

Ciao, Habr!
Alla luce degli eventi attuali legati al coronavirus, diversi servizi online hanno registrato un aumento del carico. Ad esempio, , poiché non disponeva di risorse sufficienti. E non sempre è possibile aumentare la capacità di un server semplicemente investendo in hardware più potente, ma è necessario gestire le richieste dei clienti (altrimenti andranno dai concorrenti).
In questo articolo parlerò brevemente delle pratiche popolari che possono consentire di creare un servizio rapido e resiliente. Tuttavia, tra gli approcci di sviluppo, ho selezionato solo quelli che ora sono facilmente accessibili. Per ciascun punto, avete già a disposizione librerie pronte oppure avete la possibilità di risolvere il problema utilizzando una piattaforma cloud.
Scalabilità orizzontale
Il punto più semplice e noto. In linea di massima, esistono due schemi di distribuzione del carico: la scalabilità orizzontale e quella verticale. si consente ai servizi di lavorare in parallelo, distribuendo così il carico tra di essi. si ordinano server più potenti o si ottimizza il codice.
Per esempio, prenderò un'astrazione di un cloud storage per file, simile a OwnCloud, OneDrive e così via.
L'immagine standard di uno schema simile è qui sotto, ma essa dimostra solo la complessità del sistema. Dobbiamo trovare un modo per sincronizzare i servizi. Cosa succede se un utente salva un file dal tablet e poi vuole visualizzarlo sul telefono?
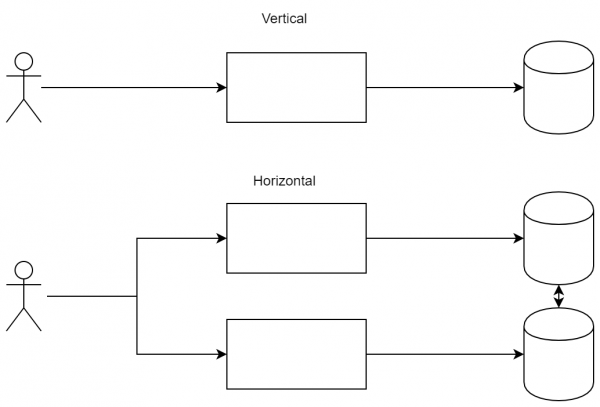
La differenza tra gli approcci: nel ridimensionamento verticale siamo pronti ad aumentare la potenza dei nodi, mentre in quello orizzontale aggiungiamo nuovi nodi per distribuire il carico.
CQRS
è un pattern piuttosto importante, poiché permette a diversi clienti di connettersi a vari servizi e di ricevere flussi di eventi identici. I suoi vantaggi non sono così evidenti per un'applicazione semplice, ma sono fondamentali (e semplici) per un servizio ad alto carico. La sua essenza è che i flussi di dati in entrata e in uscita non devono sovrapporsi. In altre parole, non puoi inviare una richiesta e aspettarti una risposta; invece, invii una richiesta al servizio A e ricevi una risposta nel servizio B.
Il primo vantaggio di questo approccio è la possibilità di interruzione della connessione (in senso ampio) durante l'esecuzione di una richiesta lunga. Prendiamo come esempio una sequenza più o meno standard:
- Il cliente ha inviato una richiesta al server.
- Il server ha avviato un'elaborazione lunga.
- Il server ha risposto al cliente con il risultato.
Immaginiamo che al punto 2 si sia verificata un'interruzione della connessione (o la rete ha riavviato la connessione, o l'utente è passato a un'altra pagina, interrompendo la connessione). In questo caso, sarà difficile per il server inviare una risposta all'utente con le informazioni su cosa sia stato elaborato. Applicando CQRS, la sequenza sarà un po' diversa:
- Il cliente si è iscritto agli aggiornamenti.
- Il cliente ha inviato una richiesta al server.
- Il server ha risposto "richiesta ricevuta".
- Il server ha risposto con il risultato attraverso il canale del "1".
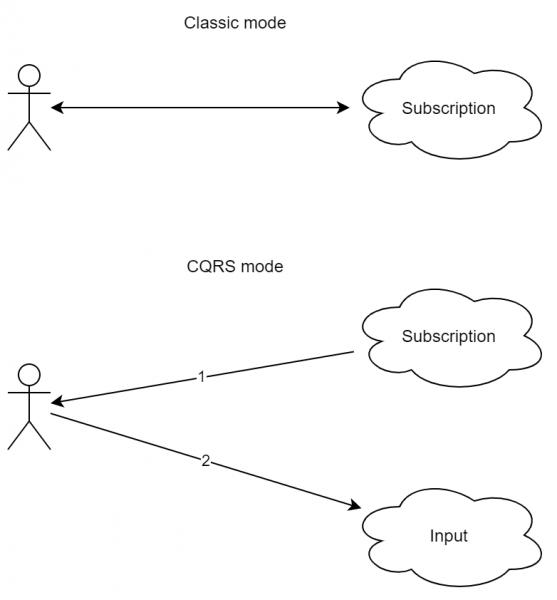
Come si può vedere, lo schema è leggermente più complesso. Inoltre, l'approccio intuitivo request-response qui è assente. Tuttavia, come si può notare, l'interruzione della connessione durante l'elaborazione della richiesta non porterà a un errore. Inoltre, se l'utente è realmente connesso al servizio da più dispositivi (ad esempio, da un telefono cellulare e da un tablet), è possibile fare in modo che la risposta arrivi a entrambi i dispositivi.
È interessante notare che il codice per gestire i messaggi in arrivo diventa simile (non al 100%) sia per gli eventi influenzati dal cliente stesso, sia per gli altri eventi, inclusi quelli provenienti da altri clienti.
Tuttavia, nella realtà, otteniamo ulteriori vantaggi poiché il flusso unidirezionale può essere gestito in uno stile funzionale (utilizzando RX e analoghi). Questo è un vantaggio significativo, poiché in sostanza l'applicazione può essere realizzata in modo completamente reattivo, utilizzando anche un approccio funzionale. Per le applicazioni più complesse, questo può ridurre notevolmente le risorse necessarie per lo sviluppo e la manutenzione.
Se si combina questo approccio con la scalabilità orizzontale, otteniamo anche la possibilità di inviare richieste a un server e ricevere risposte da un altro. In questo modo, il cliente può scegliere il servizio più conveniente per lui, mentre il sistema interno riesce comunque a gestire correttamente gli eventi.
Event Sourcing
Come sapete, una delle caratteristiche principali di un sistema distribuito è l'assenza di un tempo comune e di una sezione critica condivisa. Per un singolo processo, potete eseguire la sincronizzazione (sugli stessi mutex), all'interno della quale siete certi che nessun altro stia eseguendo quel codice. Tuttavia, per un sistema distribuito, ciò è pericoloso, poiché comporta delle spese generali e compromette l'intero vantaggio della scalabilità: tutti i componenti dovranno comunque aspettare uno.
Da ciò deriva un fatto importante: un sistema distribuito veloce non può essere sincronizzato, altrimenti ridurremo le prestazioni. D'altra parte, spesso è necessaria una certa coerenza dei componenti. Per questo motivo, si può adottare l'approccio della , dove si garantisce che, in assenza di modifiche ai dati, dopo un certo intervallo di tempo dall'ultimo aggiornamento («in fin dei conti»), tutte le richieste restituiranno l'ultimo valore aggiornato.
È importante comprendere che per i database classici si applica spesso , dove ogni nodo possiede le stesse informazioni (questo si ottiene spesso quando una transazione è considerata stabilita solo dopo la risposta del secondo server). Ci sono alcune eccezioni dovute ai livelli di isolamento, ma il concetto generale rimane lo stesso: puoi vivere in un mondo completamente coerente.
Tornando quindi al compito iniziale. Se una parte del sistema può essere costruita con , si può costruire il seguente schema.
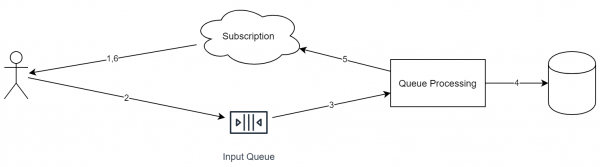
Caratteristiche chiave di questo approccio:
- Ogni richiesta in entrata viene inserita in una coda.
- Durante l'elaborazione della richiesta, il servizio può anche inserire task in altre code.
- Ogni evento in entrata ha un identificatore (necessario per la deduplicazione).
- La coda opera ideologicamente secondo lo schema "append only". Non è possibile rimuovere o riordinare gli elementi.
- La coda funziona secondo lo schema FIFO (chiedo scusa per la tautologia). Se è necessario eseguire in parallelo, bisogna spostare gli oggetti in diverse code in uno degli stadi.
Ricordo che stiamo considerando il caso di uno spazio di archiviazione online. In questo caso, il sistema apparirà all'incirca così:
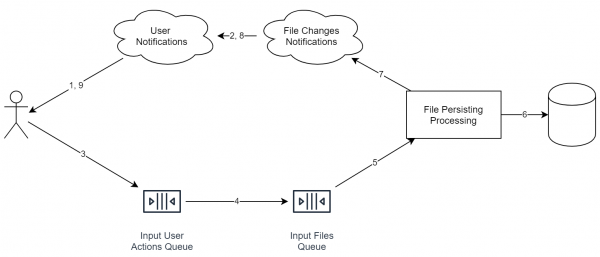
È importante notare che i servizi nel diagramma non devono necessariamente rappresentare server separati. Anche i processi possono essere gli stessi. Ciò che conta è che, ideologicamente, queste cose sono separate in modo da poter facilmente applicare la scalabilità orizzontale.
Per due utenti, lo schema apparirà così (i servizi destinati a diversi utenti sono contrassegnati con colori diversi):
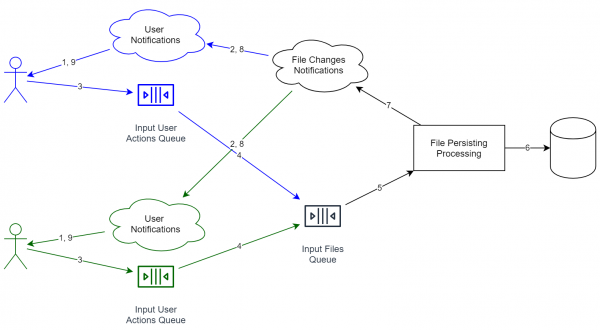
I vantaggi di una simile combinazione:
- I servizi di elaborazione delle informazioni sono separati. Anche le code sono separate. Se dobbiamo aumentare la capacità del sistema, basta avviare più servizi su un numero maggiore di server.
- Quando riceviamo informazioni dall'utente, non è necessario attendere il salvataggio completo dei dati. Al contrario, è sufficiente rispondere «ok» e iniziare a lavorare gradualmente. Inoltre, la coda attenua i picchi, poiché l'aggiunta di un nuovo oggetto avviene rapidamente, evitando all'utente di attendere un passaggio completo attraverso l'intero ciclo.
- Per esempio, ho aggiunto un servizio di deduplicazione che cerca di unire file identici. Se lavora a lungo in caso di 1%, il cliente praticamente non se ne accorgerà (vedi sopra), il che è un grande vantaggio, poiché da noi non è richiesta una velocità e un'affidabilità del cento per cento.
Tuttavia, sono subito evidenti anche i contro:
- La nostra sistema ha perso la rigorosa coerenza. Questo significa che, per esempio, se ci si iscrive a vari servizi, è teoricamente possibile ricevere stati diversi (poiché uno dei servizi potrebbe non riuscire a ricevere la notifica dalla coda interna). Come ulteriore conseguenza, ora il sistema non ha un tempo comune. Non è possibile, quindi, ordinare tutti gli eventi semplicemente in base all'orario di arrivo, poiché gli orologi tra i server potrebbero non essere sincronizzati (per di più, avere lo stesso orario su due server è un'utopia).
- Nessun evento può ora essere semplicemente annullato (come si potrebbe fare con un database). Invece, è necessario aggiungere un nuovo evento — , che cambierà l'ultimo stato necessario. Un esempio da un campo simile: senza riscrivere la cronologia (che è svantaggioso in alcuni casi) in git non si può annullare un commit, ma si può fare un'operazione speciale , che in sostanza riporterà semplicemente allo stato precedente. Tuttavia, nella cronologia rimarrà sia il commit errato che il rollback.
- Lo schema dei dati può cambiare da una release all'altra, ma ora non sarà possibile aggiornare i vecchi eventi al nuovo standard (poiché gli eventi non possono in linea generale essere modificati).
Come dimostrato, l'Event Sourcing si integra perfettamente con il CQRS. Anzi, implementare un sistema con code efficienti e facili da usare, ma senza separazione dei flussi di dati, è già di per sé una sfida, in quanto dovranno essere aggiunti punti di sincronizzazione che annulleranno tutto il vantaggio delle code. Applicando entrambi gli approcci contemporaneamente, è necessario apportare lievi modifiche al codice del programma. Nel nostro caso, quando un file viene inviato al server, la risposta restituisce solo "ok", il che significa semplicemente che "l'operazione di aggiunta del file è stata registrata". Formalmente, questo non implica che i dati siano già accessibili su altri dispositivi (ad esempio, il servizio di deduplica potrebbe ripristinare l'indice). Tuttavia, dopo un po', il cliente riceverà una notifica del tipo "il file X è stato salvato".
Come risultato:
- Il numero di stati di invio dei file aumenta: invece del classico "file inviato", otteniamo due stati: "file aggiunto alla coda sul server" e "file salvato nell'archivio". Quest'ultimo indica che altri dispositivi possono iniziare a ricevere il file (tenendo conto che le code operano a velocità diverse).
- Poiché le informazioni sull'invio ora arrivano attraverso diversi canali, è necessario trovare soluzioni per ottenere lo stato di elaborazione del file. Di conseguenza: a differenza della classica richiesta-risposta, il cliente può essere riavviato durante l'elaborazione del file, ma lo stato di tale elaborazione sarà corretto. Questo punto funziona, essenzialmente, out of the box. Di conseguenza, ora siamo più tolleranti ai fallimenti.
Sharding
Come descritto sopra, nei sistemi con event sourcing non esiste una coerenza rigorosa. Questo significa che possiamo utilizzare più archivi senza alcuna sincronizzazione tra di essi. Avvicinandoci al nostro compito, possiamo:
- Separare i file per tipologia. Ad esempio, le immagini/i video possono essere decodificati e possiamo scegliere un formato più efficiente.
- Separare gli account per paese. A causa di molte leggi, questo potrebbe essere necessario, ma questo schema architetturale offre questa possibilità in modo automatico.
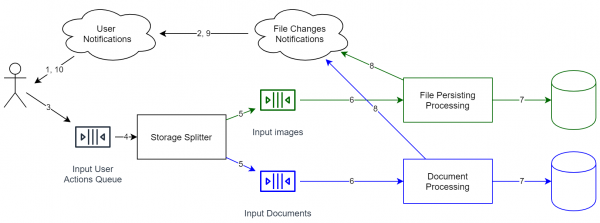
Если вы хотите перенести данные из одного хранилища в другое, то здесь уже стандартными средствами не обойтись. К сожалению, в таком случае необходимо остановить очередь, сделать миграцию, а потом запустить её. В общем случае «на лету» данные не перенести, однако, если очередь событий хранится полностью, и у вас есть слепки предыдущих состояний хранилища, то мы можем перепроиграть события следующим образом:
- В Event Source каждое событие имеет свой идентификатор (в идеале — не уменьшающийся). А значит в хранилище мы можем добавить поле — id последнего обработанного элемента.
- Дублируем очередь, чтобы все события могли обрабатываться для нескольких независимых хранилищ (первое — это то, в котором уже сейчас хранятся данные, а второе — новое, однако пока пустое). Вторая очередь, естественно, пока не обрабатывается.
- Запускаем вторую очередь (то есть начинаем перепроигрывание событий).
- Когда новая очередь будет относительно пуста (т.е. средняя разница во времени между добавлением элемента и его же извлечением будет приемлема), можно начинать переключать читателей на новое хранилище.
Come si può vedere, nel nostro sistema non c'è mai stata e non c'è una rigorosa coerenza. Esiste solo una coerenza eventuale, ovvero la garanzia che gli eventi vengano elaborati nello stesso ordine (tuttavia, con ritardi potenzialmente diversi). E, sfruttando questo, possiamo trasferire i dati senza interrompere il sistema dall'altra parte del mondo.
Pertanto, continuando con il nostro esempio di archiviazione online per i file, questa architettura ci offre già diversi vantaggi:
- Possiamo spostare gli oggetti più vicino agli utenti, in modo dinamico. In questo modo possiamo migliorare la qualità del servizio.
- Possiamo memorizzare parte dei dati all'interno delle aziende. Ad esempio, gli utenti Enterprise spesso richiedono di mantenere i loro dati in data center sotto controllo (per evitare perdite di dati). Grazie allo sharding, possiamo facilmente supportare questo. E la questione diventa ancora più semplice se il cliente dispone di un cloud compatibile (ad esempio, ).
- E la cosa più importante è che non siamo obbligati a farlo. Infatti, per cominciare, ci basterebbe avere un'unica repository per tutti gli account (per iniziare a lavorare più rapidamente). E la caratteristica chiave di questo sistema è che, sebbene sia scalabile, è abbastanza semplice nelle fasi iniziali. Non è necessario scrivere subito codice per gestire milioni di code indipendenti, ecc. Se in futuro sarà necessario, si potrà sempre fare.
Hosting di contenuti statici
Questo punto potrebbe sembrare ovvio, ma è comunque necessario per un'applicazione standard con carichi di lavoro considerevoli. La sua essenza è semplice: tutto il contenuto statico viene distribuito non dallo stesso server in cui si trova l'applicazione, ma da server dedicati appositamente a questo scopo. Di conseguenza, queste operazioni vengono eseguite più rapidamente (un condizionale nginx fornisce file in modo più veloce e meno costoso rispetto a un server Java). Inoltre, l'architettura CDN () consente di posizionare i nostri file più vicino agli utenti finali, il che migliora l'esperienza d'uso del servizio.
Il più semplice e standard esempio di contenuto statico è un insieme di script e immagini per un sito web. Con questi è tutto semplice: sono noti in anticipo e poi l'archivio viene caricato sui server CDN, da cui viene distribuito agli utenti finali.
Tuttavia, in realtà è possibile applicare un approccio simile a quello dell'architettura lambda per il contenuto statico. Torniamo al nostro compito (archiviazione online dei file), in cui dobbiamo distribuire file agli utenti. La soluzione più semplice sarebbe creare un servizio che, per ogni richiesta dell'utente, esegue tutte le necessarie verifiche (autenticazione, ecc.) e poi scarica il file direttamente dal nostro archivio. Il principale svantaggio di questo approccio è che il contenuto statico (e un file con una determinata revisione è essenzialmente un contenuto statico) viene distribuito dallo stesso server che gestisce la logica aziendale. Invece, possiamo realizzare il seguente schema:
- Il server fornisce un URL per il download. Questo può avere la forma file_id + key, dove key è una mini-firma digitale che conferisce accesso alla risorsa per le prossime 24 ore.
- La distribuzione dei file è gestita da un semplice nginx con le seguenti opzioni:
- Cache del contenuto. Poiché questo servizio potrebbe trovarsi su un server dedicato, abbiamo previsto la possibilità di memorizzare sul disco tutti i file scaricati più recenti.
- Verifica della chiave al momento della creazione della connessione
- Facoltativo: elaborazione in streaming del contenuto. Ad esempio, se comprimiamo tutti i file nel servizio, è possibile eseguire la decompressione direttamente in questo modulo. Di conseguenza: le operazioni di IO vengono eseguite dove è più opportuno. Un compressore in Java occuperebbe facilmente molta memoria extra, tuttavia riscrivere il servizio con logica commerciale in linguaggi come Rust/C++ potrebbe rivelarsi poco efficace. Nel nostro caso, utilizziamo processi diversi (o addirittura servizi), il che consente di separare in modo abbastanza efficace la logica commerciale dalle operazioni di IO.
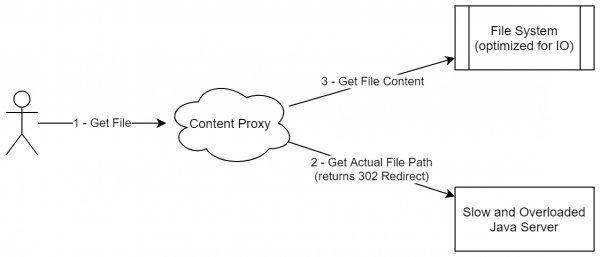
Questo schema non assomiglia molto alla distribuzione di contenuti statici (poiché non stiamo trasferendo l'intero pacchetto di statiche da nessuna parte), tuttavia, in realtà, tale approccio si occupa proprio della distribuzione di dati immutabili. Inoltre, questo schema può essere generalizzato ad altri casi in cui il contenuto non è solo statico, ma può essere rappresentato come un insieme di blocchi immutabili e non eliminabili (anche se possono essere aggiunti).
Un altro esempio (per conferma): se hai lavorato con Jenkins/TeamCity, sai che entrambe le soluzioni sono scritte in Java. Entrambi rappresentano un processo Java che si occupa sia dell'orchestrazione dei build che della gestione dei contenuti. In particolare, entrambi hanno compiti come "trasferire file/cartelle dal server". Ad esempio: distribuzione di artefatti, trasferimento del codice sorgente (quando l'agente non scarica il codice direttamente dal repository, ma lo fa il server), accesso ai log. Tutti questi compiti presentano un carico IO. Quindi, risulta che il server, responsabile della logica aziendale complessa, deve anche essere in grado di gestire efficacemente grandi flussi di dati. E ciò che è più interessante è che un'operazione simile può essere delegata allo stesso nginx secondo la stessa logica (salvo aggiungere una chiave di dati nella richiesta).
Tuttavia, se torniamo al nostro sistema, risulta una schematizzazione simile:
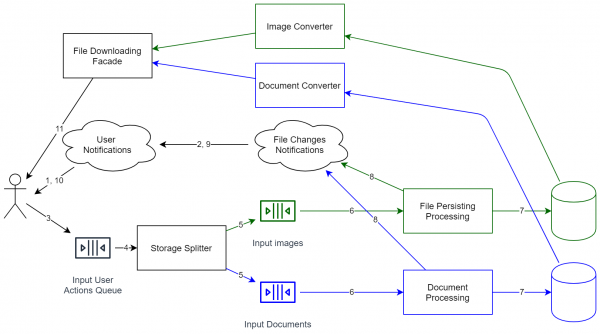
Come si può vedere, il sistema è diventato radicalmente più complesso. Non è più solo un mini-processo che memorizza файлов локально. Ora richiede un supporto più articolato, il controllo delle versioni API, ecc. Pertanto, dopo aver tracciato tutti i diagrammi, è meglio valutare attentamente se vale la pena investire in tale scalabilità. Tuttavia, se desiderate avere la possibilità di espandere il sistema (inclusa la gestione di un numero ancora maggiore di utenti), dovrete considerare soluzioni di questo tipo. Il risultato è che l'architettura del sistema è pronta ad affrontare un carico maggiore (praticamente ogni componente può essere clonato per una scalabilità orizzontale). Il sistema può essere aggiornato senza arrestarlo (alcune operazioni potrebbero solo rallentare leggermente).
Come già accennato all'inizio, diversi servizi online stanno ora affrontando carichi aumentati. Alcuni di essi hanno smesso di funzionare correttamente. In sostanza, i sistemi hanno ceduto proprio nel momento in cui il business avrebbe dovuto generare guadagni. Quindi, invece di un'opzione di consegna posticipata o di offrire ai clienti "pianificate la consegna nei prossimi mesi", il sistema ha semplicemente detto "andate dai competitor". Questa è, appunto, la conseguenza di una bassa performance: le perdite si verificano proprio quando i profitti potrebbero essere al massimo.
Conclusione
Tutti questi approcci erano già noti in precedenza. Ad esempio, VK utilizza da tempo l'idea di Static Content Hosting per la distribuzione delle immagini. Molti giochi online adottano uno schema di Sharding per separare i giocatori per regioni o per suddividere le aree di gioco (se il mondo è unico). L'approccio Event Sourcing è ampiamente utilizzato nelle email. La maggior parte delle applicazioni di trading, dove i dati arrivano continuamente, sono in realtà costruite su un approccio CQRS, per poter filtrare i dati ricevuti. Inoltre, la scalabilità orizzontale è stata applicata da tempo in molti servizi.
Tuttavia, ciò che è più importante, tutti questi modelli sono diventati molto facili da applicare nelle moderne applicazioni (se pertinenti, ovviamente). I cloud offrono Sharding e scalabilità orizzontale fin da subito, il che è molto più semplice rispetto all'ordinare server dedicati in vari data center da soli. CQRS è diventato molto più facile grazie allo sviluppo di librerie come RX. Dieci anni fa, pochi siti web erano in grado di supportare tutto ciò. Anche l'Event Sourcing si configura incredibilmente facilmente grazie ai contenitori già pronti con Apache Kafka. Dieci anni fa sarebbe stata un'innovazione, ora è una consuetudine. Allo stesso modo, anche l'hosting di contenuti statici: grazie a tecnologie più accessibili (in parte perché esiste una documentazione dettagliata e una vasta banca di risposte), questo approccio è diventato ancora più semplice.
In sintesi, l'implementazione di vari complessi pattern architetturali è diventata molto più semplice, il che significa che vale la pena prenderli in considerazione in anticipo. Se in un'applicazione decennale si è rinunciato a una delle soluzioni citate a causa dei costi elevati di implementazione e gestione, ora, in una nuova applicazione o dopo una refactoring, si può creare un servizio che sia architettonicamente sia scalabile (dal punto di vista delle prestazioni), sia pronto per nuove richieste dai clienti (ad esempio, per la localizzazione dei dati personali).
E la cosa più importante: per favore, non utilizzate questi approcci se avete un'applicazione semplice. Sì, sono belli e interessanti, tuttavia per un sito con un picco di 100 visitatori si può spesso fare a meno di un classico monolite (almeno dall'esterno, mentre all'interno tutto può essere suddiviso in moduli, e così via).
Fonte: habr.com
