si vede che, ad esempio, la Richiesta è arrivata al servizio WS -> il servizio WS ha completato i dati tramite il servizio R -> poi ha inviato la richiesta al servizio V -> il servizio V ha caricato molti dati dal servizio R -> ha interagito con il servizio P -> il servizio P ha consultato nuovamente il servizio R -> il servizio V ha ignorato il risultato e si è recato al servizio J -> e solo dopo ha restituito una risposta al servizio WS, continuando nel frattempo a calcolare qualcos'altro in background.
Senza questa traccia o una documentazione dettagliata su tutto il processo, è molto difficile comprendere cosa sta succedendo, soprattutto al primo sguardo sul codice, oltretutto il codice è disperso tra diversi servizi e nascosto dietro una miriade di bean e interfacce. - Raccolta di informazioni sull'albero di esecuzione per un'analisi posticipata. A ogni fase di esecuzione, si possono aggiungere informazioni alla traccia che sono disponibili in quella fase, per poi capire quali dati di input hanno portato a tale scenario. Ad esempio:
- ID utente
- Permessi
- Tipo di metodo selezionato
- Log o erro di esecuzione
- Conversione delle tracce in un sottoinsieme di metriche e analisi successiva già in forma di metriche.
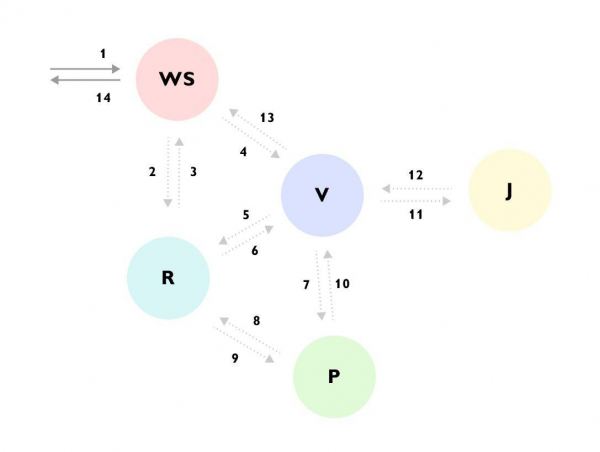
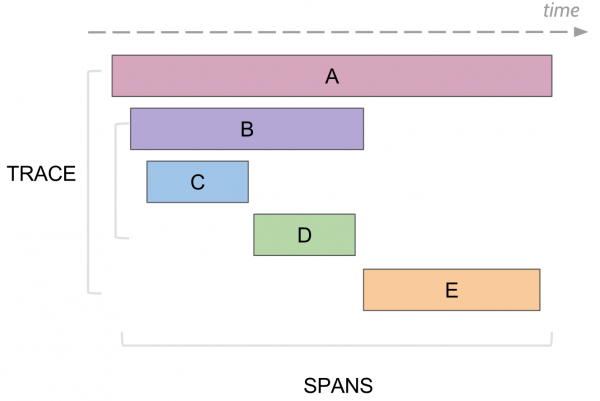
Cosa è in grado di registrare la tracciatura. Span
Nella tracciatura esiste il concetto di span, che è l'equivalente di un log, nella console. Uno span ha:
- Un nome, solitamente il nome del metodo che è stato eseguito
- Il nome del servizio in cui è stato generato lo span
- Un ID unico proprio
- Qualche metainformazione sotto forma di chiave/valore, che è stata registrata in esso. Ad esempio, i parametri del metodo o se il metodo è terminato con un errore o meno
- Il tempo di inizio e fine dell'esecuzione di questo span
- ID dello span genitore
Ogni span viene inviato a un collector di span per essere salvato nel database per una visualizzazione successiva, non appena ha completato la sua esecuzione. In seguito, è possibile costruire un albero di tutti gli span collegandoli tramite ID del genitore. Durante l'analisi, è possibile trovare, ad esempio, tutti gli span in un certo servizio che hanno impiegato più di un certo tempo. Inoltre, passando a uno specifico span, si possono vedere tutti gli alberi sopra e sotto questo span.
Opentrace, Jagger e come abbiamo realizzato questo per i nostri progetti
C'è uno standard comune , che descrive come e cosa dovrebbe essere raccolto, senza legarsi a tracce specifiche in alcun linguaggio. Ad esempio, in Java, tutto il lavoro con le tracce avviene attraverso un'API comune di Opentrace, sotto la quale può nascondersi, ad esempio, Jaeger o una semplice implementazione predefinita che non fa nulla.
Noi utilizziamo come implementazione di Opentrace. È composto da diversi componenti:
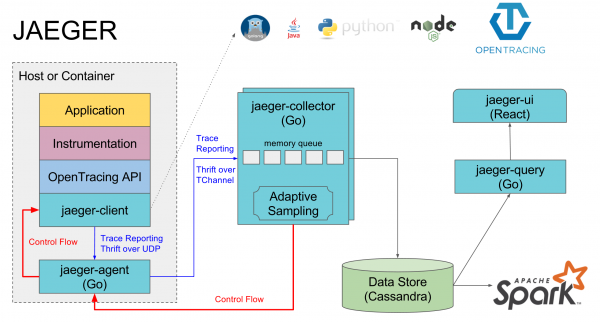
- Jaeger-agent — un agente locale, che di solito si trova su ogni macchina e nel quale i servizi registrano sul porto predefinito locale. Se l'agente non è presente, le tracce di tutti i servizi su questa macchina sono generalmente disattivate.
- Jaeger-collector — riceve tutte le tracce raccolte dai vari agenti e le inserisce nel database scelto.
- Database — preferibilmente cassandra, ma noi utilizziamo elasticsearch; ci sono implementazioni anche per un paio di altri database e un'implementazione in memoria che non salva nulla su disco.
- Jaeger-query — è un servizio che interroga il database e restituisce le tracce raccolte per l'analisi.
- Jaeger-ui — è un'interfaccia web per la ricerca e la visualizzazione delle tracce, che interroga jaeger-query.
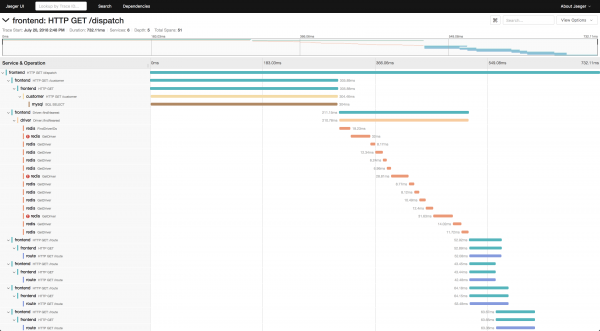
Un componente distintivo è l'implementazione di opentrace jaeger per linguaggi specifici, attraverso la quale gli span vengono inviati a jaeger-agent.
consiste nell'implementare l'interfaccia io.opentracing.Tracer, dopo di che tutti i tracciamenti passeranno attraverso di essa al vero agente.
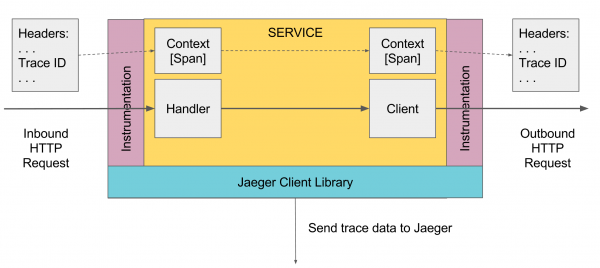
Inoltre, per i componenti di Spring, è possibile collegare e l'implementazione di Jaeger che configurerà automaticamente la tracciatura per tutto ciò che passa attraverso questi componenti, come le richieste http nei controller, le richieste al database tramite jdbc, e così via.
Registrazione dei tracciamenti in Java
A un certo livello superiore deve essere creato il primo Span, questo può essere fatto automaticamente, ad esempio dal controller di Spring al ricevimento della richiesta, oppure manualmente se non esiste. Successivamente, viene passato attraverso il Scope sottostante. Se un metodo più in basso desidera aggiungere uno Span, prende l'attuale activeSpan dal Scope, crea un nuovo Span e indica che il suo genitore è l'activeSpan ricevuto, rendendo il nuovo Span attivo. Quando vengono chiamati servizi esterni, viene passato l'attuale Span attivo, e quei servizi creano nuovi span legati a questo span.
Tutta l'attività avviene tramite un'istanza di Tracer, che può essere ottenuta attraverso il meccanismo DI o usando GlobalTracer.get() come variabile globale, nel caso in cui il meccanismo DI non funzioni. Per impostazione predefinita, se il tracer non è stato inizializzato, verrà restituito NoopTracer, che non fa nulla.
Successivamente, dal tracer si estrae l'attuale scope tramite ScopeManager, si crea un nuovo scope dall'attuale associato a un nuovo span, e successivamente si chiude lo Scope creato, il quale chiude lo span creato e restituisce il precedente Scope allo stato attivo. Lo Scope è legato al thread, quindi nella programmazione multithread è importante ricordare di passare lo span attivo a un altro thread per attivare lo Scope di quest'ultimo con il collegamento a questo span.
io.opentracing.Tracer tracer = ...; // GlobalTracer.get()
void DoSmth () {
try (Scope scope = tracer.buildSpan("DoSmth").startActive(true)) {
...
}
}
void DoOther () {
Span span = tracer.buildSpan("someWork").start();
try (Scope scope = tracer.scopeManager().activate(span, false)) {
// Fai qualcosa.
} catch(Exception ex) {
Tags.ERROR.set(span, true);
span.log(Map.of(Fields.EVENT, "errore", Fields.ERROR_OBJECT, ex, Fields.MESSAGE, ex.getMessage()));
} finally {
span.finish();
}
}
void DoAsync () {
try (Scope scope = tracer.buildSpan("ServiceHandlerSpan").startActive(false)) {
...
final Span span = scope.span();
doAsyncWork(() -> {
// PASSO 2 SOPRA: riattivare lo Span nel callback, passando true a
// startActive() se/quando lo Span deve essere completato.
try (Scope scope = tracer.scopeManager().activate(span, false)) {
...
}
});
}
}Per la programmazione multithread c'è anche TracedExecutorService e wrapper analoghi che propagano automaticamente lo span corrente nel thread al momento dell'esecuzione di task asincroni:
private ExecutorService executor = new TracedExecutorService(
Executors.newFixedThreadPool(10), GlobalTracer.get()
);Per le richieste http esterne c'è
HttpClient httpClient = new TracingHttpClientBuilder().build();Problemi che abbiamo riscontrato
- I bean e DI non funzionano sempre se il tracer non è usato in un servizio o componente, quindi Il Tracer potrebbe non funzionare e sarà necessario utilizzare GlobalTracer.get().
- Le annotazioni non funzionano se non si tratta di un componente o di un servizio, o se la chiamata al metodo avviene da un metodo adiacente della stessa classe. È necessario fare attenzione, controllare ciò che funziona e utilizzare la creazione manuale del tracciamento se @Traced non funziona. Inoltre, è possibile aggiungere un compilatore aggiuntivo per le annotazioni Java, in modo che funzionino ovunque.
- Nelle versioni precedenti di Spring e Spring Boot, l'autoconfigurazione di OpenTracing Spring Cloud non funziona a causa di errori nell'iniezione delle dipendenze. Se si desidera che i tracciamenti funzionino automaticamente nei componenti di Spring, si può fare analogamente a
- In Groovy non funziona il try with resources, è necessario utilizzare sempre il try finally.
- Ogni servizio deve specificare il proprio spring.application.name sotto il quale verranno registrati i tracciamenti. Inoltre, è necessario un nome separato per produzione e test, per non mescolarli.
- Se si utilizza GlobalTracer e Tomcat, tutti i servizi avviati in questo Tomcat hanno un GlobalTracer unico, quindi avranno tutti lo stesso nome di servizio.
- Quando si aggiungono i trace nel metodo, è importante assicurarsi che non venga chiamato più volte in un ciclo. Bisogna aggiungere un unico trace per tutte le chiamate, che registrerà il tempo totale di esecuzione. Altrimenti, si creerà un carico eccessivo.
- Una volta in jaeger-ui abbiamo fatto richieste troppo grandi per un numero elevato di trace e, poiché non aspettavamo la risposta, ne abbiamo fatte altre. Di conseguenza, jaeger-query ha iniziato a consumare molta memoria e ha rallentato Elastic. Un riavvio di jaeger-query ha risolto il problema.
Campionamento, archiviazione e visualizzazione dei trace.
Ci sono tre tipi. :
- Const che invia e salva tutti i trace.
- Probabilistico che filtra i trace con una certa probabilità prestabilita.
- Ratelimiting che limita il numero di trace al secondo. Questi parametri possono essere configurati sul client, sul jaeger-agent o nel collector. Attualmente nel nostro stack di validator utilizziamo const 1 poiché le richieste non sono molte ma richiedono tempo. In futuro, se questo comporterà un carico eccessivo sul sistema, sarà possibile limitarlo.
Se si utilizza Cassandra, per impostazione predefinita memorizza i trace solo per due giorni. Utilizziamo e i trace vengono conservati nel tempo e non vengono eliminati. Viene creato un indice separato per ogni giorno, ad esempio jaeger-service-2019-03-04. In seguito, è necessario configurare la pulizia automatica dei vecchi trace.
Per visualizzare i trace, è necessario:
- Selezionare il servizio per cui si desidera filtrare i trace, ad esempio tomcat7-default per il servizio in esecuzione su Tomcat, che non può avere un nome proprio.
- Successivamente, selezionare l'operazione, l'intervallo di tempo e la durata minima dell'operazione, ad esempio da 10 secondi, per considerare solo le esecuzioni lunghe.

- Accedere a uno dei trace e verificare cosa ha causato il rallentamento.

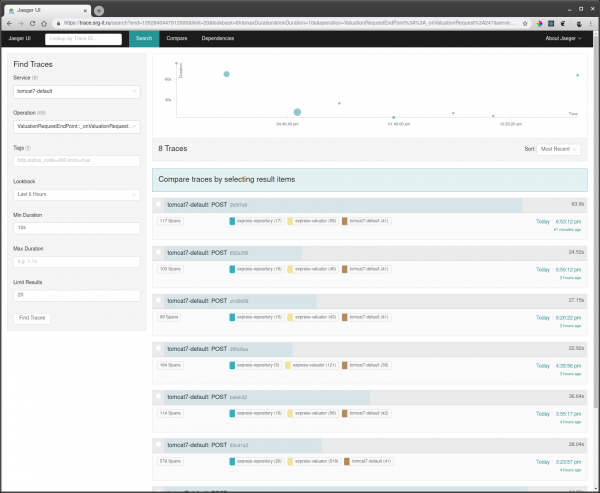
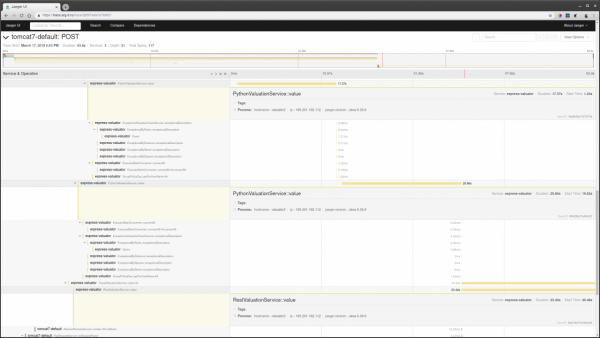
Inoltre, se si conosce un qualche id di richiesta, è possibile trovare il trace tramite questo id cercando tra i tag, se questo id viene registrato nel span del trace.
Documentazione
- Documentazione opentracing
- Documentazione jaeger
- Integrazione jaeger java
- Integrazione spring opentracing
Articoli
- Jaeger Opentracing e Microservizi in un progetto reale su PHP e Golang
- Evolving Distributed Tracing at Uber Engineering
- Esecuzione dell'agente Jaeger su bare metal
Video
- Come abbiamo utilizzato Jaeger e Prometheus per fornire query utente fulmineamente veloci — Bryan Boreham
- Introduzione: Jaeger — Yuri Shkuro, Uber & Pavol Loffay, Red Hat
- Serghei Iakovlev, “Una piccola storia di una grande vittoria: OpenTracing, AWS e Jaeger”
Fonte: habr.com
