

Ce l'abbiamo fatta!
«L'obiettivo di questo corso è prepararvi per il vostro futuro tecnologico.»
 Ciao, Habr. Ricordate l'articolo fantastico (+219, 2588 nei segnalibri, 429k letture)?
Ciao, Habr. Ricordate l'articolo fantastico (+219, 2588 nei segnalibri, 429k letture)?
Beh, nel libro di Hamming (sì, sì, quelli auto-controllanti e auto-correttivi ) c'è un intero , scritto basandosi sulle sue lezioni. Lo stiamo traducendo, perché il tipo sa il fatto suo.
Non è solo un libro su IT, è un libro sullo stile di pensiero delle persone incredibilmente brillanti. «Non è solo un'infusione di pensiero positivo; descrive le condizioni che aumentano le possibilità di realizzare un grande lavoro.»
Grazie a Andrey Pakhomov per la traduzione.
La teoria dell'informazione è stata sviluppata da C. E. Shannon alla fine degli anni '40. La direzione dei Bell Labs insisteva affinché la chiamasse «Teoria della Comunicazione», poiché questo sarebbe stato un nome molto più preciso. Per motivi ovvi, il titolo «Teoria dell'Informazione» ha un impatto significativamente maggiore sul pubblico, quindi Shannon ha optato per questo, e così è conosciuta fino ad oggi. Il nome stesso implica che la teoria riguarda l'informazione, ed è proprio questo a renderla importante, poiché ci addentriamo sempre di più nell'era dell'informazione. In questo capitolo, esplorerò alcune conclusioni fondamentali di questa teoria, fornendo prove non rigorose, ma piuttosto intuitive, di alcune affermazioni di questa teoria, affinché possiate capire cosa sia realmente la «Teoria dell'Informazione», dove potete applicarla e dove no.
Prima di tutto, cosa si intende per "informazione"? Shannon identifica l'informazione con l'incertezza. Ha scelto il logaritmo negativo della probabilità di un evento come misura quantitativa dell'informazione che si ottiene quando si verifica un evento con probabilità p. Ad esempio, se ti dico che a Los Angeles c'è nebbia, allora p è vicino a 1, il che per lo più non ci fornisce molte informazioni. Ma se dico che a giugno a Monterey piove, in questa affermazione c'è incertezza e contiene quindi più informazioni. Un evento certo non contiene alcuna informazione, poiché log 1 = 0.
Approfondiamo questo aspetto. Shannon sosteneva che la misura quantitativa dell'informazione dovesse essere una funzione continua della probabilità dell'evento p, e per eventi indipendenti dovesse essere additiva: la quantità di informazione ottenuta da due eventi indipendenti dovrebbe risultare equivalente alla quantità di informazione ottenuta da un evento congiunto. Ad esempio, il risultato del lancio di un dado e di una moneta è generalmente considerato come eventi indipendenti. Traduciamo quanto detto nel linguaggio matematico. Se I(p) è la quantità di informazione contenuta in un evento con probabilità p, allora, per un evento congiunto composto da due eventi indipendenti x con probabilità p1 e y con probabilità p2 otteniamo
![]()
(x e y sono eventi indipendenti)
Questa è l'equazione funzionale di Cauchy, valida per tutti p1 e p2. Per risolvere questa equazione funzionale, supponiamo che
p1 = p2 = p,
questo porta a
![]()
Se p1 = p2 e p2 = p, allora
![]()
e così via. Estendendo questo processo, utilizzando il metodo standard per le esponenziali, per tutti i numeri razionali m/n, la seguente affermazione è vera
![]()
Dalla continuità presunta della misura informatica, si deduce che la funzione logaritmica è l'unica soluzione continua dell'equazione funzionale di Cauchy.
Nella teoria dell'informazione, si usa comunemente una base logaritmica pari a 2, quindi una scelta binaria contiene esattamente 1 bit di informazione. Pertanto, l'informazione è misurata con la formula
![]()
Fermiamoci un momento e cerchiamo di capire cosa è successo sopra. Prima di tutto, non abbiamo mai fornito una definizione del concetto di "informazione", abbiamo semplicemente definito la formula per la sua misura quantitativa.
In secondo luogo, questa misura dipende dall'incertezza e, sebbene sia sufficientemente adatta per le macchine, come ad esempio i sistemi telefonici, radio, televisori, computer, ecc., non riflette il normale approccio umano all'informazione.
In terzo luogo, si tratta di una misura relativa, poiché dipende dallo stato attuale delle tue conoscenze. Se stai osservando un flusso di “numeri casuali” da un generatore di numeri casuali, presumi che ogni numero successivo sia incerto. Tuttavia, se conosci la formula per calcolare i “numeri casuali”, il numero successivo sarà noto e, di conseguenza, non conterrà informazioni.
Pertanto, la definizione che Shannon ha dato all'informazione è adatta in molti casi per le macchine, ma sembra non corrispondere alla comprensione umana di questo termine. Proprio per questo motivo, la “Teoria dell'informazione” avrebbe dovuto essere chiamata “Teoria della comunicazione”. Tuttavia, è già troppo tardi per cambiare definizioni (grazie alle quali la teoria ha acquisito la sua popolarità iniziale e che continuano a far pensare alla gente che questa teoria si occupi di “informazione”), quindi dobbiamo rassegnarci a esse. Devi però comprendere chiaramente quanto la definizione di informazione data da Shannon si discosti dal suo significato comune. L'informazione di Shannon riguarda qualcosa di completamente diverso, ossia l'incertezza.
Ecco cosa considerare quando proponi qualsiasi terminologia. Quanto è coerente la definizione proposta, ad esempio, la definizione di informazione fornita da Shannon, con la tua idea originale e quanto si discosta da essa? Quasi nessun termine riflette esattamente la tua precedente visione del concetto, ma alla fine, è la terminologia utilizzata a riflettere il significato del concetto, quindi la formalizzazione di qualcosa tramite definizioni chiare porta sempre a un certo rumore.
Consideriamo un sistema il cui alfabeto è composto da simboli q con probabilità pi. In questo caso, la quantità media di informazione nel sistema (il suo valore atteso) è pari a:
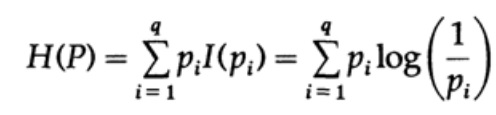
Questo è chiamato l'entropia del sistema con distribuzione di probabilità {pi}. Usiamo il termine «entropia» perché la stessa forma matematica emerge nella termodinamica e nella meccanica statistica. Per questo motivo, il termine «entropia» crea un'aura di importanza che, in ultima analisi, non è giustificata. La stessa forma matematica non implica un'interpretazione identica dei simboli!
L'entropia della distribuzione di probabilità gioca un ruolo fondamentale nella teoria dell'informazione. La disuguaglianza di Gibbs per due diverse distribuzioni di probabilità pi e qi è una delle conseguenze importanti di questa teoria. Quindi, dobbiamo dimostrare che
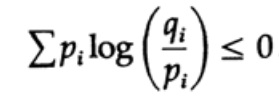
La dimostrazione si basa sul grafico evidente, Fig. 13.I, che mostra che
![]()
l'uguaglianza si raggiunge solo per x = 1. Applichiamo la disuguaglianza a ciascun termine della somma nella parte sinistra:
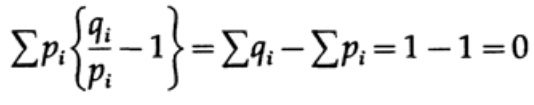
Se l'alfabeto del sistema di comunicazione è composto da q simboli, allora assumendo la probabilità di trasmissione di ciascun simbolo qi = 1/q e sostituendo q, otteniamo dalla disuguaglianza di Gibbs
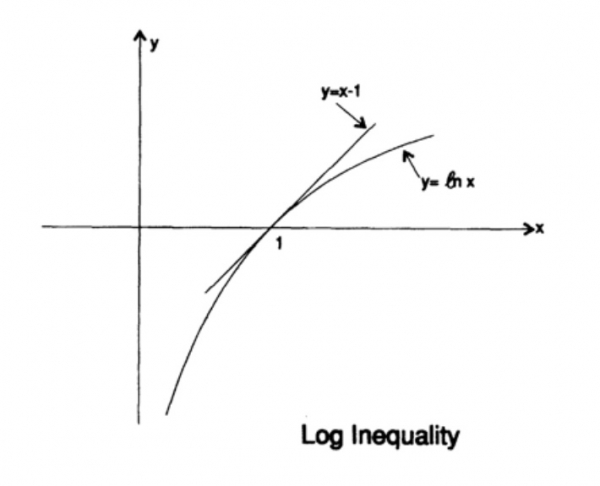
Figura 13.I
Questo implica che se la probabilità di trasmissione di tutti q simboli è la stessa ed è pari a 1/q, allora l'entropia massima è pari a ln q; altrimenti, la disuguaglianza è valida.
Nel caso di un codice univocamente decodificabile, abbiamo la disuguaglianza di Kraft
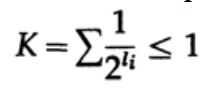
Ora, se definiamo le pseudo-probabilità
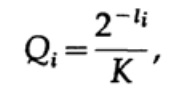
dove è finito 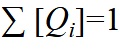 = 1, il che deriva dalla disuguaglianza di Gibbs,
= 1, il che deriva dalla disuguaglianza di Gibbs,
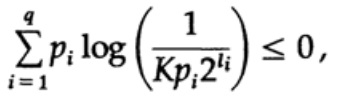
e applicando un po' di algebra (ricordate che K ≤ 1, quindi possiamo trascurare il termine logaritmico, e forse rinforzare la disuguaglianza in seguito), otteniamo
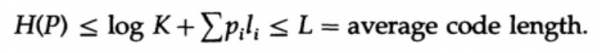
dove L è la lunghezza media del codice.
Pertanto, l'entropia rappresenta il limite minimo per qualsiasi codice simbolico con una lunghezza media del codice L. Questa è la teorema di Shannon per un canale senza rumore.
Consideriamo ora il teorema principale sulle limitazioni dei sistemi di comunicazione, in cui le informazioni vengono trasmesse come un flusso di bit indipendenti e vi è del rumore. Si presuppone che la probabilità di trasmissione corretta di un singolo bit P > 1 / 2, e la probabilità che il valore del bit venga invertito durante la trasmissione (si verifichi un errore) sia Q = 1 - P. Per comodità, supponiamo che gli errori siano indipendenti e che la probabilità di errore sia la stessa per ogni bit inviato, cioè che nel canale di comunicazione sia presente un "rumore bianco".
Abbiamo un lungo flusso di n bit, codificato in un solo messaggio — n — espansione multidimensionale di un codice unibit. Il valore di n lo determineremo più avanti. Consideriamo un messaggio composto da n bit come un punto nello spazio n-dimensionale. Dato che abbiamo uno spazio n-dimensionale — e per semplificare supponiamo che ogni messaggio abbia la stessa probabilità di apparire — esistono M possibili messaggi (M sarà definito più avanti), quindi la probabilità di un messaggio inviato è pari a
![]()
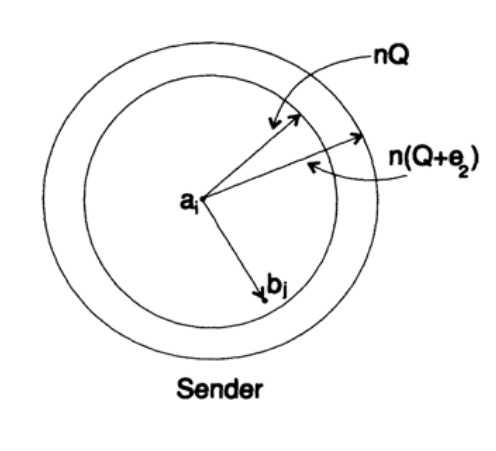
(mittente)
Grafico 13.II
Consideriamo ora l'idea della larghezza di banda del canale. Senza entrare nei dettagli, la larghezza di banda di un canale è definita come il massimo volume di informazioni che può essere trasmesso in modo affidabile attraverso un canale di comunicazione, tenendo conto dell'uso del codice più efficace. Non vi è alcun argomento a favore del fatto che possa essere trasmessa più informazione di quanto la sua capacità. Questo può essere dimostrato per un canale simmetrico binario (che utilizziamo nel nostro caso). La capacità del canale, con l'invio bit per bit, è definita come
![]()
dove, come prima, P è la probabilità di assenza di errore in qualsiasi bit inviato. Quando si inviano n bit indipendenti, la capacità del canale è definita come
![]()
Se ci troviamo vicini alla capacità del canale, dobbiamo inviare quasi la stessa quantità di informazione per ciascun simbolo ai, i = 1, …, M. Tenendo conto che la probabilità di ciascun simbolo ai è 1 / M, otteniamo
![]()
quando inviamo uno qualsiasi dei M messaggi equiprobabili ai, abbiamo
![]()
Quando inviamo n bit, ci aspettiamo che si verifichino nQ errori. In pratica, per un messaggio di n bit, avremo circa nQ errori nel messaggio ricevuto. Con grandi valori di n, la variazione relativa (variazione = ampiezza della distribuzione,)
la distribuzione del numero di errori diventerà sempre più stretta all'aumentare di n.
Quindi, dal lato del trasmettitore, prendo il messaggio ai da inviare e disegno una sfera attorno ad esso con raggio
![]()
che è leggermente maggiore dell'errore atteso Q, (figura 13.II). Se n è sufficientemente grande, allora esiste una probabilità infinitesimale che il punto di segnalazione bj sul lato del ricevente si trovi al di fuori di questa sfera. Illustriamo la situazione così come la vedo io dal punto di vista del trasmettitore: abbiamo raggi di qualsiasi lunghezza dal messaggio trasmesso ai al messaggio ricevuto bj con una probabilità di errore che è (o quasi) distribuzione normale, raggiungendo il massimo in nQ. Per qualsiasi e2 dato, esiste un n sufficientemente grande tale che la probabilità che il punto ricevente bj, che esce dalla mia sfera, sia tanto piccola quanto desideri.
Ora consideriamo la stessa situazione dal tuo punto di vista (fig. 13.III). Dalla parte del ricevente c'è una sfera S(r) dello stesso raggio r intorno al punto ricevuto bj nello spazio n-dimensionale, tale che se il messaggio ricevuto bj è all'interno della mia sfera, allora il messaggio che ho inviato ai è all'interno della tua sfera.
Come può verificarsi un errore? Un errore può verificarsi nei casi descritti nella tabella sottostante:
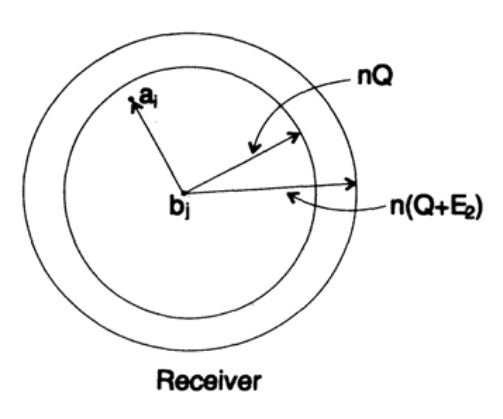
Figura 13.III

Qui vediamo che, se c'è almeno un altro punto nell'area intorno al punto accettato, corrispondente a un possibile messaggio non codificato inviato, allora si è verificato un errore durante la trasmissione, poiché non è possibile determinare quale di questi messaggi sia stato effettivamente inviato. Il messaggio inviato è privo di errori solo se il punto corrispondente a esso è nell'area e non esistono altri punti possibili in questo codice che si trovano nella stessa area.
Abbiamo un'equazione matematica per la probabilità di errore Pe, se è stato inviato un messaggio ai
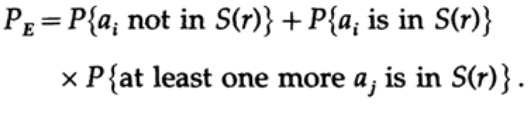
Possiamo eliminare il primo fattore nel secondo addendo, assumendolo uguale a 1. Così otteniamo un'ineguaglianza
![]()
È ovvio che
![]()
pertanto
![]()
applichiamo nuovamente all'ultimo membro a destra
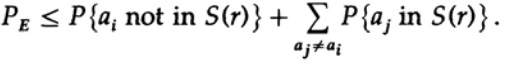
Assumendo che n sia sufficientemente grande, il primo membro può essere considerato abbastanza piccolo, diciamo, minore di un certo numero d. Pertanto abbiamo
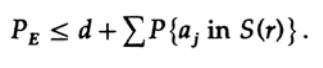
Diamo ora un'occhiata a come costruire un codice di sostituzione semplice per codificare M messaggi composti da n bit. Senza avere un'idea precisa su come costruire il codice (i codici a correzione d'errore non erano ancora stati inventati), Shannon scelse la codifica casuale. Lancia una moneta per ciascuno dei n bit del messaggio e ripeti il processo per M messaggi. In totale, saranno necessari nM lanci di moneta, quindi sono possibili
![]()
dizionari di codice, ciascuno con la stessa probabilità di ½nM. Certo, il processo casuale di creazione di un dizionario di codice implica che ci sia la possibilità di duplicati, nonché di punti di codice che saranno vicini tra loro, generando così probabili errori. Bisogna dimostrare che se ciò non accade con una probabilità superiore a un qualunque basso livello di errore scelto, allora n è sufficientemente grande.
Il punto cruciale è che Shannon ha mediato tutti i possibili libri di codice per trovare l'errore medio! Useremo il simbolo Av [.] per indicare il valore medio su un insieme di tutti i possibili dizionari di codice casuali. La media su una costante d, ovviamente, fornisce una costante, dato che per la media ogni membro coincide con qualsiasi altro membro nella somma.
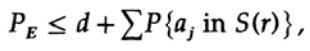
che può essere aumentato (M–1 passa a M)
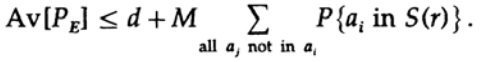
Per qualsiasi messaggio specifico, mediando tutti i libri di codice, la codifica esplora tutti i possibili valori, quindi la probabilità media che un punto si trovi all'interno della sfera è il rapporto tra il volume della sfera e il volume totale dello spazio. Il volume della sfera in questo caso
![]()
dove s=Q+e2 <1/2 e ns deve essere un numero intero.
L'ultimo addendo a destra è il maggiore in questa somma. Iniziamo a valutare il suo valore secondo la formula di Stirling per i fattoriali. Poi esamineremo il coefficiente di diminuzione dell'addendo precedente; notate che questo coefficiente aumenta spostandosi a sinistra. Pertanto possiamo: (1) limitare il valore della somma alla somma di una progressione geometrica con questo coefficiente iniziale, (2) estendere la progressione geometrica da ns membri a un numero infinito di membri, (3) calcolare la somma dell'infinita progressione geometrica (algebra standard, nulla di sostanziale) e infine ottenere il valore limite (per un n sufficientemente grande):
![]()
Notate come l'entropia H(s) sia apparsa nell'identità binomiale. Osservate che la scomposizione in serie di Taylor H(s)=H(Q+e2) fornisce una stima ottenuta considerando solo la prima derivata e ignorando tutte le altre. Ora raccogliamo l'espressione finale:
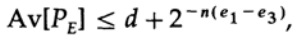
dove
![]()
Tutto ciò che dobbiamo fare è scegliere e2, in modo che e3 < e1, e allora l'ultimo termine sarà arbitrariamente piccolo, per valori di n sufficientemente grandi. Pertanto, l'errore medio PE può essere reso arbitrariamente piccolo con una capacità di canale sufficientemente vicina a C.
Se il valore medio su tutti i codici ha un errore sufficientemente piccolo, allora almeno un codice deve essere adeguato, quindi esiste almeno un sistema di codifica adeguato. Questo è un risultato importante ottenuto da Shannon — la «teorema di Shannon per i canali disturbati», sebbene va notato che lui lo dimostrò per un caso molto più generale rispetto a quello di un semplice canale simmetrico binario che ho utilizzato. Per il caso generale le dimostrazioni matematiche sono molto più complesse, ma le idee non sono così diverse, quindi molto spesso attraverso l'esempio del caso particolare si può rivelare il vero significato del teorema.
Critichiamo il risultato. Abbiamo ripetuto più volte: «Con n sufficientemente grande». Ma quanto deve essere grande n? Molto, molto grande, se vuoi veramente avvicinarti alla capacità di banda e essere sicuro della corretta trasmissione dei dati! Tanto grande che in effetti dovrai aspettare a lungo per accumulare un messaggio di tante informazioni quanti bit, per poi codificarlo. In questo modo, la dimensione del dizionario del codice casuale sarà semplicemente enorme (dopotutto, un tale dizionario non può essere rappresentato in una forma più breve rispetto a un elenco completo di tutti i bit Mn, dato che n e M sono molto grandi)!
I codici di correzione degli errori evitano l'attesa di messaggi molto lunghi, con la successiva codifica e decodifica attraverso enormi tavole di codice, perché evitano queste ultime e utilizzano invece normali calcoli. In teoria semplice, tali codici tendono di solito a perdere la capacità di avvicinarsi alla larghezza di banda del canale pur mantenendo una bassa frequenza di errori; tuttavia, quando un codice corregge un gran numero di errori, mostra buoni risultati. In altre parole, se nelle vostre considerazioni considerate una certa capacità del canale per la correzione degli errori, dovete utilizzare le capacità di correzione della maggior parte del tempo, cioè un gran numero di errori deve essere corretto in ogni messaggio inviato, altrimenti perdete questa capacità inutilmente.
Tuttavia, il teorema dimostrato sopra non è privo di significato! Mostra che i sistemi di trasmissione efficaci devono utilizzare schemi di codifica ben pensati per lunghe stringhe di bit. Un esempio sono i satelliti che hanno lasciato il sistema planetario esterno; man mano che si allontanano dalla Terra e dal Sole, sono costretti a correggere un numero crescente di errori nei blocchi di dati: alcuni satelliti utilizzano pannelli solari che forniscono circa 5 W, altri utilizzano fonti di energia nucleare che forniscono una potenza simile. La debole potenza delle fonti di alimentazione, le dimensioni ridotte delle antenne dei trasmettitori e le limitazioni delle antenne dei ricevitori sulla Terra, insieme alla enorme distanza che il segnale deve coprire, richiedono l'uso di codici ad alta capacità di correzione degli errori per costruire un sistema di comunicazione efficace.
Tornando allo spazio n-dimensionale che abbiamo utilizzato nella dimostrazione precedente. Discutendone, abbiamo mostrato che quasi tutto il volume di una sfera è concentrato attorno alla superficie esterna; così, è quasi certo che il segnale ricevuto si trovi sulla superficie della sfera costruita attorno al segnale trasmesso, anche con un raggio relativamente piccolo. Quindi non sorprende che il segnale ricevuto, dopo la correzione di un numero arbitrariamente grande di errori, nQ, si trovi tanto vicino al segnale privo di errori. La capacità del canale di comunicazione che abbiamo esaminato in precedenza è la chiave per comprendere questo fenomeno. Si noti che tali sfere, costruite per i codici di Hamming con correzione degli errori, non si sovrappongono. Un elevato numero di dimensioni praticamente ortogonali nello spazio n-dimensionale spiega perché possiamo collocare M sfere nello spazio con una leggera sovrapposizione. Se si consente una piccola, arbitrariamente piccola sovrapposizione, che può portare solo a un numero limitato di errori durante la decodifica, si può ottenere un posizionamento denso delle sfere nello spazio. Hamming garantiva un certo livello di correzione degli errori, Shannon una bassa probabilità di errore, mantenendo però una capacità effettiva del canale tanto vicino a quella del canale di comunicazione, cosa che i codici di Hamming non possono fare.
La teoria dell'informazione non indica come progettare un sistema efficace, ma suggerisce la direzione verso sistemi di comunicazione efficienti. È uno strumento prezioso per costruire sistemi di comunicazione tra macchine, ma, come già detto, non ha un particolare legame con il modo in cui le persone si scambiano informazioni. Il grado in cui l'ereditarietà biologica somiglia ai sistemi tecnici di comunicazione è semplicemente sconosciuto, quindi attualmente non è chiaro quanto la teoria dell'informazione sia applicabile ai geni. Non ci resta che provare, e se il successo ci mostrerà la natura macchina-simile di questo fenomeno, il fallimento indicherà altri aspetti sostanziali della natura dell'informazione.
Distraeamo un po' la mente. Abbiamo visto che tutte le definizioni iniziali, in misura maggiore o minore, devono esprimere l'essenza delle nostre credenze fondamentali, ma presentano un certo grado di distorsione e quindi risultano inapplicabili. Tradizionalmente si ritiene che, in ultima analisi, la definizione che utilizziamo definisca effettivamente l'essenza; tuttavia, ciò ci indica solo come affrontare le questioni e non porta con sé alcun significato reale. L'approccio postulativo, così apprezzato nei circoli matematici, lascia molto a desiderare nella pratica.
Ora esamineremo un esempio di test di intelligenza, dove la definizione è talmente circolare quanto volete, e di conseguenza porta a confusione. Si crea un test che si presume debba misurare l'intelligenza. Successivamente, viene rivisitato per renderlo il più coerente possibile, e poi pubblicato e calibrato in modo semplice, affinché l'«intelligenza» misurata risulti normalmente distribuita (naturalmente secondo la curva di calibrazione). Tutte le definizioni devono essere verificate, non solo quando vengono proposte per la prima volta, ma anche molto tempo dopo, quando vengono utilizzate per trarre conclusioni. Fino a che punto i confini delle definizioni sono adatti al compito da svolgere? Quante volte definizioni fornite in un contesto iniziano a essere applicate in contesti abbastanza diversi? Questo accade abbastanza frequentemente! Nelle scienze umane, con cui inevitabilmente ti imbatterai nella tua vita, si verifica più spesso.
Pertanto, uno degli obiettivi di questa presentazione sulla teoria dell'informazione, oltre a dimostrarne l'utilità, era avvertirvi di questo pericolo, o mostrare come utilizzarla per ottenere il risultato desiderato. È stato notato da tempo che le definizioni iniziali condizionano molto di più ciò che alla fine trovate, di quanto possa sembrare. Le definizioni iniziali richiedono una grande attenzione non solo in ogni nuova situazione, ma anche in aree in cui lavorate da tempo. Questo vi permetterà di comprendere in che misura i risultati ottenuti sono una tautologia e non qualcosa di utile.
Una storia nota di Eddington racconta di persone che pescavano nel mare con una rete. Esaminando le dimensioni dei pesci che avevano catturato, hanno determinato la dimensione minima del pesce che vive nel mare! La loro conclusione era condizionata dallo strumento utilizzato e non dalla realtà.
Continua...
Chi vuole aiutare con la traduzione, l'impaginazione e la pubblicazione del libro — scrivete in privato o all'indirizzo magisterludi2016@yandex.ru
A proposito, abbiamo anche avviato la traduzione di un altro fantastico libro — )
In particolare, stiamo cercando chi potrà aiutarti con la traduzione . (tradiamo per 10 minuti, i primi 20 già presi)
Contenuto del libro e capitoli tradotti
- Introduzione all'Arte di Fare Scienza e Ingegneria: Imparare a Imparare (28 marzo 1995)
- «Fondamenti della Rivoluzione Digitale (Discreta)» (30 marzo 1995)
- «Storia dei Computer — Hardware» (31 marzo 1995)
- «Storia dei Computer — Software» (4 aprile 1995)
- «Storia dei Computer — Applicazioni» (6 aprile 1995)
- «Intelligenza Artificiale — Parte I» (7 aprile 1995)
- «Intelligenza Artificiale — Parte II» (11 aprile 1995)
- «Intelligenza Artificiale III» (13 aprile 1995)
- «Spazio n-Dimensionale» (14 aprile 1995)
- «Teoria del Codice — La Rappresentazione dell'Informazione, Parte I» (18 aprile 1995)
- «Teoria del Codice — La Rappresentazione dell'Informazione, Parte II» (20 aprile 1995)
- «Codici di Correzione degli Errori» (21 aprile 1995)
- «Teoria dell'Informazione» (25 aprile 1995)
- «Filtri Digitali, Parte I» (27 aprile 1995)
- «Filtri Digitali, Parte II» (28 aprile 1995)
- «Filtri Digitali, Parte III» (2 maggio 1995)
- «Filtri Digitali, Parte IV» (4 maggio 1995)
- «Simulazione, Parte I» (5 maggio 1995)
- «Simulazione, Parte II» (9 maggio 1995)
- «Simulazione, Parte III» (11 maggio 1995)
- «Fibra Ottica» (12 maggio 1995)
- «Istruzione Assistita da Computer» (16 maggio 1995)
- «Matematica» (18 maggio 1995)
- «Meccanica Quantistica» (19 maggio 1995)
- «Creatività» (23 maggio 1995). Traduzione:
- «Esperti» (25 maggio 1995)
- «Dati Inaffidabili» (26 maggio 1995)
- «Ingegneria dei Sistemi» (30 maggio 1995)
- «Ottieni ciò che misuri» (1 giugno 1995)
- (2 giugno 1995) traduciamo in pezzi da 10 minuti
- Hamming, «Tu e la tua ricerca» (6 giugno 1995).
Chi vuole aiutare con la traduzione, l'impaginazione e la pubblicazione del libro — scrivete in privato o all'indirizzo magisterludi2016@yandex.ru
Fonte: habr.com
