

Ciao a tutti, condividiamo con voi la seconda parte della pubblicazione “File system virtuali in Linux: Perché sono necessari e come funzionano? La prima parte può essere letta . Ricordiamo che questa serie di pubblicazioni è programmata per coincidere con il lancio di un nuovo flusso sul corso , che inizierà molto presto.
Come monitorare VFS utilizzando gli strumenti eBPF e bcc
Il modo più semplice per capire come opera il kernel sui file sysfs è vederlo in pratica, e il modo più semplice per guardare ARM64 è usare eBPF. eBPF (abbreviazione di Berkeley Packet Filter) consiste in una macchina virtuale in esecuzione , che gli utenti privilegiati possono richiedere (query) dalla riga di comando. I sorgenti del kernel dicono al lettore cosa può fare il kernel; l'esecuzione degli strumenti eBPF su un sistema caricato mostra cosa sta effettivamente facendo il kernel.

Fortunatamente, iniziare a utilizzare eBPF è abbastanza semplice con l'aiuto di strumenti , che sono disponibili come pacchetti dalla distribuzione generale e documentato dettagliatamente . Utensili bcc sono script Python con piccoli inserimenti di codice C, il che significa che chiunque abbia familiarità con entrambi i linguaggi può modificarli facilmente. IN bcc/tools Esistono 80 script Python, il che significa che molto probabilmente uno sviluppatore o un amministratore di sistema potrà scegliere qualcosa di adatto a risolvere il problema.
Per avere almeno un'idea superficiale di cosa funzionano i VFS su un sistema in esecuzione, prova vfscount o vfsstat. Questo mostrerà, diciamo, che dozzine di chiamate vfs_open() e i "suoi amici" accadono letteralmente ogni secondo.
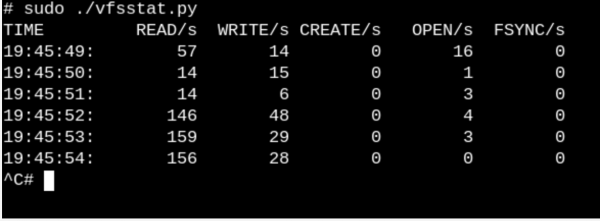
vfsstat.pyè uno script Python con inserti di codice C che conta semplicemente le chiamate alle funzioni VFS.
Facciamo un esempio più banale e vediamo cosa succede quando inseriamo una chiavetta USB in un computer e il sistema la rileva.
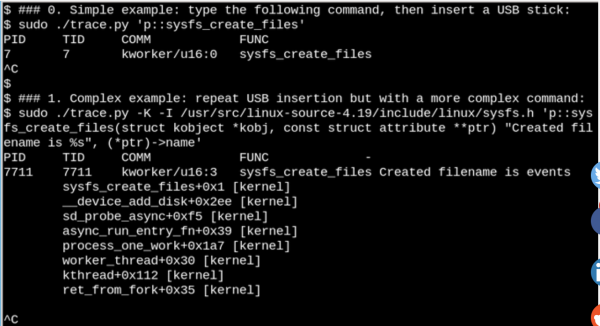
Usando eBPF puoi vedere cosa sta succedendo in
/sysquando viene inserita un'unità flash USB. Qui viene mostrato un esempio semplice e complesso.
Nell'esempio mostrato sopra, bcc инструмент stampa un messaggio quando viene eseguito il comando sysfs_create_files(). Lo vediamo sysfs_create_files() è stato lanciato utilizzando kworker stream in risposta al fatto che è stata inserita l'unità flash, ma quale file è stato creato? Il secondo esempio mostra la potenza di eBPF. Qui trace.py Stampa un backtrace del kernel (opzione -K) e il nome del file che è stato creato sysfs_create_files(). L'inserimento di una singola istruzione è un codice C che include una stringa di formato facilmente riconoscibile fornita dallo script Python che esegue LLVM compilatore just-in-time. Compila questa riga e la esegue in una macchina virtuale all'interno del kernel. Firma completa delle funzioni sysfs_create_files () deve essere riprodotto nel secondo comando in modo che la stringa di formato possa fare riferimento a uno dei parametri. Gli errori in questa parte di codice C provocano errori riconoscibili dal compilatore C. Ad esempio, se il parametro -l viene omesso, verrà visualizzato il messaggio "Impossibile compilare il testo BPF". Gli sviluppatori che hanno familiarità con C e Python troveranno gli strumenti bcc facile da espandere e modificare.
Quando viene inserita l'unità USB, il backtrace del kernel mostrerà che il PID 7711 è un thread kworkerche ha creato il file «events» в sysfs. Di conseguenza, la chiamata da sysfs_remove_files() mostrerà che la rimozione dell'unità ha comportato l'eliminazione del file events, che corrisponde al concetto generale di conteggio dei riferimenti. Allo stesso tempo, visualizzazione sysfs_create_link () con eBPF durante l'inserimento dell'unità USB verrà visualizzato che sono stati creati almeno 48 collegamenti simbolici.
Allora qual è lo scopo del file degli eventi? Utilizzo Per ricerca , mostra cosa provoca disk_add_events (), e nemmeno "media_change"O "eject_request" può essere registrato in un file evento. Qui il livello del blocco del kernel informa lo spazio utente che un "disco" è apparso ed espulso. Nota quanto sia informativo questo metodo di ricerca inserendo un'unità USB, rispetto al tentativo di capire come funzionano le cose esclusivamente dalla fonte.
I file system root di sola lettura abilitano i dispositivi incorporati
Naturalmente nessuno spegne il server o il proprio computer staccando la spina dalla presa. Ma perché? Questo perché i file system montati sui dispositivi di archiviazione fisici potrebbero avere scritture ritardate e le strutture dati che registrano il loro stato potrebbero non essere sincronizzate con le scritture sull'archiviazione. Quando ciò accade, i proprietari del sistema devono attendere fino al successivo avvio per avviare l'utilità. fsck filesystem-recovery e, nel peggiore dei casi, perdita di dati.
Tuttavia, sappiamo tutti che molti dispositivi IoT, così come router, termostati e automobili, ora funzionano su LinuxMolti di questi dispositivi non hanno praticamente alcuna interfaccia utente e non c'è modo di spegnerli correttamente. Immaginate di dover avviare un'auto con la batteria scarica quando l'alimentazione al dispositivo di controllo viene interrotta. saltando continuamente su e giù. Com'è possibile che il sistema si avvii senza molto tempo fsckquando finalmente il motore inizia a funzionare? E la risposta è semplice. I dispositivi incorporati si basano sul file system root (abbreviato ro-rootfs (file system root di sola lettura)).
ro-rootfs offrono molti vantaggi meno evidenti dell’autenticità. Un vantaggio è che il malware non può scrivere /usr o /lib, se non c'è processo Linux Non è possibile scriverci. Un altro vantaggio è che un file system in gran parte immutabile è fondamentale per l'assistenza sul campo dei dispositivi remoti, poiché il personale di supporto utilizza sistemi locali nominalmente identici ai sistemi in loco. Forse il vantaggio più importante (ma anche più insidioso) è che ro-rootfs obbliga gli sviluppatori a decidere quali oggetti di sistema saranno immutabili fin dalle prime fasi della progettazione del sistema. Lavorare con ro-rootfs può essere scomodo e faticoso, come spesso accade con le variabili const nei linguaggi di programmazione, ma i suoi vantaggi superano di gran lunga il sovraccarico aggiuntivo.
creazione rootfs La funzionalità di sola lettura richiede uno sforzo aggiuntivo per gli sviluppatori di sistemi embedded, ed è qui che entra in gioco VFS. Linux richiede che i file in /var erano scrivibili e, inoltre, molte applicazioni popolari che eseguono sistemi embedded tentano di creare configurazioni dot-files в $HOME. Una soluzione per i file di configurazione nella directory home è solitamente quella di pregenerarli e incorporarli rootfs. Per /var Un approccio possibile è montarlo su una partizione scrivibile separata, mentre / montato in sola lettura. Un'altra alternativa popolare è utilizzare supporti vincolati o sovrapposti.
Supporti collegabili e impilabili, loro utilizzo in contenitori
Esecuzione del comando man mount è il modo migliore per conoscere i montaggi associabili e sovrapponibili, che offrono agli sviluppatori e agli amministratori di sistema la possibilità di creare un file system in un percorso e quindi esporlo alle applicazioni in un altro. Per i sistemi embedded, ciò significa la possibilità di archiviare file in /var su un'unità flash di sola lettura, ma da un percorso di montaggio sovrapposto o collegabile tmpfs в /var durante il caricamento, consentirà alle applicazioni di scrivere note lì (scarabocchio). La prossima volta che attivi le modifiche a /var saranno persi. Un supporto sovrapposto crea un'unione tra tmpfs e il file system sottostante e consente di apportare modifiche apparenti ai file esistenti in ro-tootf mentre una cavalcatura legabile può renderne vuote delle nuove tmpfs cartelle visibili come scrivibili in ro-rootfs modi. Mentre overlayfs questo è quello giusto (proper) tipo di file system in cui è implementato il montaggio associabile .
In base alla descrizione del rivestimento e del supporto collegabile, nessuno se ne stupisce vengono utilizzati attivamente. Vediamo cosa succede quando lo usiamo per eseguire il contenitore utilizzando lo strumento mountsnoop от bcc.
chiamata system-nspawn avvia il contenitore durante l'esecuzione mountsnoop.py.
Vediamo cosa è successo:
Запуск mountsnoop mentre il contenitore si sta "avviando" mostra che il tempo di esecuzione del contenitore dipende fortemente dal montaggio collegato (viene mostrato solo l'inizio dell'output lungo).
Qui systemd-nspawn fornisce i file selezionati in procfs и sysfs host al contenitore come percorsi ad esso rootfs... Oltretutto MS_BIND flag che imposta il montaggio dell'associazione, alcuni altri flag sul montaggio definiscono la relazione tra le modifiche agli spazi dei nomi host e contenitore. Ad esempio, una montatura collegata può ignorare le modifiche a /proc и /sys nel contenitore, oppure nasconderli a seconda della chiamata.
conclusione
Comprendere la struttura interna Linux potrebbe sembrare un compito impossibile, dato che il kernel stesso contiene un'enorme quantità di codice, escluse le applicazioni in spazio utente. Linux e interfacce di chiamata di sistema nelle librerie C come glibc. Un modo per fare progressi è leggere il codice sorgente di un sottosistema del kernel, con particolare attenzione alla comprensione delle chiamate di sistema e delle intestazioni dello spazio utente, nonché delle principali interfacce interne del kernel, come la tabella file_operations. Le operazioni sui file forniscono il principio "tutto è un file", rendendole particolarmente piacevoli da gestire. File sorgente del kernel C nella directory di livello superiore fs/ rappresentano un'implementazione di file system virtuali, che costituiscono un livello wrapper che fornisce un'ampia e relativamente semplice compatibilità tra i file system e i dispositivi di archiviazione più diffusi. Montaggio con collegamento e sovrapposizione tramite namespace Linux — è la magia di VFS che rende possibile la creazione di container e file system root di sola lettura. Combinato con uno studio del codice sorgente, lo strumento kernel eBPF e la sua interfaccia bcc
rendendo l'esplorazione dei nuclei più semplice che mai.
Amici, fatemi sapere se questo articolo vi è stato utile. Avete forse commenti o suggerimenti? E per coloro che sono interessati al corso "Amministratore", Linux", vi invitiamo a , che si svolgerà il 18 aprile.
Fonte: habr.com
