

Менің атым Виктор Ягофаров, мен DomClick-те Ops (операция) тобындағы техникалық даму менеджері ретінде Kubernetes платформасын әзірлеп жатырмын. Мен Dev <-> Ops процестеріміздің құрылымы, Ресейдегі ең үлкен k8s кластерлерінің бірінің жұмыс істеу ерекшеліктері, сондай-ақ біздің команда қолданатын DevOps/SRE тәжірибелері туралы айтқым келеді.

Операциялық команда
Операциялық командада қазір 15 адам бар. Олардың үшеуі кеңсеге жауапты, екеуі басқа уақыт белдеуінде жұмыс істейді және түнде де қол жетімді. Осылайша, Ops-тен біреу әрқашан мониторда болады және кез келген күрделі оқиғаға жауап беруге дайын. Бізде түнгі ауысым жоқ, ол біздің психикамызды сақтайды және барлығына жеткілікті ұйықтауға және компьютерде ғана емес бос уақытты өткізуге мүмкіндік береді.
Әркімнің әр түрлі құзыреттері бар: желілік мамандар, DBA, ELK стек мамандары, Kubernetes әкімшілері/әзірлеушілері, мониторинг, виртуализация, аппараттық құралдар мамандары және т.б. Барлығын біріктіретін бір нәрсе – әркім бізді қандай да бір дәрежеде алмастыра алады: мысалы, k8s кластеріне жаңа түйіндерді енгізу, PostgreSQL жаңарту, CI/CD + Ansible құбырын жазу, Python/Bash/Go-да бір нәрсені автоматтандыру, аппараттық құралдарды қосу Деректер орталығы. Кез келген саладағы күшті құзыреттер сіздің қызмет бағытыңызды өзгертуге және басқа салада жақсара бастауға кедергі болмайды. Мысалы, мен компанияға PostgreSQL маманы ретінде қосылдым, енді менің басты жауапкершілігім саласы - Kubernetes кластерлері. Командада кез келген биіктік құпталады және левередж сезімі өте дамыған.
Айтпақшы, біз үміткерлерді іздейміз. Үміткерлерге қойылатын талаптар өте стандартты. Жеке өзім үшін адамның командаға бейімделуі, қақтығыспауы, сонымен қатар өз көзқарасын қорғай алуы, дамуға дайын болуы және жаңа нәрсені сынап көруден қорықпауы және өз идеяларын ұсынуға дайын болуы маңызды. Сондай-ақ, сценарий тілдерінде бағдарламалау дағдылары және негіздерін білу қажет. Linux және ағылшын тілі. Ағылшын тілі жай ғана қажет, егер адам қателессе, мәселенің шешімін 10 минутта емес, 10 секундта Google-дан іздей алады. Терең білімді мамандармен Linux Қазір бұл өте қиын: күлкілі, бірақ үш үміткердің екеуі «Жүктеме орташасы дегеніміз не? Ол неден тұрады?» деген сұраққа жауап бере алмайды, ал «С бағдарламасынан негізгі дампты қалай жасауға болады» деген сұрақ суперадамдарға... немесе динозаврларға арналған нәрсе болып саналады. Біз мұны көтеруіміз керек, өйткені адамдарда әдетте басқа да құзыреттер жоғары дамыған, және біз оларға Linux үйретеміз. «Неліктен DevOps инженері қазіргі бұлт әлемінде мұның бәрін білуі керек» деген сұраққа жауап осы мақаланың шеңберінен тыс қалуы керек, бірақ қысқасы: мұның бәрі қажет.
Команда құралдары
Құралдар тобы автоматтандыруда маңызды рөл атқарады. Олардың негізгі міндеті – әзірлеушілерге ыңғайлы графикалық және CLI құралдарын жасау. Мысалы, біздің ішкі даму конференциясы тінтуірді бірнеше рет басу арқылы қосымшаны Kubernetes-ке шығаруға, оның ресурстарын, қоймадағы кілттерді және т.б. конфигурациялауға мүмкіндік береді. Бұрын Jenkins + Helm 2 болды, бірақ мен көшіру-қоюды жою және бағдарламалық жасақтаманың өмірлік цикліне біркелкі ету үшін өз құралымды әзірлеуге тура келді.
Ops командасы әзірлеушілер үшін құбырларды жазбайды, бірақ олардың жазбаларында кез келген мәселелер бойынша кеңес бере алады (кейбір адамдар әлі де Helm 3-ке ие).
DevOps
DevOps болсақ, біз оны келесідей көреміз:
Әзірлеуші топтар кодты жазады, оны Confer to dev -> qa/stage -> prod арқылы шығарады. Кодтың баяулауын және қателерді қамтымауын қамтамасыз ету үшін жауапкершілік Dev және Ops топтарына жүктеледі. Күндізгі уақытта Операциялық команданың кезекшісі, ең алдымен, оқиғаға өз өтінішімен жауап беруі керек, ал кешке және түнде кезекші әкімші (Ops) егер ол білсе, кезекші әзірлеушіні оятуы керек. мәселе инфрақұрылымда емес екеніне көз жеткізіңіз. Бақылаудағы барлық көрсеткіштер мен ескертулер автоматты немесе жартылай автоматты түрде пайда болады.
Ops жауапкершілік аймағы қолданба өндіріске енгізілген сәттен басталады, бірақ Dev жауапкершілігі мұнымен аяқталмайды - біз бірдей нәрсені жасаймыз және бір қайықтамыз.
Әзірлеушілер әкімшілерге әкімші микросервисін жазуда көмек қажет болса (мысалы, Go backend + HTML5) кеңес береді және әкімшілер әзірлеушілерге кез келген инфрақұрылым мәселелері немесе k8s қатысты мәселелер бойынша кеңес береді.
Айтпақшы, бізде монолит мүлде жоқ, тек микросервистер бар. Олардың саны әзірге k900s өнім кластерінде 1000-ден 8-ға дейін ауытқиды, егер санмен өлшенсе орналастыру. Бұршақтардың саны 1700 мен 2000 арасында ауытқиды. Қазіргі уақытта өнім кластерінде шамамен 2000 түйіршіктер бар.
Мен нақты сандарды айта алмаймын, өйткені біз қажет емес микросервистерді бақылап, оларды жартылай автоматты түрде кесіп тастаймыз. K8s бізге қажет емес нысандарды қадағалауға көмектеседі , бұл көптеген ресурстар мен ақшаны үнемдейді.
Ресурстарды басқару
Бақылау
Жақсы құрылымдалған және ақпараттандырылған мониторинг үлкен кластердің жұмысының негізіне айналады. Біз барлық бақылау қажеттіліктерінің 100% жабатын әмбебап шешімді әлі таппадық, сондықтан біз осы ортада мезгіл-мезгіл әртүрлі пайдаланушы шешімдерін жасаймыз.
- Zabbix. Жақсы ескі мониторинг, ол негізінен инфрақұрылымның жалпы жағдайын бақылауға арналған. Ол өңдеу, жад, дискілер, желі және т.б. тұрғысынан түйіннің қашан өлетінін айтады. Табиғаттан тыс ештеңе жоқ, бірақ бізде агенттердің бөлек DaemonSet бар, оның көмегімен біз, мысалы, кластердегі DNS күйін бақылаймыз: біз ақымақ coredns подкасттарын іздейміз, сыртқы хосттардың болуын тексереміз. Мұнымен неліктен алаңдау керек сияқты, бірақ трафиктің үлкен көлемімен бұл компонент елеулі сәтсіздікке ұшырайды. қазірдің өзінде Мен , кластердегі DNS өнімділігімен қалай күрескенім.
- Прометей операторы. Әртүрлі экспорттаушылардың жиынтығы кластердің барлық құрамдас бөліктеріне үлкен шолу жасайды. Содан кейін біз мұның бәрін Grafana-дағы үлкен бақылау тақталарында көреміз және ескертулер үшін alertmanager пайдаланамыз.
Біз үшін тағы бір пайдалы құрал болды . Біз оны бірнеше рет бір команда басқа команданың кіру жолдарымен қабаттасатын жағдайға тап болғаннан кейін жаздық, нәтижесінде 50x қате. Енді өндіріске енгізбес бұрын әзірлеушілер ешкімге әсер етпейтінін тексереді және менің командам үшін бұл Ingresses проблемаларын бастапқы диагностикалау үшін жақсы құрал. Бір қызығы, ол алдымен әкімшілер үшін жазылған және ол біршама «ебедейсіз» болып көрінді, бірақ әзірлеушілер бұл құралға ғашық болғаннан кейін, ол қатты өзгерді және «әкімші әкімшілерге веб-бет жасады» сияқты көрінбейді. » Жақында біз бұл құралдан бас тартамыз және мұндай жағдайлар құбыр шығарылғанға дейін де расталады.
Текшедегі топ ресурстары
Мысалдарға кіріспес бұрын, ресурстарды қалай бөлетінімізді түсінген жөн микросервис.
Қандай командаларды және қандай мөлшерде пайдаланатынын түсіну ресурстар (процессор, жад, жергілікті SSD), біз әрбір пәрменді өзімізге бөлеміз атаулар кеңістігі «Текшеде» және оның процессор, жад және диск тұрғысынан максималды мүмкіндіктерін шектеңіз, бұрын командалардың қажеттіліктерін талқылады. Тиісінше, бір пәрмен, жалпы алғанда, мыңдаған ядролар мен терабайт жадтарды бөле отырып, орналастыру үшін бүкіл кластерді блоктамайды. Атау кеңістігіне қол жеткізу AD арқылы беріледі (біз RBAC қолданамыз). Атау кеңістігі және олардың шектеулері GIT репозиторийіне тарту сұрауы арқылы қосылады, содан кейін барлығы автоматты түрде Ansible конвейері арқылы шығарылады.
Топқа ресурстарды бөлу мысалы:
namespaces:
chat-team:
pods: 23
limits:
cpu: 11
memory: 20Gi
requests:
cpu: 11
memory: 20Gi
Сұраныстар мен шектеулер
текше» өтініш үшін кепілдік берілген резервтік ресурстардың саны под кластердегі (бір немесе бірнеше докер контейнерлері). Лимит – кепілдік берілмеген максимум. Кейбір топтың өзінің барлық қолданбалары үшін тым көп сұрауларды қалай орнатқанын және қолданбаны «Текшеге» орналастыра алмайтынын графиктерден жиі көруге болады, өйткені олардың атау кеңістігіндегі барлық сұраулар әлдеқашан «жұмсалған».
Бұл жағдайдан шығудың дұрыс жолы - нақты ресурстарды тұтынуды қарап, оны сұралған сомамен салыстыру (Сұраныс).
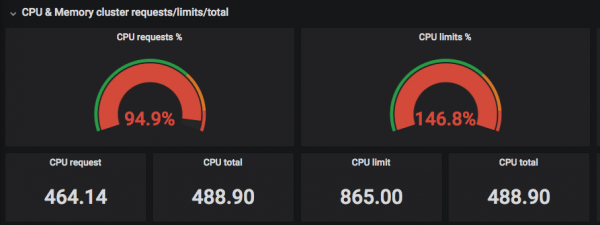
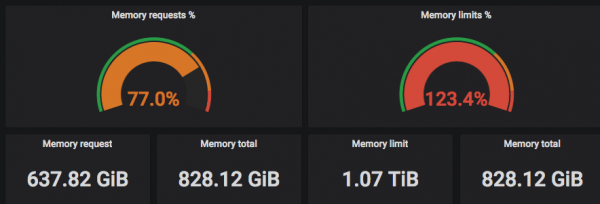
Жоғарыдағы скриншоттарда сіз «Сұралған» процессорлар ағындардың нақты санына сәйкес келетінін көре аласыз, ал шектеулер CPU ағындарының нақты санынан асып кетуі мүмкін =)
Енді кейбір аттар кеңістігін егжей-тегжейлі қарастырайық (мен аттар кеңістігі kube жүйесін таңдадым - «Cube» компоненттерінің жүйелік аттар кеңістігі) және нақты пайдаланылған процессор уақыты мен жадының сұралғанға қатынасын көрейік:
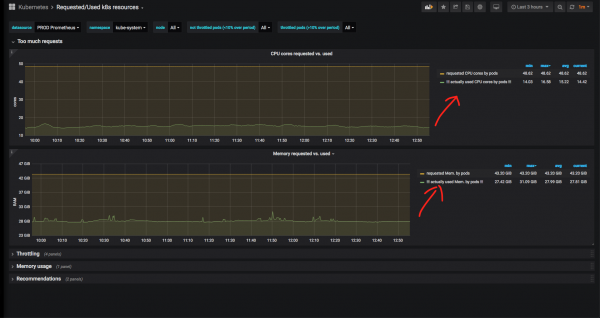
Жүйе қызметтері үшін нақты пайдаланылғаннан әлдеқайда көп жад пен процессор сақталғаны анық. Kube-жүйесінің жағдайында бұл ақталады: nginx кіру контроллері немесе nodelocaldns шыңында процессорға соғылып, көп жедел жадты тұтынғаны болды, сондықтан мұнда мұндай резерв ақталған. Бұған қоса, біз соңғы 3 сағаттағы диаграммаларға сене алмаймыз: тарихи көрсеткіштерді үлкен уақыт кезеңі ішінде көрген жөн.
«ұсынымдар» жүйесі әзірленді. Мысалы, мұнда сіз «шектеу» орын алмас үшін «шектерді» (жоғарғы рұқсат етілген жолақты) көтерудің қай ресурстардың жақсырақ болатынын көре аласыз: ресурс бөлінген уақыт бөлігінде процессорды немесе жадты жұмсаған сәт және ол «мұздатылған» болғанша күтеді:
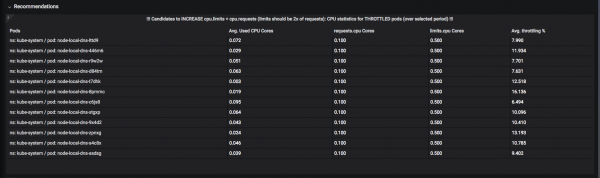
Міне, олардың тәбетін тежейтін бұршақтар:
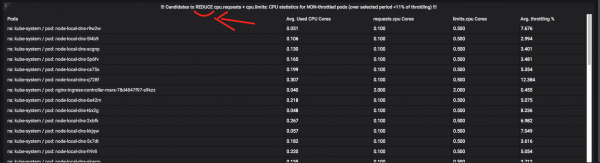
туралы дроссельдеу + ресурстарды бақылау, сіз бірнеше мақала жаза аласыз, сондықтан түсініктемелерде сұрақтар қойыңыз. Бір сөзбен айтқанда, мұндай көрсеткіштерді автоматтандыру міндеті өте қиын және көп уақытты қажет етеді және «терезе» функцияларымен және «CTE» Prometheus / VictoriaMetrics (бұл терминдер тырнақшаға алынған, өйткені бар дерлік PromQL-де мұндай ештеңе жоқ және сіз қорқынышты сұрауларды мәтіннің бірнеше экрандарына бөліп, оларды оңтайландыруыңыз керек).
Нәтижесінде, әзірлеушілер Cube ішіндегі атау кеңістігін бақылауға арналған құралдарға ие және олар қай қолданбалардың ресурстарын қай жерде және қай уақытта «қиюға» болатынын және қай серверлерге бүкіл процессорды түні бойы беруге болатынын өздері таңдай алады.
Әдістемелер
Компанияда қазіргідей сәнді, біз DevOps ұстанамыз- және SRE-практик Компанияда 1000 микросервис, 350-ге жуық әзірлеуші және бүкіл инфрақұрылым үшін 15 әкімші болса, сіз «сәнді» болуыңыз керек: осы «баспасөздердің» артында барлығын және барлығын автоматтандырудың шұғыл қажеттілігі бар, ал әкімшілер кедергі болмауы керек. процестерде.
Ops ретінде біз әзірлеушілерге қызметтің жауап беру жылдамдығы мен қателеріне қатысты әртүрлі көрсеткіштер мен бақылау тақталарын береміз.
Біз әдістемелерді қолданамыз, мысалы: , и оларды біріктіру арқылы. Біз бақылау тақталарының санын азайтуға тырысамыз, осылайша бір қарағанда қандай қызмет қазіргі уақытта нашарлап жатқаны анық болады (мысалы, секундына жауап кодтары, 99-процентильге жауап беру уақыты) және т.б. Кейбір жаңа көрсеткіштер жалпы бақылау тақталары үшін қажет болған кезде, біз оларды дереу сызып, қосамыз.
Мен бір ай бойы график салмадым. Бұл жақсы белгі шығар: бұл «қалаулардың» көпшілігі орындалғанын білдіреді. Аптаның ішінде мен күніне кем дегенде бір рет жаңа график сызатын болдым.
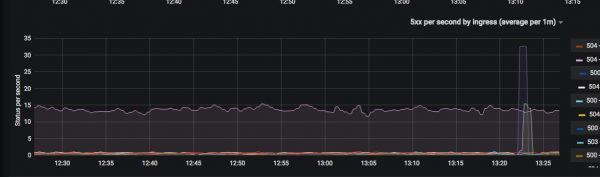
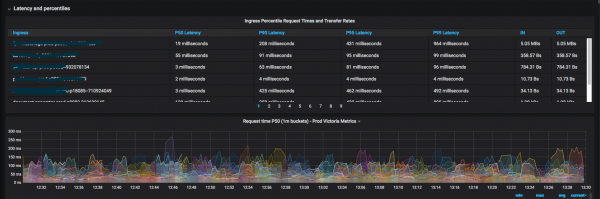
Нәтиже құнды, өйткені қазір әзірлеушілер әкімшілерге «метриканың қандай да бір түрін қайдан қарау керек» деген сұрақтармен сирек барады.
Кіріспе Қызмет торы Бұл жақын жерде және барлығының өмірін жеңілдетуі керек, Құралдардағы әріптестер «Дені сау адам туралы» рефератты енгізуге жақын: әрбір HTTP(лар) сұрауының өмірлік циклі мониторингте көрінеді және ол Қызметаралық (тек қана емес) өзара әрекеттесу кезінде «бәрі қай кезеңде бұзылғанын» түсіну әрқашан мүмкін болады. DomClick хабынан жаңалықтарға жазылыңыз. =)
Kubernetes инфрақұрылымын қолдау
Тарихи түрде біз патчталған нұсқасын қолданамыз Кубеспрай — Kubernetes-ті орналастыру, кеңейту және жаңарту үшін жауапты рөл. Бір сәтте kubeadm емес қондырғыларға қолдау негізгі тармақтан кесілді және kubeadm-ге ауысу процесі ұсынылмады. Нәтижесінде Southbridge компаниясы өзінің шанышқысын жасады (kubeadm қолдауымен және маңызды мәселелерді жылдам шешумен).
Барлық k8s кластерлерін жаңарту процесі келесідей:
- Біз аламыз Кубеспрай Саутбриджден, біздің жіппен тексеріңіз, Мержим.
- Біз жаңартуды шығарамыз стресс- «Кубик».
- Біз жаңартуды бір уақытта бір түйін шығарамыз (Ansible-де бұл «сериялық: 1») ішінде Dev- «Кубик».
- Жаңартамыз Prod сенбі күні кешке бір-бір түйін.
Алдағы уақытта ауыстыру жоспарда бар Кубеспрай жылдамырақ нәрсе үшін және барыңыз kubeadm.
Барлығы бізде үш «текше» бар: стресс, дев және өнім. Біз тағы біреуін шығаруды жоспарлап отырмыз (ыстық күту режимі) Екінші деректер орталығында өнім-“Cube”. стресс и Dev «виртуалды машиналарда» (oVirt for Stress және Dev for VMWare бұлты) өмір сүріңіз. Prod- «Куб» «жалаң металлда» өмір сүреді: бұл 32 CPU ағыны, 64-128 ГБ жады және 300 ГБ SSD RAID 10 бар бірдей түйіндер - олардың барлығы 50 бар. Үш «жұқа» түйін «шеберлерге» арналған Prod- «Куба»: 16 ГБ жад, 12 процессор ағындары.
Сату үшін біз «жалаң металлды» қолданып, қажетсіз қабаттардан аулақ болғанды жөн көреміз OpenStack: бізге «шулы көршілер» және процессор қажет емес уақытты ұрлау. Ал басқарудың күрделілігі ішкі OpenStack жағдайында шамамен екі есе артады.
CI/CD «Cubic» және басқа инфрақұрылым компоненттері үшін біз Helm 3 жеке GIT серверін қолданамыз (бұл Helm 2-ден өте ауыр көшу болды, бірақ біз опцияларға өте қуаныштымыз. атомдық), Дженкинс, Ансибл және Докер. Біз мүмкіндік тармақтарын және бір репозиторийден әртүрлі орталарға орналастыруды жақсы көреміз.
қорытынды

Бұл, жалпы алғанда, DevOps процесі DomClick-те операциялық инженердің көзқарасы бойынша қалай көрінеді. Мақала мен күткеннен аз техникалық болды: сондықтан Хабредегі DomClick жаңалықтарын қадағалаңыз: Кубернетес туралы көбірек «хардкор» мақалалар болады және т.б.
Ақпарат көзі: www.habr.com
