

In Abbiamo parlato di previsione delle serie temporali. Una logica continuazione sarebbe un articolo sulla rilevazione delle anomalie.
Applicazione
La rilevazione delle anomalie è utilizzata in settori come:
1) Previsione dei guasti delle apparecchiature
Nel 2010, le centrifughe iraniane furono attaccate dal virus Stuxnet, che impostò un regime operativo non ottimale, causando il deterioramento di parte dell'attrezzatura per usura accelerata.
Se sull'attrezzatura fossero stati utilizzati algoritmi di rilevazione delle anomalie, si sarebbero potute evitare situazioni di guasto.

La ricerca delle anomalie nelle apparecchiature è utilizzata non solo nell'industria nucleare, ma anche nella metallurgia e nel funzionamento delle turbine aeronautiche. E in altri settori dove l'uso della diagnostica predittiva è più conveniente rispetto alle possibili perdite causate da guasti imprevisti.
2) Previsione delle attività fraudolente
Se dalla carta che utilizzi a Podol'sk vengono prelevati soldi in Albania, è possibile che le transazioni debbano essere controllate ulteriormente.
3) Rilevazione di modelli di consumo anomali
Se una parte dei clienti mostra un comportamento anomalo, potrebbe esserci un problema di cui non sei a conoscenza.
4) Identificazione della domanda e del carico anomali
Se le vendite nel negozio FMCG scendono sotto la soglia dell'intervallo di confidenza della previsione, è opportuno cercare la causa di questo fenomeno.
Approcci per l'identificazione delle anomalie
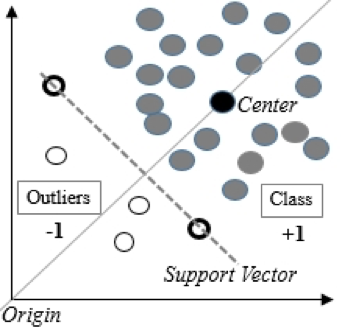
1) Metodo dei support vector con una sola classe One-Class SVM
Adatto quando i dati nel set di addestramento seguono una distribuzione normale, mentre nel test contengono anomalie.
Il metodo One-Class SVM costruisce una superficie non lineare attorno all'origine. È possibile impostare un confine per determinare quali dati considerare anomali.
Secondo l'esperienza del nostro team di DATA4, One-Class SVM è l'algoritmo più comunemente utilizzato per risolvere il problema della ricerca delle anomalie.
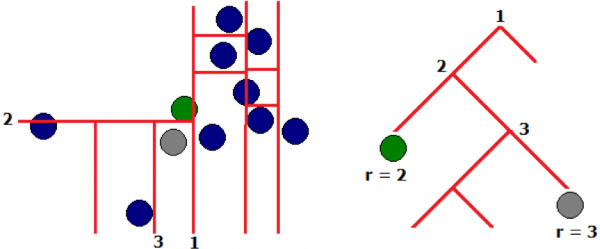
2) Metodo dell'isolamento degli alberi – isolate forest
Con il metodo di costruzione casuale degli alberi, i valori anomali verranno collocati in foglie nelle prime fasi (a bassa profondità dell'albero), il che rende più facile 'isolare' le anomalie. L'identificazione dei valori anomali avviene nelle prime iterazioni dell'algoritmo.
3) Elliptic envelope e metodi statistici
Utilizzato quando i dati sono distribuiti normalmente. Più la misura si avvicina alla coda della distribuzione, più il valore è anomalo.
A questa classe possono essere attribuiti anche altri metodi statistici.
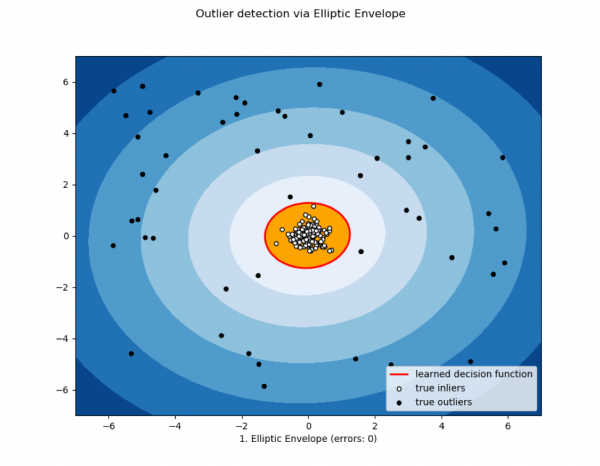
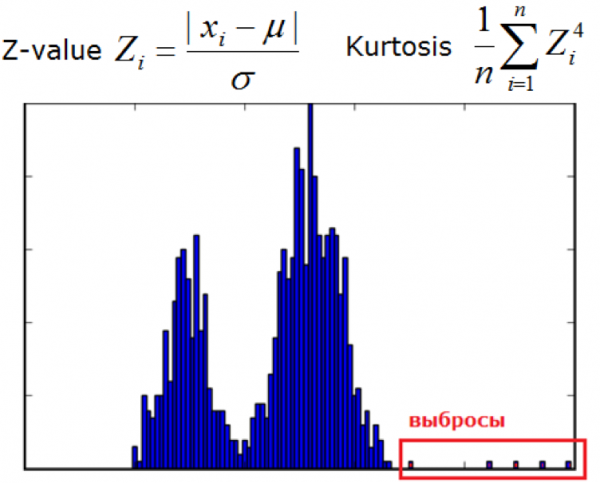
Immagine dal sito dyakonov.org
4) Metodi metrici
I metodi includono algoritmi come k vicini più prossimi, k-esimo vicino, ABOD (rilevamento di outlier basato su angoli) o LOF (fattore di outlier locale).
Adatti se la distanza tra i valori nelle caratteristiche è equivalente o normalizzata (per non misurare un serpente in pappagalli).
L'algoritmo k vicini più prossimi presuppone che i valori normali siano collocati in un'area definita dello spazio multidimensionale, e che la distanza dagli outlier sarà maggiore rispetto al piano iperbolico di separazione.
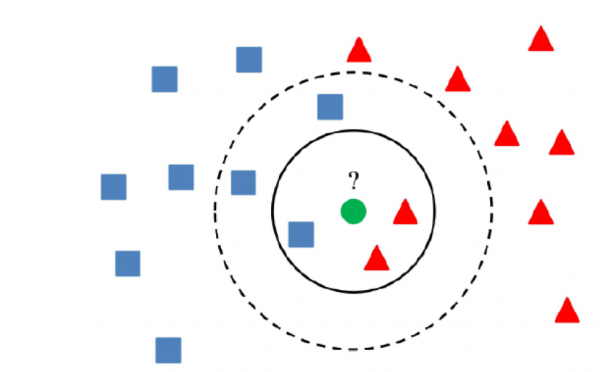
5) Metodi di clustering
La sostanza dei metodi di clustering è che se un valore è lontano dai centri dei cluster oltre una certa soglia, il valore può essere considerato anomalo.
È fondamentale utilizzare un algoritmo che clusterizzi correttamente i dati, il che dipende dal compito specifico.
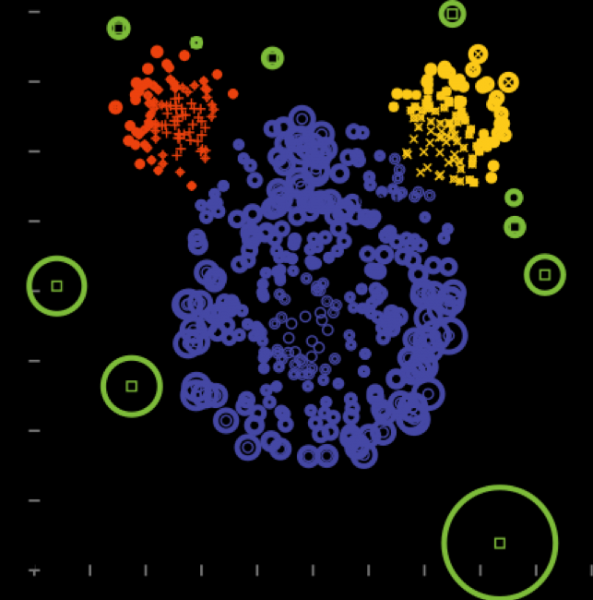
6) Metodo delle componenti principali
Adatto quando si evidenziano le direzioni di massima variazione nella varianza.
7) Algoritmi basati su previsioni di serie temporali
L'idea è che se un valore esce dall'intervallo di confidenza previsto, viene considerato anomalo. Per prevedere una serie temporale, si utilizzano algoritmi come il livellamento triplo, S(ARIMA), boosting, ecc.
Nell'articolo precedente si è parlato degli algoritmi di previsione delle serie temporali.
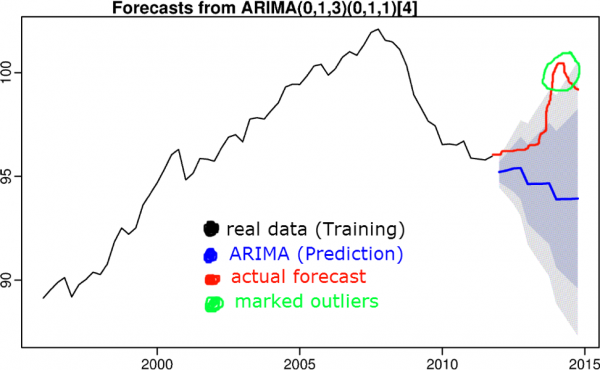
8) Apprendimento supervisionato (regressione, classificazione)
Se i dati lo consentono, utilizziamo algoritmi che spaziano dalla regressione lineare alle reti ricorrenti. Misureremo la differenza tra la previsione e il valore reale e tireremo conclusioni su quanto i dati si discostano dalla norma. È importante che l'algoritmo abbia una sufficiente capacità di generalizzazione e che il campione di addestramento non contenga valori anomali.
9) Test di modello
Affronteremo il compito di rilevare anomalie come un problema di raccomandazione. Scomporremo la nostra matrice di caratteristiche utilizzando SVD o macchine di fattorizzazione, e i valori nella nuova matrice che si discostano significativamente dagli originali saranno considerati anomali.
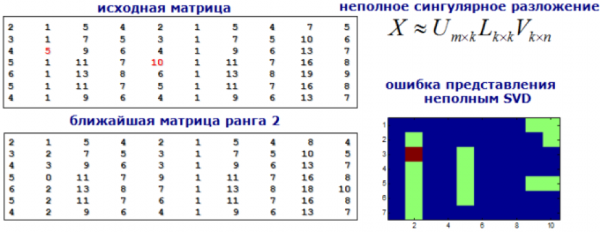
Immagine dal sito dyakonov.org
Conclusione
In questo articolo abbiamo esaminato i principali approcci per la rilevazione delle anomalie.
La ricerca delle anomalie può essere definita un'arte. Non esiste un algoritmo o un approccio perfetto il cui utilizzo risolva ogni problema. Di solito si utilizza un insieme di metodi per affrontare casi specifici. La ricerca delle anomalie viene effettuata utilizzando il metodo dei vettori di supporto a classe unica, foreste isolate, metodi metrici e di clustering, nonché impiegando le componenti principali e la previsione delle serie temporali.
Se conosci altri metodi, scrivili nei commenti all'articolo.
Fonte: habr.com
