

Google ha presentato un nuovo codec audio Lyra, ottimizzato per garantire la massima qualità nella trasmissione della voce anche su canali di comunicazione molto lenti. Il codice sorgente di Lyra è scritto in C++ ed è rilasciato sotto licenza Apache 2.0, ma tra le dipendenze necessarie per il funzionamento è inclusa una libreria proprietaria libsparse_inference.so che implementa il core per i calcoli matematici. Si segnala che la libreria proprietaria è temporanea: in futuro Google promette di sviluppare una sostituzione open source e garantire supporto per diverse piattaforme.
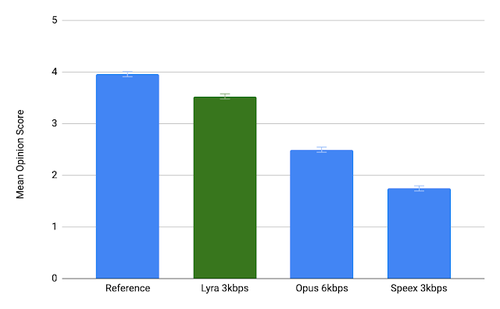
In termini di qualità del suono vocale trasmesso a basse velocità, Lyra supera significativamente i codec tradizionali che utilizzano metodi di elaborazione digitale del segnale. Per garantire un'elevata qualità nella trasmissione della voce in condizioni di limitata larghezza di banda, oltre ai consueti metodi di compressione audio e di conversione dei segnali, Lyra utilizza un modello vocale basato su un sistema di apprendimento automatico che consente di ricostruire le informazioni mancanti sulla base delle caratteristiche tipiche della parola. Il modello impiegato per la generazione del suono è stato addestrato utilizzando migliaia di ore di registrazioni vocali in oltre 70 lingue.
Il codec comprende un codificatore e un decodificatore. L'algoritmo di funzionamento del codificatore si basa sull'estrazione dei parametri dei dati vocali ogni 40 millisecondi, sulla loro compressione e sull'invio al ricevente tramite rete. Per trasmettere i dati è sufficiente un canale di comunicazione con una velocità di 3 kilobit al secondo. I parametri audio estratti includono spettrogrammi mel-logaritmici, che considerano le caratteristiche dell'energia della voce in vari intervalli di frequenza e sono preparati tenendo conto del modello di percezione uditiva umana.
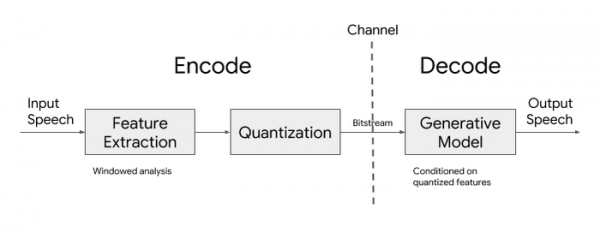
Nel decodificatore viene utilizzato un modello generativo, che ricostruisce il segnale vocale sulla base dei parametri audio trasmessi. Per ridurre la complessità dei calcoli, è stato impiegato un modello leggero basato su una rete neurale ricorrente, che rappresenta una variante del modello di sintesi vocale WaveRNN, in cui viene utilizzata una frequenza di campionamento inferiore, ma vengono generati contemporaneamente più segnali in diverse gamme di frequenza. I segnali ottenuti vengono poi sovrapposti per ottenere un unico segnale di output, corrispondente alla frequenza di campionamento specificata.
Per accelerare sono state applicate istruzioni di processore specializzate, disponibili nei processori ARM a 64 bit. Di conseguenza, nonostante l'uso dell'apprendimento automatico, il codec Lyra può essere utilizzato per codificare e decodificare l'audio in tempo reale su smartphone di fascia media, mostrando una latenza di trasmissione del segnale di 90 millisecondi.
Fonte: opennet.ru
