


Basis data seri wektu (TSDB) ing Prometheus 2 minangka conto solusi teknik sing nawakake perbaikan gedhe babagan panyimpenan v2 ing Prometheus 1 babagan kacepetan akumulasi data, eksekusi pitakon, lan efisiensi sumber daya. Kita ngetrapake Prometheus 2 ing Percona Monitoring and Management (PMM) lan aku duwe kesempatan kanggo ngerti kinerja Prometheus 2 TSDB. Ing artikel iki aku bakal ngomong babagan asil pengamatan kasebut.
Rata-rata Beban Kerja Prometheus
Kanggo sing digunakake kanggo ngurusi database tujuan umum, beban kerja Prometheus sing khas cukup menarik. Tingkat akumulasi data cenderung stabil: biasane layanan sing dipantau ngirim kira-kira jumlah metrik sing padha, lan prasarana owah-owahan kanthi alon.
Panyuwunan informasi bisa teka saka macem-macem sumber. Sawetara, kayata tandha, uga ngupayakake nilai sing stabil lan bisa ditebak. Liyane, kayata panjalukan pangguna, bisa nyebabake bledosan, sanajan iki ora kedadeyan kanggo umume beban kerja.
Tes beban
Sajrone testing, aku fokus ing kemampuan kanggo nglumpukake data. Aku disebaraké Prometheus 2.3.2 nyawiji karo Go 1.10.1 (minangka bagéan saka PMM 1.14) ing layanan Linode nggunakake script iki: . Kanggo generasi beban paling nyata, nggunakake iki Aku ngluncurake sawetara simpul MySQL kanthi beban nyata (Sysbench TPC-C Test), sing saben-saben niru 10 simpul Linux/MySQL.
Kabeh tes ing ngisor iki ditindakake ing server Linode kanthi wolung intine virtual lan memori 32 GB, mlaku 20 simulasi beban ngawasi rong atus instan MySQL. Utawa, ing istilah Prometheus, 800 target, 440 scrape per detik, 380 ewu rekaman per detik, lan 1,7 yuta seri wektu aktif.
Design
Pendekatan biasanipun saka database tradisional, kalebu siji digunakake dening Prometheus 1.x, iku kanggo . Yen ora cukup kanggo nangani beban, sampeyan bakal ngalami latensi dhuwur lan sawetara panjaluk bakal gagal. Panggunaan memori ing Prometheus 2 bisa dikonfigurasi liwat tombol storage.tsdb.min-block-duration, sing nemtokake suwene rekaman bakal disimpen ing memori sadurunge disiram menyang disk (standar yaiku 2 jam). Jumlah memori sing dibutuhake bakal gumantung saka jumlah seri wektu, label, lan scrapes sing ditambahake menyang stream mlebu net. Ing babagan ruang disk, Prometheus duwe tujuan nggunakake 3 bita saben rekaman (sampel). Ing tangan liyane, syarat memori luwih dhuwur.
Senajan iku bisa kanggo ngatur ukuran pemblokiran, iku ora dianjurake kanggo ngatur kanthi manual, supaya sampeyan dipeksa kanggo menehi Prometheus minangka akeh memori minangka mbutuhake kanggo workload Panjenengan.
Yen ora ana memori sing cukup kanggo ndhukung aliran metrik sing mlebu, Prometheus bakal ilang saka memori utawa pembunuh OOM bakal entuk.
Nambahake swap kanggo tundha kacilakan nalika Prometheus kehabisan memori ora bisa mbantu, amarga nggunakake fungsi iki nyebabake konsumsi memori sing mbledhos. Aku mikir iki ana hubungane karo Go, tukang sampah lan cara ngatasi swap.
Pendekatan liyane sing menarik yaiku ngatur blok sirah supaya disiram menyang disk ing wektu tartamtu, tinimbang ngetung saka wiwitan proses.
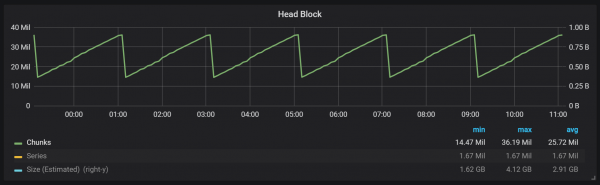
Nalika sampeyan bisa ndeleng saka grafik, flushes menyang disk dumadi saben rong jam. Yen sampeyan ngganti parameter durasi blok-min dadi siji jam, banjur reset iki bakal kedadeyan saben jam, diwiwiti sawise setengah jam.
Yen sampeyan pengin nggunakake iki lan grafik liyane ing instalasi Prometheus, sampeyan bisa nggunakake iki . Iki dirancang kanggo PMM nanging, kanthi modifikasi cilik, pas karo instalasi Prometheus.
Kita duwe blok aktif sing disebut blok sirah sing disimpen ing memori; pamblokiran karo data lawas kasedhiya liwat mmap(). Iki ngilangi kabutuhan kanggo ngatur cache kanthi kapisah, nanging uga tegese sampeyan kudu ninggalake papan sing cukup kanggo cache sistem operasi yen sampeyan pengin takon data sing luwih lawas tinimbang sing bisa ditampung ing blok sirah.
Iki uga tegese Prometheus konsumsi memori virtual bakal katon cukup dhuwur, kang ora soko padha sumelang ing bab.
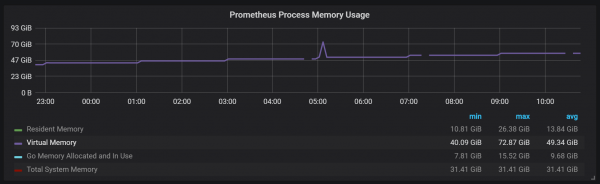
Titik desain liyane sing menarik yaiku nggunakake WAL (tulis ahead log). Minangka sampeyan bisa ndeleng saka dokumentasi panyimpenan, Prometheus nggunakake WAL supaya ora kacilakan. Mekanisme khusus kanggo njamin kaslametan data, sayangé, ora didokumentasikan kanthi apik. Prometheus versi 2.3.2 flushes WAL menyang disk saben 10 detik lan pilihan iki ora pangguna configurable.
Compactions
Prometheus TSDB dirancang kaya toko LSM (Log Structured Merge): blok sirah disiram sacara periodik menyang disk, dene mekanisme pemadatan nggabungake pirang-pirang blok supaya ora mindhai akeh blok sajrone pitakon. Ing kene sampeyan bisa ndeleng jumlah blok sing diamati ing sistem tes sawise mbukak dina.
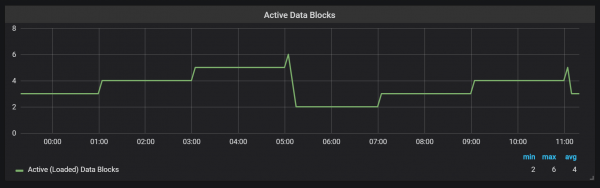
Yen sampeyan pengin sinau luwih lengkap babagan toko, sampeyan bisa mriksa file meta.json, sing duwe informasi babagan blok sing kasedhiya lan kepiye kedadeyane.
{
"ulid": "01CPZDPD1D9R019JS87TPV5MPE",
"minTime": 1536472800000,
"maxTime": 1536494400000,
"stats": {
"numSamples": 8292128378,
"numSeries": 1673622,
"numChunks": 69528220
},
"compaction": {
"level": 2,
"sources": [
"01CPYRY9MS465Y5ETM3SXFBV7X",
"01CPYZT0WRJ1JB1P0DP80VY5KJ",
"01CPZ6NR4Q3PDP3E57HEH760XS"
],
"parents": [
{
"ulid": "01CPYRY9MS465Y5ETM3SXFBV7X",
"minTime": 1536472800000,
"maxTime": 1536480000000
},
{
"ulid": "01CPYZT0WRJ1JB1P0DP80VY5KJ",
"minTime": 1536480000000,
"maxTime": 1536487200000
},
{
"ulid": "01CPZ6NR4Q3PDP3E57HEH760XS",
"minTime": 1536487200000,
"maxTime": 1536494400000
}
]
},
"version": 1
}Compactions ing Prometheus disambungake menyang wektu pemblokiran sirah wis flushed kanggo disk. Ing wektu iki, sawetara operasi kasebut bisa ditindakake.
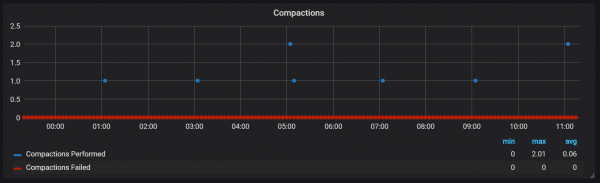
Katon sing compactions ora winates ing sembarang cara lan bisa nimbulaké gedhe disk I / O spikes sak eksekusi.
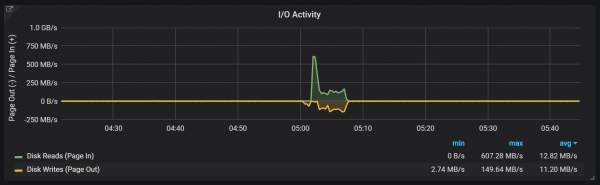
Lonjakan beban CPU
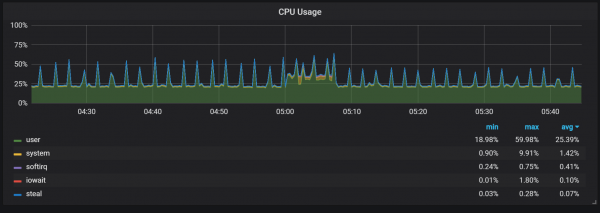
Mesthi, iki wis impact rodo negatif ing kacepetan sistem, lan uga nuduhke tantangan serius kanggo panyimpenan LSM: carane nindakake compaction kanggo ndhukung tarif request dhuwur tanpa nyebabake kakehan overhead?
Panggunaan memori ing proses compaction uga katon cukup menarik.
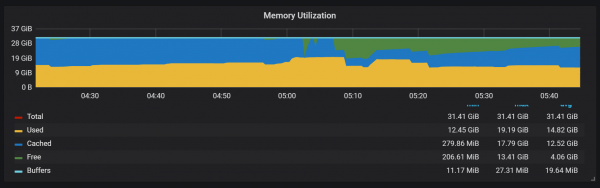
Kita bisa ndeleng carane, sawise compaction, paling saka memori owah-owahan negara saka Cached kanggo Free: iki tegese informasi duweni potensi terkenal wis dibusak saka ing kono. Penasaran yen digunakake ing kene fadvice() utawa sawetara technique minimalake liyane, utawa iku amarga cache dibebaske saka pamblokiran numpes sak compaction?
Recovery sawise Gagal
Recovery saka gagal njupuk wektu, lan kanggo alesan apik. Kanggo stream mlebu yuta cathetan per detik, aku kudu ngenteni udakara 25 menit nalika pemulihan ditindakake kanthi njupuk SSD drive.
level=info ts=2018-09-13T13:38:14.09650965Z caller=main.go:222 msg="Starting Prometheus" version="(version=2.3.2, branch=v2.3.2, revision=71af5e29e815795e9dd14742ee7725682fa14b7b)"
level=info ts=2018-09-13T13:38:14.096599879Z caller=main.go:223 build_context="(go=go1.10.1, user=Jenkins, date=20180725-08:58:13OURCE)"
level=info ts=2018-09-13T13:38:14.096624109Z caller=main.go:224 host_details="(Linux 4.15.0-32-generic #35-Ubuntu SMP Fri Aug 10 17:58:07 UTC 2018 x86_64 1bee9e9b78cf (none))"
level=info ts=2018-09-13T13:38:14.096641396Z caller=main.go:225 fd_limits="(soft=1048576, hard=1048576)"
level=info ts=2018-09-13T13:38:14.097715256Z caller=web.go:415 component=web msg="Start listening for connections" address=:9090
level=info ts=2018-09-13T13:38:14.097400393Z caller=main.go:533 msg="Starting TSDB ..."
level=info ts=2018-09-13T13:38:14.098718401Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536530400000 maxt=1536537600000 ulid=01CQ0FW3ME8Q5W2AN5F9CB7R0R
level=info ts=2018-09-13T13:38:14.100315658Z caller=web.go:467 component=web msg="router prefix" prefix=/prometheus
level=info ts=2018-09-13T13:38:14.101793727Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536732000000 maxt=1536753600000 ulid=01CQ78486TNX5QZTBF049PQHSM
level=info ts=2018-09-13T13:38:14.102267346Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536537600000 maxt=1536732000000 ulid=01CQ78DE7HSQK0C0F5AZ46YGF0
level=info ts=2018-09-13T13:38:14.102660295Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536775200000 maxt=1536782400000 ulid=01CQ7SAT4RM21Y0PT5GNSS146Q
level=info ts=2018-09-13T13:38:14.103075885Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536753600000 maxt=1536775200000 ulid=01CQ7SV8WJ3C2W5S3RTAHC2GHB
level=error ts=2018-09-13T14:05:18.208469169Z caller=wal.go:275 component=tsdb msg="WAL corruption detected; truncating" err="unexpected CRC32 checksum d0465484, want 0" file=/opt/prometheus/data/.prom2-data/wal/007357 pos=15504363
level=info ts=2018-09-13T14:05:19.471459777Z caller=main.go:543 msg="TSDB started"
level=info ts=2018-09-13T14:05:19.471604598Z caller=main.go:603 msg="Loading configuration file" filename=/etc/prometheus.yml
level=info ts=2018-09-13T14:05:19.499156711Z caller=main.go:629 msg="Completed loading of configuration file" filename=/etc/prometheus.yml
level=info ts=2018-09-13T14:05:19.499228186Z caller=main.go:502 msg="Server is ready to receive web requests."Masalah utama proses pemulihan yaiku konsumsi memori sing dhuwur. Senadyan kasunyatan sing ing kahanan normal server bisa stably karo jumlah memori sing padha, yen tubrukan bisa ora waras amarga OOM. Siji-sijine solusi sing ditemokake yaiku mateni pangumpulan data, nggawa server, supaya bisa pulih lan urip maneh kanthi aktif koleksi.
Pemanasan
Prilaku liyane sing kudu dielingi sajrone anget yaiku hubungan antara kinerja sing kurang lan konsumsi sumber daya sing dhuwur sawise wiwitan. Sajrone sawetara, nanging ora kabeh diwiwiti, aku mirsani beban serius ing CPU lan memori.
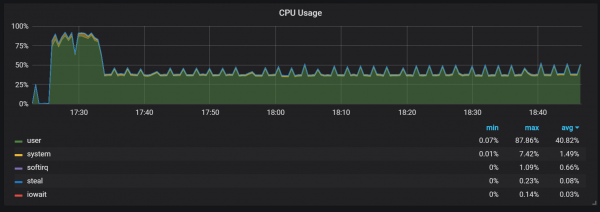
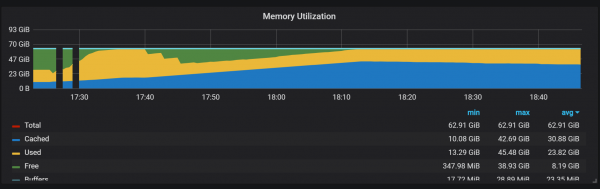
Kesenjangan ing panggunaan memori nuduhake yen Prometheus ora bisa ngatur kabeh koleksi saka wiwitan, lan sawetara informasi ilang.
Aku wis ora figured metu alesan pas kanggo CPU dhuwur lan mbukak memori. Aku curiga yen iki amarga nggawe seri wektu anyar ing blok sirah kanthi frekuensi dhuwur.
beban CPU mundhak
Saliyane compactions, kang nggawe I / O mbukak cukup dhuwur, Aku ngeweruhi spike serius ing mbukak CPU saben rong menit. Jeblugan luwih suwe nalika aliran input dhuwur lan katon amarga pangumpulan sampah Go, kanthi paling ora sawetara intine diisi kanthi lengkap.
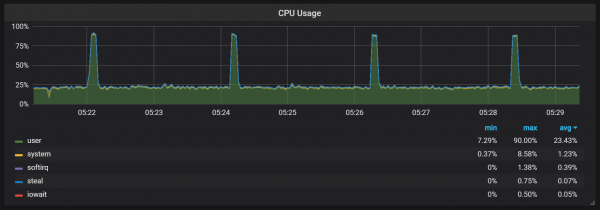
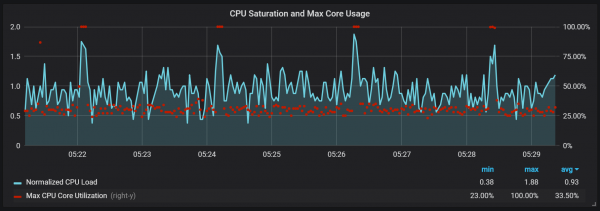
Lompat iki ora pati penting. Katon yen kedadeyan kasebut, titik entri internal Prometheus lan metrik dadi ora kasedhiya, nyebabake kesenjangan data sajrone wektu sing padha.
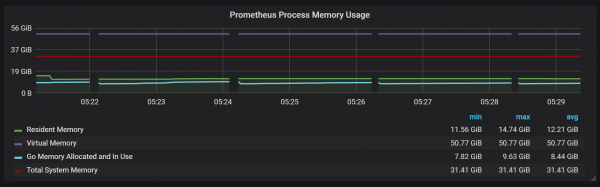
Sampeyan uga bisa sok dong mirsani sing eksportir Prometheus mati sak detik.
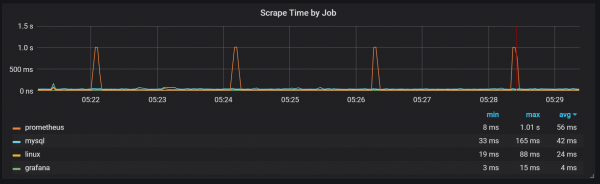
Kita bisa ngerteni hubungane karo pengumpulan sampah (GC).
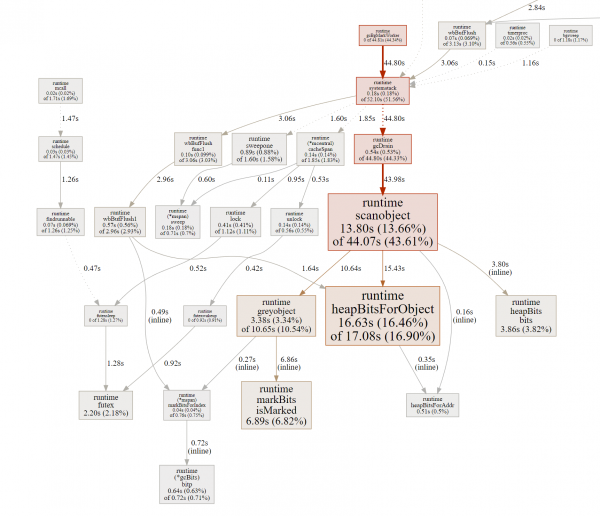
kesimpulan
TSDB ing Prometheus 2 cepet, bisa nangani mayuta-yuta seri wektu lan ing wektu sing padha ewu rekaman per detik nggunakake hardware sing cukup andhap asor. Panggunaan CPU lan disk I / O uga nyengsemaken. Contoku nuduhake nganti 200 metrik per detik saben inti sing digunakake.
Kanggo rencana expansion, sampeyan kudu ngelingi bab jumlah cukup saka memori, lan iki kudu memori nyata. Jumlah memori digunakake sing aku diamati ana bab 5 GB saben 100 cathetan per detik saka stream mlebu, kang bebarengan karo cache sistem operasi menehi bab 000 GB memori dikuwasani.
Mesthi, isih ana akeh karya sing kudu dilakoni kanggo tame CPU lan disk I / O spikes, lan iki ora ngagetne considering carane enom TSDB Prometheus 2 dibandhingake InnoDB, TokuDB, RocksDB, WiredTiger, nanging padha kabeh padha. masalah ing awal siklus urip.
Source: www.habr.com
