

Halo kabeh, jenengku Alexander, aku kerja ing CIAN minangka insinyur lan melu administrasi sistem lan otomatisasi proses infrastruktur. Ing komentar ing salah sawijining artikel sadurunge, kita dijaluk ngandhani ngendi kita entuk 4 TB log saben dina lan apa sing ditindakake. Ya, kita duwe akeh log, lan kluster infrastruktur sing kapisah wis digawe kanggo ngolah, sing ngidini kita ngatasi masalah kanthi cepet. Ing artikel iki aku bakal pirembagan bab carane kita dicocogake liwat Course saka taun kanggo bisa karo aliran tau-akeh data.
Ngendi kita miwiti?
Sajrone sawetara taun kepungkur, beban ing cian.ru wis tuwuh kanthi cepet, lan ing kuartal katelu 2018, lalu lintas sumber daya tekan 11.2 yuta pangguna unik saben wulan. Ing wektu iku, ing wektu kritis kita ilang nganti 40% saka log, kang kita ora bisa cepet ngatasi kedadean lan nglampahi akèh wektu lan gaweyan kanggo ngrampungake. Kita uga asring ora bisa nemokake sabab saka masalah, lan bakal mbaleni sawise sawetara wektu. Iku neraka lan ana sing kudu ditindakake.
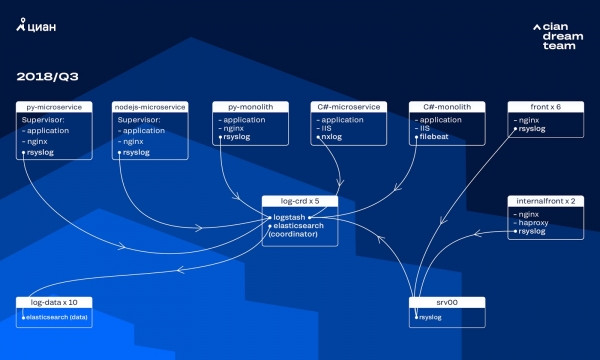
Ing wektu iku, kita nggunakake kluster 10 simpul data kanthi versi ElasticSearch 5.5.2 kanthi setelan indeks standar kanggo nyimpen log. Iki dikenalake luwih saka setahun kepungkur minangka solusi sing populer lan terjangkau: banjur aliran log ora dadi gedhe, ora ana gunane kanggo nggawe konfigurasi non-standar.
Pangolahan log sing mlebu diwenehake dening Logstash ing macem-macem port ing limang koordinator ElasticSearch. Siji indeks, preduli saka ukuran, kasusun saka limang shards. Rotasi saben jam lan saben dina diatur, minangka asil, kira-kira 100 pecahan anyar muncul ing kluster saben jam. Nalika ora ana akeh log, kluster kasebut bisa ngatasi kanthi apik lan ora ana sing nggatekake setelan kasebut.
Tantangan wutah kanthi cepet
Volume log sing digawe tansaya cepet, amarga rong proses tumpang tindih. Ing tangan siji, jumlah pangguna layanan kasebut saya tambah. Ing tangan liyane, kita wiwit aktif ngalih menyang arsitektur microservice, sawing munggah monoliths lawas kita ing C # lan Python. Sawetara rolas microservices anyar sing ngganti bagéan saka monolith kui Ngartekno luwih log kanggo kluster infrastruktur.
Iki skala sing mimpin kita menyang titik ing ngendi kluster dadi ora bisa diatur. Nalika log wiwit tekan 20 ewu pesen per detik, rotasi sing ora ana gunane nambah jumlah shards nganti 6 ewu, lan ana luwih saka 600 shards saben simpul.
Iki nyebabake masalah karo alokasi RAM, lan nalika node nabrak, kabeh shard bakal migrasi bebarengan, nambah lalu lintas lan ngemot node sing isih ana, saengga meh ora bisa nulis data menyang kluster. Lan sajrone periode iki, kita ditinggal tanpa log. Lan yen ana masalah karo server Kita kelangan 1/10 saka kluster sakabèhé. Cacahing indeks cilik sing akèh nambahi kerumitan.
Tanpa log, kita ora ngerti sebab-sebab kedadeyan kasebut lan cepet-cepet bisa mlaku maneh ing rake sing padha, lan ing ideologi tim iki ora bisa ditampa, amarga kabeh mekanisme kerja kita dirancang kanggo ngelawan - aja mbaleni maneh. masalah padha. Kanggo nindakake iki, kita butuh volume lengkap log lan pangiriman meh ing wektu nyata, amarga tim insinyur sing tugas ngawasi tandha ora mung saka metrik, nanging uga saka log. Kanggo mangerteni skala masalah, ing wektu iku volume total log kira-kira 2 TB saben dina.
Kita nemtokake tujuan kanggo ngilangi kabeh log lan nyuda wektu pangiriman menyang kluster ELK nganti maksimal 15 menit sajrone force majeure (kita banjur ngandelake angka kasebut minangka KPI internal).
Mekanisme rotasi anyar lan kelenjar panas-anget
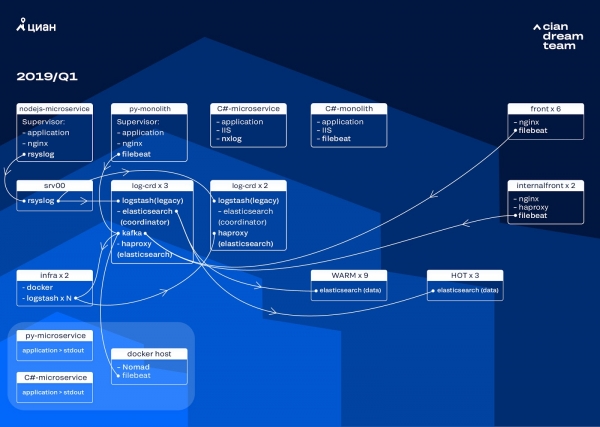
Kita miwiti konversi kluster kanthi nganyari versi ElasticSearch saka 5.5.2 dadi 6.4.3. Sawise maneh kluster versi 5 kita mati, lan kita mutusake kanggo mateni lan nganyari kanthi lengkap - isih ora ana log. Dadi, kita nggawe transisi iki mung sawetara jam.
Transformasi paling gedhe ing tahap iki yaiku implementasi Apache Kafka ing telung simpul kanthi koordinator minangka buffer perantara. Broker pesen nylametake kita supaya ora ilang log sajrone masalah karo ElasticSearch. Ing wektu sing padha, kita nambahake 2 kelenjar menyang kluster lan ngalih menyang arsitektur panas-anget karo telung "panas" kelenjar dumunung ing rak beda ing pusat data. Kita ngarahake log menyang wong-wong mau nggunakake topeng sing ora bakal ilang ing kahanan apa wae - nginx, uga log kesalahan aplikasi. Log cilik dikirim menyang node sing isih ana - debug, peringatan, lan liya-liyane, lan sawise 24 jam, log "penting" saka simpul "panas" ditransfer.
Supaya ora nambah jumlah indeks cilik, kita ngalih saka rotasi wektu kanggo mekanisme rollover. Ana akeh informasi ing forum sing rotasi kanthi ukuran indeks ora bisa dipercaya, mula kita mutusake nggunakake rotasi kanthi jumlah dokumen ing indeks kasebut. Kita nganalisa saben indeks lan nyathet jumlah dokumen sing kudu ditindakake rotasi. Mangkono, kita wis tekan ukuran beling optimal - ora luwih saka 50 GB.
Optimasi kluster
Nanging, kita durung rampung ngilangi masalah kasebut. Sayange, indeks cilik isih katon: ora tekan volume sing ditemtokake, ora diputer, lan dibusak kanthi reresik global indeks sing luwih lawas tinimbang telung dina, amarga kita mbusak rotasi miturut tanggal. Iki mimpin kanggo mundhut data amarga kasunyatan sing indeks saka kluster ilang rampung, lan nyoba kanggo nulis kanggo indeks non-ana nyuwil logika kurator sing digunakake kanggo manajemen. Alias kanggo nulis diowahi dadi indeks lan nyuwil logika rollover, nyebabake wutah sing ora bisa dikendhaleni saka sawetara indeks nganti 600 GB.
Contone, kanggo konfigurasi rotasi:
сurator-elk-rollover.yaml
---
actions:
1:
action: rollover
options:
name: "nginx_write"
conditions:
max_docs: 100000000
2:
action: rollover
options:
name: "python_error_write"
conditions:
max_docs: 10000000
Yen ora ana alias rollover, ana kesalahan:
ERROR alias "nginx_write" not found.
ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
Kita ninggalake solusi kanggo masalah iki kanggo pengulangan sabanjure lan njupuk masalah liyane: kita ngalih menyang logika narik Logstash, sing ngolah log sing mlebu (njabut informasi sing ora perlu lan nambah). Kita diselehake ing docker, sing diluncurake liwat docker-compose, lan uga diselehake logstash-eksporter ing kana, sing ngirim metrik menyang Prometheus kanggo ngawasi operasional aliran log. Kanthi cara iki, kita menehi kesempatan kanggo ngganti jumlah kedadeyan logstash kanthi lancar kanggo ngolah saben jinis log.
Nalika kita nambah kluster, lalu lintas cian.ru tambah dadi 12,8 yuta pangguna unik saben wulan. Akibaté, ternyata transformasi kita rada sithik ing owah-owahan ing produksi, lan kita ngadhepi kasunyatan manawa simpul "anget" ora bisa ngatasi beban lan nyepetake kabeh pangiriman log. Kita nampa data "panas" tanpa gagal, nanging kita kudu campur tangan ing pangiriman liyane lan nindakake rollover manual supaya bisa nyebarake indeks kanthi merata.
Ing wektu sing padha, scaling lan ngganti setelan saka logstash kedadean ing kluster rumit dening kasunyatan sing iku docker-nyipta lokal, lan kabeh tumindak wis dileksanakake kanthi manual (kanggo nambah ends anyar, iku perlu kanggo manual mbukak kabeh. server lan docker-compose munggah -d nang endi wae).
Redistribusi log
Ing wulan September taun iki, kita isih ngethok monolit, beban ing kluster saya tambah, lan aliran log nyedhak 30 ewu pesen per detik.
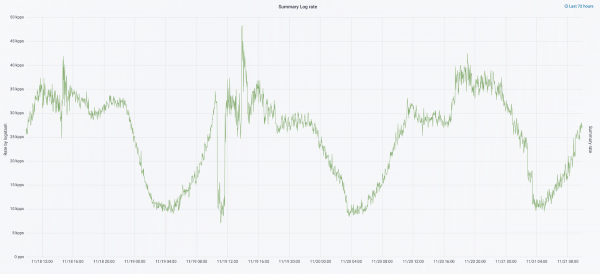
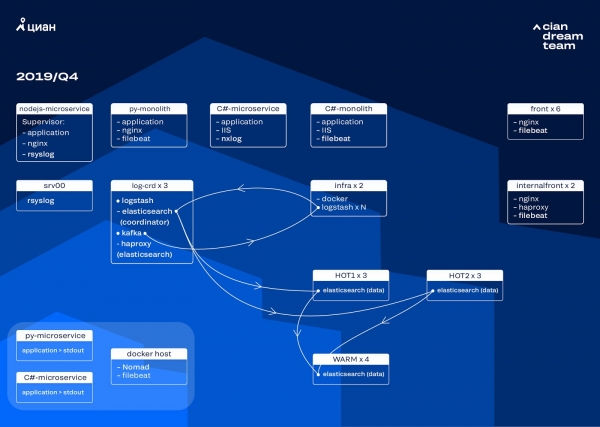
Kita miwiti pengulangan sabanjure kanthi nganyari hardware. We ngalih saka limang koordinator kanggo telung, diganti kelenjar data lan menang ing syarat-syarat dhuwit lan papan panyimpenan. Kanggo simpul kita nggunakake rong konfigurasi:
- Kanggo simpul "panas": E3-1270 v6 / 960Gb SSD / 32 Gb x 3 x 2 (3 kanggo Hot1 lan 3 kanggo Hot2).
- Kanggo simpul "anget": E3-1230 v6 / 4Tb SSD / 32 Gb x 4.
Ing pengulangan iki, kita mindhah indeks kanthi log akses microservices, sing njupuk papan sing padha karo log nginx garis ngarep, menyang klompok kapindho telung simpul "panas". Saiki kita nyimpen data ing simpul "panas" sajrone 20 jam, banjur pindhah menyang simpul "anget" menyang log liyane.
Kita ngrampungake masalah indeks cilik sing ilang kanthi konfigurasi ulang rotasi. Saiki indeks diputer saben 23 jam ing kasus apa wae, sanajan ana data sing sithik. Iki rada nambah jumlah shards (ana udakara 800), nanging saka sudut pandang kinerja kluster, bisa ditrima.
Akibaté, ana enem "panas" lan mung papat "anget" kelenjar ing kluster. Iki nyebabake wektu tundha sethithik ing panjalukan sajrone interval wektu sing suwe, nanging nambah jumlah kelenjar ing mangsa ngarep bakal ngatasi masalah iki.
Pengulangan iki uga ndandani masalah kekurangan skala semi-otomatis. Kanggo nindakake iki, kita masang kluster Nomad infrastruktur - padha karo sing wis kita pasang ing produksi. Saiki, jumlah Logstash ora diganti kanthi otomatis gumantung saka beban, nanging kita bakal teka.
Rencana kanggo masa depan
Konfigurasi sing diimplementasikake kanthi sampurna, lan saiki kita nyimpen 13,3 TB data - kabeh log sajrone 4 dina, sing perlu kanggo analisis darurat tandha. Kita ngowahi sawetara log menyang metrik, sing ditambahake menyang Graphite. Kanggo nggawe karya insinyur luwih gampang, kita duwe metrik kanggo kluster infrastruktur lan skrip kanggo ndandani masalah umum semi-otomatis. Sawise nambah jumlah simpul data, sing direncanakake kanggo taun ngarep, kita bakal ngalih menyang panyimpenan data saka 4 nganti 7 dina. Iki bakal cukup kanggo karya operasional, amarga kita tansah nyoba kanggo neliti kedadosan sanalika bisa, lan kanggo investigasi long-term ana data telemetri.
Ing Oktober 2019, lalu lintas menyang cian.ru wis tuwuh dadi 15,3 yuta pangguna unik saben wulan. Iki dadi tes serius babagan solusi arsitektur kanggo ngirim log.
Saiki kita nyiapake nganyari ElasticSearch menyang versi 7. Nanging, kanggo iki, kita kudu nganyari pemetaan akeh indeks ing ElasticSearch, amarga padha pindhah saka versi 5.5 lan diumumake minangka ora ana ing versi 6 (padha ora ana ing versi). 7). Iki tegese sajrone proses nganyari mesthi bakal ana sawetara jinis force majeure, sing bakal ninggalake kita tanpa log nalika masalah wis rampung. Saka versi 7, kita paling ngarepake Kibana kanthi antarmuka sing luwih apik lan saringan anyar.
Kita entuk tujuan utama: kita mandheg ilang log lan nyuda downtime kluster infrastruktur saka 2-3 kacilakan saben minggu dadi sawetara jam kerja pangopènan saben wulan. Kabeh karya iki ing produksi meh ora katon. Nanging, saiki kita bisa nemtokake persis apa sing kedadeyan karo layanan kita, kita bisa kanthi cepet nindakake ing mode sepi lan ora kuwatir yen log bakal ilang. Umumé, kita wareg, seneng lan nyiapake kanggo eksploitasi anyar, sing bakal kita pirembagan mengko.
Source: www.habr.com
