

Интернетте R немесе Python іздеу арқылы сіз деректермен жұмыс істеу үшін қайсысы жақсы, жылдам және ыңғайлы деген тақырып бойынша миллиондаған мақалалар мен километрлік талқылауларды таба аласыз. Бірақ, өкінішке орай, бұл мақалалар мен даулардың бәрі әсіресе пайдалы емес.

Бұл мақаланың мақсаты екі тілдің ең танымал пакеттеріндегі деректерді өңдеудің негізгі әдістерін салыстыру болып табылады. Оқырмандарға әлі білмейтін нәрсені тез меңгеруге көмектесіңіз. Python тілінде жазатындар үшін R-де бірдей нәрсені қалай жасауға болатынын біліңіз және керісінше.
Мақала барысында біз R-дегі ең танымал бумалардың синтаксисін талдаймыз. Бұл кітапханаға енгізілген бумалар. tidyverseжәне де пакет data.table. Және олардың синтаксисін салыстырыңыз pandas, Python-дағы ең танымал деректерді талдау пакеті.
Біз деректерді жүктеуден бастап Python және R көмегімен аналитикалық терезе функцияларын орындауға дейінгі деректерді талдаудың барлық жолын кезең-кезеңімен жалғастырамыз.
Мазмұны
Қарастырылып отырған пакеттердің бірінде кейбір деректерді өңдеу әрекеттерін орындау жолын ұмытып қалсаңыз, бұл мақаланы алдау парағы ретінде пайдалануға болады.

1.1.
1.2.
1.3.
1.4.
1.5.
1.6.
2.1.
2.2.
2.3.
Егер сіз деректерді талдауға қызығушылық танытсаңыз, сіз менің и арналар. Мазмұнның көп бөлігі R тіліне арналған.
R және Python арасындағы негізгі синтаксистік айырмашылықтар
Сізге Python-дан R-ге немесе керісінше ауысуды жеңілдету үшін мен сізге назар аудару керек бірнеше негізгі ойларды беремін.
Пакет функцияларына қол жеткізу
Бума R ішіне жүктелгеннен кейін оның функцияларына қол жеткізу үшін бума атын көрсету қажет емес. Көп жағдайда бұл R-де кең таралған емес, бірақ ол қолайлы. Кодыңызда оның функцияларының бірі қажет болса, пакетті мүлде импорттаудың қажеті жоқ, жай ғана буманың атын және функцияның атын көрсету арқылы оны шақырыңыз. R ішіндегі бума мен функция атаулары арасындағы бөлгіш қос қос нүкте болып табылады. package_name::function_name().
Python тілінде, керісінше, оның атын анық көрсету арқылы буманың функцияларын шақыру классикалық болып саналады. Пакетті жүктеп алған кезде оған әдетте қысқартылған атау беріледі, мысалы. pandas әдетте бүркеншік есім қолданылады pd. Бума функциясына нүкте арқылы қол жеткізіледі package_name.function_name().
Тапсырма
R тілінде нысанға мән тағайындау үшін көрсеткіні пайдалану жиі кездеседі. obj_name <- value, жалғыз теңдік белгісі рұқсат етілгенімен, R ішіндегі жалғыз теңдік белгісі мәндерді функция аргументтеріне беру үшін пайдаланылады.
Python тілінде тағайындау тек бір теңдік белгісімен орындалады obj_name = value.
Индекстеу
Мұнда да айтарлықтай айырмашылықтар бар. R тілінде индекстеу біреуден басталады және нәтиже диапазонындағы барлық көрсетілген элементтерді қамтиды,
Python тілінде индекстеу нөлден басталады және таңдалған ауқым индексте көрсетілген соңғы элементті қамтымайды. Сонымен дизайн x[i:j] Python-да j элементін қамтымайды.
Теріс индекстеуде, R белгілеуінде де айырмашылықтар бар x[-1] соңғысынан басқа вектордың барлық элементтерін қайтарады. Python-да ұқсас белгілер тек соңғы элементті қайтарады.
Әдістер және OOP
R OOP-ті өзінше жүзеге асырады, мен бұл туралы мақалада жаздым . Жалпы алғанда, R - функционалды тіл және ондағы барлық нәрсе функцияларға негізделген. Сондықтан, мысалы, Excel пайдаланушылары үшін өтіңіз tydiverse қарағанда оңайырақ болады pandas. Бұл менің субъективті пікірім болса да.
Қысқаша айтқанда, R нысандарында әдістер жоқ (егер S3 сыныптары туралы айтатын болсақ, бірақ әлдеқайда аз таралған басқа OOP іске асырулары бар). Объектінің класына байланысты оларды әртүрлі өңдейтін жалпылама функциялар ғана бар.
Құбырлар
Мүмкін бұл атау pandas Бұл мүлдем дұрыс емес, бірақ мен мағынасын түсіндіруге тырысамын.
Аралық есептеулерді сақтамау және жұмыс ортасында қажетсіз нысандарды шығармау үшін құбырдың бір түрін пайдалануға болады. Анау. есептеу нәтижесін бір функциядан екіншісіне өткізіңіз және аралық нәтижелерді сақтамаңыз.
Аралық есептеулерді бөлек нысандарда сақтайтын келесі код мысалын алайық:
temp_object <- func1()
temp_object2 <- func2(temp_object )
obj <- func3(temp_object2 )Біз 3 операцияны ретімен орындадық және әрқайсысының нәтижесі жеке нысанда сақталды. Бірақ іс жүзінде бұл аралық нысандар бізге қажет емес.
Немесе одан да нашар, бірақ Excel пайдаланушыларына көбірек таныс.
obj <- func3(func2(func1()))Бұл жағдайда біз аралық есептеу нәтижелерін сақтамадық, бірақ кірістірілген функциялары бар кодты оқу өте ыңғайсыз.
Біз R тілінде деректерді өңдеудің бірнеше тәсілдерін қарастырамыз және олар ұқсас операцияларды әртүрлі тәсілдермен орындайды.
Кітапханадағы құбырлар tidyverse оператор жүзеге асырады %>%.
obj <- func1() %>%
func2() %>%
func3()Осылайша біз жұмыстың нәтижесін аламыз func1() және оны бірінші аргумент ретінде беріңіз func2(), содан кейін біз осы есептеудің нәтижесін бірінші аргумент ретінде береміз func3(). Соңында біз барлық орындалған есептеулерді нысанға жазамыз obj <-.
Жоғарыда айтылғандардың бәрі осы мемнің сөздерінен жақсырақ суреттелген:

В data.table тізбектер ұқсас жолмен қолданылады.
newDT <- DT[where, select|update|do, by][where, select|update|do, by][where, select|update|do, by]Шаршы жақшалардың әрқайсысында алдыңғы әрекеттің нәтижесін пайдалануға болады.
В pandas мұндай операциялар нүктемен бөлінген.
obj = df.fun1().fun2().fun3()Анау. дастарханымызды аламыз df және оның әдісін қолданыңыз fun1(), содан кейін алынған нәтижеге әдісті қолданамыз fun2()кейін fun3(). Нәтиже нысанға сақталады obj .
Мәліметтер құрылымдары
R және Python тіліндегі деректер құрылымдары ұқсас, бірақ атаулары әртүрлі.
сипаттамасы
Аты Р
Python/pandas тіліндегі атау
Кесте құрылымы
data.frame, data.table, tibble
Dataaframe
Мәндердің бір өлшемді тізімі
Вектор
Пандалардағы сериялар немесе таза Python тіліндегі тізім
Көп деңгейлі кестелік емес құрылым
Тізім
Сөздік (дикт)
Төменде синтаксистің басқа да ерекшеліктері мен айырмашылықтарын қарастырамыз.
Біз қолданатын пакеттер туралы бірнеше сөз
Алдымен мен сізге осы мақалада таныс болатын пакеттер туралы аздап айтып беремін.
ұқыптылық
Ресми сайт:
Кітапхана tidyverse RStudio компаниясының аға ғылыми қызметкері Хедли Уикхэм жазған. tidyverse деректерді өңдеуді жеңілдететін әсерлі пакеттер жиынтығынан тұрады, оның 5-і CRAN репозиторийінен ең жақсы 10 жүктеп алынған файлдарға кіреді.
Кітапхананың өзегі келесі пакеттерден тұрады: ggplot2, dplyr, tidyr, readr, purrr, tibble, stringr, forcats. Бұл пакеттердің әрқайсысы белгілі бір мәселені шешуге бағытталған. Мысалы dplyr деректерді өңдеу үшін жасалған, tidyr деректерді ұқыпты пішінге келтіру, stringr жолдармен жұмыс істеуді жеңілдетеді және ggplot2 деректерді визуализациялаудың ең танымал құралдарының бірі болып табылады.
Артықшылығы tidyverse қарапайымдылығы және оқуға оңай синтаксисі, ол көптеген жағынан SQL сұрау тіліне ұқсас.
деректер кестесі
Ресми сайт:
Авторы бойынша data.table H2O.ai сайтындағы Мэтт Доул.
Кітапхананың алғашқы шығарылымы 2006 жылы болды.
Пакет синтаксисі бұрынғыдай ыңғайлы емес tidyverse және R-дегі классикалық деректер фреймдерін еске түсіреді, бірақ сонымен бірге функционалдық жағынан айтарлықтай кеңейтілді.
Осы бумадағы кестемен барлық манипуляциялар төртбұрышты жақшада сипатталған және егер сіз синтаксисті аударсаңыз data.table SQL-де сіз келесідей нәрсені аласыз: data.table[ WHERE, SELECT, GROUP BY ]
Бұл пакеттің күші үлкен көлемдегі мәліметтерді өңдеу жылдамдығы болып табылады.
панда
Ресми сайт:
Кітапхананың атауы ақпараттың көпөлшемді құрылымдық жиынын сипаттау үшін қолданылатын «панельдік деректер» эконометрикалық терминінен шыққан.
Авторы бойынша pandas американдық Уэс МакКинни.
Python-да деректерді талдауға келетін болсақ, тең pandas Жоқ. Кез келген дереккөзден деректерді жүктеуден бастап оны визуализациялауға дейін деректермен кез келген манипуляцияны орындауға мүмкіндік беретін өте көп функциялы, жоғары деңгейлі пакет.
Қосымша бумаларды орнату
Осы мақалада талқыланған пакеттер негізгі R және Python дистрибутивтеріне кірмейді. Кішкентай ескерту болса да, егер сіз Anaconda дистрибутивін орнатқан болсаңыз, қосымша орнатыңыз pandas қажет емес.
R ішінде бумаларды орнату
RStudio әзірлеу ортасын кем дегенде бір рет ашқан болсаңыз, R ішінде қажетті буманы орнату жолын бұрыннан білетін шығарсыз. Бумаларды орнату үшін стандартты пәрменді пайдаланыңыз. install.packages() оны тікелей R ішінде іске қосу арқылы.
# установка пакетов
install.packages("vroom")
install.packages("readr")
install.packages("dplyr")
install.packages("data.table")Орнатқаннан кейін пакеттерді қосу керек, ол үшін көп жағдайда команда қолданылады library().
# подключение или импорт пакетов в рабочее окружение
library(vroom)
library(readr)
library(dplyr)
library(data.table)Python-да пакеттерді орнату
Сонымен, егер сізде таза Python орнатылған болса, онда pandas оны қолмен орнату керек. Амалдық жүйеге байланысты пәрмен жолын немесе терминалды ашып, келесі пәрменді енгізіңіз.
pip install pandasСодан кейін біз Python-ға ораламыз және пәрмен арқылы орнатылған буманы импорттаймыз import.
import pandas as pdДеректер жүктелуде
Деректерді өндіру деректерді талдаудағы ең маңызды қадамдардың бірі болып табылады. Қаласаңыз, Python және R екеуі де сізге кез келген көздерден деректерді алудың кең мүмкіндіктерін береді: жергілікті файлдар, Интернет файлдары, веб-сайттар, дерекқорлардың барлық түрлері.

Мақалада біз бірнеше деректер жиынын қолданамыз:
- Google Analytics-тен екі жүктеп алу.
- Титаник жолаушыларының деректер жинағы.
Барлық деректер менде csv және tsv файлдары түрінде. Біз оларды қайдан сұраймыз?
R ішіне деректерді жүктеу: tidyverse, vroom, readr
Деректерді кітапханаға жүктеу үшін tidyverse Екі пакет бар: vroom, readr. vroom заманауи, бірақ болашақта пакеттер біріктірілуі мүмкін.
дәйексөз vroom.
vroom және оқырман
Нені шығарадыvroomүшін білдіредіreadr? Әзірге біз екі пакетті бөлек дамытуды жоспарлап отырмыз, бірақ болашақта пакеттерді біріктіретін шығармыз. Врумның жалқау оқуының бір кемшілігі - белгілі бір деректер мәселелерін алдын ала хабарлау мүмкін емес, сондықтан оларды қалай біріктіруге болатыны туралы біраз ойлану керек.vroom және readr
Шығару нені білдіреді?vroomүшінreadr? Қазіргі уақытта біз екі пакетті бөлек әзірлеуді жоспарлап отырмыз, бірақ болашақта оларды біріктіретін шығармыз. Жалқау оқудың бір кемшілігіvroomдеректерге қатысты кейбір мәселелер туралы алдын ала хабарлау мүмкін емес, сондықтан оларды қалай жақсы біріктіру керектігі туралы ойлану керек.
Бұл мақалада деректерді жүктеудің екі пакетін де қарастырамыз:
Деректер R: vroom бумасына жүктелуде
# install.packages("vroom")
library(vroom)
# Чтение данных
## vroom
ga_nov <- vroom("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_nowember.csv")
ga_dec <- vroom("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_december.csv")
titanic <- vroom("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/titanic.csv")Деректерді R ішіне жүктеу: readr
# install.packages("readr")
library(readr)
# Чтение данных
## readr
ga_nov <- read_tsv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_nowember.csv")
ga_dec <- read_tsv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_december.csv")
titanic <- read_csv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/titanic.csv")Қаптамада vroom, csv / tsv деректер пішіміне қарамастан, жүктеу аттас функция арқылы жүзеге асырылады vroom(), қаптамада readr біз әр пішім үшін басқа функцияны қолданамыз read_tsv() и read_csv().
R ішіне деректерді жүктеу: data.table
В data.table деректерді жүктеу функциясы бар fread().
Деректерді R ішіне жүктеу: data.table бумасы
# install.packages("data.table")
library(data.table)
## data.table
ga_nov <- fread("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_nowember.csv")
ga_dec <- fread("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_december.csv")
titanic <- fread("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/titanic.csv")Python-да деректерді жүктеу: пандалар
Егер біз R бумаларымен салыстырсақ, онда бұл жағдайда синтаксис ең жақын pandas болады readr, t. pandas деректерді кез келген жерден сұрай алады және бұл пакетте функциялардың тұтас тобы бар read_*().
read_csv()read_excel()read_sql()read_json()read_html()
Әртүрлі форматтағы деректерді оқуға арналған көптеген басқа функциялар. Бірақ біздің мақсаттарымыз үшін бұл жеткілікті read_table() немесе read_csv() аргументті қолдану Sep баған бөлгішті көрсету үшін.
Python-да деректерді жүктеу: пандалар
import pandas as pd
ga_nov = pd.read_csv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/russian_text_in_r/ga_nowember.csv", sep = "t")
ga_dec = pd.read_csv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/russian_text_in_r/ga_december.csv", sep = "t")
titanic = pd.read_csv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/russian_text_in_r/titanic.csv")Деректер фреймдерін құру
Кесте Титаник, біз жүктеген, өріс бар жыныс, ол жолаушының гендерлік идентификаторын сақтайды.
Бірақ жолаушы жынысы бойынша деректерді ыңғайлырақ көрсету үшін сіз гендерлік кодты емес, атын пайдалануыңыз керек.
Мұны істеу үшін біз шағын каталогты, сәйкесінше тек 2 баған (код және жыныс атауы) және 2 жол болатын кестені жасаймыз.
R: tidyverse, dplyr-де датафрам жасау
Төмендегі код мысалында функцияның көмегімен қажетті деректер қорын жасаймыз tibble() .
R: dplyr тілінде деректер қорын құру
## dplyr
### создаём справочник
gender <- tibble(id = c(1, 2),
gender = c("female", "male"))R-де деректер қорын құру: data.table
R-де деректер қорын құру: data.table
## data.table
### создаём справочник
gender <- data.table(id = c(1, 2),
gender = c("female", "male"))
Python-да деректер қорын құру: пандалар
В pandas фреймдерді құру бірнеше кезеңде жүзеге асырылады, алдымен сөздікті жасаймыз, содан кейін сөздікті деректер фрейміне түрлендіреміз.
Python-да деректер қорын құру: пандалар
# создаём дата фрейм
gender_dict = {'id': [1, 2],
'gender': ["female", "male"]}
# преобразуем словарь в датафрейм
gender = pd.DataFrame.from_dict(gender_dict)Бағандарды таңдау
Сіз жұмыс істейтін кестелер ондаған, тіпті жүздеген деректер бағандарын қамтуы мүмкін. Бірақ талдау жүргізу үшін, әдетте, бастапқы кестеде бар барлық бағандар қажет емес.
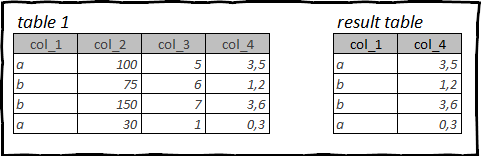
Сондықтан бастапқы кестемен орындалатын алғашқы әрекеттердің бірі оны қажетсіз ақпараттан тазарту және осы ақпарат алатын жадты босату болып табылады.
R ішіндегі бағандарды таңдау: tidyverse, dplyr
синтаксис dplyr SQL сұрау тіліне өте ұқсас, егер сіз онымен таныс болсаңыз, бұл пакетті тез меңгересіз.
Бағандарды таңдау үшін функцияны пайдаланыңыз select().
Төменде бағандарды келесі жолдармен таңдауға болатын код мысалдары берілген:
- Қажетті бағандардың атауларын тізімдеу
- Тұрақты өрнектерді қолданатын баған атауларына сілтеме жасаңыз
- Деректер түрі немесе бағандағы деректердің кез келген басқа қасиеті бойынша
R ішіндегі бағандарды таңдау: dplyr
# Выбор нужных столбцов
## dplyr
### выбрать по названию столбцов
select(ga_nov, date, source, sessions)
### исключь по названию столбцов
select(ga_nov, -medium, -bounces)
### выбрать по регулярному выражению, стобцы имена которых заканчиваются на s
select(ga_nov, matches("s$"))
### выбрать по условию, выбираем только целочисленные столбцы
select_if(ga_nov, is.integer)R ішіндегі бағандарды таңдау: data.table
Дәл осындай операциялар data.table сәл басқаша орындалады, мақаланың басында мен төртбұрышты жақшаның ішінде қандай дәлелдер бар екенін сипаттадым. data.table.
DT[i,j,by]
мұндағы:
i - қайда, яғни. жолдар бойынша сүзу
j - таңдау|жаңарту|до, яғни. бағандарды таңдау және оларды түрлендіру
бойынша - деректерді топтау
R ішіндегі бағандарды таңдау: data.table
## data.table
### выбрать по названию столбцов
ga_nov[ , .(date, source, sessions) ]
### исключь по названию столбцов
ga_nov[ , .SD, .SDcols = ! names(ga_nov) %like% "medium|bounces" ]
### выбрать по регулярному выражению
ga_nov[, .SD, .SDcols = patterns("s$")]Айнымалысы .SD барлық бағандарға қол жеткізуге мүмкіндік береді және .SDcols қажетті бағандарды тұрақты өрнектерді немесе қажет бағандардың атауларын сүзу үшін басқа функцияларды пайдаланып сүзгіден өткізіңіз.
Python, пандалардағы бағандарды таңдау
Бағандарды аты бойынша таңдау үшін pandas олардың аты-жөнінің тізімін беру жеткілікті. Тұрақты өрнектерді пайдаланып бағандарды атау бойынша таңдау немесе алып тастау үшін функцияларды пайдалану керек drop() и filter(), және дәлел ось=1, оның көмегімен жолдарды емес, бағандарды өңдеу қажет екенін көрсетесіз.
Деректер түрі бойынша өрісті таңдау үшін функцияны пайдаланыңыз select_dtypes(), және аргументтерге қамтиды немесе алып тастау таңдау керек өрістерге сәйкес деректер түрлерінің тізімін беріңіз.
Python-да бағандарды таңдау: пандалар
# Выбор полей по названию
ga_nov[['date', 'source', 'sessions']]
# Исключить по названию
ga_nov.drop(['medium', 'bounces'], axis=1)
# Выбрать по регулярному выражению
ga_nov.filter(regex="s$", axis=1)
# Выбрать числовые поля
ga_nov.select_dtypes(include=['number'])
# Выбрать текстовые поля
ga_nov.select_dtypes(include=['object'])Жолдарды сүзу
Мысалы, бастапқы кестеде бірнеше жыл деректер болуы мүмкін, бірақ тек өткен айды талдау қажет. Тағы да қосымша жолдар деректерді өңдеу процесін баяулатады және ДК жадын бітеп тастайды.
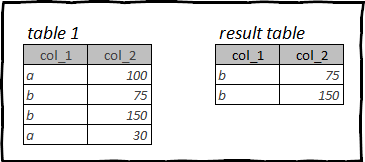
R ішіндегі жолдарды сүзу: tydyverse, dplyr
В dplyr функция жолдарды сүзу үшін пайдаланылады filter(). Ол бірінші аргумент ретінде деректер кадрын алады, содан кейін сүзу шарттарын тізімдейсіз.
Кестені фильтрлеу үшін логикалық өрнектерді жазғанда, бұл жағдайда тырнақшасыз және кесте атын жарияламай баған атауларын көрсетіңіз.
Сүзу үшін бірнеше логикалық өрнектерді пайдаланған кезде келесі операторларды пайдаланыңыз:
- & немесе үтір - логикалық ЖӘНЕ
- | - логикалық НЕМЕСЕ
R ішіндегі жолдарды сүзу: dplyr
# фильтрация строк
## dplyr
### фильтрация строк по одному условию
filter(ga_nov, source == "google")
### фильтр по двум условиям соединённым логическим и
filter(ga_nov, source == "google" & sessions >= 10)
### фильтр по двум условиям соединённым логическим или
filter(ga_nov, source == "google" | sessions >= 10)R ішіндегі жолдарды сүзу: data.table
Жоғарыда жазғанымдай, в data.table деректерді түрлендіру синтаксисі шаршы жақшаға алынған.
DT[i,j,by]
мұндағы:
i - қайда, яғни. жолдар бойынша сүзу
j - таңдау|жаңарту|до, яғни. бағандарды таңдау және оларды түрлендіру
бойынша - деректерді топтау
Аргумент жолдарды сүзу үшін пайдаланылады i, төртбұрышты жақшадағы бірінші орынға ие.
Бағандар логикалық өрнектерде тырнақшасыз және кесте атауын көрсетпей қатынасады.
Логикалық өрнектер бір-бірімен ұқсас байланыста болады dplyr & және | операторлары арқылы.
R ішіндегі жолдарды сүзу: data.table
## data.table
### фильтрация строк по одному условию
ga_nov[source == "google"]
### фильтр по двум условиям соединённым логическим и
ga_nov[source == "google" & sessions >= 10]
### фильтр по двум условиям соединённым логическим или
ga_nov[source == "google" | sessions >= 10]Python-да жолдарды сүзу: пандалар
Жолдар бойынша сүзгілеу pandas сүзгілеуге ұқсас data.table, және шаршы жақшада орындалады.
Бұл жағдайда бағандарға қол жеткізу міндетті түрде деректер кадрының атын көрсету арқылы жүзеге асырылады, содан кейін баған атауы тік жақшадағы тырнақшаларда да көрсетілуі мүмкін (мысал df['col_name']) немесе кезеңнен кейін тырнақшасыз (мысал df.col_name).
Деректер кадрын бірнеше шарттар бойынша сүзгілеу қажет болса, әрбір шарт жақшаға орналастырылуы керек. Логикалық шарттар бір-бірімен операторлар арқылы байланысады & и |.
Python-да жолдарды сүзу: пандалар
# Фильтрация строк таблицы
### фильтрация строк по одному условию
ga_nov[ ga_nov['source'] == "google" ]
### фильтр по двум условиям соединённым логическим и
ga_nov[(ga_nov['source'] == "google") & (ga_nov['sessions'] >= 10)]
### фильтр по двум условиям соединённым логическим или
ga_nov[(ga_nov['source'] == "google") | (ga_nov['sessions'] >= 10)]Мәліметтерді топтастыру және жинақтау
Деректерді талдауда жиі қолданылатын операциялардың бірі топтау және біріктіру болып табылады.
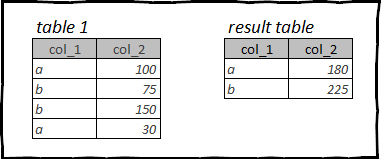
Бұл әрекеттерді орындауға арналған синтаксис біз қарастыратын барлық пакеттерде шашыраңқы.
Бұл жағдайда біз мысал ретінде dataframe аламыз Титаник, және кабина класына байланысты билеттер саны мен орташа құнын есептеңіз.
R: tidyverse, dplyr деректерін топтау және жинақтау
В dplyr функция топтау үшін пайдаланылады group_by(), және жинақтау үшін summarise(). Ақиқатында, dplyr функциялардың тұтас тобы бар summarise_*(), бірақ бұл мақаланың мақсаты негізгі синтаксисті салыстыру, сондықтан біз мұндай джунглиге бармаймыз.
Негізгі біріктіру функциялары:
sum()— қорытындылауmin()/max()– ең төменгі және максималды мәнmean()- орташа арифметикалықmedian()— медианаlength()- саны
R-де топтастыру және жинақтау: dplyr
## dplyr
### группировка и агрегация строк
group_by(titanic, Pclass) %>%
summarise(passangers = length(PassengerId),
avg_price = mean(Fare))Функцияда group_by() біз бірінші аргумент ретінде кестеден өттік Титаник, содан кейін өрісті көрсетті PC класы, ол бойынша үстелімізді топтастырамыз. Оператор көмегімен осы операцияның нәтижесі %>% функцияның бірінші аргументі ретінде берілген summarise(), және тағы 2 өріс қосылды: жолаушылар и орташа_баға. Біріншіден, функцияны пайдалану length() билеттер санын есептеді, ал екіншісінде функцияны пайдаланып mean() билеттің орташа бағасын алды.
R-де мәліметтерді топтау және жинақтау: data.table
В data.table аргумент біріктіру үшін қолданылады j төртбұрышты жақшаның ішінде екінші орны бар және топтастыру үшін by немесе keyby, олар үшінші орынға ие.
Бұл жағдайда біріктіру функцияларының тізімі мақалада сипатталғанмен бірдей dplyr, өйткені бұл негізгі R синтаксисіндегі функциялар.
R-де топтастыру және жинақтау: деректер.кесте
## data.table
### фильтрация строк по одному условию
titanic[, .(passangers = length(PassengerId),
avg_price = mean(Fare)),
by = Pclass]Python-да деректерді топтау және біріктіру: пандалар
Топтастыру pandas ұқсас dplyr, бірақ жинақтау ұқсас емес dplyr ештене етпейді data.table.
Топтау үшін әдісті қолданыңыз groupby(), оған деректер кадры топтастырылатын бағандар тізімін беру керек.
Біріктіру үшін әдісті қолдануға болады agg()ол сөздікті қабылдайды. Сөздік пернелері - біріктіру функциялары қолданылатын бағандар, ал мәндер - біріктіру функцияларының атаулары.
Біріктіру функциялары:
sum()— қорытындылауmin()/max()– ең төменгі және максималды мәнmean()- орташа арифметикалықmedian()— медианаcount()- саны
функция reset_index() төмендегі мысалда кірістірілген индекстерді қалпына келтіру үшін пайдаланылады pandas деректерді біріктіргеннен кейін әдепкі болып табылады.
Таңба келесі жолға өтуге мүмкіндік береді.
Python тілінде топтау және біріктіру: пандалар
# группировка и агрегация данных
titanic.groupby(["Pclass"]).
agg({'PassengerId': 'count', 'Fare': 'mean'}).
reset_index()Кестелерді тік біріктіру
Бір құрылымның екі немесе одан да көп кестелерін біріктіретін операция. Біз жүктеген деректерде кестелер бар ga_nov и ga_dec. Бұл кестелер құрылымы бойынша бірдей, яғни. бірдей бағандар және осы бағандардағы деректер түрлері бар.
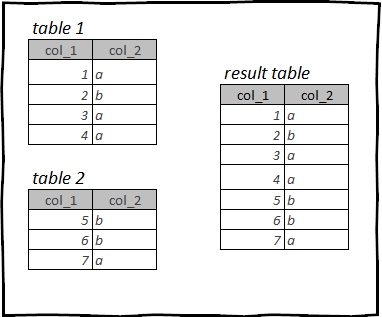
Бұл қараша және желтоқсан айларына арналған Google Analytics жүктеп салуы, осы бөлімде біз бұл деректерді бір кестеге біріктіреміз.
R ішіндегі кестелерді тігінен біріктіру: tidyverse, dplyr
В dplyr Функцияның көмегімен 2 кестені бір кестеге біріктіруге болады bind_rows(), оның аргументтері ретінде кестелерді беру.
R ішіндегі жолдарды сүзу: dplyr
# Вертикальное объединение таблиц
## dplyr
bind_rows(ga_nov, ga_dec)R ішіндегі кестелерді тігінен біріктіру: data.table
Бұл да күрделі емес, қолданайық rbind().
R ішіндегі жолдарды сүзу: data.table
## data.table
rbind(ga_nov, ga_dec)Python-да кестелерді тігінен біріктіру: пандалар
В pandas функция кестелерді біріктіру үшін қолданылады concat(), оған біріктіру үшін кадрлар тізімін беру керек.
Python-да жолдарды сүзу: пандалар
# вертикальное объединение таблиц
pd.concat([ga_nov, ga_dec])Кестелердің көлденең қосылуы
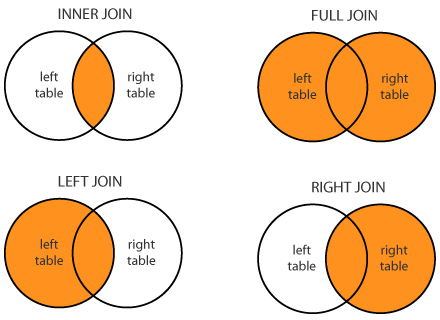
Екіншіден бағандар перне арқылы бірінші кестеге қосылатын операция. Ол көбінесе фактілер кестесін (мысалы, сату деректері бар кесте) кейбір анықтамалық деректермен (мысалы, өнімнің өзіндік құны) байытқанда қолданылады.
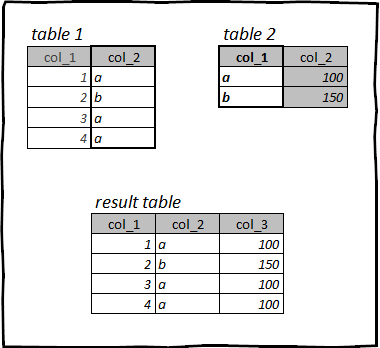
Біріктірудің бірнеше түрі бар:
Бұрын жүктелген кестеде Титаник бағанамыз бар жыныс, ол жолаушының гендерлік кодына сәйкес келеді:
1 - әйел
2 - еркек
Сонымен қатар біз кесте – анықтамалық жасадық жыныс. Жолаушылардың жынысы туралы деректерді ыңғайлырақ көрсету үшін анықтамалықтан жыныстың атын қосу керек. жыныс үстелге Титаник.
Көлденең кестені R ішінде біріктіру: tidyverse, dplyr
В dplyr Көлденең қосылуға арналған функциялардың тұтас тобы бар:
inner_join()left_join()right_join()full_join()semi_join()nest_join()anti_join()
Менің тәжірибемде ең жиі қолданылатыны left_join().
Алғашқы екі аргумент ретінде жоғарыда аталған функциялар қосылу үшін екі кестені, ал үшінші аргумент ретінде by қосылу үшін бағандарды көрсету керек.
Көлденең кестені R ішінде біріктіру: dplyr
# объединяем таблицы
left_join(titanic, gender,
by = c("Sex" = "id"))R ішіндегі кестелердің көлденең қосылуы: data.table
В data.table Функцияның көмегімен кестелерді перне арқылы біріктіру керек merge().
data.table ішіндегі біріктіру() функциясына арналған аргументтер
- x, y — Біріктіруге арналған кестелер
- by — Екі кестеде де аты бірдей болса, қосылу кілті болып табылатын баған
- by.x, by.y — Кестелерде әртүрлі атаулар болса, біріктірілетін баған атаулары
- all, all.x, all.y — Біріктіру түрі, барлығы екі кестедегі барлық жолдарды қайтарады, all.x LEFT JOIN операциясына сәйкес келеді (бірінші кестенің барлық жолдарын қалдырады), all.y — сәйкес келеді RIGHT JOIN операциясы (екінші кестенің барлық жолдарын қалдырады).
R ішіндегі кестелердің көлденең қосылуы: data.table
# объединяем таблицы
merge(titanic, gender, by.x = "Sex", by.y = "id", all.x = T)Python-да көлденең кестені біріктіру: пандалар
Сондай-ақ ішінде data.table, in pandas функция кестелерді біріктіру үшін қолданылады merge().
Pandas ішіндегі merge() функциясының аргументтері
- қалай — Қосылу түрі: сол, оң, сыртқы, ішкі
- on — Екі кестеде де аты бірдей болса, кілт болып табылатын баған
- left_on, right_on — Кестелерде әртүрлі атаулар болса, негізгі бағандардың атаулары
Python-да көлденең кестені біріктіру: пандалар
# объединяем по ключу
titanic.merge(gender, how = "left", left_on = "Sex", right_on = "id")Терезенің негізгі функциялары және есептелген бағандар
Терезе функциялары жинақтау функцияларына мағынасы жағынан ұқсас, сонымен қатар деректерді талдауда жиі қолданылады. Бірақ біріктіру функцияларынан айырмашылығы, терезе функциялары шығыс деректер кадрының жолдар санын өзгертпейді.
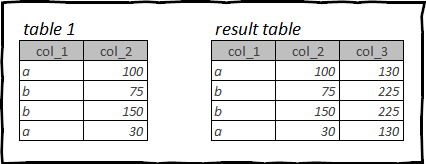
Негізінде, терезе функциясын пайдалана отырып, біз кіріс деректер кадрын кейбір критерийге сәйкес бөліктерге бөлеміз, яғни. өрістің немесе бірнеше өрістің мәні бойынша. Ал біз әр терезеге арифметикалық амалдар орындаймыз. Бұл әрекеттердің нәтижесі әрбір жолда қайтарылады, яғни. кестедегі жолдардың жалпы санын өзгертпей.
Мысалы, кестені алайық Титаник. Біз әрбір билеттің құны оның кабина класында қанша пайыз болғанын есептей аламыз.
Ол үшін әрбір жолға осы жолдағы билет жататын ағымдағы кабина класы үшін билеттің жалпы құнын алуымыз керек, содан кейін әрбір билеттің құнын сол кабина класындағы барлық билеттердің жалпы құнына бөлу керек. .
R тіліндегі терезе функциялары: tidyverse, dplyr
Жолдарды топтастыруды қолданбай, жаңа бағандарды қосу үшін dplyr функциясын атқарады mutate().
Деректерді өріс бойынша топтастыру арқылы жоғарыда сипатталған мәселені шешуге болады PC класы және өрісті жаңа бағанға қосу жолақы. Содан кейін кестенің тобын ашыңыз және өріс мәндерін бөліңіз жолақы алдыңғы қадамда болған оқиғаға.
R тіліндегі терезе функциялары: dplyr
group_by(titanic, Pclass) %>%
mutate(Pclass_cost = sum(Fare)) %>%
ungroup() %>%
mutate(ticket_fare_rate = Fare / Pclass_cost)R тіліндегі терезе функциялары: data.table
Шешім алгоритмі бұрынғыдай қалады dplyr, біз кестені өрістер бойынша терезелерге бөлуіміз керек PC класы. Жаңа бағанға әр жолға сәйкес топтың сомасын шығарыңыз және оның тобындағы әрбір билет құнының үлесін есептейтін бағанды қосыңыз.
Жаңа бағандарды қосу үшін data.table оператор бар :=. Төменде пакетті пайдаланып мәселені шешудің мысалы келтірілген data.table
R тіліндегі терезе функциялары: data.table
titanic[,c("Pclass_cost","ticket_fare_rate") := .(sum(Fare), Fare / Pclass_cost),
by = Pclass]Python тіліндегі терезе функциялары: пандалар
Жаңа баған қосудың бір жолы pandas - функцияны пайдаланыңыз assign(). Жолдарды топтамай, кабина класы бойынша билеттер құнын қорытындылау үшін біз функцияны қолданамыз transform().
Төменде кестеге қосатын шешімнің мысалы келтірілген Титаник бірдей 2 баған.
Python тіліндегі терезе функциялары: пандалар
titanic.assign(Pclass_cost = titanic.groupby('Pclass').Fare.transform(sum),
ticket_fare_rate = lambda x: x['Fare'] / x['Pclass_cost'])Функциялар мен әдістердің сәйкестік кестесі
Төменде біз қарастырған пакеттердегі деректермен әртүрлі операцияларды орындау әдістері арасындағы сәйкестік кестесі берілген.
сипаттамасы
ұқыптылық
деректер кестесі
панда
Деректер жүктелуде
vroom()/ readr::read_csv() / readr::read_tsv()
fread()
read_csv()
Деректер фреймдерін құру
tibble()
data.table()
dict() + from_dict()
Бағандарды таңдау
select()
дәлел j, тік жақшадағы екінші орын
біз тік жақшаға қажетті бағандар тізімін береміз / drop() / filter() / select_dtypes()
Жолдарды сүзу
filter()
дәлел i, төртбұрышты жақшадағы бірінші орын
Сүзу шарттарын тік жақшаға аламыз / filter()
Топтастыру және біріктіру
group_by() + summarise()
дәлелдер j + by
groupby() + agg()
Кестелердің тік бірлестігі (UNION)
bind_rows()
rbind()
concat()
Кестелерді көлденең біріктіру (JOIN)
left_join() / *_join()
merge()
merge()
Терезенің негізгі функциялары және есептелген бағандарды қосу
group_by() + mutate()
дәлел j операторды пайдалану := + аргумент by
transform() + assign()
қорытынды
Мүмкін, мақалада мен деректерді өңдеудің ең оңтайлы іске асырылуын сипаттамаған шығармын, сондықтан түсініктемелердегі қателерімді түзетсеңіз немесе мақалада берілген ақпаратты R / Python деректерімен жұмыс істеудің басқа әдістерімен толықтырсаңыз, мен қуаныштымын.
Жоғарыда жазғанымдай, мақаланың мақсаты қай тіл жақсы деген пікірді таңу емес, екі тілді де үйрену мүмкіндігін жеңілдету немесе қажет болған жағдайда олардың арасында көшіп-қону болды.
Егер сізге мақала ұнаса, мен өзімнің жаңа жазылушыларымның болғанына қуаныштымын и арналар.
сұхбат
Жұмысыңызда төмендегі пакеттердің қайсысын қолданасыз?
Түсініктемелерде таңдауыңыздың себебін жаза аласыз.
Сауалнамаға тек тіркелген пайдаланушылар қатыса алады. , өтінемін.
Сіз қандай деректерді өңдеу пакетін пайдаланасыз (бірнеше опцияны таңдауға болады)
-
45,2%ұқыптылық19
-
33,3%деректер.кесте14
-
54,8%23
42 қолданушы дауыс берді. 9 пайдаланушы қалыс қалды.
Ақпарат көзі: www.habr.com
