

Проектом Riffusion развивается вариант системы машинного обучения Stable Diffusion, адаптированный для генерации музыки вместо изображений. Музыка может синтезироваться текстового описания на естественном языке или на основе предложенного шаблона. Компоненты для синтеза музыки написаны на языке Python с использованием фреймворка PyTorch и доступны под лицензией MIT. Обвязка с интерфейсом реализована на языке TypeScript и также распространяется под лицензией MIT. Натренированные модели открыты под пермиссивной лицензией Creative ML OpenRAIL-M, допускающей использование в коммерческих целях.
Проект интересен тем, что продолжает использовать для генерации музыки модели «из текста в изображение» и «из изображения в изображение», но в качестве изображений манипулирует спектрограммами. Иными словами, классический Stable Diffusion натренирован не на фотографиях и картинках, а на изображениях спектрограмм, отражающих изменение частоты и амплитуды звуковой волны со временем. Соответственно на выходе тоже формируется спектрограмма, которая затем преобразуется в звуковое представление.
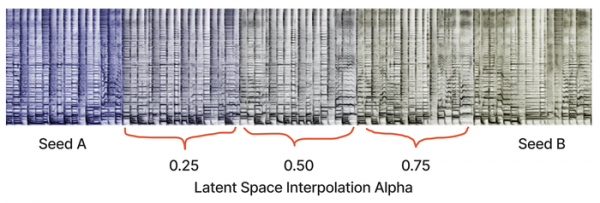
Метод также может использоваться для изменения имеющихся звуковых композиций и синтеза музыки по образцу, по аналогии с модификацией изображений в Stable Diffusion. Например, при генерации могут задаваться образцы спектрограмм с эталонным стилем, комбинироваться разные стили, выполняться плавный переход от одного стиля к другому или вноситься изменения в существующий звук для решения таких задач, как увеличение громкости отдельных инструментов, изменение ритма и замена инструментов. Образцы также используются для генерации длительно играющих композиций, компонуемых из серии близких друг к другу отрывков, немного меняющихся во времени. Отдельно генерируемые отрывки объединяются в непрерывный поток при помощи интерполяции внутренних параметров модели.
Для создания спектрограммы из звука используется оконное преобразование Фурье. При воссоздании звука из спектрограммы возникает проблема с определением фазы (на спектрограмме присутствует только частота и амплитуда), для реконструкции которой задействован алгоритм аппроксимации Гриффина-Лима.
Fonte: opennet.ru
