

С 2019 года в России действует закон об обязательной маркировке. Закон распространяется не на все группы товаров, и сроки вступления в силу обязательной маркировки для товарных групп разные. Первыми под обязательную маркировку попадают табак, обувь, лекарства, позднее добавятся и другие товары, например, духи, текстиль, молоко. Это законодательное нововведение побудило к разработке новых ИТ-решений, которые позволят отследить всю цепочку жизни товара с момента производства до покупки конечным потребителем, всем участникам процесса: как само государство, так и все организации, реализующие товары с обязательной маркировкой.
В Х5 система, которая будет отслеживать товары с маркировкой и обмениваться данными с государством и поставщиками, получила название “Маркус”. Расскажем по порядку как и кто ее разрабатывал, какой у нее стек технологий, и почему нам есть чем гордиться.
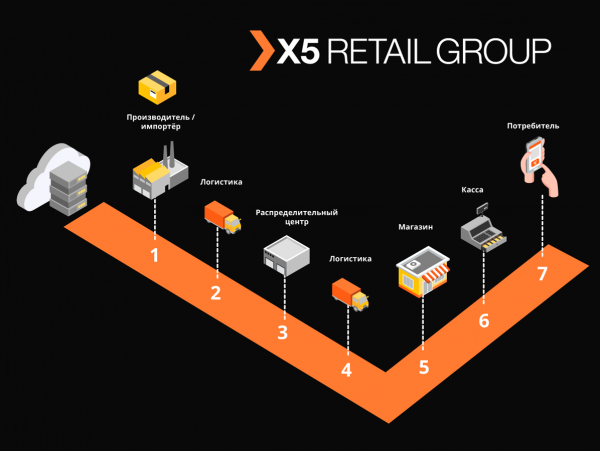
Настоящий HighLoad
“Маркус” решает множество задач, главная из них — интеграционное взаимодействие между информационными системами Х5 и государственной информационной системой маркируемой продукции (ГИС МП) для прослеживания движения маркированной продукции. Также платформа хранит все поступившие к нам коды маркировки и всю историю движения этих кодов по объектам, помогает устранить пересорт маркированной продукции. На примере табачной продукции, которая вошла в первые группы маркированных товаров, только одна фура сигарет содержит порядка 600 000 пачек, каждая из которых имеет свой уникальный код. И задача нашей системы отследить и проверить легальность перемещений каждой такой пачки между складами и магазинами, и в конечном счете проверить допустимость их реализации конечному покупателю. А кассовых операций мы фиксируем порядка 125 000 в час, и ещё надо зафиксировать как каждая такая пачка попала в магазин. Таким образом с учетом всех перемещений между объектами мы ожидаем десятки миллиардов записей в год.
Команда М
Несмотря на то, что «Маркус» считается в рамках Х5 проектом, реализуется он по продуктовому подходу. Команда работает по Scrum. Старт проекта был летом прошлого года, но первые результаты пришли только в октябре — была полностью собрана собственная команда, разработана архитектура системы и куплено оборудование. Сейчас в команде 16 человек, шесть из которых занимаются разработкой backend и frontend, трое системным анализом. Ручным, нагрузочным, автоматизированным тестированием, и сопровождением продукта занимаются еще шесть человек. Помимо этого у нас есть SRE-специалист.
Код в нашей команде пишут не только разработчики, практически все ребята умеют программировать и пишут автотесты, нагрузочные скрипты и скрипты автоматизации. Мы уделяем этому особое внимание, так как даже поддержка продукта требует высокого уровня автоматизации. Коллегам, которые раньше не программировали, всегда стараемся подсказать и помочь, дать в работу какие-то небольшие задачи.
В связи с пандемией коронавирусной инфекции мы перевели всю команду на удаленную работу, наличие всех инструментов для управления разработкой, построенный workflow в Jira и GitLab позволили легко пройти этот этап. Проведенные на удаленке месяцы показали, что производительность команды от этого не пострадала, для многих повысился комфорт в работе, единственное, не хватает живого общения.
Встреча команды до удалёнки

Встречи во время удалёнки
Технологический стек решения
Стандартным репозиторием и инструментом CI/CD для Х5 является GitLab. Мы используем его для хранения кода, непрерывного тестирования, развертывания на тестовых и продуктивных серверах. Также мы используем практику code review, когда как минимум 2 коллегами нужно одобрить вносимые разработчиком изменения в код. Статические анализаторы кода SonarQube и JaCoCo помогают нам держать код чистым и обеспечить требуемый уровень покрытия unit-тестами. Все изменения в коде обязательно должны пройти через эти проверки. Все тестовые сценарии, которые прогоняются вручную, впоследствии автоматизируются.
Для успешного выполнения бизнес-процессов “Маркусом” нам пришлось решить ряд технологических задач, о каждой по порядку.
Задача 1. Необходимость горизонтальной масштабируемости системы
Для решения этой задачи мы выбрали микросервисный подход к архитектуре. При этом было очень важно понять области ответственности сервисов. Мы постарались разделить их по бизнес-операциям с учетом специфики процессов. Например, приемка на складе — это не очень частая, но очень объемная операция, в ходе которой надо максимально быстро получить у госрегулятора информацию о принимаемых единицах товара, количество которых в одной поставке доходит до 600000, проверить допустимость приема этого товара на склад и отдать всю необходимую информацию системе автоматизации склада. А вот отгрузка со складов имеет гораздо большую интенсивность, но при этом оперирует небольшими объемами данных.
Все сервисы мы реализуем по принципу stateless и даже внутренние операции стараемся разделять на шаги, используя, как мы их называем, self-топики Kafka. Это когда микросервис отправляет сообщение сам себе, что позволяет сбалансировать нагрузку по более ресурсоемким операциям и упрощает сопровождение продукта, но об этом позже.
Мы решили выделить в отдельные сервисы модули взаимодействия с внешними системами. Это позволило решить проблему часто изменяющихся API внешних систем, практически без влияния на сервисы с бизнес-функционалом.
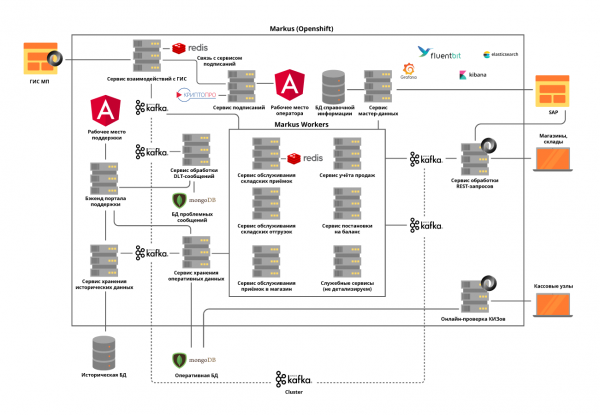
Все микросервисы разворачиваются в кластере OpenShift, который решает как проблему масштабирования каждого микросервиса, так и позволяет нам не использовать сторонние инструменты Service Discovery.
Задача 2. Необходимость поддержания высокой нагрузки и очень интенсивного обмена данными между сервисами платформы: только на фазе запуска проекта выполняется порядка 600 операций в секунду. Мы ожидаем увеличение этого значения до 5000 оп/сек по мере подключения торговых объектов к нашей платформе.
Эту задачу решали развертыванием кластера Kafka и практически полным отказом от синхронного взаимодействия между микросервисами платформы. Это требует очень внимательного анализа требований к системе, так как не все операции могут быть асинхронными. При этом, мы не просто передаем события через брокер, но и передаем в сообщении всю требуемую бизнес-информацию. Таким образом, размер сообщения может доходить до нескольких сотен килобайт. Ограничение на объем сообщений в Kafka требует от нас точного прогнозирования размера сообщений, и, при необходимости, мы их делим, но деление это логическое, связанное с бизнес-операциями.
Например, товар приехавший в автомобиле, мы делим по коробам. Для синхронных операций выделяются отдельные микросервисы и проводится тщательное нагрузочное тестирование. Использование Kafka поставило перед нами другой вызов — проверка работы нашего сервиса с учетом интеграции Kafka делает все наши unit-тесты асинхронными. Эту задачу мы решали написанием собственных утильных методов с использованием Embedded Kafka Broker. Это не отменяет необходимости написания unit-тестов на отдельные методы, но сложные кейсы мы предпочитаем тестировать с использованием Kafka.
Очень много внимания уделили трассировке логов, чтобы их TraceId не терялись при возникновении исключений в ходе работы сервисов или при работе с Kafka batch. И если с первым особых вопросов не возникло, то во втором случае мы вынуждены записать в лог все TraceId, с которыми пришел batch, и выбрать один для продолжения трассировки. Тогда при поиске по изначальному TraceId пользователь легко обнаружит с каким продолжилась трассировка.
Задача 3. Необходимость хранения большого количества данных: более 1 миллиарда маркировок в год только по табаку поступает в X5. К ним требуется постоянный и быстрый доступ. Всего система должна обрабатывать порядка 10 миллиардов записей по истории движения данных маркированных товаров.
Для решения третьей задачи была выбрана NoSQL база MongoDB. У нас построен шард из 5 нод и в каждой ноде Replica Set из 3 серверов. Это позволяет масштабировать систему горизонтально, добавляя nuovi server в кластер, и обеспечить её отказоустойчивость. Тут мы столкнулись с другой проблемой — обеспечение транзакционности в кластере mongo с учетом использования горизонтально масштабируемых микросервисов. Например, одна из задач нашей системы — выявлять попытки повторной продажи товаров с одинаковыми кодами маркировки. Тут появляются накладки с ошибочными сканированиями либо с ошибочными операциями кассиров. Мы обнаружили, что такие дубли могут возникать как внутри одного обрабатываемого batch Kafka, так и внутри двух параллельно обрабатываемых batch. Таким образом проверка на появление дублей путем запроса к базе ничего не давала. Для каждого из микросервисов мы решали проблему отдельно исходя из бизнес-логики этого сервиса. Например, для чеков добавили проверку внутри batch и отдельную обработку на появление дубликатов при вставке.
Чтобы работа пользователей с историей операций никак не влияла на самое главное — функционирование наших бизнес-процессов, все исторические данные мы выделили в отдельный сервис с отдельной базой данных, который также получает информацию через Kafka. Таким образом пользователи работают с изолированным сервисом, не оказывая влияния на сервисы, обрабатывающие данные по текущим операциям.
Задача 4. Повторная обработка очередей и мониторинг:
В распределенных системах неизбежно возникают проблемы и ошибки доступности баз данных, очередей, внешних источников данных. В случае «Маркуса» источником таких ошибок является интеграция с внешними системами. Необходимо было найти решение, позволяющее производить повторные запросы по ошибочным ответам с каким-то заданным таймаутом, но при этом не прекращать обработку успешных запросов в основной очереди. Для этого была выбрана так называемая концепция “topic based retry”. Для каждого основного топика создается один или несколько retry топиков, в которые направляются ошибочные сообщения и при этом исключается задержка на обработку сообщений из основного топика. Схема взаимодействия —
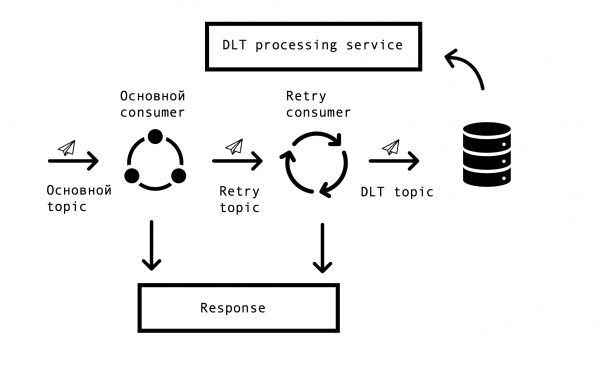
Для реализации такой схемы нам требовалось следующее — интегрировать это решение со Spring и избежать дублирования кода. На просторах сети мы наткнулись на подобное решение, основанное на Spring BeanPostProccessor, но оно показалось нам излишне громоздким. Нашей командой было сделано более простое решение, позволяющее встроиться в цикл Spring по созданию consumer и дополнительно добавлять Retry Consumer-ы. Прототип нашего решения мы предложили команде Spring, посмотреть его можно . Количество Retry Consumer-ов и количество попыток каждого consumer-a настраивается через параметры, в зависимости от потребностей бизнес-процесса, и, чтобы все заработало, остается лишь поставить знакомую всем Spring-разработчикам аннотацию org.springframework.kafka.annotation.KafkaListener.
В случае если сообщение не могло быть обработано после всех retry попыток, оно попадает в DLT (dead letter topic) с помощью Spring DeadLetterPublishingRecoverer. По просьбе поддержки, мы расширили данный функционал и сделали отдельный сервис, который позволяет просматривать попавшие в DLT сообщения, stackTrace, traceId и другую полезную информацию по ним. Кроме того, были добавлены мониторинги и алерты на все DLT топики, и сейчас, по сути, появление сообщения в DLT топике является поводом для разбора и заведения дефекта. Это очень удобно — по названию топика мы сразу понимаем, на каком шаге процесса возникла проблема, что значительно ускоряет поиск ее корневой причины.

Совсем недавно мы реализовали интерфейс, позволяющий повторно отправить сообщения силами нашей поддержки, после устранения их причин (например, восстановление работоспособности внешней системы) и, конечно, заведения соответствующего дефекта для анализа. Тут и пригодились наши self-топики, чтобы не перезапускать длинную цепочку обработки, можно перезапустить ее с нужного шага.
Эксплуатация платформы
Платформа уже находится в продуктивной эксплуатации, каждый день мы проводим поставки и отгрузки, подключаем новые распределительные центры и магазины. В рамках пилота система работает с группами товаров “Табак” и “Обувь”.
Вся наша команда участвует в проведении пилотов, анализирует возникающие проблемы и вносит предложения по усовершенствованию нашего продукта от улучшения логов до изменения в процессах.
Чтобы не повторять своих ошибок, все кейсы найденные в ходе пилота находят свое отражение в автоматизированных тестах. Наличие большого количества автотестов и unit-тестов позволяют проводить регрессионное тестирование и ставить хотфикс буквально в течении нескольких часов.
Сейчас мы продолжаем развивать и совершенствовать нашу платформу, и постоянно сталкиваемся с новыми вызовами. Если вам будет интересно, то мы расскажем о наших решениях в следующих статьях.
Fonte: habr.com
