

prasejarah
Ana mesin vending saka desain kita dhewe. Nang ana Raspberry Pi lan sawetara strapping ing Papan kapisah. A akseptor duwit receh, akseptor tagihan, terminal bank disambungake ... Kabeh wis kontrol dening program poto-ditulis. Sejarah kabeh karya ditulis ing jurnal ing flash drive (MicroSD), sing banjur dikirim liwat Internet (nggunakake modem USB) menyang server, sing disimpen ing database. Informasi sales dimuat menyang 1C, ana uga antarmuka web prasaja kanggo ngawasi, etc.
Yaiku, jurnal kasebut penting banget - kanggo akuntansi (asil, dodolan, lsp), ngawasi (kabeh jinis kegagalan lan kahanan force majeure liyane); iki, siji bisa ngomong, kabeh informasi kita duwe bab mesin iki.
masalah
Flash drive mbuktekaken dadi piranti sing ora bisa dipercaya. Padha break mudhun karo reguler enviable. Iki ndadékaké kanggo downtime mesin lan (yen sakperangan alesan log ora bisa ditransfer online) mundhut data.
Iki dudu pengalaman pertama nggunakake flash drive, sadurunge ana proyek liyane kanthi luwih saka satus piranti, ing endi jurnal kasebut disimpen ing USB flash drive, ana uga masalah linuwih, kadhangkala jumlah piranti sing gagal saben wulan ana ing puluhan. Kita nyoba macem-macem flash drive, kalebu merek karo memori SLC, lan sawetara model luwih dipercaya tinimbang liyane, nanging ngganti flash drive ora ngrampungake masalah kanthi radikal.
Ati-ati Longread! Yen sampeyan ora kasengsem ing "kok", nanging mung ing "carane", sampeyan bisa langsung menyang artikel.
kaputusan
Wangsulan: Bab ingkang sapisanan nerangake atine kanggo ninggalake MicroSD, nginstal, contone, SSD, lan boot saka. Secara teoritis, bisa uga, nanging relatif larang, lan ora bisa dipercaya (adaptor USB-SATA ditambahake; statistik kegagalan kanggo SSD anggaran uga ora nyemangati).
USB HDD uga ora katon kaya solusi sing apik banget.
Mulane, kita teka ing pilihan iki: ninggalake boot saka MicroSD, nanging digunakake ing mode mung diwaca, lan nyimpen log karya (lan informasi liyane unik kanggo Piece tartamtu saka hardware - nomer serial, kalibrasi sensor, etc.) nang endi wae liya.
Topik FS mung diwaca kanggo Raspberry Pi wis ditliti munggah lan mudhun, aku ora bakal mikir babagan rincian implementasine ing artikel iki. (nanging yen ana minat, mungkin aku bakal nulis artikel mini babagan topik iki). Siji-sijine titik sing dakkarepake yaiku saka pengalaman pribadi lan saka review saka wong-wong sing wis ngetrapake, ana gain linuwih. Ya, iku ora bisa rampung njaluk nyisihaken saka breakdowns, nanging iku bisa kanggo Ngartekno nyuda frekuensi. Lan kertu dadi manunggal, kang Ngartekno nyederhanakake panggantos kanggo personel layanan.
Hardware
Ora ana keraguan khusus babagan pilihan jinis memori - NOR Flash.
Argumentasi:
- sambungan prasaja (paling asring bis SPI, kang kita wis pengalaman nggunakake, supaya ora masalah hardware samesthine);
- rega konyol;
- protokol operasi standar (implementasine wis ana ing kernel) Linux, yen sampeyan pengin, sampeyan bisa njupuk pihak katelu, sing uga ana, utawa malah nulis dhewe, untunge, kabeh gampang);
- linuwih lan sumber daya:
saka lembar data khas: data disimpen nganti 20 taun, 100000 siklus mbusak kanggo saben blok;
saka sumber pihak katelu: BER arang banget, ora perlu kanggo kode koreksi kesalahan postulated (sawetara makalah nganggep ECC kanggo NOR, nanging biasane tegese MLC NOR, iki uga kedadeyan).
Ayo ngira syarat volume lan sumber daya.
Aku kaya kanggo mesthekake yen data disimpen kanggo sawetara dina. Iki perlu supaya yen ana masalah sambungan, riwayat penjualan ora ilang. Kita bakal fokus ing 5 dina, kanggo periode iki (malah nganggep akhir minggu lan preian) masalah bisa ditanggulangi.
Saiki kita duwe kira-kira 100kb log saben dina (3-4 ewu cathetan), nanging angka iki saya tambah akeh - rincian nambah, acara anyar ditambahake. Kajaba iku, kadhangkala ana lonjakan (sawetara sensor wiwit spamming kanthi positif palsu, umpamane). Kita bakal ngetung kanggo 10 ewu cathetan 100 bait - megabyte saben dina.
Secara total, ana 5MB data sing resik (dikompres kanthi apik). Kajaba iku, (estimasi kasar) 1 MB data layanan.
Sing, kita kudu chip kanggo 8 MB yen kita ora nggunakake komprèsi, utawa 4 MB yen kita nindakake. Angka sing cukup nyata kanggo jinis memori iki.
Minangka kanggo sumber daya: yen kita rencana sing memori bakal rampung ditulis maneh ora luwih saka sapisan saben 5 dina, banjur liwat 10 taun layanan kita njaluk kurang saka sewu siklus nulis ulang.
Ayo kula ngelingake yen pabrikan janji satus ewu.
Sedhela babagan NOR vs NAND
Dina iki, mesthi, memori NAND luwih populer, nanging aku ora bakal digunakake kanggo proyek iki: NAND, ora kaya NOR, kudu nggunakake kode koreksi kesalahan, tabel blok ala, lan liya-liyane, lan chip NAND biasane duwe pin liyane.
Kekurangan NOR kalebu:
- volume cilik (lan, miturut, rega dhuwur saben megabyte);
- kacepetan exchange kurang (umume amarga kasunyatan sing antarmuka serial digunakake, biasane SPI utawa I2C);
- mbusak alon (gumantung saka ukuran pemblokiran, iku njupuk saka pecahan saka detik kanggo sawetara detik).
Kayane ora ana sing kritis kanggo kita, mula kita terus.
Yen sampeyan kasengsem ing rincian, microcircuit dipilih (Nanging, iki ora penting, ana akeh analog ing pasar sing kompatibel karo pinout lan sistem printah, sanajan kita pengin nginstal microcircuit saka pabrikan liyane lan / utawa volume liyane, kabeh bakal bisa tanpa ngganti kode).
Aku nganggo sing wis dibangun ing kernel Linux Driver, ing Raspberry, amarga dhukungan overlay wit piranti, kabeh gampang banget - sampeyan kudu nyelehake overlay sing wis dikompilasi ing /boot/overlays lan ngowahi /boot/config.txt sethithik.
Tuladha file dts
Kanggo jujur, Aku ora yakin sing ditulis tanpa kasalahan, nanging bisa.
/*
* Device tree overlay for at25 at spi0.1
*/
/dts-v1/;
/plugin/;
/ {
compatible = "brcm,bcm2835", "brcm,bcm2836", "brcm,bcm2708", "brcm,bcm2709";
/* disable spi-dev for spi0.1 */
fragment@0 {
target = <&spi0>;
__overlay__ {
status = "okay";
spidev@1{
status = "disabled";
};
};
};
/* the spi config of the at25 */
fragment@1 {
target = <&spi0>;
__overlay__ {
#address-cells = <1>;
#size-cells = <0>;
flash: m25p80@1 {
compatible = "atmel,at25df321a";
reg = <1>;
spi-max-frequency = <50000000>;
/* default to false:
m25p,fast-read ;
*/
};
};
};
__overrides__ {
spimaxfrequency = <&flash>,"spi-max-frequency:0";
fastread = <&flash>,"m25p,fast-read?";
};
};Lan baris liyane ing config.txt
dtoverlay=at25:spimaxfrequency=50000000Aku bakal skip gambaran saka sambungan microcircuit kanggo Raspberry Pi. Ing tangan siji, aku ora pakar ing electronics, ing tangan liyane, kabeh iku ora pati penting malah kanggo kula: microcircuit mung 8 pin, kang kita kudu lemah, daya, SPI (CS, SI, SO, SCK); tingkat pas karo sing saka Raspberry Pi, ora strapping tambahan dibutuhake - mung nyambung kasebut 6 kontak.
Formulasi masalah
Minangka biasanipun, statement masalah dadi liwat sawetara iterasi, lan aku iku wektu kanggo liyane. Mula, ayo padha mandheg, nglumpukake apa sing wis ditulis, lan njlentrehake rincian sing tetep ana ing bayangan.
Dadi, kita wis mutusake manawa log kasebut bakal disimpen ing SPI NOR Flash.
Apa NOR Flash kanggo sing ora ngerti
Iki minangka memori non-molah malih sing sampeyan bisa nindakake telung operasi:
- Waosan:
Wacan sing paling umum: kita ngliwati alamat kasebut lan maca akeh bita sing dibutuhake; - Cathetan:
Nulis kanggo lampu kilat NOR katon kaya normal, nanging nduweni siji peculiarity: sampeyan mung bisa ngganti 1 kanggo 0, nanging ora kosok balene. Contone, yen kita duwe 0x55 ing sel memori, banjur sawise nulis 0x0f, 0x05 wis disimpen ing kono. (ndeleng tabel ing ngisor iki); - Busak:
Mesthi, kita kudu bisa nindakake operasi ngelawan - ngganti 0 kanggo 1, iki kanggo operasi mbusak. Boten kados loro pisanan, ora operate ing bita, nanging ing pamblokiran (pamblokiran mbusak minimal ing chip milih 4 KB). Mbusak ngrusak kabeh blok lan iki mung cara kanggo ngganti 0 dadi 1. Mulane, nalika nggarap memori lampu kilat, asring perlu kanggo nyelarasake struktur data menyang wates blok mbusak.
Nulis menyang NOR Flash:
data binar
iku
01010101
Direkam
00001111
Wis dadi
00000101
Log kasebut minangka urutan rekaman dawa variabel. Cathetan khas dawane kira-kira 30 bita (sanajan kadhangkala rekaman dawane pirang-pirang kilobyte). Ing kasus iki kita mung bisa karo wong-wong mau minangka pesawat saka bita, nanging yen sampeyan kasengsem, CBOR digunakake nang cathetan.
Saliyane log, kita kudu nyimpen sawetara informasi "persiyapan", loro dianyari lan ora: sawetara ID piranti, kalibrasi sensor, "piranti dipatèni sementara" flag, etc.
Informasi iki minangka set rekaman nilai kunci, uga disimpen ing CBOR. Kita ora duwe akeh informasi iki (paling sawetara kilobyte), lan dianyari arang banget.
Ing mangsa ngarep kita bakal ngarani konteks.
Yen sampeyan ngelingi carane artikel iki diwiwiti, penting banget kanggo njamin panyimpenan data sing dipercaya lan, yen bisa, operasi tanpa gangguan sanajan ana kegagalan hardware / korupsi data.
Apa sumber masalah sing bisa dianggep?
- Daya mati sajrone operasi nulis / mbusak. Iki saka kategori "ora ana pertahanan marang linggis".
Informasi saka ing stackexchange: nalika daya dipateni nalika nggarap lampu kilat, loro-lorone mbusak (diset menyang 1) lan nulis (diset menyang 0) mimpin kanggo prilaku undefined: data bisa ditulis, sebagian ditulis (nyarita, kita nransfer 10 bait / 80 bit, nanging mung bisa nulis 45 bit), iku uga bisa sawetara bit bakal mungkasi munggah ing negara (0 utawa intermediate 1); - Kasalahan ing memori lampu kilat dhewe.
BER, sanajan sithik banget, ora bisa padha karo nol; - Kesalahan bis
Data sing dikirim liwat SPI ora dilindhungi kanthi cara apa wae; kesalahan bit siji lan kesalahan sinkronisasi - mundhut utawa selipan bit (sing ndadékaké kanggo distorsi data massive) uga kelakon; - Kesalahan / kesalahan liyane
Kesalahan kode, gangguan Raspberry, campur tangan alien...
Aku wis ngrumusake syarat sing, miturut pendapatku, kudu dipenuhi kanggo njamin linuwih:
- cathetan kudu ditulis kanggo flash memori langsung, telat nulis ora dianggep; - yen ana kesalahan, kudu dideteksi lan diproses sakcepete; - sistem kudu, yen bisa, waras saka kasalahan.
(conto saka urip "ora mesthine", sing dakkira saben wong wis nemoni: sawise urip maneh darurat, sistem file "rusak" lan sistem operasi ora boot)
Gagasan, pendekatan, pikirane
Nalika aku wiwit mikir babagan masalah iki, akeh ide sing muncul ing sirahku, contone:
- nggunakake komprèsi data;
- nggunakake struktur data sing pinter, kayata nyimpen header rekaman kanthi kapisah saka cathetan kasebut, supaya yen ana kesalahan ing siji rekaman, liyane bisa diwaca tanpa masalah;
- nggunakake kolom bit kanggo kontrol nulis completion nalika daya dipateni;
- nyimpen checksum kanggo kabeh lan kabeh wong;
- nggunakake sawetara wangun coding kesalahan-mbenerake.
Sawetara gagasan iki digunakake, sawetara ditinggalake. Ayo padha liwat ing urutan.
Kompresi data
Acara dhewe sing direkam ing log cukup seragam lan bisa diulang ("mbuwang duwit receh 5 ruble", "dipencet tombol pangowahan", ...). Mulane, komprèsi kudu cukup efektif.
Overhead komprèsi ora pati penting (prosesor kita cukup kuat, malah Pi pisanan duwe siji inti kanthi frekuensi 700 MHz, model saiki duwe sawetara inti kanthi frekuensi luwih saka gigahertz), kacepetan ijol-ijolan kanthi panyimpenan kurang (sawetara megabyte per detik), ukuran rekaman cilik. Umumé, yen kompresi nduwe pengaruh ing kinerja, mung bakal positif. (pancen ora kritis, mung nyatakake)Kajaba iku, kita ora duwe sing dipasang tenan, nanging sing biasa. Linux — dadi implementasine ora mbutuhake gaweyan akeh (cukup mung ngubungake perpustakaan lan nggunakake sawetara fungsi saka perpustakaan kasebut).
Sepotong log saka piranti sing digunakake (1.7 MB, 70 ewu cathetan) dijupuk lan dipriksa dhisik kanggo kompresibilitas nggunakake gzip, lz4, lzop, bzip2, xz, zstd sing kasedhiya ing komputer.
- gzip, xz, zstd nuduhake asil sing padha (40Kb).
Aku kaget yen xz modis nuduhake dhewe ing tingkat gzip utawa zstd; - lzip kanthi setelan gawan menehi asil sing rada ala;
- lz4 lan lzop ora nuduhake asil sing apik banget (150Kb);
- bzip2 nuduhake asil sing apik banget (18Kb).
Dadi data compresses banget.
Dadi (yen kita ora nemokake cacat fatal) kompresi bakal ana! Mung amarga luwih akeh data bakal pas ing flash drive sing padha.
Ayo dipikirake babagan kekurangane.
Masalah pisanan: kita wis setuju yen saben rekaman kudu langsung menyang lampu kilat. Biasane, arsip nglumpukake data saka stream input nganti mutusake yen wektune nulis menyang output. Kita kudu langsung njaluk blok data sing dikompres lan simpen ing memori sing ora molah malih.
Aku ndeleng telung cara:
- Kompres saben rekaman nggunakake kompresi kamus tinimbang algoritma sing dibahas ing ndhuwur.
Iki minangka pilihan sing bisa digunakake, nanging aku ora seneng. Kanggo mesthekake tingkat kompresi luwih utawa kurang prayoga, kamus kudu "disesuaikan" kanggo data tartamtu; owah-owahan sembarang bakal kasil ing tingkat komprèsi Mudhun catastrophically. Ya, masalah kasebut bisa ditanggulangi kanthi nggawe kamus versi anyar, nanging iki mumet - kita kudu nyimpen kabeh versi kamus; ing saben entri, kita kudu nuduhake versi kamus sing dikompres nganggo... - Kompres saben rekaman nggunakake algoritma "klasik", nanging kanthi bebas saka liyane.
Algoritma komprèsi sing dianggep ora dirancang kanggo nggarap cathetan kanthi ukuran iki (puluhan bita), rasio kompresi bakal cetha kurang saka 1 (yaiku, paningkatan volume data tinimbang kompresi); - Apa FLUSH sawise saben entri.
Akeh perpustakaan kompresi ndhukung FLUSH. Iki minangka prentah (utawa parameter kanggo prosedur komprèsi), nalika nampa arsip mbentuk stream sing dikompres supaya bisa dipulihake kanthi basis. kabeh data sing ora dikompres sing wis ditampa. Iki analogsyncing sistem file utawacommiting sql.
Sing penting yaiku operasi kompresi sabanjure bakal bisa nggunakake kamus akumulasi lan rasio kompresi ora bakal nandhang sangsara kaya ing versi sadurunge.
Aku iku ketok yen aku milih pilihan katelu, ayo kang katon ing liyane rinci.
ketemu babagan FLUSH ing zlib.
Aku nggawe tes lutut adhedhasar artikel kasebut, njupuk 70 ewu entri log saka piranti nyata, kanthi ukuran kaca 60 KB (kita bakal bali menyang ukuran kaca mengko) ditampa:
Data sumber
Kompresi gzip -9 (tanpa FLUSH)
zlib karo Z_PARTIAL_FLUSH
zlib karo Z_SYNC_FLUSH
Volume, Kb
1692
40
352
604
Sepisanan, biaya FLUSH dhuwur banget, nanging nyatane kita duwe pilihan sing ora apik - salah siji ora ngompres, utawa ngompres (lan cukup efektif) nganggo FLUSH. Kita kudu ora lali yen kita duwe 70 ewu rekaman, redundansi sing dienalake Z_PARTIAL_FLUSH mung 4-5 bita saben rekaman. Lan rasio kompresi dadi meh 5: 1, sing luwih saka asil sing apik banget.
Koyone nggumunake, nanging Z_SYNC_FLUSH sejatine cara sing luwih efisien kanggo nindakake FLUSH
Yen nggunakake Z_SYNC_FLUSH, 4 bait pungkasan saben rekaman bakal tansah 0x00, 0x00, 0xff, 0xff. Lan yen kita ngerti, kita ora bisa nyimpen, supaya ukuran final mung 324 KB.
Artikel sing daksambungake duwe panjelasan:
Blok 0 jinis anyar kanthi isi kosong ditambahake.
Blok tipe 0 kanthi isi kosong kalebu:
- header blok telung bit;
- 0 nganti 7 bit padha karo nol, kanggo entuk keselarasan bait;
- urutan papat bait 00 00 FF FF.
Minangka sampeyan bisa ndeleng kanthi gampang, ing blok pungkasan sadurunge 4 byte iki ana saka 3 nganti 10 nol bit. Nanging, praktik wis nuduhake yen ana paling ora 10 nol bit.
Pranyata metu sing pamblokiran cendhak data biasane (tansah?) Dienkode nggunakake pemblokiran saka jinis 1 (blok tetep), kang kudu ends karo 7 nul bit, supaya kita njaluk 10-17 dijamin nul bit (lan liyane bakal nul karo kemungkinan bab 50%).
Dadi, ing data tes ing 100% kasus sadurunge 0x00, 0x00, 0xff, 0xff ana siji bita nol, lan ing luwih saka katelu kasus ana rong bita nol (Mungkin titik iku aku nggunakake binar CBOR, lan yen aku nggunakake teks JSON, aku bakal luwih kerep nemoni pamblokiran saka jinis 2 - pamblokiran dinamis, mungguh, aku bakal nemokke pamblokiran tanpa bita nol tambahan sadurunge 0x00, 0x00, 0xff, 0xff).
Secara total, nggunakake data tes sing kasedhiya, bisa pas kurang saka 250 KB data sing dikompres.
Kita bisa nyimpen sawetara liyane kanthi juggling bit: saiki kita nglirwakake ngarsane sawetara nol bit ing mburi blok, lan sawetara bit ing awal blok uga ora diganti ...
Nanging ing kene aku nggawe keputusan sing kuat kanggo mandheg, yen ora ing tingkat iki, aku bisa ngembangake arsipku dhewe.
Secara total, aku entuk 3-4 bita saben rekaman saka data tesku, rasio kompresi luwih saka 6: 1. Jujur, aku ora ngarep-arep asil kasebut, miturut pendapatku, apa wae sing luwih apik tinimbang 2: 1 wis dadi asil sing mbenerake panggunaan kompresi.
Kabeh apik, nanging zlib (deflate) isih minangka algoritma kompresi kuno, pantes lan rada kuno. Kasunyatan bilih 32K pungkasan saka stream data uncompressed digunakake minangka kamus katon aneh dina (yaiku, yen sawetara pemblokiran data banget padha karo apa ing stream input 40K ago, iku bakal miwiti arsip maneh, lan ora bakal deleng entri sadurungé). Ing arsip modern sing modis, ukuran kamus asring diukur ing megabyte, dudu kilobyte.
Dadi, ayo nerusake riset mini babagan arsip.
Sabanjure, bzip2 dicoba (eling, tanpa FLUSH nuduhake rasio kompresi sing apik banget, meh 100: 1). Sayange, kanthi FLUSH nuduhake dhewe banget, ukuran data sing dikompres luwih gedhe tinimbang sing ora dikompres.
Pendhaftaran guess babagan alasan kanggo gagal
Libbz2 nawakake mung siji pilihan flush, kang misale jek kanggo flush kamus (analog karo Z_FULL_FLUSH ing zlib), supaya ora ana gunane kanggo ngomong babagan kompresi efektif sawise iki.
Lan sing pungkasan dites yaiku zstd. Gumantung ing paramèter, compresses salah siji ing tingkat gzip, nanging luwih cepet, utawa luwih apik tinimbang gzip.
Sayange, kanthi FLUSH uga nuduhake "ora apik banget": ukuran data sing dikompres kira-kira 700 KB.
Я ing kaca proyek ing github, aku nampa jawaban sing worth ngetang nganti 10 bita data layanan kanggo saben pemblokiran data teken, kang cedhak karo asil dijupuk, iku ora bakal bisa kanggo nyekel munggah karo deflate.
Ing jalur iki aku mutusaké kanggo mungkasi èkspèrimèn karo archiver (ayo kula ngelingake sampeyan sing xz, lzip, lzo, lz4 durung nuduhake piyambak ing tataran testing tanpa FLUSH, lan aku ora nimbang algoritma komprèsi liyane endah).
Ayo bali menyang masalah arsip.
Kapindho (kaya sing diomongake kanthi urutan, ora penting) yaiku data sing dikompres minangka aliran tunggal, ing ngendi referensi kanggo bagean sadurunge terus digawe. Mangkono, yen sawetara bagean data sing dikompres rusak, kita bakal kelangan ora mung blok data sing ora dikompres sing ana gandhengane, nanging uga kabeh sing sabanjure.
Ana pendekatan kanggo ngrampungake masalah iki:
- Nyegah masalah saka kedadeyan - nambah redundansi menyang data sing dikompres supaya kesalahan bisa dideteksi lan didandani; kita bakal ngomong babagan iki mengko;
- Nyilikake akibat yen ana masalah
Kita wis ngandika sadurunge iku bisa kanggo compress saben pamblokiran data independen, lan masalah bakal ilang dhewe (korupsi data saka siji pamblokiran bakal mimpin kanggo mundhut data mung pemblokiran iki). Nanging, iki minangka kasus sing ekstrem, ing ngendi kompresi data bakal ora efektif. Nemen ngelawan: nggunakake kabeh 4 MB chip kita minangka arsip siji, kang bakal menehi kita komprèsi banget, nanging jalaran catastrophic ing cilik saka korupsi data.
Ya, kompromi dibutuhake ing babagan linuwih. Nanging kita kudu elinga yen kita ngembangake format panyimpenan data kanggo memori sing ora molah malih kanthi BER sing sithik banget lan umur panyimpenan data sing diumumake 20 taun.
Sajrone nyobi aku katutup sing luwih utawa kurang ngelingke losses ing tingkat komprèsi wiwit karo pamblokiran data teken kurang saka 10 KB ing ukuran.
Iku wis kasebut sadurungé sing memori digunakake paged, Aku ora weruh alesan apa sampeyan ora kudu nggunakake "siji kaca - siji blok data teken" pemetaan.
Tegese, ukuran kaca sing cukup minimal yaiku 16Kb (kanthi cadangan kanggo informasi layanan). Nanging, ukuran kaca sing cilik iki ngetrapake watesan sing signifikan kanggo ukuran rekaman maksimal.
Senajan aku ora nyana rekaman luwih gedhe tinimbang sawetara kilobyte ing wangun teken, Aku mutusaké kanggo nggunakake 32K kaca (sing menehi kula 128 kaca saben chip).
Ringkesan:
- Kita nyimpen data sing dikompres nggunakake zlib (deflate);
- Kanggo saben entri kita nyetel Z_SYNC_FLUSH;
- Kanggo saben rekaman sing dikompres, kita motong bita mburine (contone 0x00, 0x00, 0xff, 0xff); ing header kita nuduhake carane akeh bita kita Cut mati;
- Kita nyimpen data ing kaca 32Kb; ing saben kaca ana siji aliran data sing dikompres; ing saben kaca kita miwiti komprèsi anew.
Lan, sadurunge ngrampungake kompresi, aku pengin menehi perhatian marang kasunyatan manawa kita mung entuk sawetara bita data sing dikompresi saben rekaman, saengga penting banget supaya ora nambah informasi layanan, saben bait diitung ing kene.
Nyimpen header data
Awit kita duwe cathetan dawa variabel, kita kudu piye wae nemtokake panggonan seko / wates cathetan.
Aku ngerti telung pendekatan:
- Kabeh rekaman disimpen ing stream terus-terusan, pisanan header rekaman ngemot dawa, lan banjur rekaman dhewe.
Ing varian iki, header lan data bisa dawane variabel.
Intine, kita entuk dhaptar sing disambung sing digunakake saben wektu; - Header lan cathetan dhewe disimpen ing aliran kapisah.
Kanthi nggunakake header sing terus-terusan, kita mesthekake yen korupsi siji header ora mengaruhi liyane.
Pendekatan sing padha digunakake, contone, ing akeh sistem file; - Records disimpen ing stream terus, wates rekaman ditemtokake dening sawetara panandha (simbol / urutan simbol sing dilarang nang pamblokiran data). Yen panandha ditemoni ing rekaman, kita ngganti karo sawetara urutan (kita lolos).
Pendekatan sing padha digunakake, contone, ing protokol PPP.
Ayo kula ilustrasi.
Opsi 1:

Ing kene kabeh gampang banget: ngerti dawa rekaman, kita bisa ngetung alamat header sabanjure. Dadi kita pindhah liwat header nganti kita nemoni area sing diisi 0xff (area gratis) utawa mburi kaca.
Opsi 2:

Amarga dawa variabel rekaman, kita ora bisa ngomong luwih dhisik pira rekaman (lan mulane header) sing dibutuhake saben kaca. Kita bisa nyebarake header lan data dhewe ing kaca sing beda-beda, nanging aku luwih seneng pendekatan liyane: kita nyelehake header lan data ing siji kaca, nanging header (ukuran konstan) diwiwiti saka wiwitan kaca, lan data (dawa variabel) diwiwiti saka pungkasan. Sanalika dheweke "ketemu" (ora cukup ruang kosong kanggo rekaman anyar), kita nganggep kaca iki kebak.
Opsi 3:

Ora perlu nyimpen dawa utawa informasi liyane babagan lokasi data ing header, panandha sing nuduhake wates cathetan cukup. Nanging, data kasebut kudu diolah nalika nulis / maca.
Aku bakal nggunakake 0xff (yaiku kaca sing diisi sawise mbusak) minangka panandha, supaya wilayah sing bebas mesthi ora dianggep minangka data.
Tabel perbandingan:
Opsi 1
Opsi 2
Opsi 3
Toleransi kesalahan
-
+
+
Compactness
+
-
+
Kompleksitas implementasine
*
**
**
Opsi 1 duwe cacat fatal: yen salah siji saka header rusak, kabeh chain sakteruse bakal numpes. Opsi liyane ngidini sampeyan mulihake bagean data sanajan karusakan gedhe.
Nanging ing kene kudu eling yen kita mutusake kanggo nyimpen data ing wangun sing dikompres, lan kita bakal kelangan kabeh data ing kaca kasebut sawise rekaman "rusak", dadi sanajan ana minus ing tabel, kita ora nganggep.
Kekompakan:
- ing pilihan pisanan kita mung kudu nyimpen dawa ing header, yen kita nggunakake variabel-dawa integer, banjur ing paling kasus kita bisa njaluk dening siji byte;
- ing pilihan kapindho kita kudu nyimpen alamat wiwitan lan dawa; rekaman kudu ukuran pancet, Aku ngira 4 bait saben rekaman (loro bait kanggo nutup kerugian, lan loro bait kanggo dawa);
- pilihan katelu mung mbutuhake siji karakter kanggo nunjukaké wiwitan rekaman, plus rekaman dhewe bakal tuwuh dening 1-2% amarga screening. Sakabèhé, iku kira-kira ing par karo pilihan pisanan.
Kaping pisanan, aku nganggep pilihan kapindho minangka sing utama (malah nulis implementasine). Aku nilar mung nalika pungkasanipun mutusaké kanggo nggunakake komprèsi.
Mungkin ing sawijining dina aku bakal nggunakake pilihan kasebut. Contone, yen aku kudu ngatasi panyimpenan data kanggo kapal sing lelungan ing antarane Bumi lan Mars - syarat sing beda banget kanggo linuwih, radiasi kosmik, ...
Minangka kanggo pilihan katelu: Aku menehi lintang loro kanggo kerumitan implementasine mung amarga aku ora seneng kekacoan karo uwal, ngganti dawa ing proses, etc Ya, Mungkin aku bias, nanging aku kudu nulis kode - kok meksa aku kanggo nindakake soko aku ora seneng.
Ringkesan: Kita milih opsi panyimpenan ing wangun ranté "header karo dawa - variabel dawa data" amarga efisiensi lan ease saka implementasine.
Nggunakake kolom bit kanggo ngawasi sukses operasi nulis
Aku ora ngelingi saiki aku entuk ide, nanging katon kaya iki:
Kanggo saben entri, kita nyedhiyakake sawetara bit kanggo nyimpen panji.
Kita ngandika sadurungé, sawise mbusak kabeh bit kapenuhan 1, lan kita bisa ngganti 1 kanggo 0, nanging ora kosok balene. Dadi kanggo "flag not set" kita nggunakake 1, kanggo "flag set" - 0.
Mangkene carane nyelehake rekaman dawa variabel menyang lampu kilat:
- Setel gendera "rekaman dawa diwiwiti";
- We nulis mudhun dawa;
- Setel gendera "rekaman data wis diwiwiti";
- Kita nulis data;
- Kita nyetel gendera "rekaman rampung".
Kajaba iku, kita bakal duwe gendera "kesalahan ana", kanggo total 4 panji dicokot.
Ing kasus iki, kita duwe rong negara stabil "1111" - rekaman durung diwiwiti lan "1000" - rekaman sukses; yen ana gangguan sing ora dikarepke saka proses rekaman, kita bakal entuk status penengah, sing bakal bisa dideteksi lan diproses mengko.
Pendekatan iki menarik, nanging mung ngreksa marang outages daya dadakan lan gagal padha, kang, mesthi, penting, nanging iki adoh saka mung (lan ora malah utama) alesan kanggo bisa gagal.
Ringkesan: Ayo pindhah menyang nggoleki solusi sing apik.
Checksums
Checksums uga nyedhiyakake cara kanggo verifikasi (kanthi kemungkinan sing cukup) yen kita maca persis apa sing kudu ditulis. Lan, ora kaya lapangan bit sing dibahas ing ndhuwur, mesthine bisa digunakake.
Yen kita nimbang dhaptar sumber potensial masalah sing kita rembugan ndhuwur, checksum bisa ngenali kesalahan preduli saka asal. (kajaba, mbok menawa, kanggo alien jahat - uga bisa nggawe checksum).
Dadi yen tujuane kanggo verifikasi manawa data kasebut utuh, checksum minangka ide sing apik.
Pilihan algoritma kanggo ngitung checksum ora nuwuhake pitakonan - CRC. Ing sisih siji, sifat matematika ngidini 100% nyekel kesalahan saka sawetara jinis, ing sisih liya - ing data acak algoritma iki biasane nuduhake kemungkinan tabrakan ora luwih dhuwur tinimbang watesan teoritis.  . Iku bisa uga ora algoritma paling cepet, lan bisa uga ora tansah nomer tabrakan paling, nanging nduweni kualitas penting banget: ing tes aku ketemu, ora ana pola kang bakal gagal. Stabilitas minangka kualitas utama ing kasus iki.
. Iku bisa uga ora algoritma paling cepet, lan bisa uga ora tansah nomer tabrakan paling, nanging nduweni kualitas penting banget: ing tes aku ketemu, ora ana pola kang bakal gagal. Stabilitas minangka kualitas utama ing kasus iki.
Tuladha studi volumetrik: , (pranala menyang narod.ru, nuwun sewu).
Nanging, tugas milih checksum ora rampung, CRC minangka kulawarga checksum. Sampeyan kudu mutusake dawane, banjur pilih polinomial.
Milih dawa checksum ora dadi pitakonan sing gampang kaya sing katon sepisanan.
Ayo kula ilustrasi:
Ayo kita duwe kemungkinan kesalahan ing saben bait  lan checksum becik, kita ngetung jumlah rata-rata kesalahan saben yuta cathetan:
lan checksum becik, kita ngetung jumlah rata-rata kesalahan saben yuta cathetan:
Data, byte
Checksum, byte
Kesalahan sing ora dideteksi
Deteksi kesalahan positif palsu
Jumlah total tanggapan sing salah
1
0
1000
0
1000
1
1
4
999
1003
1
2
0
1997
1997
1
4
0
3990
3990
10
0
9955
0
9955
10
1
39
990
1029
10
2
0
1979
1979
10
4
0
3954
3954
1000
0
632305
0
632305
1000
1
2470
368
2838
1000
2
10
735
745
1000
4
0
1469
1469
Iku bakal katon yen kabeh iku prasaja - pilih dawa checksum kanthi minimal positif palsu gumantung saka dawa data sing dilindhungi - lan sampeyan wis rampung.
Nanging, ana masalah karo checksums singkat: sanajan padha apik ing ndeteksi kesalahan bit siji, padha bisa, karo kemungkinan cukup dhuwur, nampa data rampung acak minangka bener. Wis ana artikel babagan Habr sing nerangake .
Mulane, kanggo nggawe checksum acak sing cocog meh ora mungkin, checksum saka 32 bit utawa luwih kudu digunakake. (kanggo dawa luwih saka 64 bit, fungsi hash kriptografi biasane digunakake).
Senadyan kasunyatan sing aku wrote sadurungé sing kita kudu ngirit papan ing kabeh biaya, kita isih bakal nggunakake checksum 32-bit (16 bit ora cukup, kemungkinan tabrakan luwih saka 0.01%; lan 24 bit, lagi ngomong, ora ana kene utawa ana).
Ana bantahan ing kene: apa kita nyimpen saben bait nalika milih kompresi supaya saiki menehi 4 bait sekaligus? Apa ora luwih becik ora ngompres lan ora nambah checksum? Mesthi ora, lack of komprèsi ora ateges, yen kita ora perlu mriksa integritas.
Kita ora bakal reinvent setir nalika milih polinomial, nanging bakal njupuk saiki populer CRC-32C.
Kode iki ndeteksi kesalahan 6 bit ing paket nganti 22 bait (mbokmenawa kasus sing paling umum kanggo kita), 4 kesalahan bit ing paket nganti 655 bait (uga kasus umum kanggo kita), 2 utawa kesalahan bit sing aneh ing paket sing dawane cukup.
Yen ana sing kasengsem ing rincian
babagan CRC.
ing - mbok menawa spesialis CRC anjog ing planet.
В ana , sing nyedhiyakake paramèter sing rada apik kanggo dawa paket sing cocog karo kita, nanging aku ora nganggep prabédan sing signifikan, lan aku ora nganggep aku cukup kompeten kanggo milih kode khusus tinimbang sing standar lan diteliti kanthi apik.
Uga, amarga data kita dikompres, pitakonan muncul: apa kita kudu ngetung checksum data sing dikompres utawa ora dikompres?
Argumen kanggo ngitung checksum data sing ora dikompres:
- wekasanipun kudu mriksa safety saka panyimpenan data - supaya kita mriksa langsung (ing wektu sing padha, bisa kasalahan ing implementasine saka komprèsi / decompression, karusakan disebabake memori ala, etc. bakal dicenthang);
- algoritma deflate ing zlib wis implementasine cukup diwasa lan kudune ora tiba karo "bengkong" data input, malih, iku asring bisa independen ndeteksi kasalahan ing stream input, ngurangi kemungkinan sakabèhé saka undetecting kesalahan (Aku conducted test karo kuwalik saka dicokot siji ing rekaman singkat, zlib dideteksi kesalahan ing bab katelu saka kasus).
Argumen nglawan ngitung checksum data sing ora dikompres:
- CRC wis "ngatur" khusus kanggo sawetara kasalahan dicokot sing khas kanggo memori lampu kilat (kesalahan dicokot ing stream teken bisa nimbulaké owah-owahan massive ing stream output, kang sejatine sifate teoritis, kita bisa "nyekel" tabrakan);
- Aku ora seneng ide menehi data sing bisa rusak menyang decompressor, , carane dheweke bakal nanggepi.
Ing proyek iki aku mutusake kanggo pindhah saka praktik umum kanggo nyimpen checksum data sing ora dikompres.
Ringkesan: Kita nggunakake CRC-32C, kita ngetung checksum saka data ing wangun kang ditulis ing lampu kilat (sawise komprèsi).
Redundansi
Panggunaan coding keluwih ora, mesthi, ngilangi mundhut data; Nanging, iku bisa Ngartekno (asring dening akeh pesenan saka gedhene) nyuda kamungkinan mundhut data irreparable.
Kita bisa nggunakake macem-macem jinis redundansi kanggo mbenerake kesalahan.
Kode Hamming bisa mbenerake kesalahan siji, kode Reed-Solomon minangka simbolis, pirang-pirang salinan data bebarengan karo checksum, utawa kode kaya RAID-6 bisa mbantu mbalekake data sanajan ana korupsi gedhe.
Kaping pisanan, aku wis nyetel panggunaan coding sing mbenerake kesalahan, nanging banjur aku ngerti manawa pisanan kita kudu duwe ide babagan kesalahan apa sing pengin kita lindungi, banjur pilih coding.
Kita ujar sadurunge yen kesalahan kudu diidentifikasi kanthi cepet. Ing titik apa kita bisa nemoni kesalahan?
- Rekaman sing durung rampung (mergo sawetara alasan, daya mati nalika ngrekam, Raspberry beku, ...)
Sayange, yen ana kesalahan kasebut, siji-sijine pilihan yaiku nglirwakake cathetan sing ora bener lan nimbang data sing ilang; - Kesalahan nulis (kanggo sawetara alesan, liyane saka sing ditulis ditulis ing memori lampu kilat)
Kita bisa langsung ndeteksi kesalahan kasebut yen kita nindakake maca kontrol sanalika sawise ngrekam; - Korupsi data ing memori sajrone panyimpenan;
- Kesalahan maca
Kanggo mbenerake kesalahan, yen checksum ora cocog, cukup kanggo mbaleni maca kaping pirang-pirang.
Tegese, mung kasalahan saka jinis katelu (korupsi spontan data sajrone panyimpenan) ora bisa didandani tanpa coding kesalahan-mbenerake. Iku misale jek sing kasalahan kuwi isih arang banget kamungkinan.
Ringkesan: diputusake kanggo nglirwakake coding keluwih, nanging yen operasi nuduhake kesalahan keputusan iki, banjur bali menyang nimbang masalah kasebut (kanthi statistik akumulasi gagal, sing bakal ngidini milih jinis coding sing optimal).
Liyane
Mesthine, format artikel ora ngidini kanggo mbenerake saben bit ing format kasebut (lan aku wis ora kuwat), mula aku bakal ngrembug sawetara poin sing durung disentuh sadurunge.
- Diputusake kanggo nggawe kabeh kaca "padha"
Tegese, ora bakal ana kaca khusus kanthi metadata, aliran sing kapisah, lan liya-liyane, nanging bakal ana aliran siji sing nulis ulang kabeh kaca kanthi giliran.
Iki njamin malah nyandhang kaca, ora ana titik gagal, lan mung becik; - Penting kanggo nyedhiyani versi format.
Format tanpa nomer versi ing header iku ala!
Cukup kanggo nambah lapangan kanthi Nomer Piandel (tandha) tartamtu menyang header kaca, sing bakal nuduhake versi format sing digunakake (Aku ora mikir bakal ana puluhan wong ing praktik); - Gunakake header dawa variabel kanggo cathetan (sing ana akeh), nyoba nggawe 1 byte dawa ing paling kasus;
- Kanggo ngodhe dawa header lan dawa bagean sing dipotong saka rekaman sing dikompres, gunakake kode binar dawa variabel.
Iku banget mbiyantu Kode Huffman. Mung sawetara menit, kita bisa milih kode dawa variabel sing dibutuhake.
Katrangan format panyimpenan data
Urutan byte
Bidang sing luwih gedhe saka siji bait disimpen ing format big-endian (urutan byte jaringan), yaiku, 0x1234 ditulis minangka 0x12, 0x34.
Divisi menyang kaca
Kabeh memori lampu kilat dipérang dadi kaca kanthi ukuran sing padha.
Ukuran kaca standar yaiku 32Kb, nanging ora luwih saka 1/4 saka ukuran total chip memori (kanggo chip 4MB, iki 128 kaca).
Saben kaca nyimpen data kanthi bebas saka liyane (yaiku, data saka siji kaca ora ngrujuk data saka kaca liya).
Kabeh kaca diwenehi nomer kanthi urutan alami (ing urutan munggah alamat), diwiwiti kanthi nomer 0 (kaca nol diwiwiti kanthi alamat 0, sing pisanan - kanthi 32Kb, sing kapindho - kanthi 64Kb, lsp.)
Chip memori digunakake minangka buffer ring, yaiku, pisanan rekaman menyang kaca nomer 0, banjur kanggo kaca nomer 1, ..., nalika kita isi kaca pungkasan, siklus anyar wiwit lan rekaman terus saka kaca nul.
Nang kaca

Ing wiwitan kaca, header kaca 4-byte disimpen, banjur checksum header (CRC-32C), banjur cathetan disimpen ing format "header, data, checksum".
Header kaca (ijo reged ing diagram) kalebu:
- kolom Magic Number loro-byte (uga dikenal minangka indikator versi format)
kanggo versi saiki format dianggep minangka0xed00 ⊕ номер страницы; - loro-bait counter "Versi Kaca" (memori nulis ulang nomer siklus).
Cathetan ing kaca disimpen ing wangun kompres (nggunakake algoritma deflate). Kabeh cathetan ing siji kaca dikompres ing siji stream (nggunakake kamus umum), lan komprèsi diwiwiti maneh ing saben kaca anyar. Sing, kanggo decompress sembarang rekaman, kabeh cathetan sadurungé saka kaca iki (lan mung saka kaca iki) dibutuhake.
Saben rekaman dikompres nganggo gendera Z_SYNC_FLUSH, nyebabake stream sing dikompres rampung karo 4 bait 0x00, 0x00, 0xff, 0xff, bisa uga didhisiki siji utawa rong bita nol maneh.
We discard urutan iki (4, 5 utawa 6 bait dawa) nalika nulis kanggo flash memori.
Header rekaman yaiku 1, 2 utawa 3 bita, nyimpen:
- siji bit (T) nuduhake jinis rekaman: 0 - konteks, 1 - log;
- kolom dawa variabel (S) saka 1 nganti 7 bit, nemtokake dawa header lan "buntut" sing kudu ditambahake menyang rekaman kanggo mbongkar;
- dawa rekaman (L).
Tabel saka nilai S:
S
Dawane header, bita
Dibuwang ing nulis, byte
0
1
5 (00 00 00 ff ff)
10
1
6 (00 00 00 00 ff ff)
110
2
4 (00 00 ff ff)
1110
2
5 (00 00 00 ff ff)
11110
2
6 (00 00 00 00 ff ff)
1111100
3
4 (00 00 ff ff)
1111101
3
5 (00 00 00 ff ff)
1111110
3
6 (00 00 00 00 ff ff)
Aku nyoba kanggo ilustrasi, aku ora ngerti carane cetha dadi:
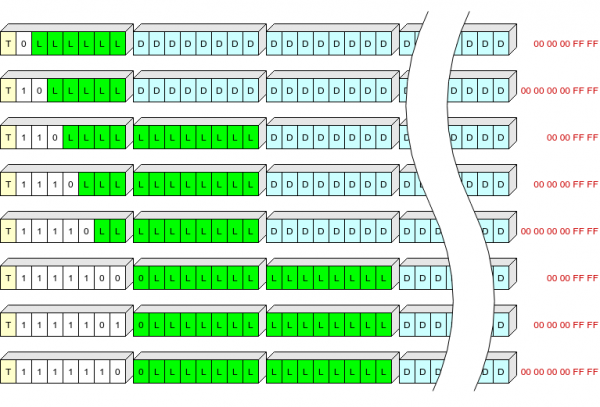
Werna kuning ing kene nuduhake lapangan T, werna putih nuduhake lapangan S, werna ijo nuduhake L (dawa data sing dikompres ing bita), werna biru nuduhake data sing dikompres, lan werna abang nuduhake bita pungkasan saka data sing dikompres sing ora ditulis ing memori flash.
Mangkono, kita bisa nulis header saka cathetan dawa paling umum (nganti 63 + 5 bait ing wangun teken) ing siji bait.
Sawise saben nulis, checksum CRC-32C disimpen, sing nggunakake nilai terbalik saka checksum sadurunge minangka nilai awal (init).
CRC nduweni sifat "durasi", rumus ing ngisor iki bener (plus utawa minus inversi bit ing proses):  .
.
Yaiku, kita bener ngetung CRC kabeh bita lan data header sadurunge ing kaca iki.
Langsung sawise checksum yaiku header rekaman sabanjure.
Header dirancang kanthi cara sing bait pisanane tansah beda karo 0x00 lan 0xff (yen tinimbang bait pisanan saka header kita nemoni 0xff, tegese iki minangka area sing ora digunakake; 0x00 menehi sinyal kesalahan).
algoritma sampel
Maca saka memori flash
Sembarang maca diiringi mriksa checksum.
Yen checksum ora cocog, maca diulang kaping pirang-pirang kanthi pangarep-arep bisa maca data sing bener.
(iku masuk akal, Linux Ora nyimpen bacaan saka NOR Flash, wis diverifikasi)
Nulis menyang memori flash
Kita nulis data kasebut.
Ayo padha maca.
Yen data sing diwaca ora cocog karo data sing ditulis, kita ngisi area kasebut kanthi nul lan menehi tandha kesalahan.
Nyiyapake microcircuit anyar kanggo operasi
Kanggo inisialisasi, header kanthi versi 1 ditulis ing kaca pisanan (utawa luwih tepate, nol).
Sawise iki, konteks awal ditulis ing kaca iki (isi UUID mesin lan setelan gawan).
Mekaten, memori lampu kilat siap digunakake.
Loading mesin
Nalika mbukak, 8 bait pisanan saben kaca (header + CRC) diwaca, kaca sing nomer Piandel sing ora dingerteni utawa CRC sing salah ora digatekake.
Saka kaca "bener", kaca kanthi versi maksimum dipilih, lan saka kaca kasebut, kaca kanthi jumlah paling dhuwur dijupuk.
Rekaman pisanan diwaca, CRC dicenthang bener, lan gendera "konteks" dicenthang. Yen kabeh OK, kaca iki dianggep saiki. Yen ora, kita bali menyang sing sadurunge nganti kita nemokake kaca "urip".
lan ing kaca sing ditemokake, kita maca kabeh cathetan, sing digunakake karo gendera "konteks".
Simpen kamus zlib (bakal perlu ditambahake menyang kaca iki).
Mekaten, loading rampung, konteks dipulihake, sampeyan bisa kerja.
Nambahake Entri Log
Kita kompres rekaman nganggo kamus sing bener, sing nemtokake Z_SYNC_FLUSH. Kita ndeleng manawa rekaman sing dikompres cocog karo kaca saiki.
Yen ora cocog (utawa ana kesalahan CRC ing kaca), miwiti kaca anyar (ndeleng ngisor).
Kita nulis rekaman lan CRC. Yen ana kesalahan, kita miwiti kaca anyar.
Kaca anyar
Kita milih kaca gratis kanthi nomer minimal (kita nganggep kaca kanthi checksum sing salah ing header utawa kanthi versi sing luwih murah tinimbang sing saiki dadi gratis). Yen ora ana kaca kasebut, kita milih kaca kanthi jumlah minimal saka sing duwe versi sing padha karo sing saiki.
Kita mbusak kaca sing dipilih. Kita mbandhingake isi karo 0xff. Yen ana sing salah, kita njupuk kaca gratis sabanjure, lsp.
Kita nulis header menyang kaca sing wis dibusak, entri pisanan minangka kahanan konteks saiki, sing sabanjure yaiku entri log sing ora ditulis (yen ana).
Aplikasi saka format
Ing mratelakake panemume, iki format apik kanggo nyimpen sembarang liyane utawa kurang compressible lepen informasi (teks biasa, JSON, MessagePack, CBOR, bisa protobuf) ing NOR Flash.
Mesthine, format kasebut "diasah" kanggo SLC NOR Flash.
Sampeyan ngirim ora digunakake karo media BER dhuwur kayata NAND utawa MLC NOR. (Memori kuwi malah kasedhiya kanggo Advertisement? Aku wis mung ndeleng nyebataken ing karya ing kode koreksi).
Kajaba iku, ora bisa digunakake karo piranti sing duwe FTL dhewe: USB flash, SD, MicroSD, lsp. (kanggo memori kasebut, aku nggawe format kanthi ukuran kaca 512 bait, tandha tangan ing wiwitan saben kaca lan nomer rekaman unik - kadhangkala bisa mbalekake kabeh data saka flash drive "glitched" kanthi maca urutan).
Gumantung saka tugas, format kasebut bisa digunakake tanpa owah-owahan ing flash drive saka 128Kbit (16Kb) dadi 1Gbit (128Mb). Yen dikarepake, bisa digunakake ing chip kapasitas luwih gedhe, nanging sampeyan bisa uga kudu nyetel ukuran kaca (Nanging ing kene ana pitakonan babagan kelayakan ekonomi, rega NOR Flash volume gedhe ora nyemangati).
Yen ana sing nemokake format kasebut menarik lan pengin digunakake ing proyek sumber terbuka, tulisen menyang aku, aku bakal nyoba golek wektu, polish kode lan kirim ing github.
kesimpulan
Minangka kita bisa ndeleng, ing pungkasan format dadi prasaja lan malah mboseni.
Pancen angel nggambarake evolusi sudut pandangku ing sawijining artikel, nanging percayaa: wiwitane aku pengin nggawe sing canggih, ora bisa dirusak, bisa urip sanajan ana bledosan nuklir ing jarak sing cedhak. Nanging, alesan (mugi-mugi) isih menang lan mboko sithik prioritas pindhah menyang gamblang lan compactness.
Apa aku salah? Ya, mesthi. Bisa uga kita tuku kumpulan microcircuits kualitas rendah. Utawa kanggo sawetara alesan liyane peralatan ora bakal ketemu pangarepan ing syarat-syarat linuwih.
Apa aku duwe rencana iki? Aku sing sawise maca artikel sampeyan ora mangu sing ana rencana. Lan ora malah siji.
Dadi luwih serius, format kasebut dikembangake minangka pilihan kerja lan minangka "balon uji coba".
Saiki, kabeh bisa digunakake ing meja, solusi kasebut bakal disebarake kanthi harfiah sajrone sawetara dina (kira-kira) ing satus piranti, ayo ndeleng apa sing bakal kelakon ing operasi "pertempuran" (untung, muga-muga, format kasebut ngidini deteksi kegagalan sing bisa dipercaya, supaya bisa ngumpulake statistik lengkap). Ing sawetara sasi bakal bisa nggawe kesimpulan (lan yen sampeyan ora beruntung, malah luwih awal).
Yen, sawise nggunakake, ana masalah serius sing ditemokake lan dandan dibutuhake, aku mesthi bakal nulis babagan iki.
Sastra
Aku ora pengin nggawe dhaptar referensi sing dawa lan mboseni; sawise kabeh, saben wong duwe Google.
Ing kene aku mutusake ninggalake dhaptar temuan sing katon menarik banget kanggo aku, nanging mboko sithik dheweke langsung pindhah menyang teks artikel, lan mung siji item sing isih ana ing dhaptar:
- Utilitas saka penulis zlib. Bisa nampilake isi arsip deflate/zlib/gzip ing wangun sing cetha. Yen sampeyan kudu ngatasi struktur internal format deflate (utawa gzip), aku menehi saran banget.
Source: www.habr.com
