

休暇が終わり、Istio Service Mesh シリーズの XNUMX 回目の投稿に戻ります。

今日のトピックはサーキットブレーカーです。ロシア語の電気工学に翻訳すると「サーキットブレーカー」、一般用語では「サーキットブレーカー」を意味します。 Istio でのみ、このマシンは短絡または過負荷の回路ではなく、障害のあるコンテナを切断しません。
これが理想的にどのように機能するか
マイクロサービスが、たとえば OpenShift プラットフォーム内で Kubernetes によって管理される場合、負荷に応じて自動的にスケールアップおよびスケールダウンされます。 マイクロサービスはポッド内で実行されるため、XNUMX つのエンドポイント上にコンテナ化されたマイクロサービスの複数のインスタンスが存在することができ、Kubernetes がリクエストをルーティングし、それらの間で負荷分散を行います。 そして、理想的には、これらすべてが完璧に機能するはずです。
マイクロサービスは小さくて一時的なものであることを覚えています。 一時性とは、ここでは現れたり消えたりすることの容易さを意味しますが、過小評価されることがよくあります。 ポッド内でマイクロサービスの別のインスタンスが誕生したり消滅したりすることは非常に予想されることであり、OpenShift と Kubernetes はこれをうまく処理し、すべてがうまく機能しますが、これも理論上の話です。
実際の仕組み
ここで、マイクロサービスの特定のインスタンス (コンテナー) が使用できなくなったと想像してください。応答しないか (エラー 503)、あるいはさらに不快なことに、応答はしますが、速度が遅すぎます。 つまり、問題が発生したり、リクエストに応答しなくなったりしますが、プールから自動的に削除されるわけではありません。 この場合はどうすればよいでしょうか? 再試行するには? ルーティング スキームから削除する必要がありますか? そして、「遅すぎる」とは何を意味しますか?その数字はどれくらいで、誰がそれを決定するのでしょうか? 一旦休憩して、後でもう一度試してみてはいかがでしょうか? もしそうなら、どれくらい後ですか?
Istio のプールの排出とは何ですか
そして、ここで Istio がサーキット ブレーカー保護マシンを使用して救助に来ます。これは、ルーティングと負荷分散のリソース プールから障害のあるコンテナを一時的に削除し、プールの排出手順を実装します。
Istio は外れ値検出戦略を使用して、ラインから外れているカーブ ポッドを検出し、スリープ ウィンドウと呼ばれる指定された期間、リソース プールからそれらを削除します。
OpenShift プラットフォーム上の Kubernetes でこれがどのように機能するかを示すために、リポジトリ内の例から通常に動作しているマイクロサービスのスクリーンショットから始めましょう。 。 ここには、v1 と v2 の XNUMX つのポッドがあり、それぞれが XNUMX つのコンテナーを実行しています。 Istio ルーティング ルールが使用されていない場合、Kubernetes はデフォルトで均等にバランスのとれたラウンドロビン ルーティングを使用します。
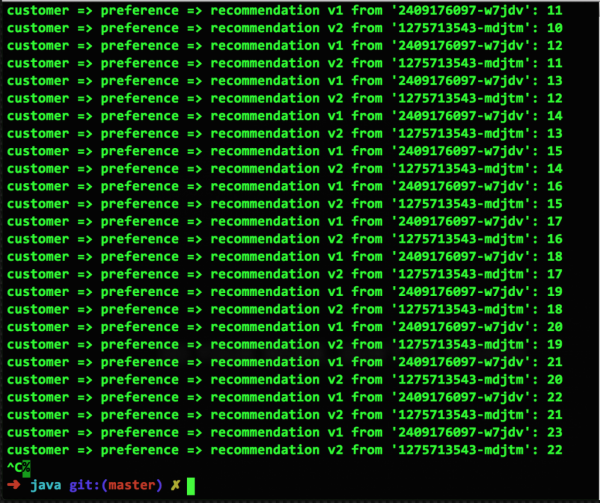
クラッシュに備える
プールの排出を実行する前に、Istio ルーティング ルールを作成する必要があります。 ポッド間でリクエストを 50/50 の比率で分散したいとします。 さらに、次のように v2 コンテナの数を XNUMX つから XNUMX つに増やします。
oc scale deployment recommendation-v2 --replicas=2 -n tutorial
次に、トラフィックがポッド間で 50/50 の比率で分散されるようにルーティング ルールを設定します。

このルールの結果は次のようになります。
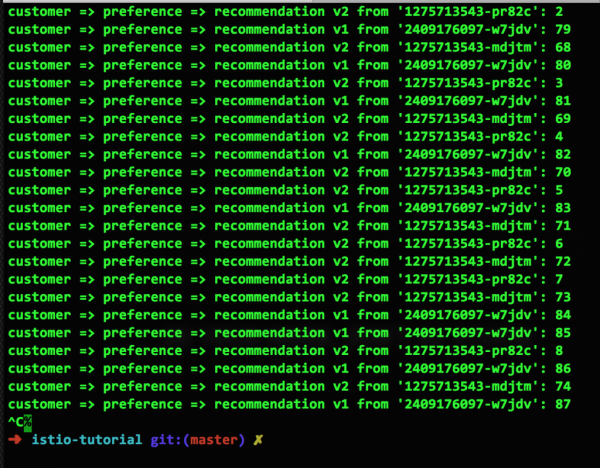
この画面が 50/50 ではなく 14:9 であるという事実に欠点を見つけることもできますが、時間の経過とともに状況は改善されます。
不具合を起こす
次に、2 つの v1 コンテナのうち 2 つを無効にして、正常な v2 コンテナが XNUMX つ、正常な vXNUMX コンテナが XNUMX つ、障害のある vXNUMX コンテナが XNUMX つになるようにします。
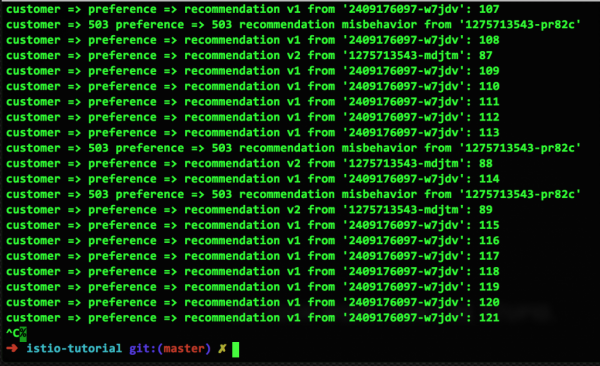
不具合の修正
コンテナに欠陥があるため、プールの排出の時期が来ました。 非常に単純な構成を使用して、この失敗したコンテナーをルーティング スキームから 15 秒間除外し、コンテナーが正常な状態に戻ることを期待します (再起動またはパフォーマンスの復元のいずれか)。 この構成とその作業の結果は次のようになります。

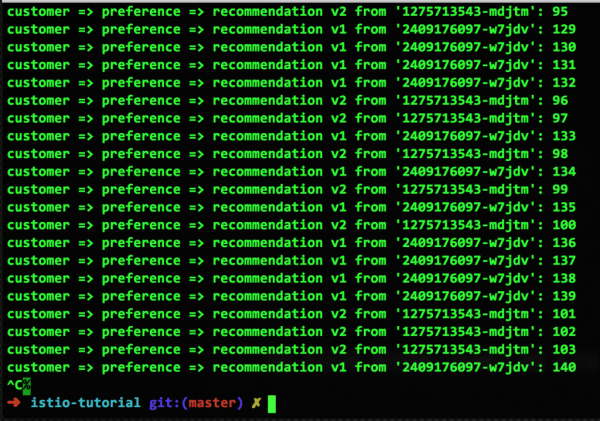
ご覧のとおり、失敗した v2 コンテナはプールから削除されたため、リクエストのルーティングには使用されなくなりました。 ただし、15 秒後には自動的にプールに戻ります。 実際、私たちはプールの排出がどのように機能するかを示したばかりです。
建築を作り始めましょう
プールの排出を Istio の監視機能と組み合わせることで、障害のあるコンテナを自動的に置き換えるフレームワークの構築を開始して、ダウンタイムや障害をなくすことはできないにしても、削減することができます。
NASA には「失敗は選択肢ではない」という声高なモットーがあり、その著者はフライトディレクターであると考えられています。 。 これはロシア語に翻訳すると「失敗は選択肢にない」という意味で、十分な意志があればすべてはうまくいくという意味です。 しかし、現実の生活では、失敗はただ起こるものではなく、どこでも、あらゆるものにおいて避けられません。 そして、マイクロサービスの場合、それらにどのように対処すればよいのでしょうか? 私たちの意見では、意志の力ではなく、コンテナの機能に依存する方がよいと考えています。 , と .
上で書いたように、Istio はサーキット ブレーカーの概念を実装しており、これは物理世界で十分に実証されています。 そして、電気サーキット ブレーカーが回路の問題セクションをオフにするのと同じように、エンドポイントに何か問題がある場合 (たとえば、サーバーがクラッシュしたり、サーバーが壊れ始めたりした場合)、Istio のソフトウェア サーキット ブレーカーは、リクエストのストリームと問題のあるコンテナの間の接続を開きます。減速する。
さらに、XNUMX 番目のケースでは、XNUMX つのコンテナのブレーキがそれにアクセスするサービスに連鎖的な遅延を引き起こし、その結果、システム全体のパフォーマンスが低下するだけでなく、繰り返しのすでに実行速度が遅いサービスにリクエストを送信すると、状況が悪化するだけです。
理論上のサーキットブレーカー
サーキット ブレーカーは、エンドポイントへのリクエストのフローを制御するプロキシです。 このポイントが動作しなくなるか、指定された設定によっては速度が低下し始めると、プロキシはコンテナとの接続を切断します。 その後、トラフィックは単に負荷分散により他のコンテナにリダイレクトされます。 接続は、特定のスリープ ウィンドウ (たとえば XNUMX 分間) の間開いたままになり、その後は半分開いたと見なされます。 次のリクエストを送信しようとすると、接続のその後の状態が決まります。 サービスにすべて問題がない場合、接続は動作状態に戻り、再び閉じられます。 それでもサービスに問題がある場合は、接続が切断され、スリープ ウィンドウが再び有効になります。 簡略化されたサーキット ブレーカーの状態図は次のようになります。
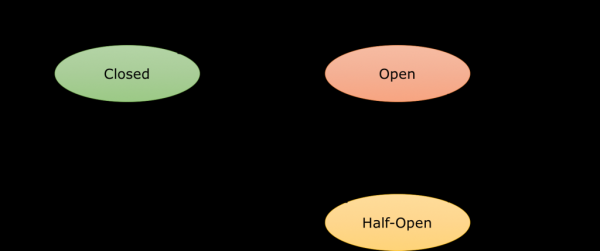
ここで重要なのは、これはすべて、いわばシステム アーキテクチャのレベルで発生するということです。 したがって、ある時点で、応答としてデフォルト値を提供するか、可能であればサービスの存在を無視するなど、アプリケーションに Circuit Breaker で動作するように教える必要があります。 これにはバルクヘッド パターンが使用されますが、それについてはこの記事の範囲を超えています。
サーキットブレーカーの実践
たとえば、OpenShift 上でレコメンデーション マイクロサービスの 1 つのバージョンを実行します。 バージョン 2 は正常に動作しますが、vXNUMX ではサーバーの速度低下をシミュレートするために遅延を組み込みます。 結果を表示するには、ツールを使用します :
siege -r 2 -c 20 -v customer-tutorial.$(minishift ip).nip.io
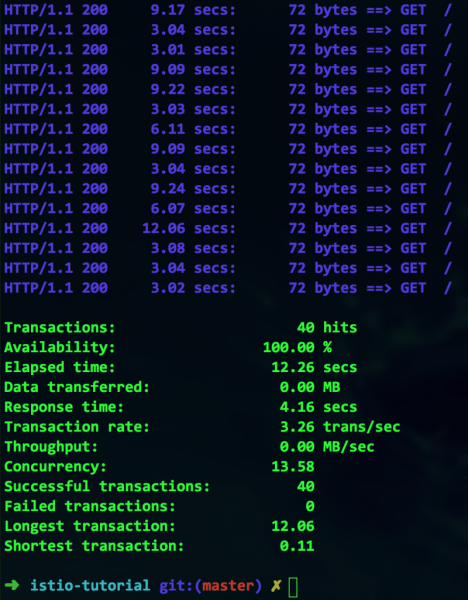
すべてが機能しているように見えますが、コストはいくらでしょうか? 一見したところ、可用性は 100% であるように見えますが、よく見てみると、最大トランザクション期間は 12 秒にもなります。 これは明らかにボトルネックであり、拡張する必要があります。
これを行うには、Istio を使用して、遅いコンテナーへの呼び出しを排除します。 これは、Circuit Breaker を使用した対応する構成がどのように見えるかです。

httpMaxRequestsPerConnection パラメータを含む最後の行は、既存の接続に加えて別の (503 番目の) 接続を作成しようとするときに接続を切断する必要があることを示します。 私たちのコンテナは遅いサービスをシミュレートしているため、そのような状況が定期的に発生し、Istio は XNUMX エラーを返しますが、これが siege で表示される内容です。
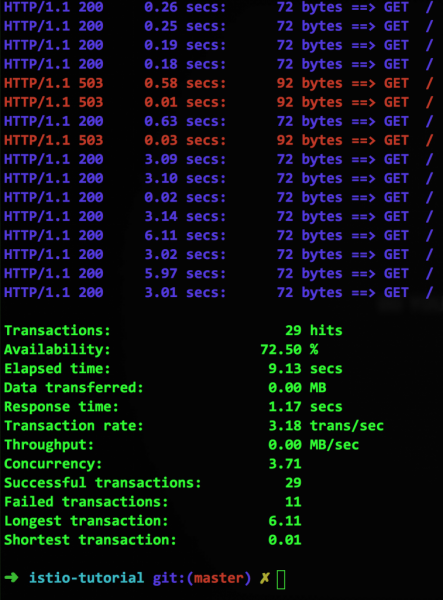
OK、サーキットブレーカーはできた、次は何をする?
そこで、サービス自体のソースコードには一切触れずに自動シャットダウンを実装しました。 サーキット ブレーカーと上記のプール排出手順を使用すると、ブレーキ コンテナーが通常に戻るまでリソース プールから削除し、指定した頻度でステータスを確認できます。この例では、これは XNUMX 分です (sleepWindow パラメーター)。
503 エラーに応答するアプリケーションの機能は依然としてソース コード レベルで設定されていることに注意してください。 サーキットブレーカーを使用するには、状況に応じてさまざまな戦略があります。
次の投稿では: すでに組み込まれている、または Istio に簡単に追加できるトレースとモニタリング、およびシステムに意図的にエラーを導入する方法について説明します。
出所: habr.com
