


In questo articolo, spiegherò come configurare un ambiente per l'apprendimento automatico in 30 minuti, creare una rete neurale per il riconoscimento delle immagini e poi eseguire la stessa rete su una scheda grafica (GPU).
Cominciamo definendo cosa sia una rete neurale.
Nel nostro caso, si tratta di un modello matematico e della sua implementazione software o hardware, costruito secondo il principio di organizzazione e funzionamento delle reti neurali biologiche — le reti di cellule nervose di un organismo vivo. Questo concetto è emerso durante lo studio dei processi che avvengono nel cervello e nel tentativo di modellare tali processi.
Le reti neurali non vengono programmate nel senso tradizionale del termine, ma vengono addestrate. La possibilità di apprendimento è uno dei principali vantaggi delle reti neurali rispetto agli algoritmi tradizionali. Dal punto di vista tecnico, l'addestramento consiste nel trovare i coefficienti delle connessioni tra i neuroni. Durante il processo di apprendimento, la rete neurale è in grado di identificare dipendenze complesse tra i dati in ingresso e quelli in uscita, nonché di eseguire generalizzazioni.
Dal punto di vista del machine learning, una rete neurale è un caso specifico dei metodi di riconoscimento di pattern, analisi discriminante, metodi di clustering e altri approcci simili.
Attrezzature
Iniziamo dall'hardware. Abbiamo bisogno di un server con un sistema operativo Linux installato. L'hardware per i sistemi di machine learning deve essere piuttosto potente e, di conseguenza, costoso. Per chi non ha a disposizione una buona macchina, consiglio di considerare l'offerta dei provider cloud. È possibile noleggiare il server necessario rapidamente e pagare solo per il tempo di utilizzo.
Nei progetti che richiedono la creazione di reti neurali, utilizzo server di uno dei fornitori di cloud russi. L'azienda offre server cloud in affitto specificamente per il machine learning, dotati di potenti GPU Tesla V100 di NVIDIA. In breve: l'uso di un server con GPU può essere decine di volte più efficiente (veloce) rispetto a un server con CPU simile per costo (il ben noto processore centrale). Questo è possibile grazie alle caratteristiche dell'architettura GPU, che gestisce i calcoli più rapidamente.
Per eseguire gli esempi descritti di seguito, abbiamo noleggiato un tale server per alcuni giorni:
- Disco SSD da 150 GB
- RAM da 32 GB
- Processore Tesla V100 da 16 Gb con 4 core
Sul server abbiamo installato Ubuntu 18.04.
Installiamo l'ambiente
Ora installeremo sul server tutto il necessario per lavorare. Poiché il nostro articolo è principalmente per principianti, tratterò alcuni aspetti che saranno utili a loro.
La configurazione dell'ambiente richiede molto lavoro attraverso la riga di comando. La maggior parte degli utenti utilizza Windows come sistema operativo. La console standard di questo sistema lascia molto a desiderare. Pertanto, utilizzeremo uno strumento più comodo. . Scarichiamo la mini versione e avviamo Cmder.exe. Successivamente, dobbiamo collegarci al server tramite il protocollo SSH:
ssh root@server-ip-or-hostnameAl posto di server-ip-or-hostname, inserite l'indirizzo IP o il nome DNS del vostro server. Inseriamo quindi la password e, se la connessione ha successo, dovremmo ricevere un messaggio simile.
Welcome to Ubuntu 18.04.3 LTS (GNU/Linux 4.15.0-74-generic x86_64)Il linguaggio principale per lo sviluppo di modelli ML è Python. E la piattaforma più popolare per il suo utilizzo su Linux è .
Installiamola sul nostro server.
Iniziamo aggiornando il gestore locale dei pacchetti:
sudo apt-get updateInstalliamo curl (strumento a riga di comando):
sudo apt-get install curlScarichiamo l'ultima versione di Anaconda Distribution:
cd /tmp
curl –O https://repo.anaconda.com/archive/Anaconda3-2019.10-Linux-x86_64.shAvviamo l'installazione:
bash Anaconda3-2019.10-Linux-x86_64.shDurante l'installazione sarà necessario confermare il contratto di licenza. Dopo un'installazione avvenuta con successo, dovresti vedere questo:
Grazie per aver installato Anaconda3!Per lo sviluppo di modelli ML sono stati creati molti framework, noi lavoriamo con i più popolari: e .
L'utilizzo del framework consente di aumentare la velocità di sviluppo e di sfruttare strumenti già pronti per compiti standard.
In questo esempio lavoreremo con PyTorch. Installiamolo:
conda install pytorch torchvision cudatoolkit=10.1 -c pytorchOra dobbiamo avviare Jupyter Notebook, uno strumento popolare tra i professionisti del ML. Permette di scrivere codice e vedere immediatamente i risultati della sua esecuzione. Jupyter Notebook è incluso in Anaconda ed è già installato sul nostro server. È necessario collegarsi ad esso dalla nostra macchina desktop.
Per fare ciò, prima avvieremo Jupyter sul server indicando la porta 8080:
jupyter notebook --no-browser --port=8080 --allow-rootPoi, aprendo un'altra scheda nella nostra console Cmder (menù in alto — New console dialog), ci collegheremo alla porta 8080 del server tramite SSH:
ssh -L 8080:localhost:8080 root@server-ip-or-hostnameDopo aver inserito il primo comando, ci verranno fornite le link per aprire Jupyter nel nostro browser:
Per accedere al notebook, apri questo file in un browser:
file:///root/.local/share/jupyter/runtime/nbserver-18788-open.html
Oppure copia e incolla uno di questi URL:
http://localhost:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
o http://127.0.0.1:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
Utilizziamo il link per localhost:8080. Copia il percorso completo e incollalo nella barra degli indirizzi del browser locale del tuo PC. Si aprirà Jupyter Notebook.
Creiamo un nuovo notebook: New — Notebook — Python 3.
Verifichiamo il corretto funzionamento di tutti i componenti che abbiamo installato. Inseriamo in Jupyter un esempio di codice PyTorch e avviamo l'esecuzione (pulsante Run):
from __future__ import print_function
import torch
x = torch.rand(5, 3)
print(x)
Il risultato dovrebbe essere più o meno così:
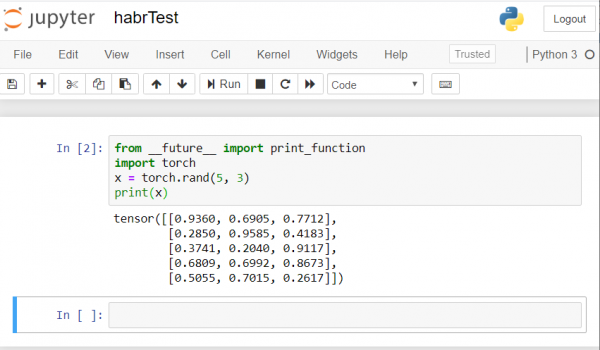
Se ottieni un risultato simile, significa che abbiamo configurato tutto correttamente e possiamo iniziare a sviluppare la rete neurale!
Creiamo una rete neurale
Stiamo per creare una rete neurale per il riconoscimento delle immagini. Prenderemo come base questo .
Per addestrare la rete utilizzeremo il set di dati pubblico CIFAR10. Esso include le classi: «aereo», «automobile», «uccello», «gatto», «cervo», «cane», «rana», «cavallo», «nave», «camion». Le immagini in CIFAR10 hanno una dimensione di 3x32x32, ovvero immagini colorate a 3 canali di 32×32 pixel.

Per il lavoro utilizzeremo il pacchetto PyTorch creato per la gestione delle immagini — torchvision.
Eseguiranno i seguenti passaggi in ordine:
- Caricamento e normalizzazione dei set di dati di addestramento e test
- Definizione della rete neurale
- Addestramento della rete sui dati di addestramento
- Test della rete sui dati di test
- Ripeteremo l'addestramento e il test utilizzando la GPU
Tutto il codice qui sotto lo eseguiremo in Jupyter Notebook.
Caricamento e normalizzazione di CIFAR10
Copia e incolla il seguente codice in Jupyter:
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('aereo', 'auto', 'uccello', 'gatto',
'cervo', 'cane', 'rana', 'cavallo', 'nave', 'camion')La risposta deve essere così:
Scaricando https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz in ./data/cifar-10-python.tar.gz
Estraendo ./data/cifar-10-python.tar.gz in ./data
File già scaricati e verificatiMostriamo alcune immagini di addestramento per verifica:
import matplotlib.pyplot as plt
import numpy as np
# funzioni per mostrare un'immagine
def imshow(img):
img = img / 2 + 0.5 # denormalizza
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# ottieni alcune immagini di addestramento casuali
dataiter = iter(trainloader)
images, labels = dataiter.next()
# mostra le immagini
imshow(torchvision.utils.make_grid(images))
# stampa le etichette
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

Definizione della rete neurale
Iniziamo a vedere come funziona una rete neurale per il riconoscimento delle immagini. Si tratta di una rete semplice a connessione diretta. Accetta i dati di input, li elabora attraverso diversi strati uno dopo l'altro e, infine, fornisce l'output.
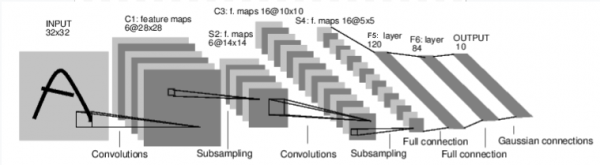
Creiamo una rete simile nel nostro ambiente:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
Definiamo anche la funzione di perdita e l'ottimizzatore
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)Addestramento della rete sui dati di addestramento
Iniziamo l'addestramento della nostra rete neurale. Tieni presente che dopo aver eseguito questo codice, dovrai attendere un po' fino al termine dell'esecuzione. A me è servito circa 5 minuti. L'addestramento della rete richiede tempo.
per epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# ottieni gli input; data è una lista di [input, etichette]
inputs, labels = data
# azzera i gradienti dei parametri
optimizer.zero_grad()
# avanti + indietro + ottimizza
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# stampa statistiche
running_loss += loss.item()
if i % 2000 == 1999: # stampa ogni 2000 mini-lotti
print('[%d, ] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Formazione completata')
Otterremo questo risultato:
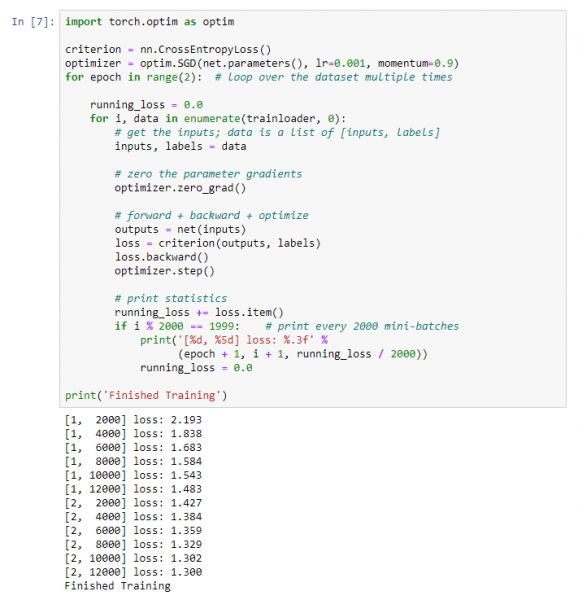
Salviamo il nostro modello addestrato:
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)Test della rete sui dati di test
Abbiamo addestrato la rete utilizzando un set di dati di addestramento. Ma dobbiamo verificare se la rete ha veramente appreso qualcosa.
Verificheremo questo prevedendo l'etichetta di classe emessa dalla rete neurale e controllandola per la verità. Se la previsione è corretta, aggiungiamo il campione all'elenco delle previsioni corrette.
Mostriamo un'immagine del set di test:
dataiter = iter(testloader)
images, labels = dataiter.next()
# stampa le immagini
imshow(torchvision.utils.make_grid(images))
print('Verità Terrena: ', ' '.join('%5s' % classes[labels[j]] for j in range(4))) 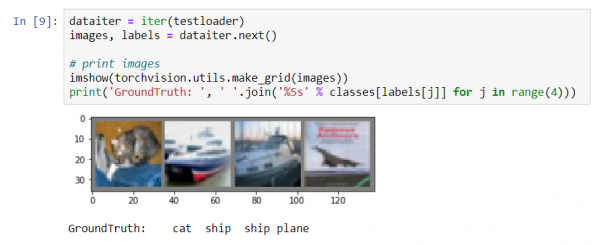
Ora chiediamo alla rete neurale di dirci cosa c'è in queste immagini:
net = Net()
net.load_state_dict(torch.load(PATH))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predetto: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))
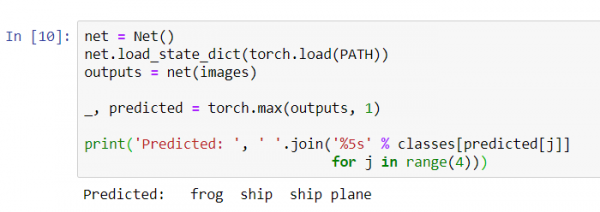
I risultati sembrano piuttosto buoni: la rete ha identificato correttamente tre immagini su quattro.
Vediamo come si comporta la rete su tutto il set di dati.
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuratezza della rete sulle 10000 immagini di test: %d %%' % (
100 * correct / total)) 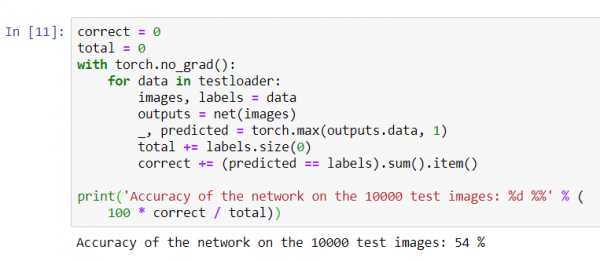
Sembra che la rete sappia qualcosa e stia funzionando. Se classificasse le classi a caso, l'accuratezza sarebbe del 10%.
Ora vediamo quali classi la rete identifica meglio:
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuratezza di %5s : %%' % (
classes[i], 100 * class_correct[i] / class_total[i])) 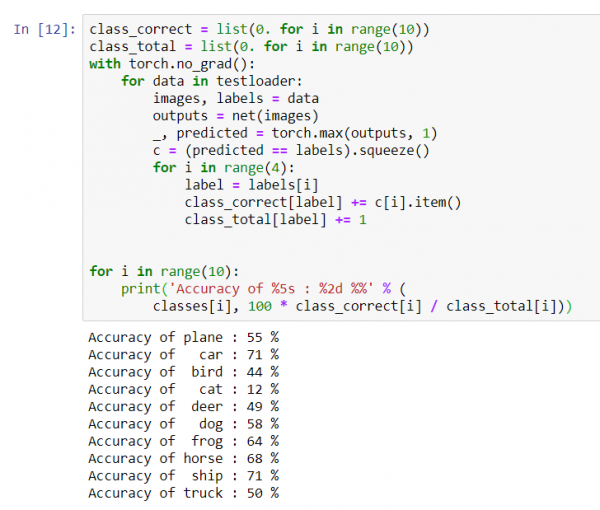
Sembra che la rete identifichi meglio le auto e le navi: 71% di accuratezza.
Quindi, la rete funziona. Ora proviamo a trasferire il suo funzionamento sulla scheda grafica (GPU) e vediamo cosa cambia.
Addestramento della rete neurale su GPU
Iniziamo con una breve spiegazione di cosa sia CUDA. CUDA (Compute Unified Device Architecture) è una piattaforma di calcolo parallelo sviluppata da NVIDIA, per calcoli generali su schede grafiche (GPU). Grazie a CUDA, gli sviluppatori possono accelerare notevolmente le applicazioni di calcolo sfruttando le potenzialità delle schede grafiche. La piattaforma è già installata sul nostro server che abbiamo acquistato.
Iniziamo definendo la nostra GPU come primo dispositivo visibile CUDA.
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Supponendo di essere su una macchina CUDA, questo dovrebbe stampare un dispositivo CUDA:
print(device) 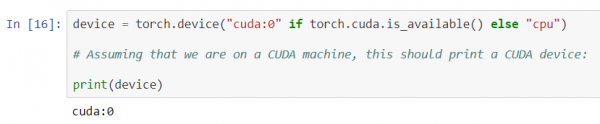
Inviamo la rete sulla GPU:
net.to(device)Dovremo anche inviare input e obiettivi ad ogni passaggio sulla GPU:
inputs, labels = data[0].to(device), data[1].to(device)Avviamo il riaddestramento della rete già sulla GPU:
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# ottieni gli input; data è una lista di [input, etichette]
inputs, labels = data[0].to(device), data[1].to(device)
# azzera i gradienti dei parametri
optimizer.zero_grad()
# avanti + indietro + ottimizza
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# stampa statistiche
running_loss += loss.item()
if i % 2000 == 1999: # stampa ogni 2000 mini-lotti
print('[%d, ] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Formazione completata')Questa volta l'addestramento della rete è durato circa 3 minuti. Ricordiamo che la stessa fase su un normale processore ha impiegato 5 minuti. La differenza non è significativa, poiché la nostra rete non è così grande. Quando si utilizzano grandi set di dati per l'addestramento, la differenza tra la velocità di lavoro della GPU e quella del processore tradizionale aumenterà.
Sembra sia tutto. Cosa siamo riusciti a fare:
- Abbiamo esaminato cosa sia una GPU e scelto un server su cui è installata;
- Abbiamo configurato l'ambiente software per creare una rete neurale;
- Abbiamo creato una rete neurale per il riconoscimento delle immagini e l'abbiamo addestrata;
- Abbiamo riaddestrato la rete utilizzando la GPU e abbiamo ottenuto un incremento nella velocità.
Sarò lieto di rispondere alle domande nei commenti.
Fonte: habr.com
