

Ciao a tutti. Di seguito è riportata la trascrizione .
– un sistema di monitoraggio per vari sistemi e servizi, che consente agli amministratori di sistema di raccogliere informazioni sui parametri attuali dei sistemi e di configurare avvisi per ricevere notifiche su eventuali malfunzionamenti.
Nella presentazione verrà effettuato un confronto e — progetti per la conservazione a lungo termine delle metriche di Prometheus.



Iniziamo con Prometheus. È un sistema di monitoraggio che raccoglie metriche da target specificati e le salva in uno storage locale. Prometheus è in grado di registrare metriche in uno storage remoto, generare avvisi e recording rules.

Limitazioni di Prometheus:
- Non dispone di una vista globale delle query. Questo accade quando avete più istanze indipendenti di Prometheus che raccolgono metriche. E volete eseguire una query su tutte queste metriche raccolte da diverse istanze di Prometheus. Prometheus non lo consente.
- In prometheus, le prestazioni sono limitate a un solo server. Prometheus non può scalare automaticamente su più server. Puoi solo suddividere manualmente i tuoi target tra più Prometheus.
- Il numero di metriche in Prometheus è limitato a un solo server per lo stesso motivo per cui non può scalare automaticamente su più server.
- In Prometheus non è così facile garantire la persistenza dei dati.

Quali sono le soluzioni a questi problemi?
Le soluzioni sono:
Tutte queste soluzioni servono per l'archiviazione remota dei dati raccolti da Prometheus. Risolvono il problema dello storage remoto del diapositiva precedente in modi diversi. In questa presentazione parlerò solo delle prime due soluzioni: e .
Per la prima volta, informazioni su sono apparse a . Qui viene descritta l'architettura e come funziona.

Thanos prende i dati che Prometheus ha salvato sul disco locale e li copia in S3, in o in un altro storage object.

In questo modo Thanos fornisce una vista globale delle query. Puoi interrogare i dati archiviati nello storage object da più istanze di Prometheus.

Thanos supporta PromQL e .

Thanos utilizza il codice di Prometheus per la persistenza dei dati.

Thanos è sviluppato dagli stessi sviluppatori di Prometheus.
Riguardo . Ecco , dove abbiamo parlato per la prima volta di .
VictoriaMetrics raccoglie dati da più prometheus tramite un protocollo supportato da Prometheus.
VictoriaMetrics fornisce una vista di query globale, poiché più istanze di Prometheus possono scrivere dati in un'unica VictoriaMetrics. Pertanto, puoi effettuare richieste su tutti questi dati.

VictoriaMetrics supporta, come Thanos, sia PromQL che l'API di query di Prometheus.

A differenza di Thanos, il codice sorgente di VictoriaMetrics è stato scritto da zero ed è ottimizzato per velocità e consumo di risorse.

VictoriaMetrics, a differenza di Thanos, può scalare sia verticalmente che orizzontalmente. C'è , che scala verticalmente. Puoi iniziare con un processore e 1 GB di memoria e crescere gradualmente fino a centinaia di processori e 1 TB di memoria. VictoriaMetrics è in grado di utilizzare tutte queste risorse. Le sue performance aumenteranno di circa 100 volte rispetto a un sistema a un nucleo.

La storia di Thanos è iniziata a novembre 2017, quando è stato effettuato il primo commit pubblico. Prima di ciò, Thanos era sviluppato all'interno dell'azienda .

Nel giugno 2019, è stata rilasciata la versione 0.5.0, in cui protocollo. È stato rimosso da Thanos perché ha mostrato alcune lacune. Spesso il cluster Thanos non funzionava correttamente, con nodi che si collegavano in modo errato a causa del protocollo gossip. Per questo motivo si è deciso di rimuoverlo. Ritengo che sia la scelta giusta.

Nello stesso giugno 2019 hanno inviato la richiesta numero in .

E dopo qualche mese, Thanos è stato accettato in , che include Prometheus, Kubernetes e altri progetti popolari.

Nel gennaio 2018 è iniziato lo sviluppo di VictoriaMetrics.

A settembre 2018 ho menzionato pubblicamente per la prima volta VictoriaMetrics.

A dicembre 2018 è stata pubblicata la versione Single-node.

A maggio 2019 i sorgenti sia della versione Single-node che di quella cluster.

A giugno 2019, proprio come Thanos, abbiamo presentato la domanda alla CNCF foundation con il numero . Abbiamo presentato la domanda un giorno prima rispetto a Thanos.

Ma, sfortunatamente, non siamo ancora stati accettati. Abbiamo bisogno dell'aiuto della community.

Esaminiamo le diapositive più importanti, che mostrano l'architettura di Thanos e VictoriaMetrics.
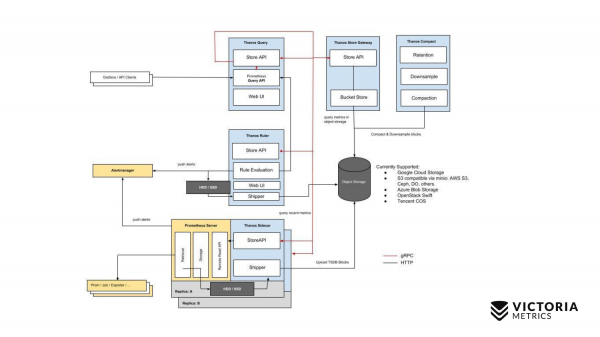
Iniziamo con Thanos. I componenti gialli sono i componenti di Prometheus. Tutto il resto sono componenti di Thanos. Cominciamo con il componente più importante. Thanos Sidecar è un componente che si installa accanto a ogni Prometheus. Si occupa di caricare i dati di Prometheus dallo storage locale in S3 o in un altro Object Storage.
C'è anche un componente chiamato Thanos Store Gateway, che può leggere questi dati dall'Object Storage quando riceve richieste da Thanos Query. Thanos Query implementa PromQL e l'API di Prometheus. Quindi, esternamente, appare come Prometheus. Riceve richieste PromQL, le invia a Thanos Store Gateway, il quale recupera i dati necessari dall'Object Storage e li rimanda indietro.
Tuttavia, nel nostro Object Storage i dati degli ultimi due ore non sono conservati a causa della particolare implementazione di Thanos Sidecar, che non riesce a caricare le ultime due ore nell'Object Storage S3, poiché per queste due ore Prometheus non ha ancora creato i file nello storage locale.
Come abbiamo risolto questo problema? Thanos Query, oltre a inviare richieste a Thanos Store Gateway, invia parallelamente richieste a ciascun Thanos Sidecar che si trova accanto a Prometheus.
Il Thanos Sidecar, a sua volta, inoltra le richieste a Prometheus, recuperando i dati delle ultime due ore.
Oltre a questi componenti, c'è un componente opzionale senza il quale Thanos potrebbe non funzionare bene. Si tratta di Thanos Compact, che gestisce la fusione di file di piccole dimensioni in file più grandi all'interno dello Object Storage, caricati dai Thanos Sidecar. Thanos Sidecar carica i file di dati delle ultime due ore. Se non vengono uniti in file più grandi, il loro numero può aumentare notevolmente. Maggiore è il numero di questi file, più memoria è necessaria per Thanos Store Gateway e più risorse occorrono per la trasmissione dei dati tramite la rete e i metadati. L'efficacia di Thanos Store Gateway diminuisce. Pertanto, è essenziale avviare Thanos Compact, che unisce i file di piccole dimensioni in file più grandi, per ridurre il numero di tali file e diminuire il sovraccarico su Thanos Store Gateway.
C'è anche un componente chiamato Thanos Ruler. Esso esegue le regole di allerta di Prometheus e può calcolare le regole di registrazione di Prometheus, per registrare nuovamente i dati nello Object Storage. Tuttavia, non si raccomanda di utilizzare questo componente, poiché è .
Ecco uno schema semplice di Thanos.
Ora confrontiamolo con lo schema di VictoriaMetrics.
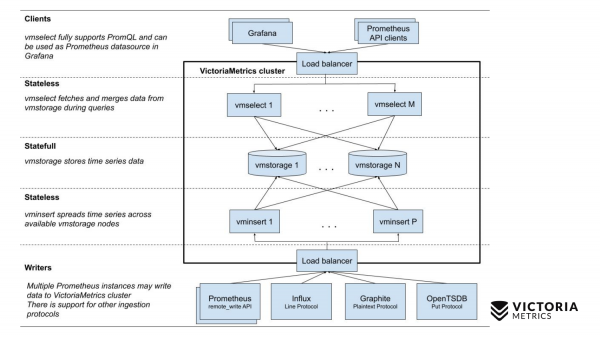
VictoriaMetrics offre due versioni: quella a nodo singolo e la versione cluster. La versione a nodo singolo funziona su un solo computer. Non ci sono questi componenti nella versione a nodo singolo, ma solo un binario. Questo binario è rappresentato da questo quadrato nel diagramma. Tutto ciò che si trova all'interno del quadrato è il contenuto del file binario per la versione a nodo singolo. Non è necessario sapere nulla di più. Basta eseguire il binario e tutto funziona.
La versione cluster è più complessa. Al suo interno ci sono tre componenti diversi: vmselect, vminsert e vmstorage. Dalla loro denominazione si può intuire qual è la funzione di ciascuno di essi. Il componente Insert accetta dati in diversi formati: dall'API Prometheus remote write, dal protocollo Line di Influx, dal protocollo Graphite e dal protocollo OpenTSDB. Il componente Insert li riceve, li analizza e li distribuisce tra i componenti di storage disponibili, dove i dati vengono effettivamente memorizzati. Il componente Select, dal canto suo, riceve le query PromQL. Implementa , oltre all'API di interrogazione di Prometheus, e può essere utilizzato come sostituto di Prometheus in Grafana o in altri client API di Prometheus. Il Select accetta una query promql, la analizza, legge i dati necessari per eseguire questa query dai nodi di storage, elabora questi dati e restituisce la risposta.

Confrontiamo la complessità di installazione di Thanos e VictoriaMetrics.

Iniziamo con Thanos. Prima di iniziare a lavorare con Thanos, è necessario creare un bucket nello storage oggetti, come S3 o GCS, affinché il Thanos Sidecar possa scrivere i dati.

Successivamente, per ogni Prometheus, è necessario installare il Thanos Sidecar. Prima di questo, non dimenticare di disattivare la compattazione dei dati in Prometheus. La compattazione dei dati comprime periodicamente i dati nel storage locale di Prometheus per ridurre il consumo di risorse.
Quando installi il Thanos Sidecar sui tuoi Prometheus, devi disattivare questa compattazione dei dati, perché il Thanos Sidecar non può funzionare correttamente se la compattazione dei dati è attiva. Questo significa che il tuo Prometheus inizia a salvare i dati in blocchi di due ore e smette di unire questi blocchi in dimensioni maggiori. Di conseguenza, se effettui richieste che superano la durata delle ultime due ore, queste non funzioneranno in modo altrettanto efficiente, rispetto a come potrebbero se la compattazione dei dati fosse attiva.

Pertanto, Thanos consiglia di ridurre il periodo di conservazione dei dati nel storage locale a 6-8 ore, per diminuire questo overhead di un gran numero di piccoli blocchi.
Dopo aver installato Thanos Sidecar, è necessario installare due componenti per ogni Object Storage Bucket. Questi sono Thanos Compactor e Thanos Store Gateway.

Successivamente, devi installare Thanos Query e configurarlo in modo che possa connettersi a tutti i Thanos Store Gateway che hai, oltre a sapersi collegare a tutti i Thanos Sidecar.
Qui potrebbe esserci un piccolo problema.

È necessario configurare una connessione sicura e affidabile da Thanos Query a questi componenti. E se i tuoi Prometheus si trovano in diversi data center o in diverse VPC, le connessioni esterne sono vietate. Tuttavia, per far funzionare Thanos Query, devi trovare un modo per configurare la connessione.
Se hai molti di questi data center, l'affidabilità dell'intero sistema diminuisce. Thanos Query deve mantenere continuamente le connessioni a tutti i Thanos Sidecar situati in diversi data center. Ad ogni richiesta in ingresso, invierà le richieste a tutti i Thanos Sidecar. Se la connessione si interrompe, riceverai o un set di dati incompleto o la risposta 'cluster non funziona'.

Con VictoriaMetrics tutto è un po' più semplice. Per la versione Single-node, basta avviare un binario e tutto funziona.

Nella versione cluster, è necessario avviare tutti e tre i tipi di componenti menzionati in qualsiasi numero desiderato, oppure utilizzare per automatizzare l'avvio dei componenti in Kubernetes. Abbiamo in programma di creare un operatore Kubernetes. Helm chart non copre alcuni casi e può causare problemi. Ad esempio, consente di ridurre il numero di storage node, il che comporterà una perdita di dati.

Dopo aver avviato un binario oppure la versione cluster, è sufficiente aggiungere alla configurazione di Prometheus , affinché inizi a scrivere i dati contemporaneamente nello storage locale e nello storage remoto. Come avrete notato, questa configurazione dovrebbe funzionare in modo molto più affidabile rispetto a quella di Thanos. Non abbiamo bisogno di mantenere una connessione da VictoriaMetrics a tutti i Prometheus, perché i Prometheus si connettono direttamente a VictoriaMetrics e trasmettono i dati.

Consideriamo il supporto di Thanos e VictoriaMetrics.

Thanos deve monitorare Sidecar per assicurarsi che continui a caricare i dati in Object Storage. Potrebbero interrompere questo caricamento a causa di errori, ad esempio se la connessione di rete con Object Storage viene temporaneamente interrotta o se Object Storage diventa temporaneamente non disponibile. In quel momento, Thanos Sidecar noterà il problema, segnalerà l'errore, potrebbe chiudersi e smettere di funzionare. Se non lo monitori, i dati smetteranno di essere trasferiti in Object Storage. Se trascorre il tempo di retention (6-8 ore raccomandato), perderai i dati che non sono stati salvati in Object Storage.

I compactor di Thanos possono smettere di funzionare a causa di . I compactor prelevano i dati da Object Storage e li uniscono in blocchi più grandi. Poiché i compactor non sono sincronizzati con i Sidecar, può verificarsi quanto segue: il Sidecar non ha ancora completato la scrittura del blocco e il Compactor decide che quel blocco è completamente registrato. Il Compactor inizia a leggerlo. Lo legge in modo incompleto e smette di funzionare. Vedi dettagli. .

Store Gateway può restituire dati incoerenti a causa di race condition tra il Compactor e i Sidecar. Qui succede la stessa cosa, perché il Store Gateway non è sincronizzato con i Compactor e i Sidecar. Di conseguenza, possono verificarsi condizioni di gara in cui il Store Gateway non vede parte dei dati o vede dati extra.

Il componente Query in Thanos restituisce per impostazione predefinita un risultato parziale se alcuni Sidecar o il Store Gateway non sono disponibili al momento. Otterrete parte dei dati, e non saprete nemmeno di aver ricevuto solo una parte. Funziona così per impostazione predefinita. In situazioni simili, VictoriaMetrics restituisce i dati contrassegnati come parziali.

A differenza di Thanos, VictoriaMetrics perde raramente dati. Anche se la connessione tra Prometheus e VictoriaMetrics viene interrotta, non è un problema, poiché Prometheus continua a registrare i nuovi dati in arrivo nel Write Ahead Log, la cui dimensione è di 2 ore. Se entro due ore ripristinate la connessione a VictoriaMetrics, i dati non andranno persi. .

A differenza di Thanos, che registra i dati nell'object storage solo dopo due ore, Prometheus replica automaticamente i dati tramite il protocollo remote write nello storage remoto, come VictoriaMetrics. Non devi preoccuparti di perdere lo storage locale in Prometheus. Se dovesse perdere lo storage locale, nel peggiore dei casi perderai solo gli ultimi secondi di dati che non sono stati registrati nello storage remoto.

Kubernetes gestisce automaticamente il cluster, a differenza di Thanos. Tutti i componenti di Thanos sono complessi da collocare in un unico cluster Kubernetes, a differenza dei componenti cluster di VictoriaMetrics.

Con VictoriaMetrics, l'aggiornamento a una nuova versione è molto semplice. Basta fermare VictoriaMetrics, aggiornare i file binari e riavviarlo. Durante l'arresto tramite il segnale SIGINT, tutti i file binari di VictoriaMetrics eseguono un gracefull shutdown. Salvano correttamente i dati necessari e chiudono le connessioni in ingresso per non perdere nulla. Quindi, non perderai nulla durante l'aggiornamento.

Espandere il cluster di VictoriaMetrics è molto semplice. Basta aggiungere i componenti necessari e continuare a lavorare.

Sugli insidiosi aspetti di Thanos e VictoriaMetrics.

Thanos presenta alcune insidie. Prometheus deve memorizzare i dati delle ultime due ore. Se vengono persi, li perderai completamente, poiché non sono ancora stati salvati nello storage oggetti, come S3.

Il componente Store Gateway e il componente compactor possono richiedere molta memoria per lavorare con un grande Object Storage, se contiene molti file piccoli. Maggiore è il numero e il volume dei file, maggiore è la memoria operativa richiesta da Store Gateway e compactor per memorizzare le informazioni sui metadati. Thanos ha molti problemi al riguardo. .

Thanos viene pubblicizzato come in grado di scalare all'infinito in base al numero dei tuoi Prometheus. In realtà, non è vero. Poiché tutte le richieste passano attraverso il componente Query, che deve interrogare in parallelo tutti i componenti Store Gateway e tutti i componenti Sidecar, estrarre i dati e poi pre-processarli. È ovvio che la velocità delle richieste è limitata dal anello più debole, cioè dal Store Gateway più lento o dal Sidecar più lento.
Questi componenti potrebbero essere caricati in modo non uniforme. Ad esempio, avete un Prometheus che raccoglie milioni di metriche al secondo. E c'è un Prometheus che raccoglie migliaia di metriche al secondo. Il Prometheus che raccoglie milioni di metriche al secondo carica il server su cui è in esecuzione in modo molto più intenso. Di conseguenza, il Sidecar funziona più lentamente. E in generale, tutto lì funziona lentamente. E il componente Query estrarrà i dati da lì molto lentamente. Pertanto, le prestazioni dell'intero cluster saranno limitate da questo Sidecar lento.

Per impostazione predefinita, Thanos restituisce dati parziali se alcuni Sidecar o Store Gateway non sono disponibili. Ad esempio, se i vostri Sidecar sono distribuiti in tutto il mondo in diversi data center, la probabilità di interruzione della connessione e di indisponibilità dei componenti aumenta notevolmente. Pertanto, nella maggior parte dei casi riceverete dati parziali, senza nemmeno saperlo.
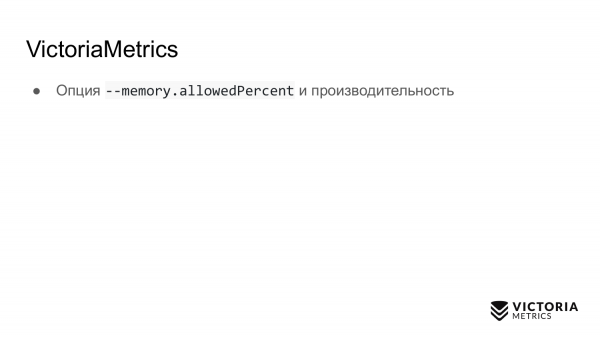
Anche VictoriaMetrics ha le sue insidie. La prima insidia è l'opzione che limita la quantità di memoria RAM utilizzata per la cache di VictoriaMetrics. Per impostazione predefinita, è pari al 60% della memoria RAM sulla macchina in cui è in esecuzione VictoriaMetrics oppure al 60% della RAM del pod VictoriaMetrics in Kubernetes.
Se questo valore viene modificato in modo errato, si può compromettere le prestazioni di VictoriaMetrics. Ad esempio, impostare un valore troppo basso può far sì che i dati non riescano a stare nella cache di VictoriaMetrics. Questo costringerà il sistema a effettuare più lavoro, sovraccaricando la CPU e il disco. Se si imposta questo parametro troppo alto, aumenta, da un lato, la probabilità che VictoriaMetrics si blocchi con un errore di out of memory, e dall'altro, si avrà pochissima memoria RAM disponibile per la cache di file nel sistema operativo. VictoriaMetrics fa affidamento sulla cache di file per le prestazioni. Se è insufficiente, il carico sul disco può aumentare notevolmente. Pertanto, il consiglio è di non modificare il parametro senza una necessità estrema.
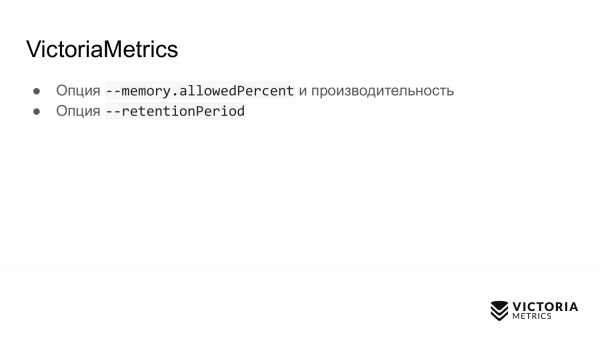
Secondo opzione. Questo è il retentionPeriod — il periodo predefinito impostato su 1 mese. È il tempo durante il quale VictoriaMetrics archivia i dati. Al termine di questo periodo, VictoriaMetrics elimina i dati.
Molti avviano VictoriaMetrics senza questo parametro, registrano i dati per un mese. E poi si chiedono: perché i dati sono scomparsi nel mese precedente? Perché il retentionPeriod predefinito è di 1 mese. Quindi è necessario sapere e impostare il retentionPeriod corretto.

Esploriamo le caratteristiche uniche.

Thanos ha una funzione chiamata downsampling: intervalli di 5 minuti e orari, che spesso . Se si cerca su Google e si guarda alle loro issue su GitHub, ci sono molte questioni relative a questo downsampling, che talvolta funziona in modo errato o non come si aspettano gli utenti.

Thanos ha una deduplicazione dei dati per le coppie Prometheus HA. Quando due Prometheus raccolgono le stesse metriche dagli stessi target e Thanos le accumula nello Object Storage. Thanos sa deduplicare correttamente questi dati, a differenza di VictoriaMetrics.

Thanos ha un componente di alert che era nello schema di Thanos. Ma non è .

Thanos ha il vantaggio che il codice di Thanos e Prometheus è condiviso. Thanos e Prometheus sono stati sviluppati dagli stessi programmatori. Con miglioramenti in Thanos, l'altra parte beneficia anche in Prometheus.

La caratteristica principale di VictoriaMetrics è MetricsQL. Si tratta di un'estensione di VictoriaMetrics per PromQL, di cui ho parlato al recente big monitoring meetup.

VictoriaMetrics supporta il caricamento di dati tramite diversi protocolli. VictoriaMetrics può non solo ricevere dati da Prometheus, ma anche tramite i protocolli Influx, OpenTSDB e Graphite.

I dati di VictoriaMetrics Occupano notevolmente meno spazio rispetto a Thanos e Prometheus.
Se si registrano dati reali, gli utenti segnalano una riduzione delle dimensioni su disco dei dati da 2 a 5 volte rispetto a Prometheus e Thanos.

Un ulteriore vantaggio di VictoriaMetrics è che è ottimizzata per la velocità.

Diamo un'occhiata ai costi dell'infrastruttura.

Uno dei vantaggi di Thanos è che memorizza i dati nel cloud storage, che è relativamente economico.
Quando salvi i dati nello storage a oggetti, devi pagare per le operazioni di scrittura e lettura dei dati (10€ per milione di operazioni). Quando registri dati nello storage a oggetti, copri i costi del tuo hosting per caricare i dati su Internet, a meno che il tuo cluster non si trovi in AWS — lì è gratuito. Quando leggi i dati, paghi da 10 a 230€ per 1TB. Questo può risultare significativo se richiedi frequentemente dati storici dal cluster Thanos.

Per il cluster Thanos è necessario pagare i server per i componenti Compact, Store Gateway, Query, che richiedono molta memoria e CPU per grandi volumi di dati.

I costi per VictoriaMetrics sono i seguenti. Se conservi i dati su dischi HDD GCE, il costo è di 40€ per 1TB. Per VictoriaMetrics sono sufficienti normali dischi HDD, non sono necessari SSD, che costano cinque volte di più. VictoriaMetrics è ottimizzata per gli HDD.

Per VictoriaMetrics sono necessari server per i componenti: o un nodo singolo o per componenti cluster, che richiedono molte meno CPU e RAM rispetto ai componenti Thanos — di conseguenza saranno più economici.

Esempi di implementazione.

Un esempio di implementazione per Thanos è Gitlab. Gitlab funziona completamente su Thanos. Tuttavia, non è tutto così semplice. Se guardi il loro , si può notare che hanno costantemente problemi : manca memoria per i componenti Store Gateway o Query. Devono continuamente aumentare la quantità di memoria.
A causa di ciò, i costi per risolvere questi problemi aumentano.
Un secondo implementazione, che potrebbe avere più successo, è l'azienda Improbable, che ha iniziato a sviluppare Thanos. Hanno pubblicato il codice sorgente di Thanos. Improbable è un'azienda che si occupa dello sviluppo di motori grafici.

VictoriaMetrics presenta esempi pubblici di implementazione:
- wix.com creatore di siti web
- Adidas implementa VictoriaMetrics e ha persino fatto una presentazione all'ultimo PromCon 2019
- TrafficStars — rete pubblicitaria
- Seznam.cz — popolare motore di ricerca ceco.
E poi ci sono aziende sconosciute che non posso nominare adesso. Non hanno dato il loro consenso.
- Un grande sviluppatore di giochi. Più grande di Improbable.
- Un importante sviluppatore di software grafico.
- Una grande banca russa.
- Produttore europeo di turbine eoliche che ha testato con successo VictoriaMetrics. Questo produttore implementa VictoriaMetrics per il monitoraggio dei dati provenienti dalle turbine eoliche a una velocità di 50 campioni al secondo per ogni sensore. Ogni turbina eolica ha centinaia di sensori. Hanno diverse centinaia di turbine eoliche.
- Compagnie aeree russe che desiderano implementare VictoriaMetrics, ma non riescono mai a farlo. Siamo in fase di contratto con loro.
 Conclusioni.
Conclusioni.
VictoriaMetrics e Thanos risolvono problemi simili, ma in modi diversi:
- Vista di query globale
- scalabilità orizzontale
- retention arbitraria

Grazie.
Vi aspettiamo sul nostro .

Solo gli utenti registrati possono partecipare al sondaggio. , per favore.
Cosa usate come storage a lungo termine per Prometheus?
35,3%Thanos6
0,0%Cortex0
0,0%M3DB0
41,2%VictoriaMetrics7
23,5%altro4
Hanno votato 17 utenti. Si sono astenuti 16 utenti.
Fonte: habr.com
