


Prometheus 2 の時系列データベース (TSDB) は、データ蓄積速度、クエリ実行、リソース効率の点で Prometheus 2 の v1 ストレージに比べて大幅な改善をもたらしたエンジニアリング ソリューションの優れた例です。 私たちは Prometheus 2 を Percona Monitoring and Management (PMM) に実装しており、Prometheus 2 TSDB のパフォーマンスを理解する機会がありました。 この記事では、これらの観察結果について説明します。
Prometheus の平均ワークロード
汎用データベースの扱いに慣れている人にとって、典型的な Prometheus ワークロードは非常に興味深いものです。 データの蓄積速度は安定する傾向があります。通常、監視しているサービスはほぼ同じ数のメトリクスを送信し、インフラストラクチャの変化は比較的ゆっくりです。
情報の要求はさまざまなソースから行われる場合があります。 アラートなどの一部のものも、安定した予測可能な値を目指しています。 ほとんどのワークロードには当てはまりませんが、ユーザー要求などのその他の要求によってバーストが発生する可能性があります。
負荷試験
テスト中はデータを蓄積できることに重点を置きました。 次のスクリプトを使用して、Go 2.3.2 (PMM 1.10.1 の一部として) でコンパイルされた Prometheus 1.14 を Linode サービスにデプロイしました。 。 最も現実的な負荷を生成するには、これを使用します。 実際の負荷(Sysbench TPC-Cテスト)をかけた複数のMySQLノードを起動しました。各ノードは10個のノードをエミュレートしています。 Linux/MySQL。
以下のテストはすべて、32 つの仮想コアと 20 GB のメモリを備えた Linode サーバーで実行され、800 の MySQL インスタンスを監視する 440 の負荷シミュレーションを実行しました。 Prometheus の用語では、380 のターゲット、1,7 秒あたり XNUMX のスクレイピング、XNUMX 秒あたり XNUMX 万のレコード、および XNUMX 万のアクティブな時系列になります。
デザイン
Prometheus 1.x で使用されているものを含む、従来のデータベースの通常のアプローチは次のとおりです。 。 負荷を処理するのに十分でない場合、待ち時間が長くなり、一部のリクエストは失敗します。 Prometheus 2 のメモリ使用量はキーで設定可能 storage.tsdb.min-block-duration、ディスクにフラッシュする前に録音をメモリに保持する時間を決定します (デフォルトは 2 時間)。 必要なメモリの量は、正味の受信ストリームに追加される時系列、ラベル、およびスクレイピングの数によって異なります。 ディスク容量の観点から、Prometheus はレコード (サンプル) ごとに 3 バイトを使用することを目指しています。 一方で、メモリ要件ははるかに高くなります。
ブロック サイズを構成することは可能ですが、手動で構成することはお勧めできません。そのため、ワークロードに必要なだけのメモリを Prometheus に与える必要があります。
メトリクスの受信ストリームをサポートするのに十分なメモリがない場合、Prometheus がメモリ不足になるか、OOM キラーがメモリに到達します。
Prometheus がメモリ不足になったときにクラッシュを遅らせるためにスワップを追加しても、この関数を使用すると爆発的なメモリ消費が発生するため、実際には役に立ちません。 これは Go、そのガベージ コレクター、およびスワップの処理方法に関係があると思います。
もう XNUMX つの興味深いアプローチは、プロセスの開始からカウントするのではなく、特定の時点でヘッド ブロックをディスクにフラッシュするように構成することです。
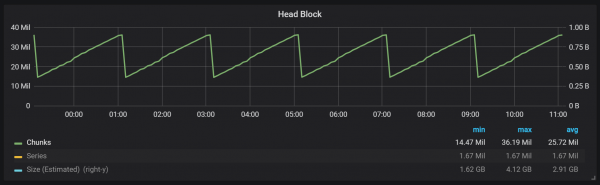
グラフからわかるように、ディスクへのフラッシュは XNUMX 時間ごとに発生します。 min-block-duration パラメーターを XNUMX 時間に変更すると、これらのリセットは XNUMX 分後から XNUMX 時間ごとに実行されます。
Prometheus インストールでこのグラフと他のグラフを使用したい場合は、これを使用できます 。 これは PMM 用に設計されましたが、わずかな変更を加えることで、あらゆる Prometheus インストールに適合します。
メモリに保存されているヘッド ブロックと呼ばれるアクティブ ブロックがあります。 古いデータを含むブロックは、次の方法で入手できます。 mmap()。 これにより、キャッシュを個別に構成する必要がなくなりますが、ヘッド ブロックが対応できるよりも古いデータをクエリする場合は、オペレーティング システム キャッシュ用に十分なスペースを残しておく必要があることも意味します。
これは、Prometheus の仮想メモリの消費量がかなり多くなる可能性があることも意味しますが、これは心配する必要はありません。
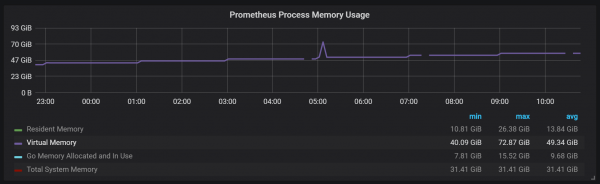
もう 2.3.2 つの興味深い設計ポイントは、WAL (ログ先行書き込み) の使用です。 ストレージのドキュメントからわかるように、Prometheus はクラッシュを回避するために WAL を使用します。 残念ながら、データの生存性を保証するための具体的なメカニズムは十分に文書化されていません。 Prometheus バージョン 10 は、XNUMX 秒ごとに WAL をディスクにフラッシュしますが、このオプションはユーザーが構成できません。
圧縮
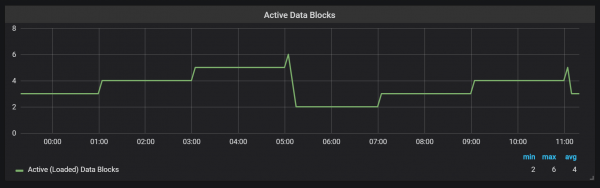
Prometheus TSDB は LSM (Log Structured Merge) ストアのように設計されています。ヘッド ブロックは定期的にディスクにフラッシュされますが、クエリ中にあまりにも多くのブロックがスキャンされることを避けるために、圧縮メカニズムが複数のブロックを結合します。 ここでは、XNUMX 日負荷をかけた後にテスト システム上で観察されたブロックの数を確認できます。
ストアについて詳しく知りたい場合は、meta.json ファイルを調べることができます。このファイルには、利用可能なブロックとその生成方法に関する情報が含まれています。
{
"ulid": "01CPZDPD1D9R019JS87TPV5MPE",
"minTime": 1536472800000,
"maxTime": 1536494400000,
"stats": {
"numSamples": 8292128378,
"numSeries": 1673622,
"numChunks": 69528220
},
"compaction": {
"level": 2,
"sources": [
"01CPYRY9MS465Y5ETM3SXFBV7X",
"01CPYZT0WRJ1JB1P0DP80VY5KJ",
"01CPZ6NR4Q3PDP3E57HEH760XS"
],
"parents": [
{
"ulid": "01CPYRY9MS465Y5ETM3SXFBV7X",
"minTime": 1536472800000,
"maxTime": 1536480000000
},
{
"ulid": "01CPYZT0WRJ1JB1P0DP80VY5KJ",
"minTime": 1536480000000,
"maxTime": 1536487200000
},
{
"ulid": "01CPZ6NR4Q3PDP3E57HEH760XS",
"minTime": 1536487200000,
"maxTime": 1536494400000
}
]
},
"version": 1
}Prometheus の圧縮は、ヘッド ブロックがディスクにフラッシュされる時間に関連付けられます。 この時点で、そのような操作がいくつか実行される場合があります。
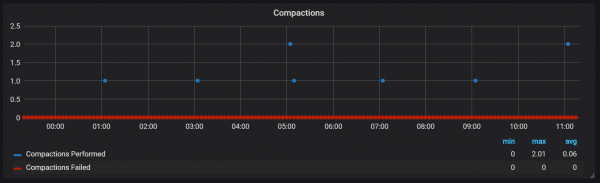
圧縮にはいかなる制限もないようで、実行中に大きなディスク I/O スパイクが発生する可能性があります。
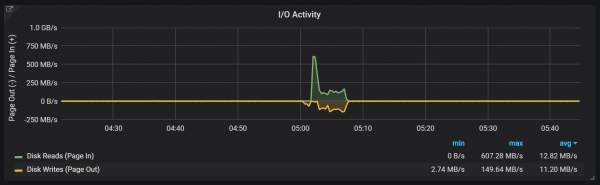
CPU負荷のスパイク
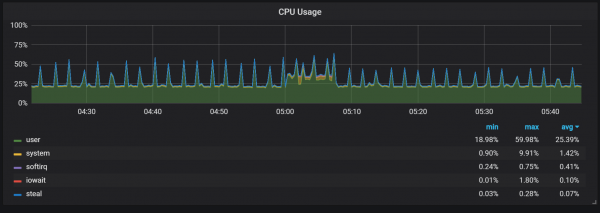
もちろん、これはシステムの速度にかなり悪影響を及ぼし、LSM ストレージにとっても深刻な課題を引き起こします。それは、過度のオーバーヘッドを発生させずに、高いリクエスト レートをサポートするために圧縮をどのように行うかということです。
圧縮プロセスでのメモリの使用も非常に興味深いようです。
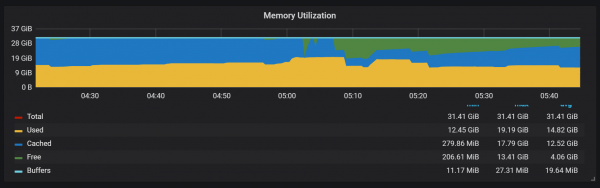
圧縮後、メモリの大部分がキャッシュ状態からフリー状態にどのように変化するかがわかります。これは、潜在的に貴重な情報がそこから削除されていることを意味します。 ここで使われるのか気になる fadvice() それとも他の最小化手法が原因でしょうか、それとも圧縮中に破壊されたブロックからキャッシュが解放されたためでしょうか?
障害後の回復
障害からの回復には時間がかかりますが、それには十分な理由があります。 25 秒あたり XNUMX 万レコードの受信ストリームの場合、SSD ドライブを考慮してリカバリが実行されるまで約 XNUMX 分間待つ必要がありました。
level=info ts=2018-09-13T13:38:14.09650965Z caller=main.go:222 msg="Starting Prometheus" version="(version=2.3.2, branch=v2.3.2, revision=71af5e29e815795e9dd14742ee7725682fa14b7b)"
level=info ts=2018-09-13T13:38:14.096599879Z caller=main.go:223 build_context="(go=go1.10.1, user=Jenkins, date=20180725-08:58:13OURCE)"
level=info ts=2018-09-13T13:38:14.096624109Z caller=main.go:224 host_details="(Linux 4.15.0-32-generic #35-Ubuntu SMP Fri Aug 10 17:58:07 UTC 2018 x86_64 1bee9e9b78cf (none))"
level=info ts=2018-09-13T13:38:14.096641396Z caller=main.go:225 fd_limits="(soft=1048576, hard=1048576)"
level=info ts=2018-09-13T13:38:14.097715256Z caller=web.go:415 component=web msg="Start listening for connections" address=:9090
level=info ts=2018-09-13T13:38:14.097400393Z caller=main.go:533 msg="Starting TSDB ..."
level=info ts=2018-09-13T13:38:14.098718401Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536530400000 maxt=1536537600000 ulid=01CQ0FW3ME8Q5W2AN5F9CB7R0R
level=info ts=2018-09-13T13:38:14.100315658Z caller=web.go:467 component=web msg="router prefix" prefix=/prometheus
level=info ts=2018-09-13T13:38:14.101793727Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536732000000 maxt=1536753600000 ulid=01CQ78486TNX5QZTBF049PQHSM
level=info ts=2018-09-13T13:38:14.102267346Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536537600000 maxt=1536732000000 ulid=01CQ78DE7HSQK0C0F5AZ46YGF0
level=info ts=2018-09-13T13:38:14.102660295Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536775200000 maxt=1536782400000 ulid=01CQ7SAT4RM21Y0PT5GNSS146Q
level=info ts=2018-09-13T13:38:14.103075885Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536753600000 maxt=1536775200000 ulid=01CQ7SV8WJ3C2W5S3RTAHC2GHB
level=error ts=2018-09-13T14:05:18.208469169Z caller=wal.go:275 component=tsdb msg="WAL corruption detected; truncating" err="unexpected CRC32 checksum d0465484, want 0" file=/opt/prometheus/data/.prom2-data/wal/007357 pos=15504363
level=info ts=2018-09-13T14:05:19.471459777Z caller=main.go:543 msg="TSDB started"
level=info ts=2018-09-13T14:05:19.471604598Z caller=main.go:603 msg="Loading configuration file" filename=/etc/prometheus.yml
level=info ts=2018-09-13T14:05:19.499156711Z caller=main.go:629 msg="Completed loading of configuration file" filename=/etc/prometheus.yml
level=info ts=2018-09-13T14:05:19.499228186Z caller=main.go:502 msg="Server is ready to receive web requests."回復プロセスの主な問題は、大量のメモリ消費です。 通常の状況では、サーバーは同じ量のメモリで安定して動作しますが、クラッシュした場合、OOM が原因で回復できない可能性があります。 私が見つけた唯一の解決策は、データ収集を無効にしてサーバーを起動し、回復させて収集を有効にして再起動することでした。
ウォーミングアップ
ウォームアップ中に留意すべきもう XNUMX つの動作は、開始直後の低パフォーマンスと高いリソース消費との関係です。 すべてではありませんが、一部の起動中に、CPU とメモリに重大な負荷がかかることが観察されました。
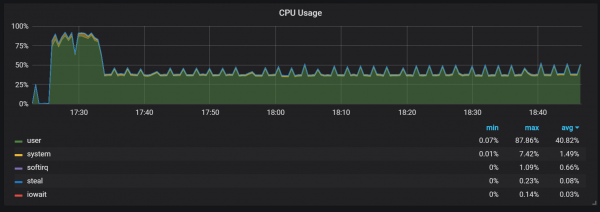
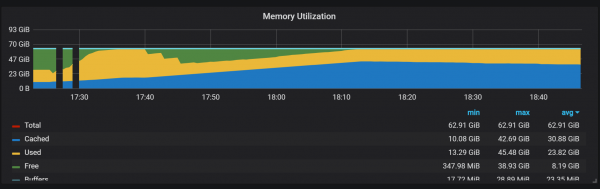
メモリ使用量のギャップは、Prometheus が最初からすべてのコレクションを構成できず、一部の情報が失われることを示しています。
CPU とメモリの負荷が高い正確な理由はわかりません。 これはヘッドブロック内で高頻度で新たな時系列が作成されたためではないかと思われます。
CPU負荷が急増する
かなり高い I/O 負荷を生み出す圧縮に加えて、XNUMX 分ごとに CPU 負荷が大幅に急増していることに気付きました。 入力フローが多いときはバーストが長くなり、少なくとも一部のコアが完全にロードされている状態で Go のガベージ コレクターが原因であると考えられます。
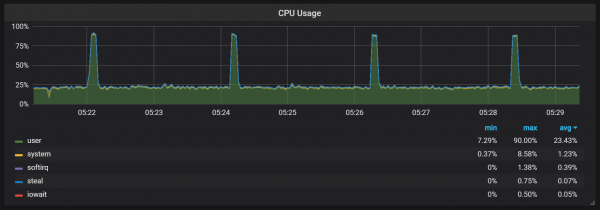
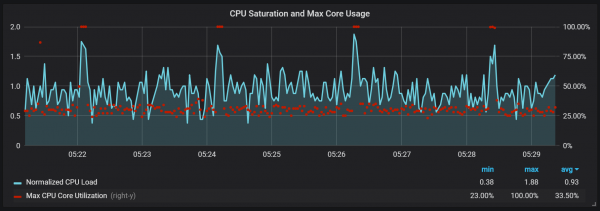
これらの飛躍はそれほど重要ではありません。 これらが発生すると、Prometheus の内部エントリ ポイントとメトリクスが利用できなくなり、同じ期間にデータ ギャップが発生するようです。
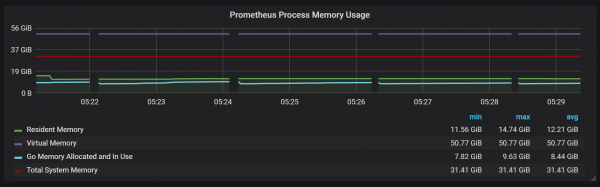
Prometheus エクスポータが XNUMX 秒間シャットダウンすることもわかります。
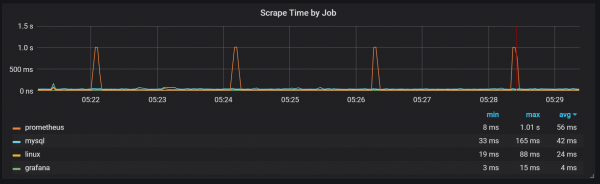
ガベージ コレクション (GC) との相関関係に気づくことができます。
まとめ
Prometheus 2 の TSDB は高速で、かなり控えめなハードウェアを使用して、200 秒あたり数百万の時系列と同時に数千のレコードを処理できます。 CPU とディスク I/O 使用率も印象的です。 私の例では、使用されるコアごとに 000 秒あたり最大 XNUMX メトリクスが示されました。
拡張を計画するには、十分な量のメモリを覚えておく必要があります。これは実メモリである必要があります。 私が観察した使用メモリ量は、受信ストリームの 5 秒あたり 100 レコードあたり約 000 GB で、オペレーティング システムのキャッシュと合わせると約 8 GB のメモリが占有されていました。
もちろん、CPU とディスク I/O のスパイクを抑えるためにやるべきことはまだたくさんあります。TSDB Prometheus 2 が InnoDB、TokuDB、RocksDB、WiredTiger と比べていかに若いかを考えると、これは驚くべきことではありませんが、どれも同様の機能を備えていました。ライフサイクルの早い段階で問題が発生します。
出所: habr.com
