

Halo kabeh! Jenengku Golov Nikolay. Sadurunge, aku kerja ing Avito lan ngatur Platform Data sajrone nem taun, yaiku, aku kerja ing kabeh database: analitis (Vertica, ClickHouse), streaming lan OLTP (Redis, Tarantool, VoltDB, MongoDB, PostgreSQL). Sak iki wektu, aku urusan karo nomer akeh database - beda banget lan mboten umum, lan kasus non-standar sing digunakake.
Aku saiki kerja ing ManyChat. Intine, iki minangka wiwitan - anyar, ambisius lan berkembang kanthi cepet. Lan nalika pisanan gabung karo perusahaan kasebut, ana pitakonan klasik: "Apa sing kudu ditindakake dening wiwitan enom saka DBMS lan pasar database?"
Ing artikel iki, adhedhasar laporan ing , Aku bakal njawab pitakonan iki. Versi video saka laporan kasedhiya ing .
Database umum dikenal 2020
Iki 2020, aku ndeleng lan ndeleng telung jinis database.
Tipe pisanan - database OLTP klasik: PostgreSQL, SQL Server, Oracle, MySQL. Dheweke wis ditulis suwe banget, nanging isih relevan amarga wis akrab karo komunitas pangembang.
Jinis kapindho yaiku dhasar saka "nol". Dheweke nyoba nyingkirake pola klasik kanthi nilar SQL, struktur tradisional lan ACID, kanthi nambahake sharding sing dibangun lan fitur atraktif liyane. Contone, iki Cassandra, MongoDB, Redis utawa Tarantool. Kabeh solusi kasebut pengin nawakake pasar sing anyar lan ngenggoni ceruk amarga pancen trep kanggo tugas tartamtu. Aku bakal nuduhake database kasebut kanthi istilah payung NOSQL.
"nol" wis rampung, kita wis biasa karo database NOSQL, lan jagad, saka sudut pandangku, njupuk langkah sabanjure - kanggo database ngatur. Basis data iki duwe inti sing padha karo basis data OLTP klasik utawa NoSQL anyar. Nanging dheweke ora butuh DBA lan DevOps lan nganggo piranti keras sing dikelola ing awan. Kanggo pangembang, iki "mung basis" sing bisa digunakake nang endi wae, nanging ora ana sing peduli carane diinstal ing server, sing ngatur server lan sing nganyari.
Conto database kasebut:
- AWS RDS minangka pambungkus sing dikelola kanggo PostgreSQL/MySQL.
- DynamoDB minangka analog AWS saka basis data adhedhasar dokumen, padha karo Redis lan MongoDB.
- Amazon Redshift minangka basis data analitik sing dikelola.
Iki minangka basis data lawas, nanging digedhekake ing lingkungan sing dikelola, tanpa kudu nggarap hardware.
Cathetan. Conto kasebut dijupuk kanggo lingkungan AWS, nanging analoge uga ana ing Microsoft Azure, Google Cloud, utawa Yandex.Cloud.
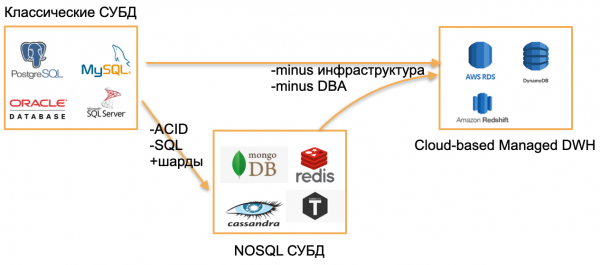
Apa sing anyar babagan iki? Ing 2020, ora ana.
Konsep tanpa server
Sing paling anyar ing pasar ing taun 2020 yaiku solusi tanpa server utawa tanpa server.
Aku bakal nyoba nerangake apa tegese nggunakake conto layanan biasa utawa aplikasi backend.
Kanggo nyebarake aplikasi backend biasa, kita tuku utawa nyewa server, nyalin kode kasebut, nerbitake titik pungkasan ing njaba lan mbayar sewa, listrik lan layanan pusat data. Iki minangka skema standar.
Apa ana cara liya? Kanthi layanan tanpa server sampeyan bisa.
Apa fokus pendekatan iki: ora ana server, malah ora nyewa conto virtual ing méga. Kanggo nyebarake layanan kasebut, nyalin kode (fungsi) menyang repositori lan nerbitake menyang titik pungkasan. Banjur kita mung mbayar saben telpon kanggo fungsi iki, ora nggatekake hardware sing dileksanakake.
Aku bakal nyoba kanggo ilustrasi pendekatan iki karo gambar.
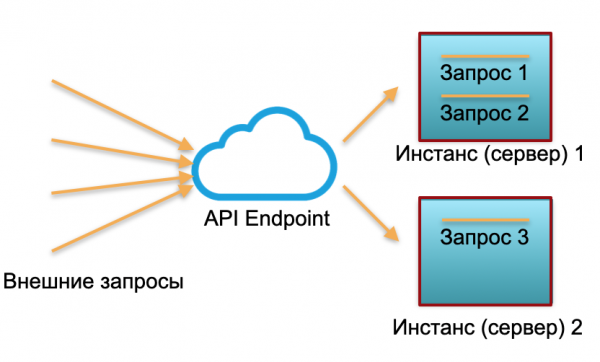
Panyebaran klasik. Kita duwe layanan kanthi beban tartamtu. Kita mundhakaken rong kedadean: server fisik utawa kedadean ing AWS. Panjaluk eksternal dikirim menyang kasus kasebut lan diproses ing kana.
Nalika sampeyan bisa ndeleng ing gambar, server ora dibuwang merata. Siji 100% digunakake, ana rong panjaluk, lan siji mung 50% - sebagian nganggur. Yen ora teka telung panjalukan, nanging 30, kabeh sistem ora bakal bisa kanggo ngrampungake karo mbukak lan bakal wiwit alon mudhun.
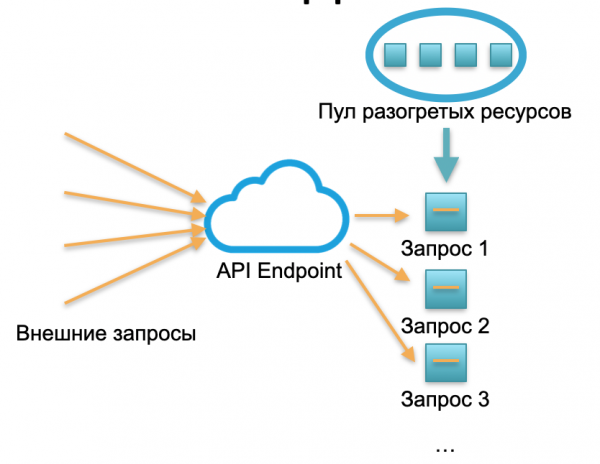
Penyebaran tanpa server. Ing lingkungan tanpa server, layanan kasebut ora duwe conto utawa server. Ana blumbang tartamtu saka sumber panas - cilik disiapake Docker kontaner karo tugas tugas kode. Sistem kasebut nampa panjalukan eksternal lan kanggo saben kerangka tanpa server ngunggahake wadhah cilik kanthi kode: ngolah panjaluk kasebut lan mateni wadhah kasebut.
Siji panjaluk - siji wadhah diunggahake, 1000 panjaluk - 1000 wadhah. Lan penyebaran ing server hardware wis dadi karya panyedhiya maya. Iku rampung didhelikake dening framework tanpa server. Ing konsep iki kita mbayar saben telpon. Contone, siji telpon teka dina - kita mbayar siji telpon, yuta teka saben menit - kita mbayar kanggo yuta. Utawa ing detik, iki uga kedadeyan.
Konsep nerbitake fungsi tanpa server cocok kanggo layanan tanpa negara. Lan yen sampeyan butuh (negara) layanan statefull, banjur kita nambah database kanggo layanan. Ing kasus iki, nalika nggarap negara, saben fungsi statefull mung nulis lan maca saka database. Kajaba iku, saka basis data saka telung jinis sing diterangake ing wiwitan artikel.
Apa watesan umum kabeh database kasebut? Iki minangka biaya saka server maya utawa hardware sing terus digunakake (utawa sawetara server). Ora Matter apa kita nggunakake database klasik utawa ngatur, apa kita duwe Devops lan admin utawa ora, kita isih mbayar kanggo hardware, listrik lan rental pusat data 24/7. Yen kita duwe basis klasik, kita mbayar master lan budak. Yen database sharded banget dimuat, kita mbayar 10, 20 utawa 30 server, lan kita mbayar terus.
Ngarsane server sing dilindhungi kanthi permanen ing struktur biaya sadurunge dianggep minangka ala sing perlu. Database konvensional uga duwe kesulitan liyane, kayata watesan jumlah sambungan, watesan skala, konsensus sing disebarake geo - bisa uga ditanggulangi ing database tartamtu, nanging ora kabeh bebarengan lan ora saenipun.
Database tanpa server - teori
Pitakonan 2020: apa bisa uga nggawe database tanpa server? Kabeh wong wis krungu babagan backend tanpa server ... ayo nyoba nggawe database tanpa server?
Iki muni aneh, amarga database minangka layanan statefull, ora cocok banget kanggo infrastruktur tanpa server. Ing wektu sing padha, negara database gedhe banget: gigabyte, terabyte, lan ing database analitis malah petabyte. Ora gampang ngunggahake ing wadhah Docker sing entheng.
Ing sisih liya, meh kabeh database modern ngemot akeh logika lan komponen: transaksi, koordinasi integritas, prosedur, dependensi relasional lan akeh logika. Kanggo logika database cukup akeh, negara cilik cukup. Gigabyte lan Terabyte langsung digunakake mung bagean cilik saka logika database sing melu langsung nglakokake pitakon.
Dadi, ide kasebut yaiku: yen bagean saka logika ngidini eksekusi stateless, kenapa ora dibagi basis dadi bagean Stateful lan Stateless.
Serverless kanggo solusi OLAP
Ayo ndeleng apa sing bisa nglereni database dadi bagean Stateful lan Stateless nggunakake conto praktis.
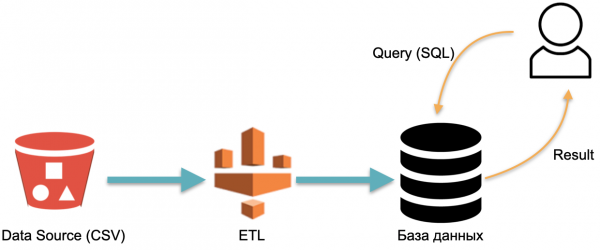
Contone, kita duwe database analitis: data eksternal (silinder abang ing sisih kiwa), proses ETL sing ngemot data menyang database, lan Analyst sing ngirim pitakon SQL kanggo database. Iki minangka skema operasi gudang data klasik.
Ing skema iki, ETL ditindakake kanthi syarat sapisan. Banjur sampeyan kudu mbayar terus-terusan kanggo server sing database mlaku karo data sing diisi ETL, supaya ana sing ngirim pitakon.
Ayo goleki pendekatan alternatif sing ditindakake ing AWS Athena Serverless. Ora ana perangkat keras khusus sing diundhuh kanthi permanen kanggo nyimpen data sing diundhuh. Tinimbang iki:
- Pangguna ngirim pitakon SQL menyang Athena. Pangoptimal Athena nganalisa query SQL lan nelusuri nyimpen metadata (Metadata) kanggo data tartamtu sing dibutuhake kanggo nglakokake query.
- Pangoptimal, adhedhasar data sing diklumpukake, ndownload data sing dibutuhake saka sumber eksternal menyang panyimpenan sementara (database sementara).
- Pitakonan SQL saka pangguna dieksekusi ing panyimpenan sementara lan asil kasebut bali menyang pangguna.
- Panyimpenan sementara dibuwang lan sumber daya dibebasake.
Ing arsitektur iki, kita mung mbayar kanggo proses nglakokaké panjalukan. Ora ana panjaluk - ora ana biaya.
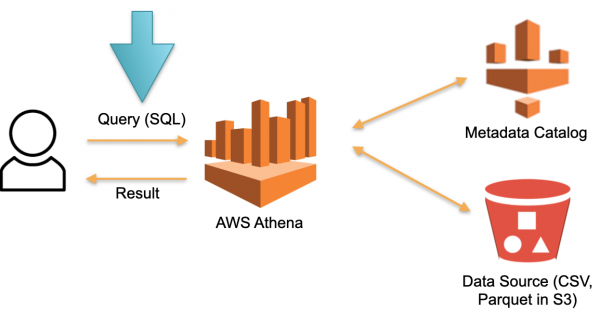
Iki minangka pendekatan sing bisa digunakake lan ditindakake ora mung ing Athena Serverless, nanging uga ing Redshift Spectrum (ing AWS).
Conto Athena nuduhake yen database Serverless bisa digunakake ing pitakon nyata kanthi puluhan lan atusan Terabyte data. Atusan Terabytes mbutuhake atusan server, nanging ora kudu mbayar - kita mbayar panjaluk kasebut. Kacepetan saben panjalukan (banget) kurang dibandhingake karo database analitis khusus kaya Vertica, nanging kita ora mbayar wektu downtime.
Basis data kasebut bisa ditrapake kanggo pitakon ad-hoc analitis sing langka. Contone, nalika kita mutusake kanthi spontan kanggo nyoba hipotesis babagan sawetara data sing gedhe banget. Athena sampurna kanggo kasus kasebut. Kanggo panjaluk biasa, sistem kasebut larang. Ing kasus iki, cache data ing sawetara solusi khusus.
Serverless kanggo solusi OLTP
Conto sadurunge ndeleng tugas OLAP (analitik). Saiki ayo goleki tugas OLTP.
Ayo mbayangno PostgreSQL utawa MySQL sing bisa diukur. Ayo ngunggahake conto sing dikelola biasa PostgreSQL utawa MySQL kanthi sumber daya minimal. Nalika instance nampa luwih akeh, kita bakal nyambungake replika tambahan sing bakal disebarake bagean saka beban maca. Yen ora ana panjaluk utawa beban, kita mateni replika. Kaping pisanan yaiku master, lan liyane minangka replika.
Ide iki ditindakake ing basis data sing diarani Aurora Serverless AWS. Prinsip kasebut gampang: panjaluk saka aplikasi eksternal ditampa dening armada proxy. Ningali mundhak beban, nyedhiyakake sumber daya komputasi saka kedadeyan minimal sing wis dipanasake - sambungan kasebut digawe kanthi cepet. Pateni kedadean kedadeyan kanthi cara sing padha.
Ing Aurora ana konsep Aurora Capacity Unit, ACU. Iki minangka (sarat) conto (server). Saben ACU tartamtu bisa dadi master utawa budak. Saben Unit Kapasitas duwe RAM dhewe, prosesor lan disk minimal. Mulane, siji master, liyane diwaca mung replika.
Jumlah Unit Kapasitas Aurora iki minangka parameter sing bisa dikonfigurasi. Jumlah minimal bisa dadi siji utawa nol (ing kasus iki, database ora bisa digunakake yen ora ana panjaluk).
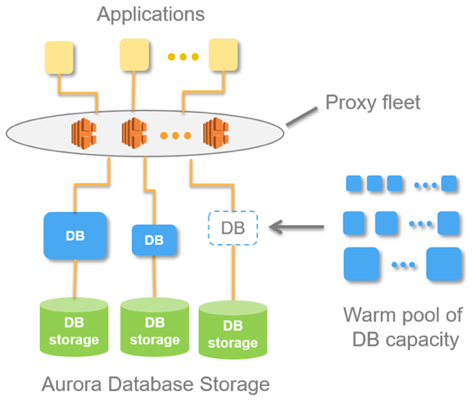
Nalika basis nampa panjalukan, armada proxy mundhakaken Aurora Kapasitas Unit, nambah sumber daya kinerja sistem. Kemampuan kanggo nambah lan ngurangi sumber daya ngidini sistem kanggo "juggle" sumber daya: kanthi otomatis nampilake ACU individu (ngganti wong anyar) lan muter metu kabeh nganyari saiki kanggo sumber daya mundur.
Basis Aurora Serverless bisa ngukur beban maca. Nanging dokumentasi ora ngomong iki langsung. Bisa uga aran kaya bisa ngangkat multi-master. Ora ana sihir.
Basis data iki cocog kanggo ngindhari mbuwang akeh dhuwit ing sistem kanthi akses sing ora bisa ditebak. Contone, nalika nggawe MVP utawa marketing situs kertu bisnis, kita biasane ora nyana beban stabil. Patut, yen ora ana akses, kita ora mbayar kanggo kedadean. Nalika ana beban sing ora dikarepke, contone sawise konferensi utawa kampanye iklan, akeh wong sing ngunjungi situs kasebut lan beban mundhak sacara dramatis, Aurora Serverless kanthi otomatis njupuk beban iki lan nyambungake sumber daya sing ilang (ACU). Banjur konferensi liwati, kabeh wong lali babagan prototipe, server (ACU) dadi peteng, lan biaya mudhun dadi nol - trep.
Solusi iki ora cocok kanggo beban dhuwur sing stabil amarga ora ngukur beban nulis. Kabeh sambungan lan pedhot sumber daya kasebut dumadi ing "titik skala" - titik nalika database ora didhukung dening transaksi utawa tabel sementara. Contone, ing minggu titik ukuran bisa uga ora kelakon, lan basis bisa ing sumber daya padha lan mung ora bisa nggedhekake utawa kontrak.
Ora ana sihir - iku PostgreSQL biasa. Nanging proses nambah mesin lan medhot iku sebagian otomatis.
Serverless dening desain
Aurora Serverless minangka basis data lawas sing ditulis ulang kanggo awan kanggo njupuk kauntungan saka sawetara keuntungan saka Serverless. Lan saiki aku bakal pitutur marang kowe babagan basis, sing asline ditulis kanggo awan, kanggo pendekatan tanpa server - Serverless-by-design. Iku langsung dikembangaké tanpa asumsi sing bakal mbukak ing server fisik.
Dasar iki diarani Snowflake. Wis telung pamblokiran tombol.
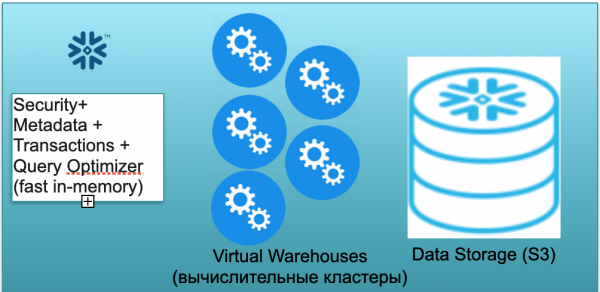
Sing pertama yaiku blok metadata. Iki minangka layanan memori cepet sing ngrampungake masalah keamanan, metadata, transaksi, lan optimasi pitakon (katon ing ilustrasi ing sisih kiwa).
Blok kapindho yaiku set kluster komputasi virtual kanggo petungan (ing ilustrasi ana set bunder biru).
Blok katelu yaiku sistem panyimpenan data adhedhasar S3. S3 minangka panyimpenan obyek tanpa dimensi ing AWS, kaya Dropbox tanpa dimensi kanggo bisnis.
Ayo ndeleng carane Snowflake bisa dianggo, assuming wiwitan kadhemen. Tegese, ana database, data kasebut dimuat, ora ana pitakon sing mlaku. Mulane, yen ora ana panjalukan kanggo database, banjur kita wis ngunggahake layanan Metadata cepet ing memori (blok pisanan). Lan kita duwe panyimpenan S3, ing ngendi data tabel disimpen, dipérang dadi micropartitions. Kanggo kesederhanaan: yen tabel ngemot transaksi, banjur micropartitions minangka dina transaksi. Saben dina minangka partisi mikro sing kapisah, file sing kapisah. Lan nalika database makaryakke ing mode iki, sampeyan mung mbayar papan sing dikuwasani dening data. Menapa malih, tingkat saben jog banget kurang (utamané njupuk menyang akun komprèsi wujud). Layanan metadata uga dianggo terus-terusan, nanging sampeyan ora butuh akeh sumber daya kanggo ngoptimalake pitakon, lan layanan kasebut bisa dianggep minangka shareware.
Saiki ayo bayangake manawa pangguna teka ing database kita lan ngirim query SQL. Pitakonan SQL langsung dikirim menyang layanan Metadata kanggo diproses. Mulane, nalika nampa panjalukan, layanan iki nganalisa panjalukan, data sing kasedhiya, ijin pangguna lan, yen kabeh apik, nggawe rencana kanggo ngolah panjaluk kasebut.
Sabanjure, layanan kasebut miwiti peluncuran kluster komputasi. Kluster komputasi minangka kluster server sing nindakake petungan. Sing, iki kluster sing bisa ngemot 1 server, 2 server, 4, 8, 16, 32 - minangka akeh sing pengin. Sampeyan mbuwang panjalukan lan peluncuran kluster iki langsung diwiwiti. Iku pancene njupuk detik.
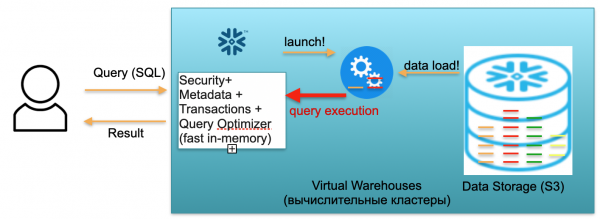
Sabanjure, sawise kluster diwiwiti, mikropartisi sing dibutuhake kanggo ngolah panyuwunan sampeyan wiwit disalin menyang kluster saka S3. Dadi, ayo bayangake yen kanggo nglakokake query SQL sampeyan butuh rong partisi saka siji meja lan siji saka liyane. Ing kasus iki, mung telung partisi sing dibutuhake bakal disalin menyang kluster, lan ora kabeh tabel kabeh. Pramila, lan sabenere amarga kabeh dumunung ing siji pusat data lan disambungake kanthi saluran sing cepet banget, kabeh proses transfer kedadeyan kanthi cepet: ing sawetara detik, arang banget ing sawetara menit, kajaba kita ngomong babagan sawetara panjaluk sing nggegirisi . Mulane, partisi mikro disalin menyang kluster komputasi, lan, sawise rampung, query SQL dieksekusi ing kluster komputasi iki. Asil saka panjalukan iki bisa dadi siji baris, sawetara baris utawa tabel - dikirim externally kanggo pangguna supaya bisa ngundhuh, nampilake ing alat BI, utawa nggunakake ing sawetara cara liyane.
Saben query SQL ora mung bisa maca agregat saka data sing dimuat sadurunge, nanging uga mbukak / ngasilake data anyar ing database. Tegese, bisa dadi pitakonan sing, contone, nglebokake cathetan anyar menyang meja liyane, sing ndadékaké munculé partisi anyar ing kluster komputasi, sing, kanthi otomatis disimpen ing panyimpenan S3 siji.
Skenario sing diterangake ing ndhuwur, saka tekane pangguna nganti mundhakaken kluster, ngunggahake data, nglakokake pitakon, entuk asil, dibayar kanthi tarif menit nggunakake kluster komputasi virtual sing diangkat, gudang virtual. Tarif beda-beda gumantung saka zona AWS lan ukuran kluster, nanging rata-rata sawetara dolar saben jam. Kluster papat mesin kaping pindho luwih larang tinimbang kluster loro mesin, lan kluster wolung mesin isih kaping pindho larang. Pilihan saka 16, 32 mesin kasedhiya, gumantung ing kerumitan panjalukan. Nanging sampeyan mung mbayar menit kasebut nalika kluster bener-bener mlaku, amarga nalika ora ana panjaluk, sampeyan bakal njupuk tangan sampeyan, lan sawise 5-10 menit ngenteni (parameter sing bisa dikonfigurasi) bakal metu dhewe. mbebasake sumber daya lan dadi gratis.
Skenario sing realistis yaiku nalika sampeyan ngirim panjaluk, kluster kasebut muncul, kanthi relatif, sajrone menit, bakal ngetung menit liyane, banjur limang menit mati, lan sampeyan bakal mbayar pitung menit operasi kluster iki, lan ora kanggo sasi lan taun.
Skenario pisanan sing diterangake nggunakake Snowflake ing setelan pangguna siji. Saiki ayo bayangake manawa ana akeh pangguna, sing luwih cedhak karo skenario nyata.
Ayo kita duwe akeh analis lan laporan Tableau sing terus-terusan ngebom database kita kanthi akeh pitakon SQL analitis sing prasaja.
Kajaba iku, ayo ngomong yen kita duwe Ilmuwan Data inventif sing nyoba nindakake perkara sing nggegirisi karo data, operate kanthi puluhan Terabyte, nganalisa milyaran lan triliun larik data.
Kanggo rong jinis beban kerja sing diterangake ing ndhuwur, Snowflake ngidini sampeyan ngunggahake sawetara klompok komputasi mandiri kanthi kapasitas sing beda. Kajaba iku, kluster komputasi iki bisa digunakake kanthi mandiri, nanging kanthi data konsisten sing umum.
Kanggo nomer akeh pitakonan cahya, sampeyan bisa mundhakaken 2-3 klompok cilik, kira-kira 2 mesin saben. Prilaku iki bisa ditindakake, ing antarane, nggunakake setelan otomatis. Dadi sampeyan ngomong, "Snowflake, mundhakaken klompok cilik. Yen beban kasebut mundhak ing ndhuwur parameter tartamtu, mundhakake nomer loro sing padha, katelu. Nalika beban wiwit suda, mateni keluwihan." Supaya ora ketompo carane akeh analis teka lan miwiti ndeleng laporan, saben wong duwe sumber daya sing cukup.
Ing wektu sing padha, yen analis turu lan ora ana sing ndeleng laporan kasebut, kluster bisa dadi peteng, lan sampeyan mandheg mbayar.
Ing wektu sing padha, kanggo pitakon abot (saka Data Scientists), sampeyan bisa ngunggahake siji kluster sing gedhe banget kanggo 32 mesin. Kluster iki uga bakal dibayar mung kanggo menit lan jam nalika panyuwunan raksasa sampeyan mlaku ing kana.
Kesempatan sing diterangake ing ndhuwur ngidini sampeyan mbagi ora mung 2, nanging uga luwih akeh jinis beban kerja dadi klompok (ETL, pemantauan, materialisasi laporan, ...).
Ayo ngringkes Snowflake. Dasar nggabungake ide sing apik lan implementasine sing bisa ditindakake. Ing ManyChat, kita nggunakake Snowflake kanggo nganalisa kabeh data sing ana. Kita ora duwe telung klompok, kaya ing conto, nanging saka 5 nganti 9, kanthi ukuran sing beda-beda. We have conventional 16-mesin, 2-mesin, lan uga super-cilik 1-mesin kanggo sawetara tugas. Dheweke kasil nyebarake beban lan ngidini kita ngirit akeh.
Basis data kasil ngukur beban maca lan nulis. Iki prabédan ageng lan temonan ageng dibandhingake padha "Aurora", kang mung nindakake mbukak mbukak. Snowflake ngidini sampeyan ngukur beban kerja nulis kanthi klompok komputasi kasebut. Yaiku, kaya sing dakkandhakake, kita nggunakake sawetara klompok ing ManyChat, klompok cilik lan super-cilik utamane digunakake kanggo ETL, kanggo ngemot data. Lan analis wis manggon ing klompok medium, sing pancen ora kena pengaruh beban ETL, mula kerjane cepet banget.
Dadi, database cocok kanggo tugas OLAP. Nanging, sayangé, iki durung bisa ditrapake kanggo beban kerja OLTP. Kaping pisanan, database iki minangka kolom, kanthi kabeh akibat sing bakal ditindakake. Kapindho, pendekatan kasebut, nalika saben panyuwunan, yen perlu, sampeyan ngunggahake kluster komputasi lan banjir data, sayangé, durung cukup cepet kanggo beban OLTP. Nunggu detik kanggo tugas OLAP iku normal, nanging kanggo tugas OLTP ora bisa ditampa; 100 ms bakal luwih apik, utawa 10 ms bakal luwih apik.
Asile
Database tanpa server bisa ditindakake kanthi mbagi basis data dadi bagean Stateless lan Stateful. Sampeyan bisa uga wis ngeweruhi ing kabeh conto ing ndhuwur, bagean Stateful, relatif ngandika, nyimpen partisi mikro ing S3, lan Stateless punika optimizer, nggarap metadata, nangani masalah keamanan sing bisa wungu minangka layanan Stateless entheng sawijining.
Nglakokake pitakon SQL uga bisa dianggep minangka layanan negara entheng sing bisa muncul ing mode tanpa server, kaya kluster komputasi Snowflake, mung ngundhuh data sing dibutuhake, nglakokake pitakon lan "metu."
Database tingkat produksi tanpa server wis kasedhiya kanggo digunakake, lagi digunakake. Database tanpa server iki wis siyap kanggo nangani tugas OLAP. Sayange, kanggo tugas OLTP digunakake ... karo nuansa, amarga ana watesan. Ing tangan siji, iki minus. Nanging, ing sisih liya, iki minangka kesempatan. Mbok menawa salah sawijining pembaca bakal nemokake cara kanggo nggawe database OLTP rampung tanpa server, tanpa watesan Aurora.
Mugi sampeyan nemokake iku menarik. Serverless iku masa depan :)
Source: www.habr.com
