


מסד הנתונים של סדרות הזמן (TSDB) ב-Prometheus 2 הוא דוגמה מצוינת לפתרון הנדסי המציע שיפורים משמעותיים לעומת אחסון v2 ב-Prometheus 1 מבחינת צבירת נתונים וביצועי שאילתות, ויעילות משאבים. יישמנו את Prometheus 2 ב-Percona Monitoring and Management (PMM), והייתה לי הזדמנות להבין את ביצועי ה-TSDB של Prometheus 2. במאמר זה, אשתף את תוצאות התצפיות הללו.
עומס עבודה ממוצע של פרומתאוס
עבור אלו המורגלים להתמודד עם מסדי נתונים למטרות ראשוניות, עומס עבודה טיפוסי של Prometheus הוא די מעניין. קצב צבירת הנתונים נוטה להיות יציב: השירותים שאתה מנטר בדרך כלל שולחים בערך את אותו מספר מדדים, והתשתית משתנה יחסית לאט.
בקשות למידע יכולות להגיע ממגוון מקורות. חלקן, כמו התראות, נוטות להיות גם יציבות וצפויות. אחרות, כמו בקשות משתמשים, יכולות לגרום לקפיצות תנועה, אם כי זה לא אופייני לרוב העומסים.
בדיקת עומס
במהלך הבדיקות, התמקדתי ביכולת לצבור נתונים. פרסתי את Prometheus 2.3.2 שעבר קומפילציה עם Go 1.10.1 (כחלק מ-PMM 1.14) לשירות Linode באמצעות הסקריפט הזה: עבור יצירת עומס מציאותית ביותר, זה הפעלתי מספר צמתי MySQL עם עומס אמיתי (מבחן Sysbench TPC-C), שכל אחד מהם חיקה 10 צמתי Linux/MySQL.
כל הבדיקות הבאות בוצעו על שרת Linode עם שמונה ליבות וירטואליות ו-32 ג'יגה-בייט של זיכרון, תוך הרצת 20 סימולציות עומס המנטרות 800 מופעי MySQL. או, במונחים של Prometheus, 440 מטרות, 380 גירוד לשנייה, 1,7 דגימות לשנייה ו-XNUMX מיליון סדרות זמן פעילות.
תכנית
הגישה האופיינית של מסדי נתונים מסורתיים, כולל זו המשמשת את Prometheus 1.x, היא אם זה לא מספיק כדי להתמודד עם העומס, תחווה השהייה גבוהה וחלק מהשאילתות לא יבוצעו. ניצול הזיכרון ב-Prometheus 2 מוגדר באמצעות המפתח. storage.tsdb.min-block-duration, אשר קובע כמה זמן יישמרו רשומות בזיכרון לפני שיימחקו לדיסק (ברירת המחדל היא שעתיים). כמות הזיכרון הנדרשת תהיה תלויה במספר סדרות הזמן, התוויות והגירודים בנוסף לזרימה הנכנסת נטו. מבחינת שטח דיסק, Prometheus שואפת להשתמש ב-2 בתים לכל רשומה (דגימה). מצד שני, דרישות הזיכרון גבוהות בהרבה.
אמנם ניתן להגדיר את גודל הבלוק, אך לא מומלץ להגדיר אותו באופן ידני, כך שתיאלצו לתת ל-Prometheus את כמות הזיכרון שהוא מבקש עבור עומס העבודה שלכם.
אם אין מספיק זיכרון כדי לתמוך בזרם המטריקות הנכנסות, פרומתאוס יקרוס עם סוף זיכרון או ייתפס על ידי הרוצח של OOM.
הוספת swap כדי לעכב את הקריסה כאשר הזיכרון של Prometheus נגמר לא עוזרת הרבה, כי השימוש בה גורם לצריכת זיכרון להתפוצץ. אני חושב שזה Go, איסוף הזבל שלו, והאופן שבו הוא מטפל ב-swap.
גישה מעניינת נוספת היא להגדיר את בלוק הראש כך שיורקן לדיסק בזמן מסוים, במקום לספור אותו מרגע תחילת התהליך.
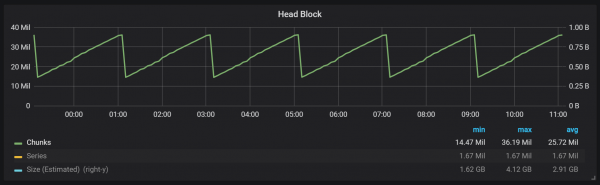
כפי שניתן לראות מהגרף, ריקונים לדיסק מתרחשים כל שעתיים. אם תשנה את הפרמטר min-block-duration לשעה, ריקונים אלה יתרחשו כל שעה, החל לאחר חצי שעה.
אם ברצונך להשתמש בגרפים אלה ובגרפים אחרים בהתקנת Prometheus שלך, תוכל להשתמש בזה הוא תוכנן עבור PMM, אך עם שינויים קלים הוא מתאים לכל התקנה של פרומתאוס.
יש לנו בלוק פעיל, הנקרא בלוק ראשי, המאוחסן בזיכרון; בלוקים עם נתונים ישנים יותר נגישים דרך mmap()זה מבטל את הצורך להגדיר את המטמון בנפרד, אבל גם אומר שצריך להשאיר מספיק מקום למטמון של מערכת ההפעלה אם רוצים לבצע שאילתות על נתונים ישנים יותר ממה שבלוק ה-head יכול להכיל.
משמעות הדבר היא גם שצריכת הזיכרון הווירטואלי של פרומתאוס תיראה גבוהה למדי, וזה לא משהו לדאוג לגביו.
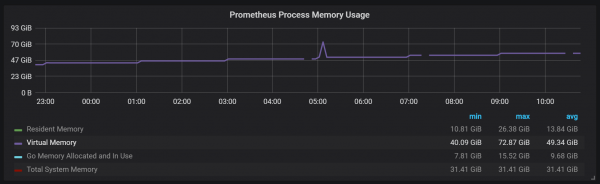
נקודת עיצוב מעניינת נוספת היא השימוש ב-WAL (כתיבה מראש יומן). כפי שניתן לראות מתיעוד האחסון, Prometheus משתמש ב-WAL כדי למנוע הפסדים במהלך קריסות. המנגנונים הספציפיים להבטחת עמידות הנתונים, למרבה הצער, מתועדים בצורה גרועה. Prometheus 2.3.2 שופך את WAL לדיסק כל 10 שניות, ופרמטר זה אינו ניתן להגדרה על ידי המשתמש.
דחיסות
Prometheus TSDB מתוכנן כמו מאגר Log Structured Merge (LSM): בלוק ה-head נמחק מעת לעת לדיסק, בעוד מנגנון דחיסה מאחד בלוקים מרובים יחד כדי למנוע סריקת בלוקים רבים מדי עבור שאילתות. הנה מספר הבלוקים שראיתי במערכת הבדיקה לאחר יום של טעינה.
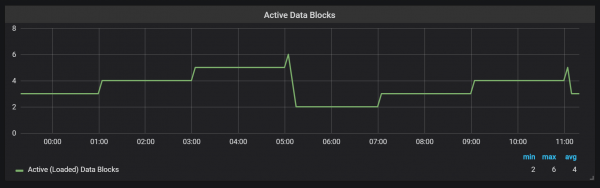
אם אתם רוצים לדעת עוד על המאגר, תוכלו לעיין בקובץ meta.json, המכיל מידע על הבלוקים הזמינים וכיצד הם נוצרו.
{
"ulid": "01CPZDPD1D9R019JS87TPV5MPE",
"minTime": 1536472800000,
"maxTime": 1536494400000,
"stats": {
"numSamples": 8292128378,
"numSeries": 1673622,
"numChunks": 69528220
},
"compaction": {
"level": 2,
"sources": [
"01CPYRY9MS465Y5ETM3SXFBV7X",
"01CPYZT0WRJ1JB1P0DP80VY5KJ",
"01CPZ6NR4Q3PDP3E57HEH760XS"
],
"parents": [
{
"ulid": "01CPYRY9MS465Y5ETM3SXFBV7X",
"minTime": 1536472800000,
"maxTime": 1536480000000
},
{
"ulid": "01CPYZT0WRJ1JB1P0DP80VY5KJ",
"minTime": 1536480000000,
"maxTime": 1536487200000
},
{
"ulid": "01CPZ6NR4Q3PDP3E57HEH760XS",
"minTime": 1536487200000,
"maxTime": 1536494400000
}
]
},
"version": 1
}דחיסות בפרומתאוס קשורות לזמן שבו בלוק הראש נשטף בדיסק. מספר פעולות כאלה עשויות להתבצע בו זמנית.
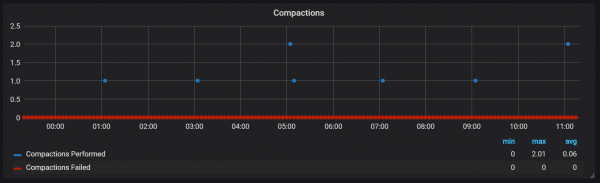
נראה כי דחיסות אינן מוגבלות בשום צורה ויכולות לגרום לקפיצות גדולות בקלט/פלט של הדיסק במהלך הביצוע.
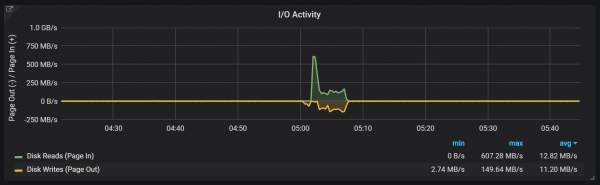
קפיצות עומס על המעבד
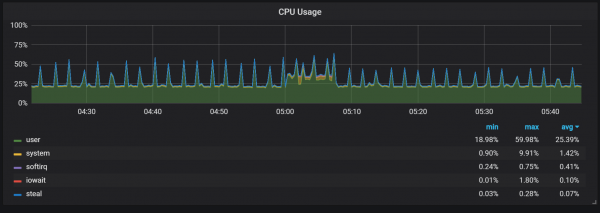
כמובן, יש לכך השפעה שלילית למדי על ביצועי המערכת, וזה גם אתגר רציני עבור אחסון LSM: כיצד לדחוס אותו כדי לתמוך בקצבי שאילתות גבוהים מבלי לגרום לתקורה רבה מדי?
השימוש בזיכרון במהלך דחיסה גם נראה די מעניין.
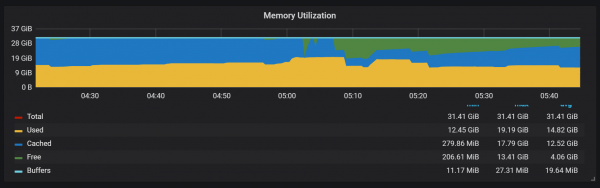
אנו יכולים לראות כיצד לאחר דחיסה רוב מצב הזיכרון משנה את מצבו מ-Cached ל-Free, כלומר מידע בעל ערך פוטנציאלי הוסר משם. אני תוהה אם זה משמש fadvice() או טכניקת מזעור אחרת, או שזה נגרם על ידי שחרור המטמון מבלוקים שנהרסו במהלך הדחיסה?
התאוששות לאחר כישלון
התאוששות מתקלות לוקחת זמן, ויש לכך סיבה טובה. עבור זרם נכנס של מיליון רשומות בשנייה, הייתי צריך לחכות כ-25 דקות עד שההתאוששות תתרחש, בהתחשב בכונן ה-SSD.
level=info ts=2018-09-13T13:38:14.09650965Z caller=main.go:222 msg="Starting Prometheus" version="(version=2.3.2, branch=v2.3.2, revision=71af5e29e815795e9dd14742ee7725682fa14b7b)"
level=info ts=2018-09-13T13:38:14.096599879Z caller=main.go:223 build_context="(go=go1.10.1, user=Jenkins, date=20180725-08:58:13OURCE)"
level=info ts=2018-09-13T13:38:14.096624109Z caller=main.go:224 host_details="(Linux 4.15.0-32-generic #35-Ubuntu SMP Fri Aug 10 17:58:07 UTC 2018 x86_64 1bee9e9b78cf (none))"
level=info ts=2018-09-13T13:38:14.096641396Z caller=main.go:225 fd_limits="(soft=1048576, hard=1048576)"
level=info ts=2018-09-13T13:38:14.097715256Z caller=web.go:415 component=web msg="Start listening for connections" address=:9090
level=info ts=2018-09-13T13:38:14.097400393Z caller=main.go:533 msg="Starting TSDB ..."
level=info ts=2018-09-13T13:38:14.098718401Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536530400000 maxt=1536537600000 ulid=01CQ0FW3ME8Q5W2AN5F9CB7R0R
level=info ts=2018-09-13T13:38:14.100315658Z caller=web.go:467 component=web msg="router prefix" prefix=/prometheus
level=info ts=2018-09-13T13:38:14.101793727Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536732000000 maxt=1536753600000 ulid=01CQ78486TNX5QZTBF049PQHSM
level=info ts=2018-09-13T13:38:14.102267346Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536537600000 maxt=1536732000000 ulid=01CQ78DE7HSQK0C0F5AZ46YGF0
level=info ts=2018-09-13T13:38:14.102660295Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536775200000 maxt=1536782400000 ulid=01CQ7SAT4RM21Y0PT5GNSS146Q
level=info ts=2018-09-13T13:38:14.103075885Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536753600000 maxt=1536775200000 ulid=01CQ7SV8WJ3C2W5S3RTAHC2GHB
level=error ts=2018-09-13T14:05:18.208469169Z caller=wal.go:275 component=tsdb msg="WAL corruption detected; truncating" err="unexpected CRC32 checksum d0465484, want 0" file=/opt/prometheus/data/.prom2-data/wal/007357 pos=15504363
level=info ts=2018-09-13T14:05:19.471459777Z caller=main.go:543 msg="TSDB started"
level=info ts=2018-09-13T14:05:19.471604598Z caller=main.go:603 msg="Loading configuration file" filename=/etc/prometheus.yml
level=info ts=2018-09-13T14:05:19.499156711Z caller=main.go:629 msg="Completed loading of configuration file" filename=/etc/prometheus.yml
level=info ts=2018-09-13T14:05:19.499228186Z caller=main.go:502 msg="Server is ready to receive web requests."הבעיה העיקרית בתהליך השחזור היא צריכת הזיכרון הגבוהה. למרות שהשרת יכול בדרך כלל לעבוד ביציבות עם אותה כמות זיכרון, כאשר הוא קורס ייתכן שהוא לא יוכל להתאושש עקב OOM. הפתרון היחיד שמצאתי היה להשבית את איסוף הנתונים, להפעיל את השרת מחדש, לתת לו להתאושש ולאתחל מחדש כאשר האיסוף מופעל.
להתחמם
התנהגות נוספת שיש לשים לב אליה במהלך החימום היא היחס בין ביצועים נמוכים לצריכת משאבים גבוהה מיד לאחר ההפעלה. ראיתי שימוש משמעותי במעבד ובזיכרון במהלך חלק מההפעלהים, אך לא כולם.
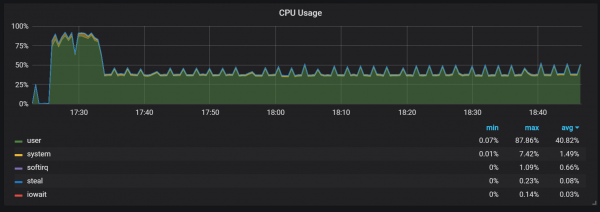
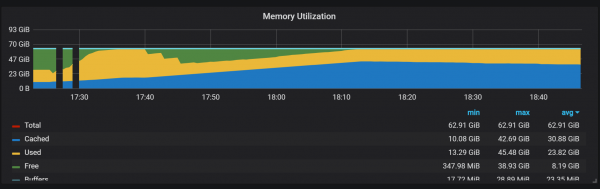
ירידות בשימוש בזיכרון מצביעות על כך ש-Prometheus אינו מסוגל להגדיר את כל האוספים מההתחלה, וחלק מהמידע אובד.
לא הבנתי בדיוק את הסיבות לעומס הגבוה על המעבד והזיכרון. אני חושד שזה קשור ליצירת סדרות זמן חדשות בבלוק הראש בתדירות גבוהה.
קפיצות עומס על המעבד
בנוסף לדחיסות, שיוצרות עומס קלט/פלט גבוה למדי, שמתי לב לקפיצות משמעותיות בעומס המעבד כל שתי דקות. הקפיצות ארוכות יותר כאשר הזרימה הנכנסת גבוהה, ונראה שהן נגרמות על ידי אוסף הזבל של Go, לפחות חלק מהליבות מנוצלות במלואן.
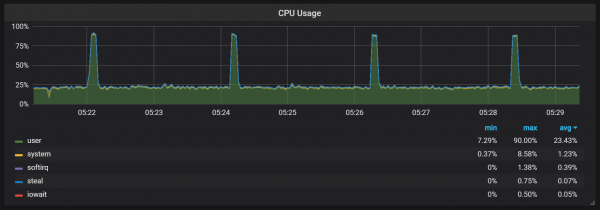
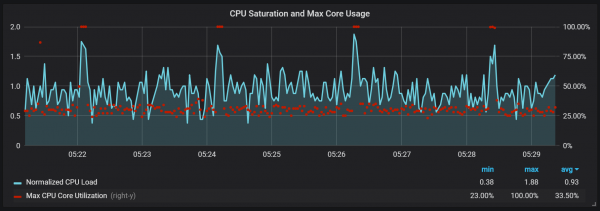
קפיצות אלו אינן כה חסרות משמעות. נראה שכאשר הן מתרחשות, נקודת הכניסה הפנימית ומדדי פרומתאוס הופכים ללא זמינים, מה שגורם לירידה בנתונים במהלך אותן תקופות זמן.
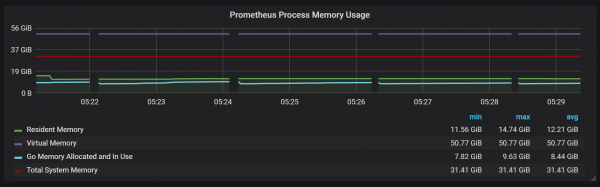
ניתן גם להבחין שיצואן פרומתאוס נתקע למשך שנייה אחת.
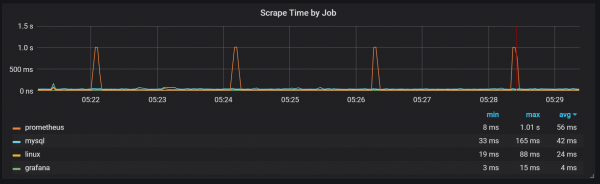
אנו יכולים לראות קורלציות עם איסוף אשפה (GC).
מסקנה
ה-TSDB ב-Prometheus 2 מהיר, מסוגל להתמודד עם מיליוני סדרות זמן ובמקביל אלפי כתיבות לשנייה באמצעות חומרה צנועה למדי. ניצול ה-CPU וה-Disk I/O גם הוא מרשים. הדוגמה שלי הראתה עד 200 מדדים לשנייה לכל ליבה בשימוש.
כשמתכננים הרחבה, צריך לזכור שצריך מספיק זיכרון, והוא צריך להיות זיכרון אמיתי. כמות הזיכרון שנעשה בה שימוש כפי שראיתי הייתה כ-5 ג'יגה-בייט לכל 100 כתיבות לשנייה של תעבורה נכנסת, מה ששילוב עם מטמון מערכת ההפעלה נתן כ-000 ג'יגה-בייט של זיכרון תפוס.
כמובן, עדיין יש הרבה עבודה לעשות כדי לרסן את קפיצות ה-CPU וה-I/O של הדיסק, וזה לא מפתיע בהתחשב בצעירותו של TSDB Prometheus 2 בהשוואה ל-InnoDB, TokuDB, RocksDB ו-WiredTiger, אך לכולם היו בעיות דומות בתחילת מחזור חייהם.
מקור: www.habr.com
