

L'originale dell'articolo è pubblicato sul sito ed è stato pubblicato su 3DNews con il permesso dell'autore. Presentiamo il testo completo dell'articolo, ad eccezione di un gran numero di link — questi saranno utili a chi è seriamente interessato all'argomento e desidera approfondire gli aspetti teorici della fotografia computazionale, ma per un pubblico più ampio abbiamo ritenuto che questo materiale fosse superfluo.
Oggi nessuna presentazione di uno smartphone può prescindere dall'analizzare la sua fotocamera. Ogni mese sentiamo di un nuovo successo delle fotocamere mobile: Google insegna al Pixel a scattare foto al buio, Huawei zoomma come un binocolo, Samsung integra il lidar e Apple realizza gli angoli più arrotondati al mondo. È raro che l'innovazione scorra così abbondantemente in altri settori.
Le reflex digitali, nel frattempo, sembrano stagnare. Sony ogni anno sorprende tutti con nuovi sensori, mentre i produttori aggiornano pigramente solo l'ultima cifra della versione e continuano a fumare relax in disparte. Ho una reflex sul tavolo che costa $3000, ma quando viaggio porto con me l'iPhone. Perché?
Come diceva un classico — sono andato su internet con questa domanda. Lì discutono di qualche «algoritmo» e «reti neurali», senza avere la minima idea di come influenzino specificamente la fotografia. I giornalisti leggono ad alta voce il numero di megapixel, i blogger si affrettano a pubblicare unboxing sponsorizzati, mentre gli esteti si avvolgono nella «percezione sensoriale della tavolozza dei colori del sensore». Tutto come al solito.
Ho dovuto sedermi, spendere metà della vita e capire tutto da solo. In questo articolo racconterò cosa ho scoperto.
Che cos'è la fotografia computazionale?
Ovunque, incluso Wikipedia, danno una definizione simile: la fotografia computazionale è qualsiasi tecnica di cattura e lavorazione delle immagini in cui, anziché le trasformazioni ottiche, si utilizzano calcoli digitali. In essa tutto è buono, tranne il fatto che non spiega nulla. Anche l'autofocus rientra in questa definizione, ma non la plenottica, che ci ha già portato molte cose utili. L'ammaliante vaghezza delle definizioni ufficiali sembra suggerire che non abbiamo idea di cosa stiamo parlando.
Il pioniere della fotografia computazionale, il professor della Stanford University Marc Levoy (che ora è anche responsabile della fotocamera di Google Pixel), fornisce un'altra definizione: un insieme di metodi di visualizzazione computazionale che migliorano o ampliano le capacità della fotografia digitale, utilizzando i quali si ottiene una fotografia normale che non potrebbe essere tecnicamente catturata con quella macchina fotografica nel modo tradizionale. In questo articolo mi attengo proprio alla sua definizione.
Quindi, la colpa è stata degli smartphone.
Gli smartphone non avevano altra scelta se non dare vita a un nuovo tipo di fotografia: la fotografia computazionale.
I loro piccoli sensori rumorosi e le minuscole lenti a bassa luminosità, secondo tutte le leggi della fisica, avrebbero dovuto portare solo dolore e sofferenza. E lo facevano, finché i loro sviluppatori non hanno trovato un modo astuto per sfruttare i loro punti di forza per superare i punti deboli: otturatori elettronici veloci, potenti processori e software.

La maggior parte delle ricerche significative nel campo della fotografia computazionale risale al 2005-2015, un periodo che nel mondo scientifico è considerato quasi come ieri. Proprio ora, sotto i nostri occhi e nelle nostre tasche, si sta sviluppando un nuovo campo di conoscenze e tecnologie che non è mai esistito prima.
La fotografia computazionale non è solo un selfie con il neuro-bokeh. La recente fotografia di un buco nero non sarebbe stata realizzata senza i metodi della fotografia computazionale. Per scattare una foto del genere con un normale telescopio, avremmo dovuto costruirne uno delle dimensioni della Terra. Tuttavia, unendo i dati di otto radiotelescopi in diverse parti del nostro pianeta e scrivendo un po' di codice in Python, abbiamo ottenuto la prima fotografia al mondo dell'orizzonte degli eventi. Anche per i selfie può andar bene.

Inizio: elaborazione digitale
Immaginiamo di essere tornati al 2007. La nostra mamma è anarchia, e le nostre fotografie sono rumorosi JPEG da 0,6 MP scattati su uno skateboard. Circa in quel periodo nasce il primo irresistibile desiderio di applicare dei preset per nascondere l'ineleganza dei sensori mobili. Non limitiamoci.

Matan e Instagram
Con l'arrivo di Instagram, tutti sono impazziti per i filtri. Come persona che un tempo ha fatto reverse engineering di X-Pro II, Lo-Fi e Valencia, ovviamente per scopi di ricerca (eheh), ricordo ancora che erano composti da tre componenti:
- Impostazioni colore (Tonality, Saturazione, Luminosità, Contrasto, Livelli, ecc.) — coefficienti digitali semplici, proprio come in qualsiasi preset che i fotografi usano da tempi remoti.
- Mappe di tonalità (Tone Mapping) — vettori di valori, ognuno dei quali ci diceva: «Il colore rosso con tono 128 deve essere trasformato nel tono 240».
- Overlay — un'immagine semitrasparente con polvere, grana, vignettatura e tutto il resto che si può sovrapporre per ottenere un effetto di vecchia pellicola che non è affatto banale. Non era sempre presente.
I filtri moderni non si sono allontanati molto da questo trio, sono solo diventati un po' più complessi dal punto di vista matematico. Con l'arrivo dei shader hardware e di OpenCL sugli smartphone, sono stati rapidamente adattati per la GPU, ed era considerato davvero fantastico. Per il 2012, certo. Oggi qualsiasi studente delle scuole superiori può creare qualcosa di simile con CSS e non gli verrà nemmeno riconosciuto al diploma.
Tuttavia, il progresso dei filtri non si è fermato oggi. I ragazzi di Dehancer, ad esempio, stanno facendo grandi cose con i filtri non lineari: invece di utilizzare la mappatura tonale proletaria, stanno impiegando trasformazioni non lineari più complesse, che, a loro avviso, aprono molte più possibilità.
Con le trasformazioni non lineari si possono fare molte cose, ma sono incredibilmente complesse, e noi, esseri umani, siamo incredibilmente stupidi. Quando si tratta di trasformazioni non lineari, preferiamo ricorrere ai metodi numerici e riempire tutto di reti neurali, affinché scrivano capolavori al nostro posto. La stessa cosa è accaduta qui.
Automatica e sogni del pulsante «capolavoro»
Quando tutti si erano abituati ai filtri, abbiamo iniziato a integrarli direttamente nelle fotocamere. La storia nasconde chi sia stato il primo produttore, ma solo per capire quanto tempo sia passato: con iOS 5.0, uscito nel 2011, esisteva già un'API pubblica per l'Auto Enhancing Images. Solo Jobs sa quanto a lungo sia stata utilizzata prima di essere aperta al pubblico.
L'automazione faceva ciò che ognuno di noi faceva aprendo una foto nell'editor: estraeva i dettagli nelle luci e nelle ombre, regolava la saturazione, rimuoveva gli occhi rossi e correggeva il tono della pelle. Gli utenti nemmeno si rendevano conto che la "camera drammaticamente migliorata" nel nuovo smartphone era solo merito di un paio di nuovi shader. Mancavano ancora cinque anni all'uscita di Google Pixel e all'inizio del boom della fotografia computazionale.

Oggi la battaglia per il pulsante "capolavoro" si è trasferita nel campo del machine learning. Dopo aver giocato con il tone mapping, tutti si sono messi a addestrare CNN e GAN per muovere i cursori al posto dell'utente. In altre parole, si tratta di determinare, in base all'immagine in entrata, un insieme di parametri ottimali che avvicinassero l'immagine a una certa comprensione soggettiva di "buona fotografia". Questo è implementato nello stesso Pixelmator Pro e in altri editor. Funziona, come si può immaginare, non sempre e non bene.
Il stacking è il 90% del successo delle fotocamere mobili.
La vera fotografia computazionale è iniziata con il stacking: sovrapporre più foto l'una sull'altra. Per uno smartphone non è un problema scattare una dozzina di scatti in mezzo secondo. Nelle loro fotocamere non ci sono parti meccaniche lente: l'apertura è fissa e al posto di un otturatore meccanico c'è un otturatore elettronico. Il processore semplicemente ordina al sensore per quanti microsecondi deve catturare i fotoni selvaggi e legge il risultato.
Tecnicamente, il telefono può scattare foto alla velocità di un video e registrare video con risoluzione fotografica, ma tutto dipende dalla velocità del bus e del processore. Pertanto, vengono sempre impostati limiti software.
Il stacking è con noi da molto tempo. Anche i nostri nonni usavano plugin su Photoshop 7.0 per assemblare più foto in un HDR strabiliante o unire una panoramica di 18000 × 600 pixel e… in realtà nessuno ha ancora capito cosa farne dopo. Erano tempi d'oro, peccato, selvaggi.
Ora siamo cresciuti e chiamiamo questo «fotografia epsilon» — quando, modificando uno dei parametri della fotocamera (esposizione, messa a fuoco, posizione) e unendo i frame ottenuti, otteniamo qualcosa che non potrebbe essere catturato in un'unica inquadratura. Ma questo è un termine per i teorici; nella pratica si è affermato un altro nome: stacking. Oggi, di fatto, su di esso si basa il 90% di tutte le innovazioni nelle fotocamere dei telefoni cellulari.

Una cosa a cui molti non pensano, ma che è importante per comprendere tutta la fotografia mobile e computazionale: la fotocamera di uno smartphone moderno inizia a scattare foto non appena apri la sua applicazione. È logico, deve infatti trasmettere l'immagine sullo schermo. Tuttavia, oltre allo schermo, conserva fotogrammi ad alta risoluzione nel proprio buffer circolare, dove li mantiene per qualche secondo in più.
Quando premi il pulsante «scatta foto», in realtà è già stata scattata; la fotocamera prende semplicemente l'ultima foto dal buffer.
Oggi qualsiasi fotocamera mobile funziona in questo modo. Almeno in tutti i modelli di punta, non in quelli di fascia bassa. La bufferizzazione consente di realizzare non solo una ritardo dell’otturatore pari a zero, che i fotografi sognano da tempo, ma persino un ritardo negativo: quando si preme il pulsante, lo smartphone guarda indietro, carica 5-10 ultime foto dalla memoria temporanea e inizia a analizzarle freneticamente e a unirle. Non è più necessario aspettare che il telefono catturi le immagini per HDR o la modalità notturna: basta prenderle dalla memoria, l'utente non se ne accorgerà nemmeno.
A proposito, proprio grazie al ritardo negativo dell’otturatore è stata realizzata la funzione Live Photo sugli iPhone, mentre in HTC qualcosa di simile esisteva già nel 2013 con il curioso nome di Zoe.
Il stacking per esposizione — HDR e lotta con i contrasti di luminosità.

Le matrici delle fotocamere sono in grado di catturare tutta la gamma di luminosità visibile ai nostri occhi? Questo è un tema di vecchia data che scatena dibattiti accesi. Alcuni dicono di no, poiché l'occhio umano può vedere fino a 25 stop di esposizione, mentre anche il miglior sensore full-frame riesce a estrarre un massimo di 14. Altri criticano il confronto, affermando che l'occhio è aiutato dal cervello, che regola automaticamente la pupilla e completa l'immagine attraverso le proprie reti neurali, e che il vero intervallo dinamico dell'occhio è di fatto compreso tra 10 e 14 stop. Lasciamo queste discussioni ai migliori pensatori da divano su Internet.
Il fatto è semplice: quando si fotografano amici contro un cielo luminoso senza HDR con un qualsiasi smartphone, si ottiene o un cielo normale con volti scuri, oppure amici ben definiti ma con un cielo completamente bruciato.
La soluzione è da tempo conosciuta: ampliare la gamma di luminosità con l'HDR (High Dynamic Range). È necessario scattare alcune foto con esposizioni diverse e unirle insieme. Una dovrebbe essere "normale", la seconda un po' più chiara e la terza più scura. Prendiamo i punti scuri dalla foto più chiara, e i bianchi stravolti li riempiamo dalla foto scura — profitto. Resta solo da risolvere il problema del bracketing automatico: quanto spostare l'esposizione di ciascun scatto per non esagerare? Un secondo anno di università tecnica sarebbe già in grado di determinare la media della luminosità dell'immagine.

Sugli ultimi iPhone, Pixel e Galaxy, la modalità HDR si attiva automaticamente quando un semplice algoritmo all'interno della fotocamera riconosce che stai fotografando qualcosa di contrastante in una giornata di sole. Puoi persino notare come il telefono cambi la modalità di registrazione in buffer per salvare gli scatti con esposizioni spostate: i fotogrammi al secondo (fps) diminuiscono e l'immagine diventa più vivace. Il momento del passaggio è ben evidente sul mio iPhone X, specialmente quando scatto all'aperto. Fai attenzione al tuo smartphone la prossima volta!
L'assenza di HDR con bracketing dell'esposizione è la sua inesorabile impotenza in condizioni di scarsa illuminazione. Anche con la luce di una lampada da tavolo, le immagini risultano così scure che il computer non riesce a bilanciarle e unirle. Per risolvere i problemi di illuminazione, nel 2013 Google ha presentato un approccio diverso all'HDR con lo smartphone Nexus lanciato in quel periodo, utilizzando il stacking temporale.
Stacking temporale — simulazione di un'esposizione lunga e time-lapse.

Lo stacking temporale consente di ottenere un'esposizione lunga tramite una serie di esposizioni brevi. I pionieri furono gli appassionati di fotografia che intendevano catturare i sentieri delle stelle nel cielo notturno, trovando scomodo mantenere il diaframma aperto per due ore. Era difficile calcolare in anticipo tutte le impostazioni e anche la minima vibrazione rovinava l'intero scatto. Hanno deciso di aprire il diaframma solo per qualche minuto, ma molte volte, e poi tornare a casa e assemblare gli scatti in Photoshop.

Quindi, la fotocamera non ha mai realmente scattato a lunga esposizione, ma abbiamo ottenuto un effetto di imitazione sovrapponendo più scatti consecutivi. Per smartphone esistono già da tempo molte applicazioni che utilizzano questo trucco, ma tutte non sono necessarie da quando questa funzionalità è stata aggiunta quasi a tutte le fotocamere standard. Oggi anche un iPhone può facilmente creare per voi una lunga esposizione da una Live Photo.

Torniamo a Google con il suo HDR notturno. Si è scoperto che, utilizzando il bracketing temporale, è possibile realizzare un buon HDR al buio. Questa tecnologia è apparsa per la prima volta nel Nexus 5 ed era chiamata HDR+. Altri telefoni Android l'hanno ricevuta come un regalo. La tecnologia è ancora così popolare che viene vantata anche nelle presentazioni dell'ultimo Pixel.
L'HDR+ funziona in modo piuttosto semplice: identificando che stai scattando al buio, la fotocamera scarica dalla memoria 8-15 delle ultime foto in RAW per sovrapporle. In questo modo, l'algoritmo raccoglie più informazioni sulle aree scure dell'immagine per ridurre al minimo il rumore: quei pixel in cui, per un motivo o per l'altro, la fotocamera non è riuscita a raccogliere tutte le informazioni e ha fatto un errore.
Come se non sapeste come appare un capibara e aveste chiesto a cinque persone di descriverlo: le loro storie sarebbero circa simili, ma ognuno menzionerebbe un dettaglio unico. Così raccogliereste più informazioni rispetto a chiedere a uno solo. Lo stesso vale per i pixel.
Sommare le immagini scattate da un'unica posizione produce lo stesso effetto fasullo di un'esposizione lunga come quella delle stelle sopra. L'esposizione di decine di scatti si accumula, mentre gli errori in uno si minimizzano negli altri. Immaginate quante volte bisognerebbe premere l'otturatore della reflex per ottenere un simile risultato.

Restava solo da risolvere il problema della correzione automatica dei colori: le immagini scattate al buio risultano generalmente gialle o verdi, mentre noi vogliamo la vivacità della luce diurna. Nelle versioni iniziali di HDR+, questo veniva risolto semplicemente regolando le impostazioni, come nei filtri tipo Instagram. Successivamente, si è fatto ricorso a reti neurali.
E così è nata Night Sight — la tecnologia per la "fotografia notturna" nei Pixel 2 e 3. Nel suo descrittivo si afferma: "Tecniche di apprendimento automatico costruite su HDR+, che rendono Night Sight funzionale". In sostanza, si tratta di un'automatizzazione del processo di correzione del colore. La macchina è stata addestrata su un dataset di foto "prima" e "dopo", in modo da trasformare un insieme di scatti scuri in una bella immagine.

A proposito, il dataset è stato reso disponibile al pubblico. Chissà, magari i ragazzi di Apple lo utilizzeranno per insegnare finalmente alle loro fotocamere di vetro a scattare decentemente al buio.
In aggiunta, Night Sight utilizza il calcolo del vettore di movimento degli oggetti nella scena per normalizzare le vibrazioni, che inevitabilmente si verificano con esposizioni lunghe. In questo modo, lo smartphone può prendere parti chiare da altri scatti e unirle.
Stacking per il movimento — panorami, super zoom e lotta contro il rumore.

Il panorama è un passatempo popolare tra gli abitanti delle zone rurali. Attualmente non si conoscono casi in cui una "salsiccina" fotografica sia risultata interessante per qualcuno al di fuori del suo autore, ma è impossibile non menzionarla — per molti, è da qui che è iniziato tutto lo stacking.

Il primo utile modo di applicare la panoramica è ottenere una fotografia con una risoluzione superiore a quella consentita dal sensore della fotocamera, unendo più scatti. I fotografi utilizzano da tempo diversi software per le così dette fotografie con superrisoluzione, quando foto leggermente spostate si integrano tra i pixel. In questo modo è possibile ottenere un'immagine di addirittura centinaia di gigapixel, cosa molto utile se si desidera stamparla su un manifesto pubblicitario delle dimensioni di una casa.
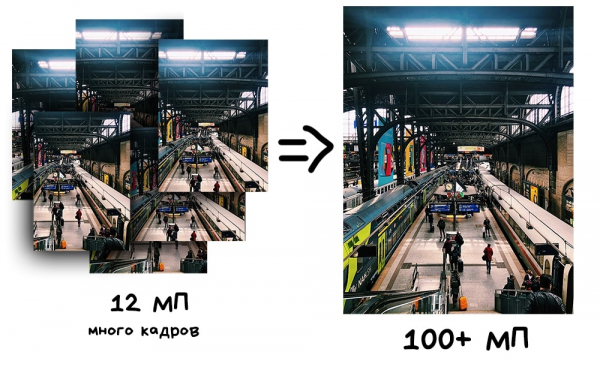
Un altro approccio, già più interessante, è lo Pixel Shifting. Alcune fotocamere mirrorless come Sony e Olympus hanno iniziato a supportarlo già dal 2014, ma il risultato doveva comunque essere unito manualmente. Tipiche innovazioni delle grandi fotocamere.
Gli smartphone, invece, hanno avuto successo qui per una ragione divertente: quando scatti una foto, le tue mani tremano. Questo problema, a prima vista, è alla base dell'implementazione della superrisoluzione nativa sugli smartphone.
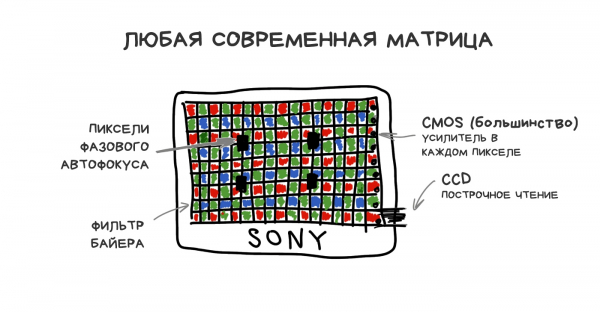
Per comprendere come funziona, bisogna ricordare come è strutturato il sensore di qualsiasi fotocamera. Ogni suo pixel (fotodiodo) è in grado di rilevare solo l'intensità della luce, cioè la quantità di fotoni che vi arriva. Tuttavia, un pixel non può misurare il suo colore (lunghezza d'onda). Per ottenere un'immagine RGB, è stato necessario adottare delle soluzioni creative: coprire l'intero sensore con una rete di vetri colorati. La sua realizzazione più popolare è conosciuta come il filtro Bayer ed è oggi utilizzata nella maggior parte dei sensori. Si presenta come nell'immagine sottostante.
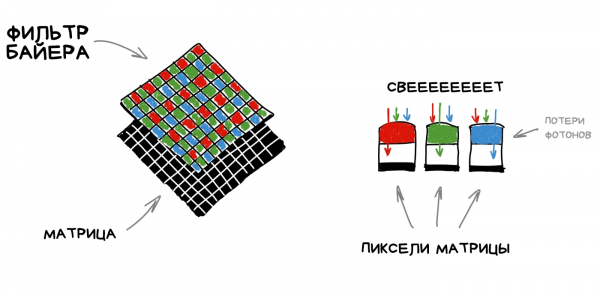
Di conseguenza, ogni pixel del sensore acquisisce solo la componente R-, G- o B-, poiché gli altri fotoni vengono spietatamente riflessi dal filtro Bayer. Le componenti mancanti sono calcolate tramite una semplice media dei valori dei pixel adiacenti.
Ci sono più celle verdi nel filtro Bayer, realizzato per analogia con l'occhio umano. Così, su 50 milioni di pixel nel sensore, 25 milioni rileveranno il colore verde, mentre rosso e blu ne cattureranno 12,5 milioni ciascuno. Il resto sarà mediato: questo processo è chiamato debayerizzazione o demosaicizzazione, ed è una sorta di imperfetta ma divertente soluzione su cui si basa tutto.
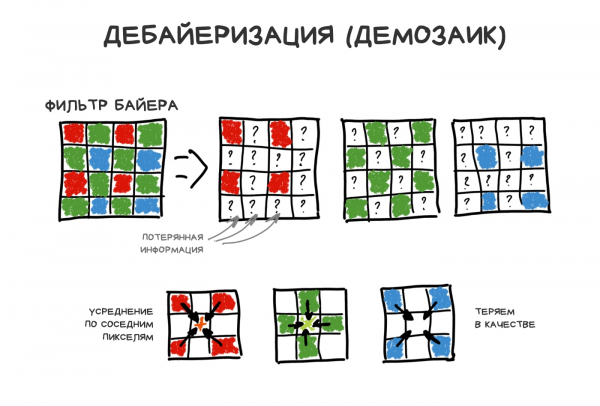
In realtà, ogni matrice ha il suo astuto algoritmo di demosaicizzazione brevettato, ma in questa storia possiamo trascurarlo.
Altri tipi di matrici (come il Foveon) non si sono ancora davvero affermati. Anche se alcuni produttori tentano di utilizzare matrici senza filtro Bayer per migliorare la nitidezza e il intervallo dinamico.
Quando c'è poca luce o i dettagli dell'oggetto sono molto piccoli, perdiamo un sacco di informazioni perché il filtro Bayer taglia con arroganza i fotoni con lunghezze d'onda non gradite. Per questo motivo è stato inventato il Pixel Shifting: spostare la matrice di 1 pixel su, giù, a destra e a sinistra per catturarli tutti. La fotografia non risulta quindi quattro volte più grande, come potrebbe sembrare, ma il processore utilizza questi dati per registrare con maggiore precisione il valore di ogni pixel. In pratica media non tra i vicini, ma tra i quattro valori di se stesso.
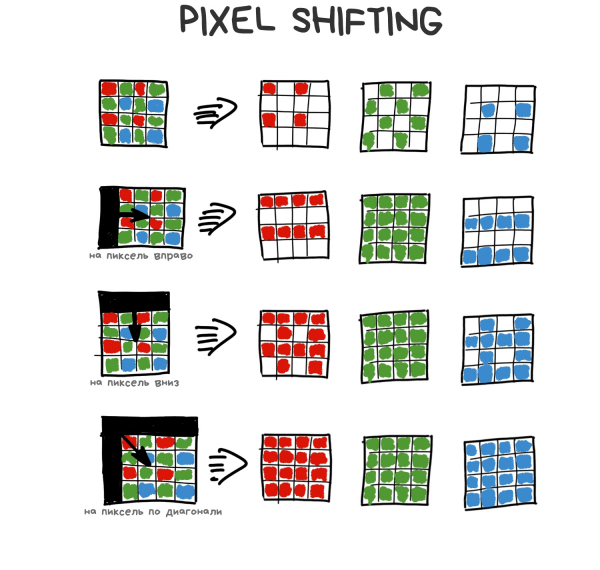
La vibrazione delle nostre mani durante la cattura di foto con il telefono rende questo processo una conseguenza naturale. Nelle ultime versioni di Google Pixel, questa funzione è implementata e si attiva sempre quando si usa lo zoom sul telefono, ed è chiamata Super Res Zoom (sì, anche a me piace il loro naming spietato). Anche i cinesi l'hanno copiata nei loro telefoni, anche se è venuta un po' peggio.
Sovrapporre fotografie leggermente spostate consente di raccogliere più informazioni sul colore di ogni pixel, riducendo così il rumore, aumentando la nitidezza e sollevando la risoluzione senza aumentare il numero fisico di megapixel del sensore. I moderni smartphone Android fanno questo automaticamente, mentre i loro utenti nemmeno ci pensano.
Stacking per messa a fuoco — qualsiasi profondità di campo e rifocalizzazione in post-produzione

Il metodo deriva dalla macrofotografia, dove una profondità di campo ridotta è sempre stata un problema. Per avere l'intero oggetto a fuoco, era necessario scattare più immagini spostando il focus avanti e indietro per unirle in un'unica immagine nitida. Lo stesso metodo veniva frequentemente utilizzato dagli appassionati di fotografia di paesaggio, rendendo il primo e il secondo piano nitidi come la diarrea.

Tutto ciò è arrivato anche sugli smartphone, anche se senza particolare clamore. Nel 2013 esce il Nokia Lumia 1020 con l'app «Refocus», e nel 2014 il Samsung Galaxy S5 con la modalità «Selective Focus». Funzionavano secondo lo stesso schema: premendo il pulsante, scattavano rapidamente 3 foto — una con messa a fuoco «normale», una con la messa a fuoco spostata in avanti e l'altra con la messa a fuoco spostata indietro. Il software allineava le immagini e permetteva di scegliere una di esse, presentando il tutto come un vero «controllo» del fuoco in post-produzione.
Non c'è stata alcuna elaborazione ulteriore, poiché anche questo semplice trucco era sufficiente per piantare un altro chiodo nella bara del Lytro e analoghi con il loro onesto rifocus. A proposito, parliamo di loro (maestri delle transizioni di livello 80).
Matrici computazionali — campi luminosi e plenottica
Come abbiamo capito sopra, i nostri sensori sono un disastro su una gamba di legno. Ci siamo semplicemente abituati e cerchiamo di convivere con questo. Nella loro struttura, sono cambiati poco sin dai tempi antichi. Abbiamo solo migliorato il processo tecnologico: abbiamo ridotto la distanza tra i pixel, combattuto contro il rumore, aggiunto pixel speciali per il funzionamento dell'autofocus a fase. Ma anche prendendo la reflex più costosa e tentando di fotografare un gatto in movimento in una stanza illuminata, il gatto, per così dire, vince sempre.
Da tempo stiamo tentando di inventare qualcosa di migliore. Molti tentativi e ricerche in questo campo possono essere trovati con la ricerca «sensore computazionale» o «sensore non Bayer», e anche il precedente esempio con il Pixel Shifting può rientrare tra i tentativi di migliorare i sensori attraverso il calcolo. Tuttavia, le storie più promettenti degli ultimi vent'anni provengono dal mondo delle cosiddette camere plenottiche.
Per evitare che vi addormentiate nell'attesa delle complesse parole in arrivo, lascio qui un'indiscrezione: la fotocamera degli ultimi Google Pixel è "leggermente" plenottica. Solo due pixel in più, ma anche questo permette di calcolare una vera profondità ottica dell'immagine senza la seconda fotocamera come nelle altre.
La plenottica è un'arma potente che deve ancora esplodere. Vi lascio un link a uno dei miei articoli recenti preferiti , da cui ho preso in prestito alcuni esempi.
La fotocamera plenottica – presto sarà presente ovunque
Inventata nel 1994, sviluppata a Stanford nel 2004. La prima fotocamera per consumatori – Lytro, rilasciata nel 2012. Attualmente, l'industria VR sta sperimentando attivamente tecnologie simili.
A differenza di una fotocamera tradizionale, quella plenottica si distingue per una modifica: il sensore è coperto da una rete di lenti, ognuna delle quali copre diversi pixel reali. In questo modo:
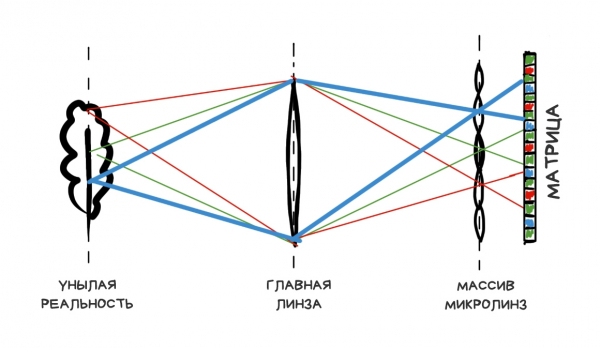
se si calcola correttamente la distanza dalla rete al sensore e le dimensioni dell'apertura, nell'immagine finale si otterranno gruppi nitidi di pixel, delle vere e proprie mini-versioni dell'immagine originale.
Si scopre che, se prendiamo da ogni cluster, ad esempio, un pixel centrale e uniamo l'immagine solo in base a questi, non ci sarà differenza rispetto a una foto scattata con una normale fotocamera. Sì, abbiamo perso un po' di risoluzione, ma semplicemente chiederemo a Sony di aggiungere qualche megapixel nei nuovi sensori.

Il divertimento inizia qui. Se prendiamo un altro pixel da ogni cluster e uniamo di nuovo l'immagine, otterremo di nuovo una foto normale, ma come se fosse stata scattata con uno spostamento di un pixel. In questo modo, avendo cluster di 10 × 10 pixel, otterremo 100 immagini dell'oggetto da 'leggermente' diverse angolazioni.
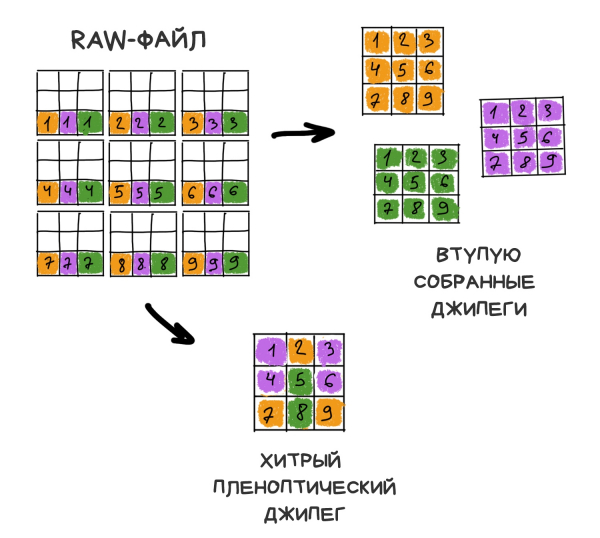
Maggiore è la dimensione del cluster, maggiori saranno le immagini, ma minore sarà la risoluzione. Nel mondo degli smartphone con sensori da 41 megapixel, possiamo un po' trascurare la risoluzione, ma c'è un limite a tutto. Dobbiamo mantenere un equilibrio.
Ok, abbiamo assemblato una fotocamera plenottica, e cosa ci offre?
Rifocalizzazione onesta
La funzionalità di cui tutti i giornalisti hanno parlato negli articoli su Lytro è la possibilità di una vera correzione della messa a fuoco in post-produzione. Per 'vera' si intende che non applichiamo alcun algoritmo di disblur, ma utilizziamo esclusivamente i pixel disponibili, selezionandoli o mediandoli dai cluster nell'ordine necessario.
Una foto RAW da una camera plenottica appare strana. Per ottenere un JPEG nitido e familiare, è necessario prima assemblarlo. Per fare ciò, bisogna selezionare ogni pixel del JPEG da uno dei cluster del RAW. A seconda di come li selezioniamo, il risultato cambierà.
Ad esempio, più un cluster si trova lontano dal punto di incidenza del raggio originale, più il raggio risulta sfocato. Questo è dovuto all'ottica. Per ottenere un'immagine sfocata, dobbiamo semplicemente scegliere i pixel alla distanza desiderata dall'originale — sia più vicini che più lontani.
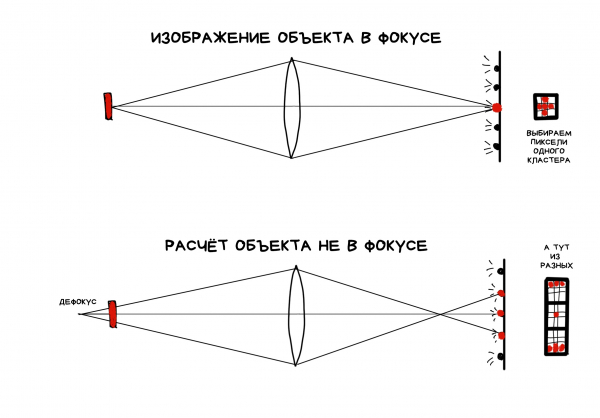
Con un cambio di messa a fuoco su se stessi, era più difficile — fisicamente c'erano meno pixel nei cluster. All'inizio, gli sviluppatori non volevano nemmeno dare agli utenti la possibilità di concentrarsi manualmente: la fotocamera lo decideva autonomamente tramite software. A questa visione del futuro gli utenti non si sono adattati, quindi la funzionalità è stata aggiunta in versioni successive sotto il nome di 'modalità creativa', ma il refocus è stato molto limitato proprio per questo motivo.
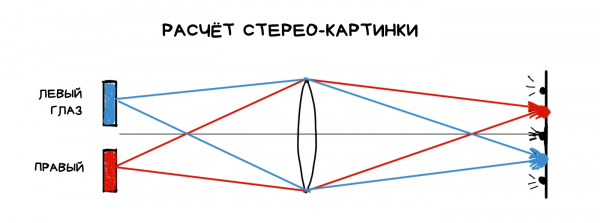
Mappa di profondità e 3D con una sola fotocamera
Una delle operazioni più semplici nella plenopitica è ottenere una mappa di profondità. Per farlo, è sufficiente raccogliere due scatti diversi e calcolare quanto siano spostati gli oggetti in essi. Maggiore è lo spostamento, maggiore è la distanza dalla fotocamera.
Recentemente Google ha acquistato e smantellato Lytro, ma ha utilizzato le loro tecnologie per il proprio VR e... per la fotocamera nel Pixel. A partire dal Pixel 2, la fotocamera è diventata per la prima volta 'un po'' plenoptrica, anche se con cluster di soli due pixel. Questo ha permesso a Google di non utilizzare una seconda fotocamera, come hanno fatto tutti gli altri, calcolando la mappa di profondità esclusivamente da una sola immagine.


La mappa di profondità viene costruita da due fotogrammi spostati di un sottopixel. Questo è assolutamente sufficiente per calcolare una mappa binaria di profondità e separare il primo piano dallo sfondo, sfocando quest'ultimo in un elegante effetto bokeh. Il risultato di questo stratificarsi viene ulteriormente levigato e "migliorato" da reti neurali addestrate per ottimizzare le mappe di profondità (e non per sfocare, come molti pensano).
Il vantaggio è che la plenottica negli smartphone ci è arrivata quasi gratuitamente. Già montavamo lenti su questi minuscoli sensori per aumentare in qualche modo il flusso luminoso. Nei prossimi Pixel, Google prevede di fare un passo avanti e coprire con una lente quattro fotodiodi.
Fonte: 3dnews.ru
