

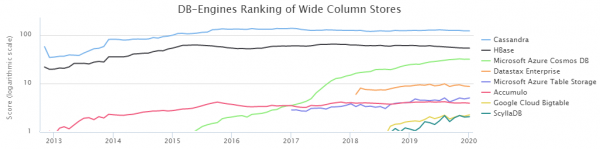
Бұл тіпті әзіл емес; Бұл нақты сурет осы дерекқорлардың мәнін дәл көрсететін сияқты және соңында неге екені белгілі болады:

DB-Engines Ranking сәйкес NoSQL бағандарының ең танымал екі дерекқоры - Cassandra (бұдан әрі CS) және HBase (HB).
Тағдырдың қалауымен Сбербанктегі деректерді жүктеуді басқару командасы қазірдің өзінде бар және HB-мен тығыз жұмыс істейді. Осы уақыт ішінде біз оның күшті және әлсіз жақтарын жақсы түсініп, оны қалай пайдалану керектігін білдік. Дегенмен, CS түріндегі баламаның болуы бізді үнемі күмәнмен қинады: біз дұрыс таңдау жасадық па? Әсіресе нәтижелерден бері DataStax сынақтары CS HB-ді көшкін арқылы оңай жеңетінін мәлімдеді. Дегенмен, DataStax-тың жеке мүдделері бар, сондықтан сіз бұл үшін олардың сөзін қабылдамауыңыз керек. Тестілеу шарттары туралы салыстырмалы түрде шектеулі ақпараттар да қызықты болды, сондықтан біз BigData NoSql патшасы кім екенін өзіміз білуге шешім қабылдадық және нәтижелер өте қызықты болды.
Дегенмен, сынақ нәтижелерін талқыламас бұрын, орта конфигурациясының негізгі аспектілерін сипаттау маңызды. CS деректерді жоғалтуға төзімді режимде пайдаланылуы мүмкін. Бұл берілген кілттің деректері үшін тек бір сервер (түйін) жауапты екенін білдіреді және ол қандай да бір себептермен сәтсіздікке ұшыраса, сол кілттің мәні жоғалады. Көптеген қолданбалар үшін бұл маңызды емес, бірақ банк қызметі үшін бұл ережеден гөрі ерекшелік. Біздің жағдайда қауіпсіз сақтау үшін деректердің бірнеше көшірмелері болуы өте маңызды.
Сондықтан КС үш еселік репликация режимі ғана қарастырылды, яғни пернелер кеңістігін құру келесі параметрлермен орындалды:
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}; Консистенцияның қажетті деңгейін қамтамасыз етудің екі жолы бар. Жалпы ереже:
NW + NR > RF
Бұл түйін жазу растауларының саны (NW) плюс түйінді оқу растауларының саны (NR) репликация коэффициентінен көп болуы керек дегенді білдіреді. Біздің жағдайда RF = 3, яғни келесі опциялар қолайлы:
2 + 2 > 3
3 + 1 > 3
Деректерді мүмкіндігінше қауіпсіз сақтау біз үшін өте маңызды болғандықтан, біз 3+1 схемасын таңдадық. Сонымен қатар, HB ұқсас принцип бойынша жұмыс істейді, яғни бұл салыстыру әділірек болады.
Айта кетейік, DataStax өз зерттеулерінде керісінше жасады: олар CS және HB үшін де RF = 1 (соңғысы HDFS параметрлерін өзгерту арқылы) орнатты. Бұл шын мәнінде маңызды аспект, өйткені бұл жағдайда CS өнімділігіне әсері айтарлықтай. Мысалы, төмендегі сурет CS-ге деректерді жүктеуге қажетті уақыттың ұлғаюын көрсетеді:
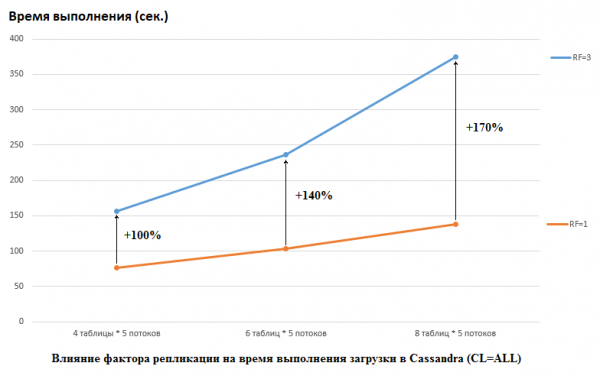
Мұнда біз мынаны көреміз: неғұрлым бәсекелес ағындар деректерді жазады, соғұрлым ұзақ уақыт алады. Бұл табиғи нәрсе, бірақ RF=3 үшін өнімділіктің төмендеуі айтарлықтай жоғары екенін ескеру маңызды. Басқаша айтқанда, егер әрқайсысында 5 ағыны бар 4 кестеге жазсақ (барлығы 20), онда RF=3 шамамен 2 есе жоғалтады (RF=3 үшін 150 секунд, RF=1 үшін 75). Бірақ егер деректерді әрқайсысы 5 ағыны бар 8 кестеге жүктеу арқылы жүктемені арттырсақ (барлығы 40), онда RF=3 2,7 есе жоғалтады (138-ге қарсы 375 секунд).
Мүмкін бұл ішінара DataStax-тың CS жүктемесін сәтті сынауының құпиясы болуы мүмкін, өйткені репликация коэффициентін 2-ден 3-ке дейін өзгерту біздің орнатуымызда HB-ге әсер етпеді. Бұл дискілер біздің конфигурациямыздағы HB үшін кедергі емес дегенді білдіреді. Дегенмен, бұл жерде басқа да көптеген қателіктер бар, өйткені біздің HB нұсқамыз аздап түзетілген және бапталған, орталар мүлдем басқа және т.б. екенін атап өткен жөн. Сондай-ақ, мен CS-ті қалай дұрыс дайындау керектігін білмеймін және онымен жұмыс істеудің тиімді жолдары болуы мүмкін екенін атап өткен жөн. Біз мұны түсініктемелерде анықтай аламыз деп үміттенемін. Бірақ бірінші нәрсе.
Барлық сынақтар әрқайсысы келесі конфигурацияға ие 4 серверден тұратын аппараттық кластерде орындалды:
Орталық процессор: Xeon E5-2680 v4 @ 2.40 ГГц 64 ағын.
Дискілер: 12 SATA қатты дискілері
java нұсқасы: 1.8.0_111
CS нұсқасы: 3.11.5
cassandra.yml параметрлерітаңбалар_саны: 256
hinted_handoff_enabled: шын
hinted_handoff_throttle_in_kb: 1024
максималды_кеңестер_жеткізу_ағындары: 2
hints_directory: /data10/cassandra/hints
кеңестер_тазалау_кезеңі_мс: 10000
максимум_кеңестер_файл_өлшемі_mb: 128
batchlog_replay_throttle_in_kb: 1024
аутентификация: AllowAllAuthenticator
авторизатор: AllowAllAuthorizer
role_manager: CassandraRoleManager
рөлдердің_жарамдылығы_мс: 2000
рұқсаттардың_жарамдылығы_мс: 2000
тіркелгі деректерінің_жарамдылығы_мс: 2000
бөлуші: org.apache.cassandra.dht.Murmur3Partitioner
деректер_файлының_каталогтары:
— /data1/cassandra/data # әрбір dataN каталогы жеке диск болып табылады
— /data2/cassandra/data
— /data3/cassandra/data
— /data4/cassandra/data
— /data5/cassandra/data
— /data6/cassandra/data
— /data7/cassandra/data
— /data8/cassandra/data
commitlog_каталогы: /data9/cassandra/commitlog
cdc_enabled: жалған
disk_failure_policy: тоқтату
commit_failure_policy: тоқтату
hazırlanmış_statements_cache_size_mb:
thrift_prepared_statements_cache_size_mb:
key_cache_size_in_mb:
кілт_кэшті_сақтау_кезеңі: 14400
жол_кэш_өлшемі_мб: 0
жолды_кэш_сақтау_кезеңі: 0
counter_cache_size_in_mb:
қарсы_кэшті_сақтау_кезеңі: 7200
сақталған_кэштер_каталогы: /data10/cassandra/saved_caches
commitlog_sync: мерзімді
commitlog_sync_period_in_ms: 10000
commitlog_segment_size_in_mb: 32
тұқым_провайдері:
- сынып_атауы: org.apache.cassandra.locator.SimpleSeedProvider
параметрлер:
— тұқымдар: «*,*»
concurrent_reads: 256 # тырысты 64 - ешқандай айырмашылық байқалмады
concurrent_writes: 256 # тырысты 64 - ешқандай айырмашылық байқалмады
concurrent_counter_writes: 256 # тырысты 64 - ешқандай айырмашылық байқалмады
concurrent_materialized_view_writes: 32
memtable_heap_space_in_mb: 2048 # 16 ГБ қолданды - ол баяуырақ болды
memtable_allocation_type: heap_buffers
индекс_жинақтау_сыйымдылығы_мб:
индекс_жинақының_өлшемі_минуттағы_аралығы: 60
trickle_fsync: жалған
trickle_fsync_interval_kb: 10240
сақтау_порты: 7000
ssl_storage_port: 7001
тыңдау_мекенжайы: *
тарату_мекен-жайы: *
эфирде_тыңдау_мекенжайы: шын
internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
бастау_нативті_тасымалдау: шын
жергілікті_көлік_порты: 9042
start_rpc: шын
rpc_адрес: *
rpc_порты: 9160
rpc_keepalive: шын
rpc_server_type: синхрондау
thrift_framed_transport_sele_in_mb: 15
қосымша_сақтық көшірмелер: жалған
нығыздаудан бұрынғы_сурет: жалған
auto_snapshot: шын
баған_индекс_өлшемі_кб: 64
баған_индекс_кэш_өлшемі_кб: 2
concurrent_compactors: 4
нығыздау_өткізу_мб_секунд: 1600
sstable_preemptive_open_interval_mb: 50
оқу_сұранысының_уақыты_мсында: 100000
диапазон_сұраныс_уақытының_минутында: 200000
write_quest_timeout_in_ms: 40000
counter_write_request_timeout_in_ms: 100000
cas_conttention_timeout_in_ms: 20000
truncate_request_timeout_in_ms: 60000
сұрау_уақытының_минусы: 200000
slow_query_log_timeout_in_ms: 500
кросс_түйін_уақыты: жалған
endpoint_snitch: GossipingPropertyFileSnitch
dynamic_snitch_update_in_ms: 100
dynamic_snitch_reset_interval_ms: 600000
dynamic_snitch_жамандық шегі: 0.1
сұрау_жоспарлаушысы: org.apache.cassandra.scheduler.NoScheduler
сервер_шифрлау_опциялары:
түйінаралық_шифрлау: жоқ
клиент_шифрлау_опциялары:
қосулы: жалған
түйінаралық_қысу: DC
inter_dc_tcp_nodelay: жалған
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
enable_user_defined_functions: false
enable_scripted_user_defined_functions: false
windows_таймер_интервалы: 1
мөлдір_деректер_шифрлау_опциялары:
қосулы: жалған
құлпытас_ескерту шегі: 1000
құлпытас_сәтсіздігі_шегі: 100000
топтаманың_өлшемі_ескерту_шегі_кб: 200
топтаманың_өлшемі_сәтсіз_шегі_кб: 250
unlogged_patch_across_partitions_warn_threshold: 10
тығыздау_үлкен_бөлім_ескерту_шегі_мб: 100
gc_warn_threshold_in_ms: 1000
back_pressure_enabled: жалған
қосу_материалдандырылған_көріністер: шын
enable_sasi_indexes: шын
GC параметрлері:
### CMS параметрлері-XX:+UseParNewGC
-XX:+ConcMarkSweepGC пайдаланыңыз
-XX:+CMSParallelRemarkEnabled
-XX:Тірі қалу коэффициенті=8
-XX:MaxTenuring Threshold=1
-XX:CMSIinitiatingOccupancyFraction=75
-XX:+CMSIinitiatingOccupancyOnly пайдаланыңыз
-XX:CMSWaitDuration=10000
-XX:+CMSParallelInitialMarkEnabled
-XX:+CMSEdenChunksRecordAlways
-XX:+CMSClassUnloadingEnabled
jvm.options жадына 16 Гб бөлінді (біз де 32 Гб қолданып көрдік, ешқандай айырмашылық байқалмады).
Кестелер келесі пәрмен арқылы құрылды:
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};HB нұсқасы: 1.2.0-cdh5.14.2 (org.apache.hadoop.hbase.regionserver.HRegion сыныбында біз MetricsRegion қолданбасын алып тастадық, бұл RegionServer жүйесіндегі аймақтар саны 1000-нан астам болғанда GC-ге әкелді)
Әдепкі емес HBase параметрлеріzookeeper.session.timeout: 120000
hbase.rpc.timeout: 2 минут(лар)
hbase.client.scanner.timeout.period: 2 минут(лар)
hbase.master.handler.count: 10
hbase.regionserver.lease.period, hbase.client.scanner.timeout.period: 2 минут(лар)
hbase.regionserver.handler.count: 160
hbase.regionserver.metahandler.count: 30
hbase.regionserver.logroll.период: 4 сағат(лар)
hbase.regionserver.maxlogs: 200
hbase.hregion.memstore.flush.size: 1 ГБ
hbase.hregion.memstore.block.көбейткіш: 6
hbase.hstore.compactionШегі: 5
hbase.hstore.blockingStoreFiles: 200
hbase.hregion.majorcompaction: 1 күн
hbase-site.xml үшін HBase қызметінің кеңейтілген конфигурация үзіндісі (қауіпсіздік клапаны):
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
HBase RegionServer үшін Java конфигурациясының опциялары:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSIinitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:ReservedCodeCacheSize=256m
hbase.snapshot.master.timeoutMillis: 2 минут(лар)
hbase.snapshot.region.timeout: 2 минут(лар)
hbase.snapshot.master.timeout.millis: 2 минут(лар)
HBase REST серверінің ең үлкен журнал өлшемі: 100 МБ
HBase REST серверіндегі журнал файлының ең көп сақтық көшірмелері: 5
HBase Thrift Server журналының максималды өлшемі: 100 МБ
HBase Thrift серверіндегі журнал файлының ең көп сақтық көшірмелері: 5
Негізгі журналдың максималды өлшемі: 100 МБ
Негізгі ең көп журнал файлының сақтық көшірмелері: 5
RegionServer журналының максималды өлшемі: 100 МБ
RegionServer журналының максималды сақтық көшірмелері: 5
HBase белсенді шеберін анықтау терезесі: 4 минут(лар)
dfs.client.hedged.read.threadpool.size: 40
dfs.client.hedged.read.threshold.millis: 10 миллисекунд(лар)
hbase.rest.threads.min: 8
hbase.rest.threads.max: 150
Процесс файлының максималды дескрипторлары: 180000
hbase.thrift.minWorkerThreads: 200
hbase.master.executor.openregion.threads: 30
hbase.master.executor.closeregion.threads: 30
hbase.master.executor.serverops.threads: 60
hbase.regionserver.thread.compaction.small: 6
hbase.ipc.server.read.threadpool.size: 20
Аймақты жылжытушы ағындар: 6
Клиент Java үймесінің байттағы өлшемі: 1 ГБ
HBase REST серверінің әдепкі тобы: 3 ГБ
HBase Thrift серверінің әдепкі тобы: 3 ГБ
HBase Master бағдарламасының байттағы Java үйме өлшемі: 16 ГБ
HBase RegionServer серверінің байттағы Java үйме өлшемі: 32 ГБ
+ZooKeeper
maxClientCnxns: 601
maxSessionTimeout: 120000
Кестелерді құру:
hbase org.apache.hadoop.hbase.util.RegionSplitter ns:t1 UniformSplit -c 64 -f cf
өзгерту 'ns:t1', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF', ҚЫСЫЛУ => 'GZ'}
Мұнда бір маңызды мәселе бар: DataStax сипаттамасы HB кестелерін жасау үшін қанша аймақ пайдаланылғанын көрсетпейді, бірақ бұл үлкен көлемдер үшін өте маңызды. Сондықтан тестілеу үшін 640 ГБ-қа дейін, яғни орташа өлшемді кестені сақтауға мүмкіндік беретін 64 аймақ таңдалды.
Сынақ кезінде HBase-де 22 мың кесте және 67 мың аймақ болды (бұл жоғарыда аталған патч болмаса, 1.2.0 нұсқасы үшін жойқын болар еді).
Енді кодқа қатысты. Әрбір дерекқор үшін қандай конфигурациялар тиімдірек екені белгісіз болғандықтан, сынақтар әртүрлі комбинацияларда орындалды. Яғни, кейбір сынақтарда жүктеу бір уақытта төрт кестеге орындалды (қосылу үшін барлық төрт түйін пайдаланылды). Басқа сынақтарда сегіз түрлі кесте қолданылды. Кейбір жағдайларда партия өлшемі 100, басқаларында 200 болды (пакет параметрі — төмендегі кодты қараңыз). Мәнге арналған деректер өлшемі 10 байт немесе 100 байт (dataSize) болды. Әр кестеге барлығы 5 миллион жазба жазылды және оқылды. Бес ағын (thNum ағын нөмірі) әрбір кестеге жазылған/оқылған, әрқайсысы өзінің негізгі ауқымын пайдаланады (сан = 1 миллион):
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("BEGIN BATCH ");
for (int i = 0; i < batch; i++) {
String value = RandomStringUtils.random(dataSize, true, true);
sb.append("INSERT INTO ")
.append(tableName)
.append("(id, title) ")
.append("VALUES (")
.append(key)
.append(", '")
.append(value)
.append("');");
key++;
}
sb.append("APPLY BATCH;");
final String query = sb.toString();
session.execute(query);
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN (");
for (int i = 0; i < batch; i++) {
sb = sb.append(key);
if (i+1 < batch)
sb.append(",");
key++;
}
sb = sb.append(");");
final String query = sb.toString();
ResultSet rs = session.execute(query);
}
}
Тиісінше, HB үшін ұқсас функционалдылық қамтамасыз етілді:
Configuration conf = getConf();
HTable table = new HTable(conf, keyspace + ":" + tableName);
table.setAutoFlush(false, false);
List<Get> lGet = new ArrayList<>();
List<Put> lPut = new ArrayList<>();
byte[] cf = Bytes.toBytes("cf");
byte[] qf = Bytes.toBytes("value");
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lPut.clear();
for (int i = 0; i < batch; i++) {
Put p = new Put(makeHbaseRowKey(key));
String value = RandomStringUtils.random(dataSize, true, true);
p.addColumn(cf, qf, value.getBytes());
lPut.add(p);
key++;
}
table.put(lPut);
table.flushCommits();
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lGet.clear();
for (int i = 0; i < batch; i++) {
Get g = new Get(makeHbaseRowKey(key));
lGet.add(g);
key++;
}
Result[] rs = table.get(lGet);
}
}
HB-де клиент деректердің біркелкі таралуына қамқорлық жасауы керек болғандықтан, негізгі тұздау функциясы келесідей болды:
public static byte[] makeHbaseRowKey(long key) {
byte[] nonSaltedRowKey = Bytes.toBytes(key);
CRC32 crc32 = new CRC32();
crc32.update(nonSaltedRowKey);
long crc32Value = crc32.getValue();
byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7);
return ArrayUtils.addAll(salt, nonSaltedRowKey);
}
Енді ең қызықты бөлім – нәтижелер:
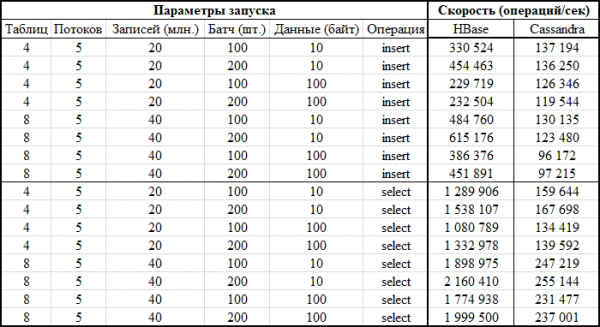
График түрінде бірдей:
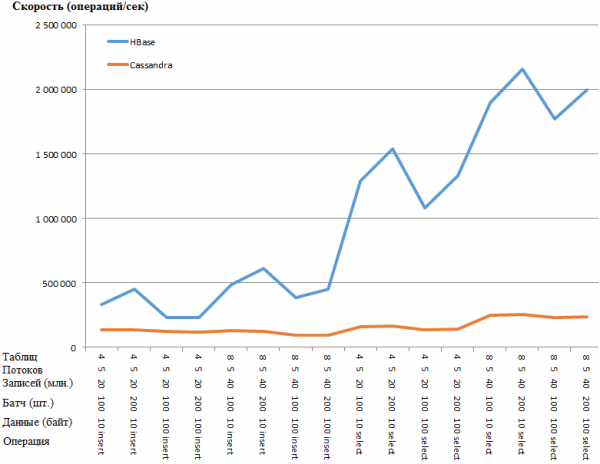
HB артықшылығы соншалықты таңқаларлық, мен CS параметрлерінде кейбір кедергілер бар деп ойлаймын. Дегенмен, Google іздеу және ең айқын параметрлерді өзгерту (мысалы, concurrent_writes немесе memtable_heap_space_in_mb) жылдамдықты арттырмады. Сонымен қатар, бөренелер таза, ешқандай ақаулар жоқ.
Деректер түйіндер бойынша біркелкі таратылады және барлық түйіндердің статистикасы шамамен бірдей.
Түйіндердің бірі бар кестенің статистикасы осылай көрінеді.Пернелер кеңістігі: ks
Оқылған саны: 9383707
Оқу кідірісі: 0.04287025042448576 мс
Жазу саны: 15462012
Жазу кідірісі: 0.1350068438699957 мс
Күтудегі жуулар: 0
Кесте: t1
SSTable саны: 16
Пайдаланылған кеңістік (тірі): 148.59 МБ
Пайдаланылған кеңістік (барлығы): 148.59 МБ
Суреттер пайдаланатын кеңістік (барлығы): 0 байт
Пайдаланылған үйме жады (барлығы): 5.17 МБ
SSTable қысу коэффициенті: 0.5720989576459437
Бөлімдердің саны (бағалау): 3970323
Жадты ұяшықтар саны: 0
Memtable деректер өлшемі: 0 байт
Пайдаланылған жадыдан тыс үйме жады: 0 байт
Memtable қосқыштарының саны: 5
Жергілікті оқылғандар саны: 2346045
Жергілікті оқу кідірісі: NaN мс
Жергілікті жазу саны: 3865503
Жергілікті жазу кідірісі: NaN мс
Күтудегі тазартулар: 0
Жөндеу пайызы: 0.0
Блум сүзгісінің жалған позитивтері: 25
Блум сүзгісінің жалған коэффициенті: 0.00000
Пайдаланылған Блум сүзгі кеңістігі: 4.57 МБ
Блум сүзгісі пайдаланылған үйме жады: 4.57 МБ
Пайдаланылған үйме жады индексінің жиынтық сипаттамасы: 590.02 КБ
Пайдаланылған жинақтық жадты қысу метадеректері: 19.45 КБ
Тығыздалған бөлімнің минималды байттары: 36
Тығыздалған бөлімнің максималды байты: 42
Тығыздалған бөлімнің орташа байты: 42
Бір кесіндідегі орташа тірі жасушалар (соңғы бес минут): NaN
Бір кесіндідегі максималды тірі ұяшықтар (соңғы бес минут): 0
Бір кесіндідегі орташа құлпытастар (соңғы бес минут): NaN
Бір кесіндідегі ең көп құлпытастар (соңғы бес минут): 0
Түсірілген мутациялар: 0 байт
Пакет өлшемін азайту әрекеті (тіпті жеке партияларды жіберу) ешқандай нәтиже бермеді; тек нашарлады. Бұл шын мәнінде CS үшін максималды өнімділік болуы мүмкін, өйткені CS үшін алынған нәтижелер DataStax нәтижелеріне ұқсас — секундына шамамен жүз мың операция. Сонымен қатар, егер ресурстарды пайдалануды қарастыратын болсақ, CS процессор мен дискілік кеңістікті айтарлықтай көбірек пайдаланатынын көреміз:
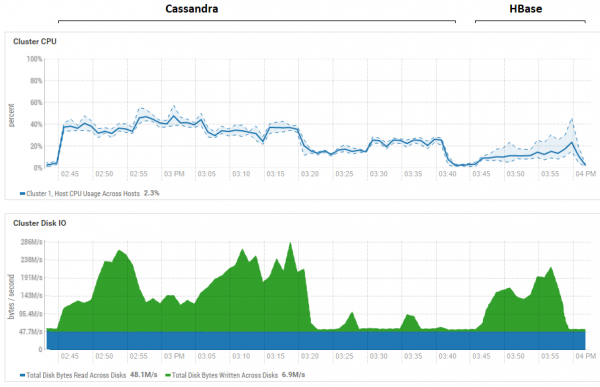
Суретте екі дерекқор үшін қатардағы барлық сынақтарды орындау кезінде пайдалану көрсетілген.
HB оқу өнімділігіндегі маңызды артықшылығына келетін болсақ, екі дерекқор үшін де оқу кезінде дискіні пайдалану өте төмен екені анық (оқу сынақтары әрбір дерекқордың сынақ циклінің соңғы бөлігі болып табылады; мысалы, CS үшін бұл 15:20-дан 15:40-қа дейін). HB жағдайында оның себебі анық - деректердің көпшілігі жадта, жад қоймасында, ал кейбіреулері блок кэште кэштелген. CS-ге келетін болсақ, оның қалай жұмыс істейтіні анық емес, бірақ дискіні пайдалану да көрінбейді. Қалай болғанда да, мен кэшті қосуға тырыстым (row_cache_size_in_mb = 2048) және кэштеу параметрін = {'keys': 'ALL', 'rows_per_partition': '2000000'}, бірақ бұл іс жүзінде жағдайды біршама нашарлатты.
Сондай-ақ, HB аймақтарының саны туралы маңызды мәселені қайталаған жөн. Біздің жағдайда 64 нақтыланды. Оны, айталық, 4-ке дейін төмендететін болсақ, оқу жылдамдығы 2 есе төмендейді. Себебі, memstore тезірек толтырылады, файлдар жиі жыпылықтайды және оқу үшін көбірек файлдарды өңдеу қажет болады, бұл HB үшін өте күрделі операция. Нақты әлемдегі жағдайларда бұл алдын ала бөлу және тығыздау стратегиясын әзірлеу арқылы шешілуі мүмкін. Атап айтқанда, біз фондық режимде қоқыс жинауды және HFiles қысуды үздіксіз орындайтын теңшелетін қызметтік бағдарламаны қолданамыз. DataStax сынақтары әр кестеде тек бір аймақпен жасалған болуы әбден мүмкін (бұл дұрыс емес) және бұл HB оқу сынақтарында неге соншалықты нашар орындағанын түсіндіреді.
Бұдан мынадай алдын ала қорытындылар жасауға болады. Тестілеу кезінде үлкен қателіктер жасалмады деп есептесек, Кассандра табандары саз балшықпен жасалған дүңгіршек тәрізді. Дәлірек айтқанда, мақаланың басындағы суреттегідей, бір аяқпен теңдестіру кезінде ол салыстырмалы түрде жақсы нәтиже көрсетеді, бірақ бірдей жағдайларда сыналған кезде ол толығымен жоғалады. Сонымен қатар, біздің аппараттық құралымызда CPU пайдаланудың төмендігін ескере отырып, біз бір хостқа екі RegionServer HB орналастыруды үйрендік, осылайша өнімділікті екі есе арттырдық. Осылайша, ресурстарды пайдалануды ескере отырып, CS үшін жағдай одан да ауыр болады.
Әрине, бұл сынақтар өте синтетикалық және мұнда қолданылатын деректер көлемі салыстырмалы түрде қарапайым. Мүмкін, егер біз терабайтқа дейін ұлғайсақ, жағдай басқаша болар еді, бірақ біз HB үшін терабайт деректерді өңдей алатын болсақ, бұл CS үшін проблемалық болды. Жауап күту уақытының параметрлері әдепкімен салыстырғанда әлдеқашан ұлғайғанына қарамастан, ол OperationTimedOutException функциясын осы көлемдерде жиі шығарды.
Бірлескен күш-жігеріміздің арқасында біз CS-дегі кедергілерді табамыз деп үміттенемін және егер біз оны тездете алсақ, мен посттың соңында соңғы нәтижелер туралы ақпаратты міндетті түрде қосамын.
ЖАҢАЛЫҚ: Жолдастарымның кеңесінің арқасында мен оқуды тездете алдым. Ол болды:
159 644 операция (4 кесте, 5 ағын, 100 топтама).
Қосқан:
.withLoadBalancingPolicy(жаңа TokenAwarePolicy(DCAwareRoundRobinPolicy.builder().build()))
Мен жіптердің санымен ойнадым. Мен алғаным мынау:
4 кесте, 100 ағын, пакет = 1 (жеке): 301 969 операция
4 кесте, 100 ағын, пакет = 10: 447,608 операция
4 кесте, 100 ағын, пакет = 100: 447,608 операция
Кейінірек баптау бойынша басқа кеңестерді қолданамын, толық сынақ циклін іске қосамын және нәтижелерді посттың соңына қосамын.
Ақпарат көзі: www.habr.com
