

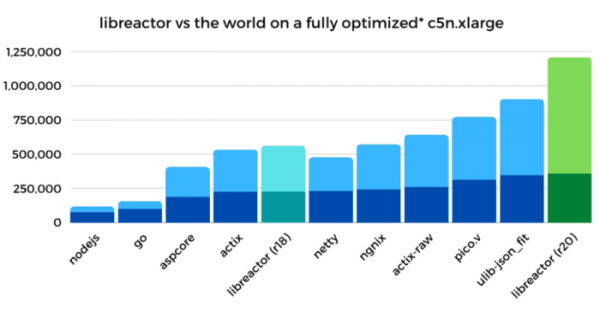
È stata pubblicata una guida dettagliata sull'ottimizzazione dell'ambiente Linux per raggiungere le massime prestazioni nella gestione delle richieste HTTP. I metodi proposti hanno consentito di aumentare le prestazioni del gestore JSON basato sulla libreria libreactor in un ambiente Amazon EC2 (4 vCPU) da 224.000 richieste API al secondo con le impostazioni predefinite di Amazon Linux 2 con kernel 4.14 a 1,2 milioni di richieste al secondo dopo l'ottimizzazione (crescita del 436%), oltre a ridurre i tempi di latenza nella gestione delle richieste del 79%. I metodi proposti non sono specifici per libreactor e funzionano con altri server http, tra cui nginx, Actix, Netty e Node.js (libreactor è stato utilizzato nei test poiché la soluzione basata su di esso ha mostrato le migliori prestazioni).
Ottimizzazioni principali:
- Ottimizzazione del codice libreactor. Come base è stata utilizzata la versione R18 del set Techempower, migliorata attraverso la rimozione del codice per limitare il numero di core della CPU in uso (questa ottimizzazione ha permesso di aumentare le prestazioni del 25-27%), la compilazione in GCC con le opzioni «-O3» (incremento del 5-10%) e «-march-native» (5-10%), la sostituzione delle chiamate read/write con recv/send (5-10%) e la riduzione delle spese generali nell'uso di pthreads (2-3%). L'aumento complessivo delle prestazioni dopo l'ottimizzazione del codice è stato del 55%, mentre la capacità di gestione è aumentata da 224k req/s a 347k req/s.
- Disattivazione della protezione contro le vulnerabilità causate dall'esecuzione speculativa delle istruzioni. L'uso dei parametri durante il caricamento del kernel «nospectre_v1 nospectre_v2 pti=off mds=off tsx_async_abort=off» ha portato a un aumento delle prestazioni del 28%, con una larghezza di banda aumentata da 347k req/s a 446k req/s. In particolare, il guadagno derivante dal parametro «nospectre_v1» (protezione da Spectre v1 + SWAPGS) è stato dell'1-2%, «nospectre_v2» (protezione da Spectre v2) del 15-20%, «pti=off» (Spectre v3/Meltdown) del 6%, «mds=off tsx_async_abort=off» (MDS/Zombieload e TSX Asynchronous Abort) del 6%. Sono rimaste inalterate le impostazioni per la protezione contro gli attacchi L1TF/Foreshadow (l1tf=flush), i colpi multipli iTLB, il bypass speculativo dello store e SRBDS, che non hanno influito sulle prestazioni, poiché non si sovrapponevano alla configurazione testata (ad esempio, specifica per KVM, la virtualizzazione nidificata e altri modelli di CPU).
- Disattivazione dei meccanismi di audit e blocco delle chiamate di sistema tramite il comando «auditctl -a never,task» e specificando l'opzione «—security-opt seccomp=unconfined» durante l'avvio del contenitore docker. L'aumento complessivo delle prestazioni è stato dell'11%, con una larghezza di banda cresciuta da 446k req/s a 495k req/s.
- Disabilitare iptables/netfilter scaricando i relativi moduli del kernel. L'idea di disattivare il firewall, non utilizzato in una soluzione server specifica, è stata motivata dai risultati del profiling, da cui si evince che la funzione nf_hook_slow richiedeva il 18% del tempo. Si segnala che nftables è più efficiente di iptables, ma su Amazon Linux resta in uso iptables. Dopo la disattivazione di iptables, si è registrato un aumento delle prestazioni del 22% e la capacità di elaborazione è aumentata da 495k req/s a 603k req/s.
- Riduzione della migrazione dei gestori tra core CPU diversi per migliorare l'efficienza dell'uso della cache della CPU. L'ottimizzazione è stata effettuata sia a livello di binding dei processi libreactor ai core CPU (CPU Pinning), sia mediante il fissaggio dei gestori di rete del kernel (Receive Side Scaling). Ad esempio, è stata disattivata l'irqbalance e sono state impostate esplicitamente le affinità delle code a CPU in /proc/irq/$IRQ/smp_affinity_list. Per utilizzare lo stesso core CPU per elaborare il processo libreactor e la coda di rete dei pacchetti in entrata è stato impiegato un gestore BPF personalizzato, connesso tramite l'impostazione del flag SO_ATTACH_REUSEPORT_CBPF durante la creazione del socket. Per il binding a CPU delle code dei pacchetti in uscita sono state modificate le impostazioni in /sys/class/net/eth0/queues/tx-<n>/xps_cpus. Il guadagno totale di prestazioni è stato del 38%, mentre la larghezza di banda è aumentata da 603k req/s a 834k req/s.
- Ottimizzazione della gestione delle interruzioni e utilizzo del polling. L'attivazione della modalità adaptive-rx nel driver ENA e le manipolazioni con il sysctl net.core.busy_read hanno consentito un incremento delle prestazioni del 28% (la larghezza di banda è passata da 834k req/s a 1.06M req/s, mentre le latenza è scesa da 361μs a 292μs).
- Disattivazione dei servizi di sistema che causano blocchi eccessivi nello stack di rete. Disattivare dhclient e installare Indirizzi IP manualmente ha portato a un aumento delle prestazioni del 6%, mentre la capacità di trasmissione è aumentata da 1,06M req/s a 1,12M req/s. La ragione dell'impatto di dhclient sulle prestazioni nell'analisi del traffico utilizzando socket raw.
- Combattere lo Spin Lock. Passare lo stack di rete alla modalità "noqueue" tramite sysctl "net.core.default_qdisc=noqueue" e "tc qdisc replace dev eth0 root mq" ha portato a un aumento delle prestazioni del 2%, mentre la capacità di trasmissione è aumentata da 1,12M req/s a 1,15M req/s.
- Ottimizzazioni finali minori, come la disabilitazione di GRO (Generic Receive Offload) con il comando "ethtool -K eth0 gro off" e la sostituzione dell'algoritmo di controllo del sovraccarico da cubic a reno tramite sysctl "net.ipv4.tcp_congestion_control=reno". L'aumento complessivo delle prestazioni è stato del 4%. La capacità di trasmissione è aumentata da 1,15M req/s a 1,2M req/s.
Oltre alle ottimizzazioni implementate, l'articolo discute anche metodi che non hanno portato al aumento delle prestazioni previsto. Ad esempio, si sono rivelati inefficaci:
- L'esecuzione separata di libreactor non ha mostrato differenze di prestazioni rispetto all'esecuzione in container. La sostituzione di writev con send, l'aumento di maxevents in epoll_wait, esperimenti con versioni di GCC e flag (l'effetto era visibile solo per i flag "-O3" e "-march-native") non hanno avuto impatto.
- L'aggiornamento del kernel Linux a versioni 4.19 e 5.4, l'uso dei pianificatori SCHED_FIFO e SCHED_RR, la manipolazione di sysctl kernel.sched_min_granularity_ns, kernel.sched_wakeup_granularity_ns, transparent_hugepages=never, skew_tick=1 e clocksource=tsc non hanno influito sulle prestazioni.
- Nella driver ENA, l'attivazione delle modalità Offload (segmentazione, scatter-gather, checksum rx/tx), la compilazione con il flag "-O3" e l'applicazione dei parametri ena.rx_queue_size e ena.force_large_llq_header non hanno avuto effetto.
- Le modifiche nello stack di rete non hanno portato a un aumento delle prestazioni:
- Disabilitazione di IPv6: ipv6.disable=1
- Disabilitazione di VLAN: modprobe -rv 8021q
- Disabilitazione del controllo della sorgente dei pacchetti
- net.ipv4.conf.all.rp_filter=0
- net.ipv4.conf.eth0.rp_filter=0
- net.ipv4.conf.all.accept_local=1 (effetto negativo)
- net.ipv4.tcp_sack=0
- net.ipv4.tcp_dsack=0
- net.ipv4.tcp_mem/tcp_wmem/tcp_rmem
- net.core.netdev_budget
- net.core.dev_weight
- net.core.netdev_max_backlog
- net.ipv4.tcp_slow_start_after_idle=0
- net.ipv4.tcp_moderate_rcvbuf=0
- net.ipv4.tcp_timestamps=0
- net.ipv4.tcp_low_latency=1
- SO_PRIORITY
- TCP_NODELAY
Fonte: opennet.ru
