


Осы көктемде біз кейбір кіріспе тақырыптарды талқыладық, мысалы, и . Олардың екіншісінде біз ZFS-те әртүрлі көп дискілік топологиялардың өнімділігін зерттеуді жалғастыруға уәде бердік. Бұл қазір барлық жерде енгізілетін келесі буын файлдық жүйесі: from қарай .
Міне, бүгін ZFS, ізденімпаз оқырмандармен танысудың ең жақсы күні. OpenZFS әзірлеушісі Мэтт Аренстің қарапайым пікірі бойынша, «бұл шынымен қиын» екенін біліңіз.
Бірақ біз сандарға келмес бұрын - және олар болады, мен уәде беремін - сегіз дискілік ZFS конфигурациясының барлық нұсқалары туралы сөйлесуіміз керек. қалай Жалпы ZFS деректерді дискіде сақтайды.
Zpool, vdev және құрылғы
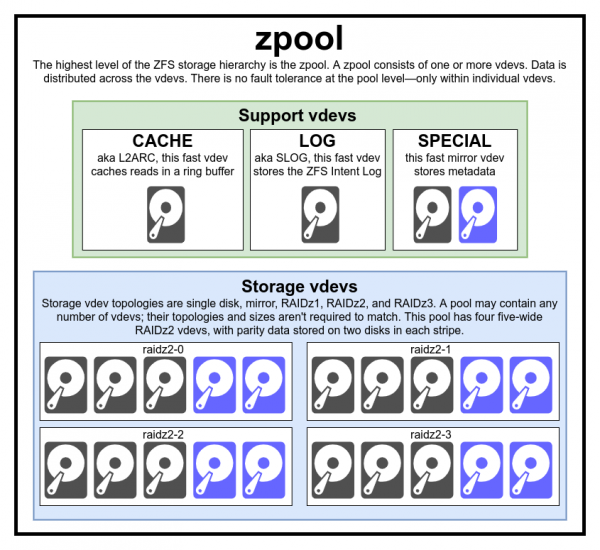
Бұл толық пул диаграммасы үш көмекші vdev, әр сыныптың біреуі және RAIDz2 үшін төртеуін қамтиды.

Әдетте сәйкес келмейтін vdev түрлері мен өлшемдерінің пулын жасауға ешқандай себеп жоқ - бірақ қаласаңыз, мұны істеуге ештеңе кедергі болмайды.
ZFS файлдық жүйесін шынымен түсіну үшін оның нақты құрылымын мұқият қарау керек. Біріншіден, ZFS дыбыс деңгейін және файлдық жүйені басқарудың дәстүрлі деңгейлерін біріктіреді. Екіншіден, ол транзакциялық көшіру-жазба механизмін пайдаланады. Бұл мүмкіндіктер жүйенің әдеттегі файлдық жүйелер мен RAID массивтерінен құрылымдық жағынан айтарлықтай ерекшеленетінін білдіреді. Түсінуге болатын негізгі құрылыс блоктарының бірінші жинағы - сақтау пулы (zpool), виртуалды құрылғы (vdev) және нақты құрылғы (құрылғы).
zpool
Zpool сақтау пулы ZFS ең жоғарғы құрылымы болып табылады. Әрбір бассейнде бір немесе бірнеше виртуалды құрылғылар бар. Өз кезегінде олардың әрқайсысында бір немесе бірнеше нақты құрылғылар (құрылғы) бар. Виртуалды бассейндер дербес блоктар болып табылады. Бір физикалық компьютерде екі немесе одан да көп жеке пулдар болуы мүмкін, бірақ олардың әрқайсысы басқалардан толығымен тәуелсіз. Бассейндер виртуалды құрылғыларды ортақ пайдалана алмайды.
ZFS артықшылығы пул деңгейінде емес, виртуалды құрылғы деңгейінде. Пул деңгейінде артықшылық мүлдем жоқ - егер кез келген диск vdev немесе арнайы vdev жоғалса, онда онымен бірге бүкіл пул жоғалады.
Заманауи сақтау пулдары кэш немесе виртуалды құрылғы журналының жоғалуынан аман қалуы мүмкін - бірақ олар электр қуатының үзілуі немесе жүйенің бұзылуы кезінде vdev журналын жоғалтса, лас деректердің аз мөлшерін жоғалтуы мүмкін.
ZFS «деректер жолақтары» бүкіл бассейнде жазылған деген қате түсінік бар. Бұл дұрыс емес болып табылады. Zpool мүлдем күлкілі RAID0 емес, бұл өте күлкілі күрделі айнымалы тарату механизмімен.
Көбінесе жазбалар қол жетімді виртуалды құрылғылар арасында қол жетімді бос кеңістікке сәйкес бөлінеді, сондықтан теорияда олардың барлығы бір уақытта толтырылады. ZFS-тің кейінгі нұсқаларында ағымдағы vdev пайдалану (пайдалану) ескеріледі - егер бір виртуалды құрылғы екіншісіне қарағанда айтарлықтай бос болса (мысалы, оқу жүктемесіне байланысты), ол ең жоғары тегінге қарамастан, уақытша жазуға жіберіледі. кеңістік қатынасы.
Заманауи ZFS жазуды бөлу әдістеріне кіріктірілген пайдалануды анықтау механизмі әдеттен тыс жоғары жүктеме кезеңдерінде кідірістерді азайтып, өткізу қабілеттілігін арттырады, бірақ олай емес. карт-бланш бір пулда баяу HDD және жылдам SSD дискілерін еріксіз араластыру туралы. Мұндай тең емес пул әлі де ең баяу құрылғының жылдамдығымен жұмыс істейді, яғни ол толығымен осындай құрылғылардан тұратын сияқты.
vdev
Әрбір сақтау пулы бір немесе бірнеше виртуалды құрылғылардан тұрады (виртуалды құрылғы, vdev). Өз кезегінде әрбір vdev бір немесе бірнеше нақты құрылғыларды қамтиды. Виртуалды құрылғылардың көпшілігі қарапайым деректерді сақтау үшін пайдаланылады, бірақ CACHE, LOG және SPECIAL сияқты бірнеше vdev көмекші сыныптары бар. Осы vdev түрлерінің әрқайсысында бес топологияның біреуі болуы мүмкін: жалғыз құрылғы (бір құрылғы), RAIDz1, RAIDz2, RAIDz3 немесе айна (айна).
RAIDz1, RAIDz2 және RAIDz3 - ескі таймерлер қос (диагональды) RAID паритеті деп атайтын ерекше сорттар. 1, 2 және 3 әр деректер жолағы үшін қанша паритет блоктары бөлінгенін көрсетеді. Паритет үшін бөлек дискілердің орнына RAIDz виртуалды құрылғылары бұл паритетті дискілер арасында жартылай біркелкі таратады. RAIDz массивінде паритет блоктары болса, сонша дискілер жоғалуы мүмкін; егер ол басқасын жоғалтса, ол бұзылып, сақтау пулын өзімен бірге алып кетеді.
Айналанған виртуалды құрылғыларда (айна vdev) әрбір блок vdev ішіндегі әрбір құрылғыда сақталады. Екі кең айналар ең көп таралған болса да, айнада кез келген ерікті сандық құрылғылар болуы мүмкін - үш есе жиі оқу өнімділігін жақсарту және ақауларға төзімділік үшін үлкен қондырғыларда қолданылады. vdev айнасы vdev ішіндегі кем дегенде бір құрылғы жұмысын жалғастырғанша, кез келген сәтсіздікке төтеп бере алады.
Жалғыз vdev-тер қауіпті. Мұндай виртуалды құрылғы бір сәтсіздіктен аман қалмайды - егер сақтау немесе арнайы vdev ретінде пайдаланылса, онда оның істен шығуы бүкіл бассейннің бұзылуына әкеледі. Мұнда өте сақ болыңыз.
Кэш, журнал және АРНАЙЫ VA жоғарыда аталған топологиялардың кез келгенін пайдаланып жасалуы мүмкін - бірақ АРНАЙЫ VA жоғалуы пулдың жоғалуын білдіретінін есте сақтаңыз, сондықтан артық топология өте ұсынылады.
құрал
Бұл ZFS-те түсінудің ең оңай термині болуы мүмкін - бұл кездейсоқ қол жеткізу құрылғысы. Виртуалды құрылғылар жеке құрылғылардан, ал пул виртуалды құрылғылардан тұратынын есте сақтаңыз.
Дискілер - магниттік немесе қатты күй - vdev-тің құрылыс блоктары ретінде пайдаланылатын ең көп таралған блоктық құрылғылар. Дегенмен, /dev ішінде дескрипторы бар кез келген құрылғы орындалады, сондықтан бүкіл аппараттық RAID массивтері бөлек құрылғылар ретінде пайдаланылуы мүмкін.
Қарапайым шикі файл - vdev құрастыруға болатын ең маңызды альтернативті блок құрылғыларының бірі. Тест пулдарын бастап пул пәрмендерін тексерудің және берілген топологияның пулында немесе виртуалды құрылғысында қаншалықты бос орын бар екенін көрудің өте ыңғайлы тәсілі.
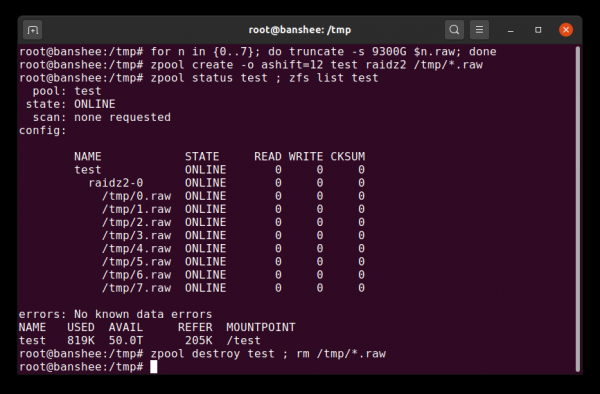
Сіз бірнеше секундта сирек файлдардан сынақ пулын жасай аласыз, бірақ кейін бүкіл пулды және оның құрамдастарын жоюды ұмытпаңыз.
Серверді сегіз дискіге орналастырғыңыз келеді делік және 10 ТБ дискілерді (~9300 ГБ) пайдалануды жоспарлап отырсыз, бірақ сіз қай топологияның қажеттіліктеріңізге сәйкес келетініне сенімді емессіз. Жоғарыдағы мысалда біз бірнеше секунд ішінде сирек файлдардан сынақ пулын жасаймыз - және қазір біз сегіз 2 ТБ дискіден тұратын RAIDz10 vdev 50 TiB жарамды сыйымдылықты қамтамасыз ететінін білеміз.
Құрылғылардың тағы бір арнайы класы - SPARE (қосалқы). Ыстық ауыстыру құрылғылары қарапайым құрылғылардан айырмашылығы, бір виртуалды құрылғыға емес, бүкіл пулға жатады. Пулдағы vdev сәтсіз болса және резервтік құрылғы пулға қосылып, қолжетімді болса, ол автоматты түрде зардап шеккен vdev жүйесіне қосылады.
Зардап шеккен vdev-ге қосылғаннан кейін қосалқы құрылғы жетіспейтін құрылғыда болуы керек деректердің көшірмелерін немесе қайта құруларын ала бастайды. Дәстүрлі RAID-те бұл қайта құру деп аталады, ал ZFS-де ол қайта қалпына келтіру деп аталады.
Қосалқы құрылғылар істен шыққан құрылғыларды біржола ауыстырмайтынын ескеру маңызды. Бұл vdev деградациясының уақытын азайту үшін уақытша ауыстыру ғана. Әкімші сәтсіз vdev файлын ауыстырғаннан кейін, артықшылық сол тұрақты құрылғыға қалпына келтіріледі және SPARE vdev жүйесінен ажыратылады және бүкіл пул үшін қосалқы құрал ретінде жұмысқа оралады.
Деректер жиындары, блоктар және секторлар
ZFS саяхатымызда түсінуге болатын құрылыс блоктарының келесі жинағы аппараттық құрал туралы азырақ және деректердің өзі қалай ұйымдастырылатыны және сақталатыны туралы көбірек. Жалпы құрылым туралы түсінікті сақтай отырып, егжей-тегжейлерді шатастырып алмау үшін біз мұнда бірнеше деңгейлерді өткізіп жатырмыз - мысалы, метаслаб -.
Деректер жинағы (деректер жинағы)
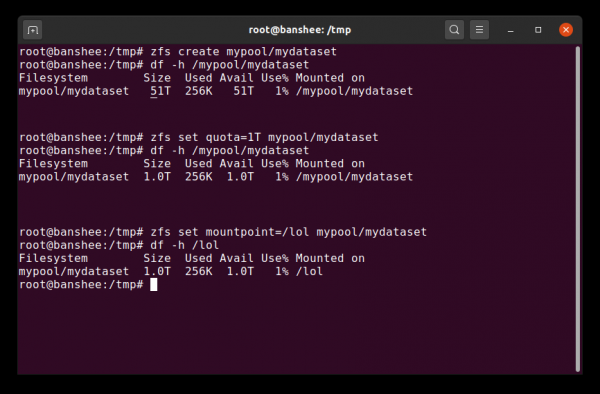
Деректер жиынын алғаш жасаған кезде ол барлық қолжетімді пул кеңістігін көрсетеді. Содан кейін біз квотаны орнатамыз - және бекіту нүктесін өзгертеміз. Сиқырлы!
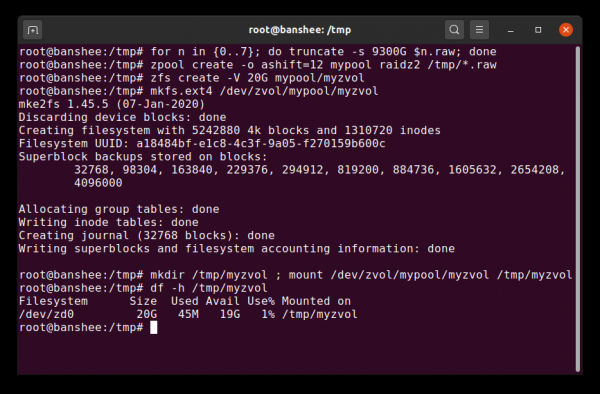
Zvol негізінен файлдық жүйе қабатынан айырылған деректер жиынтығы болып табылады, оны біз мұнда өте қалыпты ext4 файлдық жүйесімен ауыстырамыз.
ZFS деректер жинағы стандартты орнатылған файлдық жүйемен шамамен бірдей. Кәдімгі файлдық жүйе сияқты, ол бір қарағанда «басқа қалтаға» ұқсайды. Бірақ кәдімгі орнатылатын файлдық жүйелер сияқты, әрбір ZFS деректер жинағының өзінің негізгі қасиеттерінің жиынтығы бар.
Ең алдымен, деректер жиынында тағайындалған квота болуы мүмкін. Орнатылған болса zfs set quota=100G poolname/datasetname, содан кейін орнатылған қалтаға жаза алмайсыз /poolname/datasetname 100 ГБ астам.
Әр жолдың басында қиғаш сызықтардың бар-жоқтығына назар аударыңыз ба? Әрбір деректер жиынының ZFS иерархиясында да, жүйені орнату иерархиясында да өз орны бар. ZFS иерархиясында жетекші қиғаш сызық жоқ - сіз пул атауынан бастайсыз, содан кейін бір деректер жиынынан келесіге дейінгі жол. Мысалы, pool/parent/child аталған деректер жинағы үшін child негізгі деректер жинағының астында parent шығармашылық аты бар бассейнде pool.
Әдепкі бойынша деректер жиынының бекіту нүктесі ZFS иерархиясындағы оның атына балама болады, алдыңғы қиғаш сызық – пул деп аталады. pool ретінде орнатылған /pool, деректер жинағы parent орнатылған /pool/parent, және еншілес деректер жинағы child орнатылған /pool/parent/child. Дегенмен, деректер жиынының жүйені орнату нүктесін өзгертуге болады.
Егер нақтылайтын болсақ zfs set mountpoint=/lol pool/parent/child, содан кейін деректер жинағы pool/parent/child ретінде жүйеге орнатылған /lol.
Деректер жиындарына қосымша, біз томдарды (zvols) атап өтуіміз керек. Том деректер жиынымен шамамен бірдей, тек оның файлдық жүйесі жоқ — бұл жай блоктық құрылғы. Сіз, мысалы, жасай аласыз zvol Атымен mypool/myzvol, содан кейін оны ext4 файлдық жүйесімен пішімдеңіз, содан кейін сол файлдық жүйені орнатыңыз - сізде енді ext4 файлдық жүйесі бар, бірақ ZFS барлық қауіпсіздік мүмкіндіктері бар! Бұл бір құрылғыда ақымақ болып көрінуі мүмкін, бірақ iSCSI құрылғысын экспорттау кезінде сервер ретінде әлдеқайда мағынасы бар.
Блок
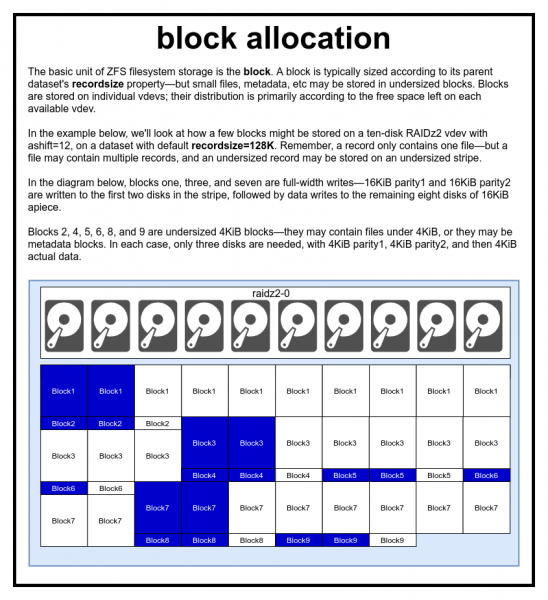
Файл бір немесе бірнеше блоктармен ұсынылған. Әрбір блок бір виртуалды құрылғыда сақталады. Блок өлшемі әдетте параметрге тең рекордтық өлшем, бірақ дейін азайтуға болады 2 ^ ауысымоның құрамында метадеректер немесе шағын файл болса.

Біз шынымен шынында Егер сіз тым аз ауысымды орнатсаңыз, үлкен өнімділік айыппұлы туралы әзілдемеңіз
ZFS пулында барлық деректер, соның ішінде метадеректер блоктарда сақталады. Әрбір деректер жиыны үшін ең үлкен блок өлшемі сипатта анықталған recordsize (рекордтық өлшем). Жазба өлшемін өзгертуге болады, бірақ бұл деректер жиынына бұрыннан жазылған блоктардың өлшемін немесе орнын өзгертпейді - ол тек жаңа блоктарға жазылған кезде әсер етеді.
Егер басқаша көрсетілмесе, ағымдағы әдепкі жазба өлшемі 128 КБ. Бұл өнімділік мінсіз болмаған күрделі сауда, бірақ көп жағдайда бұл да қорқынышты емес. Recordsize 4K пен 1M аралығындағы кез келген мәнге орнатуға болады (қосымша параметрлермен recordsize одан да көп орнатуға болады, бірақ бұл сирек жақсы идея).
Кез келген блок тек бір файлдың деректеріне сілтеме жасайды - екі түрлі файлды бір блокқа біріктіре алмайсыз. Әрбір файл өлшеміне қарай бір немесе бірнеше блоктан тұрады. Егер файл өлшемі жазба өлшемінен кішірек болса, ол кішірек блок өлшемінде сақталады - мысалы, 2 КБ файлы бар блок дискідегі тек бір 4 КБ секторды алады.
Егер файл жеткілікті үлкен болса және бірнеше блокты қажет етсе, онда бұл файлдағы барлық жазбалар өлшемді болады recordsize - оның ішінде соңғы жазба, оның негізгі бөлігі болуы мүмкін .
zvols меншікке ие емес recordsize — орнына олардың баламалы қасиеті бар volblocksize.
Секторлар
Соңғы, ең негізгі құрылыс блогы сектор болып табылады. Бұл негізгі құрылғыға жазуға немесе одан оқуға болатын ең кішкентай физикалық бірлік. Бірнеше ондаған жылдар бойы дискілердің көпшілігі 512 байт секторларды пайдаланды. Жақында дискілердің көпшілігінде 4 КБ секторлары орнатылған, ал кейбіреулерінде, әсіресе SSD дискілерде 8 киБ немесе одан да көп секторлар бар.
ZFS жүйесінде сектор өлшемін қолмен орнатуға мүмкіндік беретін қасиет бар. Бұл мүлік ashift. Біраз түсініксіз, ashift екінің дәрежесі. Мысалы, ashift=9 2^9 немесе 512 байт сектор өлшемін білдіреді.
ZFS жаңа vdev жүйесіне қосылған кезде әрбір блоктық құрылғы туралы егжей-тегжейлі ақпарат алу үшін операциялық жүйеден сұрайды және теория жүзінде осы ақпаратқа сүйене отырып, автоматты түрде ashift параметрін орнатады. Өкінішке орай, көптеген дискілер үйлесімділікті сақтау үшін сектор өлшемі туралы өтірік айтады. Windows XP (әртүрлі сектор өлшемдері бар дискілерді түсіне алмады).
Бұл ZFS әкімшісіне өз құрылғыларының нақты сектор өлшемін білуге және оны қолмен орнатуға кеңес беріледі дегенді білдіреді. ashift. Ashift тым төмен орнатылса, оқу/жазу операцияларының саны астрономиялық түрде артады. Сонымен, 512 байттық «секторларды» нақты 4 КБ секторға жазу бірінші «секторды» жазу, содан кейін 4 КБ секторды оқып, оны екінші 512 байт «сектормен өзгерту», оны жаңаға қайта жазу керек дегенді білдіреді. Әрбір жазба үшін 4 КБ секторы және т.б.
Нақты әлемде мұндай айыппұл Samsung EVO SSD дискілеріне түседі, ол үшін ashift=13, бірақ бұл SSD дискілерінің сектор өлшемі туралы өтірік айтады, сондықтан әдепкі мәнге орнатылған ashift=9. Тәжірибелі жүйе әкімшісі бұл параметрді өзгертпесе, бұл SSD жұмыс істейді Жайрақ кәдімгі магниттік қатты диск.
Салыстыру үшін, тым үлкен өлшем үшін ashift іс жүзінде ешқандай айыппұл жоқ. Нақты өнімділік айыппұлы жоқ және пайдаланылмаған кеңістіктің ұлғаюы шексіз аз (немесе қысу қосылған кезде нөлге тең). Сондықтан, тіпті 512 байт секторларды пайдаланатын дискілерді орнатуды ұсынамыз ashift=12 немесе тіпті ashift=13болашаққа сеніммен қарау.
Меншік ashift әрбір vdev виртуалды құрылғысы үшін орнатылады және бассейн үшін емес, көптеген қате ойлайтындай - және орнатудан кейін өзгермейді. Егер сіз байқаусызда ұрып қалсаңыз ashift пулға жаңа vdev қосқанда, сіз бұл пулды төмен өнімділік құрылғысымен қайтымсыз ластадыңыз және әдетте пулды жойып, қайта бастаудан басқа амал жоқ. Тіпті vdev-ті жою сізді бұзылған конфигурациядан құтқармайды ashift!
Жазу бойынша көшіру механизмі
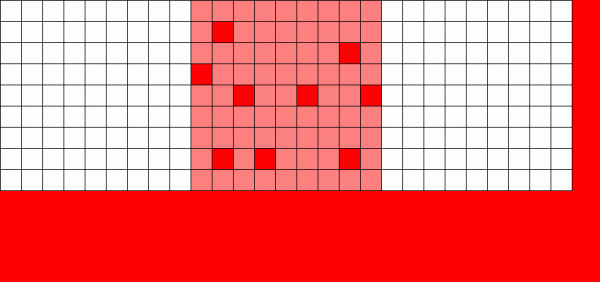
Егер кәдімгі файлдық жүйе деректерді қайта жазу қажет болса, ол әр блокты орналасқан жерінде өзгертеді
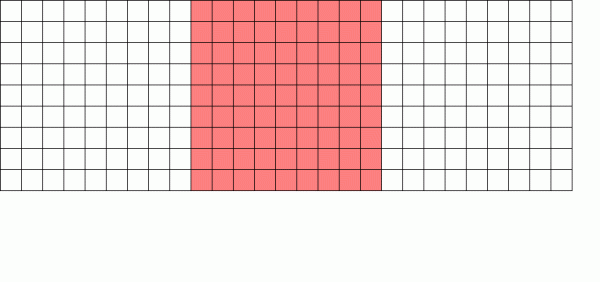
Жазуға көшіру файлдық жүйесі жаңа блок нұсқасын жазады, содан кейін ескі нұсқаның құлпын ашады

Аннотацияда, егер блоктардың нақты физикалық орналасуын елемейтін болсақ, онда біздің «деректер кометасы» қолжетімді кеңістік картасы бойынша солдан оңға қарай жылжитын «деректер құртына» жеңілдетіледі.

Енді біз жазуға көшіру суреттерінің қалай жұмыс істейтіні туралы жақсы түсінік ала аламыз - әр блок бірнеше суретке ие болуы мүмкін және барлық байланысты суреттер жойылғанша сақталады.
Copy on Write (CoW) механизмі ZFS-ті соншалықты керемет жүйеге айналдыратын негізгі негіз болып табылады. Негізгі тұжырымдама қарапайым - егер сіз дәстүрлі файлдық жүйеден файлды өзгертуді сұрасаңыз, ол сіз сұраған нәрсені дәл орындайды. Егер сіз жазуға көшіру файлдық жүйесінен дәл солай істеуді сұрасаңыз, ол «жарайды» дейді, бірақ сізге өтірік айтады.
Оның орнына, жазуға көшіру файлдық жүйесі өзгертілген блоктың жаңа нұсқасын жазады, содан кейін ескі блоктың байланысын жою және оған жаңа ғана жазған жаңа блокты байланыстыру үшін файлдың метадеректерін жаңартады.
Ескі блокты ажырату және жаңасын байланыстыру бір әрекетте орындалады, сондықтан оны үзу мүмкін емес - егер бұл орын алған соң қуат өшірілсе, сізде файлдың жаңа нұсқасы бар, ал ертерек өшірсеңіз, ескі нұсқасы болады. . Кез келген жағдайда файлдық жүйеде қайшылықтар болмайды.
ZFS жүйесінде көшіру файлдық жүйе деңгейінде ғана емес, сонымен қатар дискіні басқару деңгейінде де орын алады. Бұл ZFS-ге бос кеңістік әсер етпейтінін білдіреді () - қайта жүктеуден кейін массивтің зақымдалуымен, жүйе бұзылғанға дейін жолақ тек ішінара жазуға уақыт болған құбылыс. Мұнда жолақ атомдық түрде жазылады, vdev әрқашан дәйекті және .
ZIL: ZFS ниет журналы
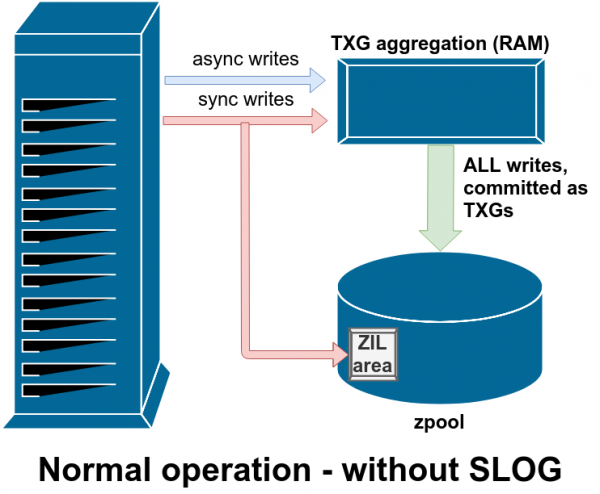
ZFS жүйесі синхронды жазуларды ерекше түрде өңдейді - ол уақытша, бірақ асинхронды жазулармен бірге кейінірек тұрақты түрде жазбас бұрын оларды бірден ZIL-де сақтайды.
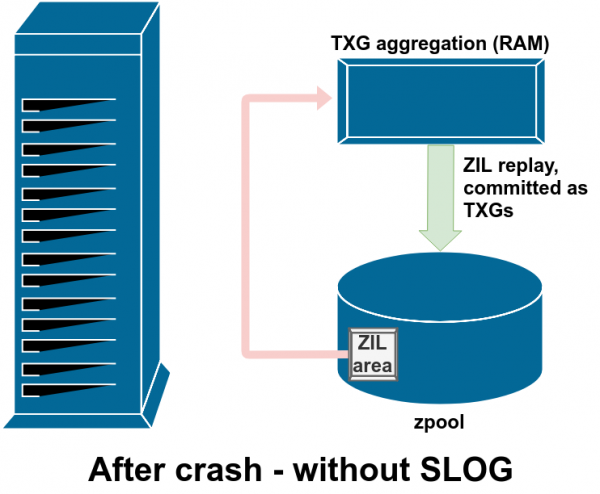
Әдетте, ZIL-ге жазылған деректер ешқашан қайта оқылмайды. Бірақ бұл жүйенің бұзылуынан кейін мүмкін
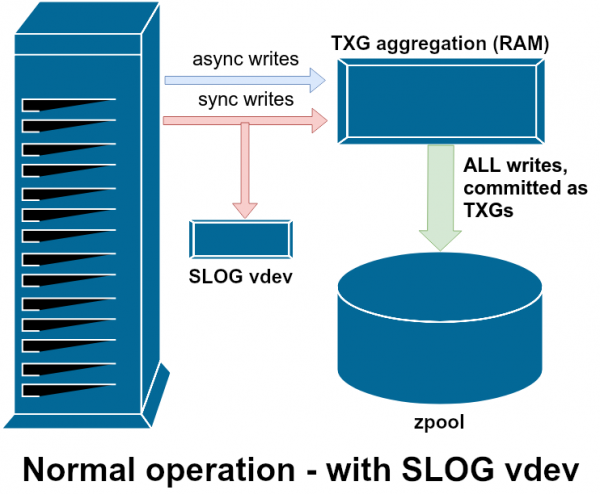
SLOG немесе қосымша LOG құрылғысы - бұл жай ғана ерекше және жақсырақ өте жылдам vdev, мұнда ZIL негізгі жадтан бөлек сақталуы мүмкін.
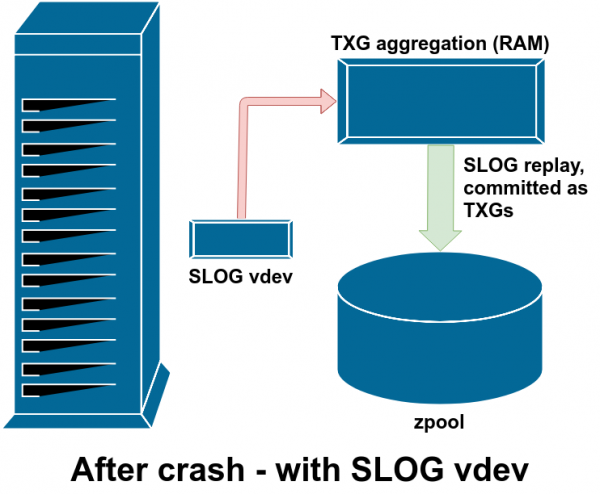
Бұзылғаннан кейін ZIL-дегі барлық лас деректер қайталанады - бұл жағдайда ZIL SLOG жүйесінде, сондықтан ол сол жерден қайталанады
Жазу операцияларының екі негізгі категориясы бар - синхронды (синхронды) және асинхронды (асинхронды). Көптеген жұмыс жүктемелері үшін жазулардың басым көпшілігі асинхронды болып табылады - файлдық жүйе оларды жинақтауға және пакеттерде шығаруға мүмкіндік береді, бұл фрагментацияны азайтады және өткізу қабілеттілігін айтарлықтай арттырады.
Синхрондалған жазбалар мүлдем басқа мәселе. Қолданба синхронды жазуды сұрағанда, ол файлдық жүйеге былай дейді: «Сіз мұны тұрақты жадқа беруіңіз керек. дәл қазірОған дейін мен басқа ештеңе істей алмаймын». Сондықтан, синхронды жазуды дереу дискіге тапсыру керек — егер бұл фрагментацияны арттырса немесе өткізу қабілеттілігін төмендетсе, солай болады.
ZFS синхронды жазуларды кәдімгі файлдық жүйелерге қарағанда басқаша өңдейді — оларды бірден тұрақты сақтауға тапсырудың орнына, ZFS оларды ZFS Intent Log немесе ZIL деп аталатын арнайы сақтау аймағына тапсырады. Ең бастысы, бұл жазбалар ақ жадта қалады, қалыпты асинхронды жазу сұрауларымен бірге жинақталады, кейінірек мүлдем қалыпты TXG (транзакция топтары) ретінде сақтауға ауыстырылады.
Қалыпты жұмыс кезінде ZIL жазылады және ешқашан оқылмайды. Бірнеше минуттан кейін ZIL жазбалары ЖЖҚ-дан қарапайым TXG-де негізгі сақтауға тапсырылғанда, олар ЗИЛ-ден ажыратылады. ЗИЛ-ден бірдеңе оқылатын жалғыз уақыт - бассейн импортталған кезде.
Егер ZFS сәтсіз болса - операциялық жүйенің бұзылуы немесе электр қуатының үзілуі - ZIL-де деректер болған кезде, бұл деректер пулдың келесі импорты кезінде оқылады (мысалы, апаттық жүйені қайта іске қосқанда). ZIL ішіндегі кез келген нәрсе оқылады, TXG-ге топтастырылады, негізгі жадқа бекітіледі, содан кейін импорт процесі кезінде ZIL-ден ажыратылады.
vdev көмекші сыныптарының бірі LOG немесе SLOG деп аталады, LOG қосымша құрылғысы. Оның бір мақсаты бар - бассейнді негізгі vdev дүкенінде сақтаудың орнына, ZIL сақтау үшін бөлек, жақсырақ әлдеқайда жылдам, жазуға өте төзімді vdev беру. ZIL өзі қай жерде сақталса да бірдей әрекет етеді, бірақ LOG vdev жазу өнімділігі өте жоғары болса, синхронды жазу жылдамырақ болады.
Пулға LOG арқылы vdev қосу жұмыс істемейді мүмкін емес асинхронды жазу өнімділігін жақсарту - тіпті ZIL-ге барлық жазуды мәжбүрлеп орындасаңыз да zfs set sync=always, олар TXG жүйесіндегі негізгі жадпен журналсыз бірдей жолмен және бірдей қарқынмен байланыстырылады. Жалғыз тікелей өнімділікті жақсарту - синхронды жазулардың кешігуі (себебі жылдам журнал операцияларды жылдамдатады). sync).
Дегенмен, көп синхронды жазуларды қажет ететін ортада vdev LOG асинхронды жазуларды және кэштелмеген оқуларды жанама түрде жылдамдата алады. ZIL жазбаларын бөлек vdev LOG-ге түсіру барлық оқу және жазу өнімділігін белгілі бір дәрежеде жақсартатын негізгі жадтағы IOPS үшін аз тартысты білдіреді.
Суреттер
Жазу бойынша көшіру механизмі сонымен қатар ZFS атомдық суреттері мен инкрементті асинхронды репликация үшін қажетті негіз болып табылады. Белсенді файлдық жүйеде барлық жазбаларды ағымдағы деректермен белгілейтін көрсеткіш ағашы бар - суретті түсіргенде, сіз жай ғана осы көрсеткіш ағашының көшірмесін жасайсыз.
Белсенді файлдық жүйеде жазба қайта жазылғанда, ZFS алдымен пайдаланылмаған кеңістікке жаңа блок нұсқасын жазады. Содан кейін ол блоктың ескі нұсқасын ағымдағы файлдық жүйеден ажыратады. Бірақ кейбір сурет ескі блокқа қатысты болса, ол әлі де өзгеріссіз қалады. Ескі блок осы блокқа сілтеме жасайтын барлық суреттер жойылмайынша бос орын ретінде қалпына келтірілмейді!
репликация
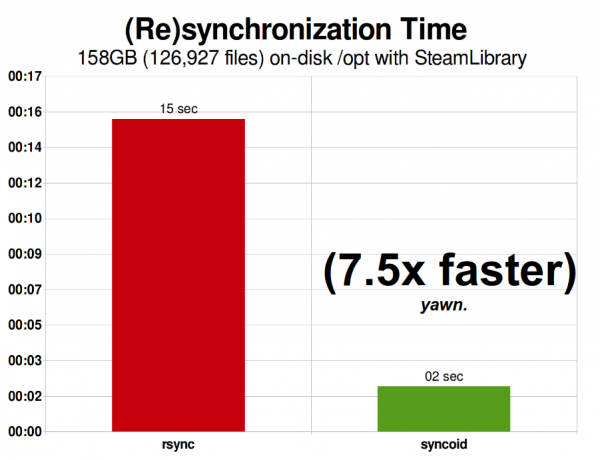
Менің Steam кітапханасы 2015 жылы 158 ГБ болды және оған 126 927 файл кіреді. Бұл rsync үшін оңтайлы жағдайға өте жақын - желі арқылы ZFS репликациясы «бар болғаны» 750% жылдамырақ болды.
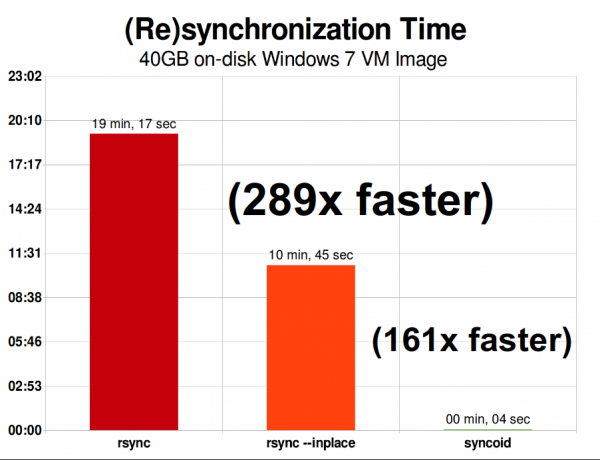
Сол желіде 40 гигабайттық виртуалды машина кескін файлының көшірмесі Windows 7 мүлдем басқа әңгіме. ZFS репликациясы rsync-ке қарағанда 289 есе жылдам немесе егер сіз --inplace қосқышы арқылы rsync-ті шақыруға жеткілікті білімді болсаңыз, «тек» 161 есе жылдам.
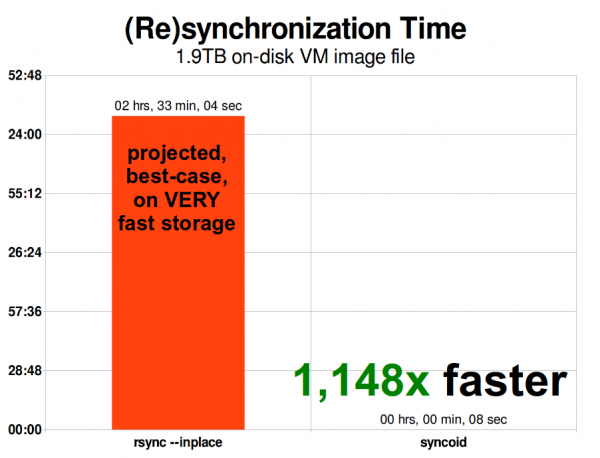
VM кескіні масштабталған кезде, rsync онымен масштабталады. 1,9 TiB заманауи VM кескіні үшін соншалықты үлкен емес - бірақ ZFS репликациясы rsync-тен 1148 есе жылдамырақ болатындай үлкен, тіпті rsync --inplace аргументі болса да.
Суреттердің қалай жұмыс істейтінін түсінгеннен кейін репликацияның мәнін түсіну оңай болуы керек. Сурет тек жазбаларға арналған көрсеткіштер ағашы болғандықтан, егер солай етсек zfs send сурет, содан кейін біз осы ағашты да, онымен байланысты барлық жазбаларды да жібереміз. Біз мұны жіберген кезде zfs send в zfs receive мақсатта ол блоктың нақты мазмұнын да, мақсатты деректер жиынына блоктарға сілтеме жасайтын көрсеткіштер ағашын да жазады.
Екіншісінде бәрі қызық болады zfs send. Қазір бізде екі жүйе бар, олардың әрқайсысында poolname/datasetname@1, және сіз жаңа суретке түсіресіз poolname/datasetname@2. Сондықтан, сізде бастапқы бассейнде datasetname@1 и datasetname@2, және мақсатты пулда әзірге тек бірінші сурет datasetname@1.
Өйткені бізде көз мен мақсат арасында ортақ сурет бар datasetname@1, біз жасай аламыз қосымша zfs send оның үстінде. Жүйеге айтқанда zfs send -i poolname/datasetname@1 poolname/datasetname@2, ол екі көрсеткіш ағашын салыстырады. Тек ішінде бар кез келген көрсеткіштер @2, жаңа блоктарға сілтеме жасайтыны анық - сондықтан бізге осы блоктардың мазмұны қажет.
Қашықтағы жүйеде инкрементті өңдеу send дәл солай қарапайым. Алдымен ағынға енгізілген барлық жаңа жазбаларды жазамыз send, содан кейін сол блоктарға көрсеткіштерді қосыңыз. Войла, бізде @2 жаңа жүйеде!
ZFS асинхронды қосымша репликациясы rsync сияқты бұрынғы суретке негізделмеген әдістерге қарағанда үлкен жақсарту болып табылады. Екі жағдайда да тек өзгертілген деректер тасымалданады, бірақ алдымен rsync керек оқыңыз дискіден қосындыны тексеру және оны салыстыру үшін екі жағындағы барлық мәліметтер. Керісінше, ZFS репликациясы көрсеткіш ағаштарынан және ортақ суретте жоқ кез келген блоктардан басқа ештеңені оқымайды.
Кірістірілген қысу
Жазу бойынша көшіру механизмі кірістірілген қысу жүйесін де жеңілдетеді. Дәстүрлі файлдық жүйеде қысу қиындық тудырады - өзгертілген деректердің ескі нұсқасы да, жаңа нұсқасы да бір кеңістікте орналасады.
Егер 0x00000000 және т.с.с нөлдерден тұратын мегабайт ретінде өмірді бастайтын файлдың ортасындағы деректер бөлігін қарастырсақ, оны дискідегі бір секторға қысу өте оңай. Бірақ сол мегабайт нөлдерді JPEG немесе псевдокездейсоқ шу сияқты сығылмайтын деректердің мегабайтымен ауыстырсақ не болады? Күтпеген жерден бұл мегабайт деректер бір емес, 256 4 КБ секторды қажет етеді және бұл жерде дискіде бір ғана сектор сақталған.
ZFS-де бұл мәселе жоқ, өйткені өзгертілген жазбалар әрқашан пайдаланылмаған кеңістікке жазылады - бастапқы блок тек бір 4 КБ секторды алады, ал жаңа жазба 256 секторды алады, бірақ бұл мәселе емес - жақында өзгертілген фрагмент " файлдың ортасы оның өлшемі өзгерген-өзгермегеніне қарамастан пайдаланылмаған кеңістікке жазылады, сондықтан ZFS үшін бұл қалыпты жағдай.
Native ZFS қысу әдепкі бойынша өшірілген және жүйе қосылатын алгоритмдерді ұсынады — қазіргі уақытта LZ4, gzip (1-9), LZJB және ZLE.
- LZ4 ағынды алгоритмі өте жылдам қысу мен ашуды және көптеген пайдалану жағдайлары үшін өнімділік артықшылықтарын ұсынады - тіпті өте баяу процессорларда.
- GZIP барлық Unix пайдаланушылары білетін және жақсы көретін құрметті алгоритм. Оны 1-деңгейге жақындаған сайын қысу коэффициенті мен процессорды пайдалану арта отырып, 9-9 қысу деңгейлерімен жүзеге асырылуы мүмкін. Алгоритм барлық мәтінді (немесе басқа жоғары қысылатын) пайдалану жағдайларына жақсы сәйкес келеді, бірақ басқа жағдайда жиі CPU мәселелерін тудырады – оны пайдаланыңыз сақтықпен, әсіресе жоғары деңгейде.
- LZJB ZFS-дегі бастапқы алгоритм болып табылады. Ол ескірген және бұдан былай пайдаланылмауы керек, LZ4 оны барлық жағынан асып түседі.
- ЖАМАН - нөл деңгейлі кодтау, нөлдік деңгей кодтау. Ол қалыпты деректерге мүлдем тимейді, бірақ нөлдердің үлкен тізбегін қысады. Толығымен сығылмайтын деректер жиындары (мысалы, JPEG, MP4 немесе басқа сығылған пішімдер) үшін пайдалы, себебі ол қысылмайтын деректерді елемейді, бірақ нәтиже жазбаларындағы пайдаланылмаған кеңістікті қысады.
Барлық дерлік пайдалану жағдайлары үшін LZ4 қысуды ұсынамыз; сығылмайтын деректерге тап болған кезде өнімділік жазасы өте аз және ұлғайту Әдеттегі деректер үшін өнімділікке әсері айтарлықтай. Жаңа операциялық жүйені орнату үшін виртуалды машина кескінін көшіру Windows (жаңа орнатылған ОС, ішінде әлі деректер жоқ) compression=lz4 қарағанда 27% жылдам өтті compression=none, in .
ARC – адаптивті ауыстыру кэш
ZFS – ЖЖҚ-да жақында оқылған блоктардың көшірмелерін сақтау үшін операциялық жүйенің бет кэшіне сүйенбей, өзінің оқу кэштеу механизмін пайдаланатын жалғыз заманауи файлдық жүйе.
Жергілікті кэш проблемаларсыз болмаса да - ZFS жаңа жадты бөлу сұрауларына ядро сияқты жылдам жауап бере алмайды, сондықтан жаңа міндет malloc() егер ол қазіргі уақытта ARC алып жатқан ЖЖҚ қажет болса, жадты бөлу сәтсіз болуы мүмкін. Бірақ өзіңіздің кэшіңізді пайдаланудың жақсы себептері бар, кем дегенде қазір.
MacOS қоса алғанда, барлық белгілі заманауи операциялық жүйелер, Windows, Linux және BSD бет кэшін іске асыру үшін LRU (ең аз қолданылған) алгоритмін пайдаланады. Бұл кэштелген блокты әрбір оқудан кейін «кезектің жоғарғы жағына» жылжытатын және жаңа кэш қателерін (кэштен емес, дискіден оқылуы керек блоктар) жоғарыға қосу үшін қажет болған жағдайда блоктарды «кезектің төменгі жағына» шығаратын қарапайым алгоритм.
Алгоритм әдетте жақсы жұмыс істейді, бірақ үлкен жұмыс деректер жинақтары бар жүйелерде LRU оңай соққыға әкеледі - кэштен ешқашан оқылмайтын блоктарға орын жасау үшін жиі қажет болатын блоктарды шығару.
«салмақталған» кэш ретінде қарастыруға болатын әлдеқайда аз аңғал алгоритм болып табылады. Кэштелген блокты оқыған сайын, оны шығару қиынырақ болады - тіпті блокты шығарғаннан кейін де қадағаланады белгілі бір уақыт аралығында. Шығарылған, бірақ кейін кэшке қайта оқуды қажет ететін блок та «ауыр» болады.
Мұның бәрінің түпкілікті нәтижесі - әлдеқайда жоғары соққы коэффициенті бар кэш, кэш соққылары (кэштен орындалатын оқулар) және кэшті өткізіп алу (дисктен оқу) арасындағы қатынас. Бұл өте маңызды статистика – кэш соққыларының өзі үлкен тапсырыстарға ғана емес, кэшті жіберіп алуларға да жылдам қызмет көрсетуге болады, өйткені кэш көп болған сайын, бір мезгілде диск сұраулары азаяды және қалған жіберіп алулар үшін кідіріс соғұрлым аз болады. дискімен бірге беріледі.
қорытынды
ZFS негізгі семантикасын - жазуға көшіру қалай жұмыс істейтінін, сондай-ақ сақтау пулдары, виртуалды құрылғылар, блоктар, секторлар және файлдар арасындағы қарым-қатынастарды үйренгеннен кейін біз нақты сандармен нақты әлемдегі өнімділікті талқылауға дайынбыз.
Келесі бөлімде біз айналы vdev және RAIDz бар пулдардың нақты өнімділігін бір-бірімен, сондай-ақ дәстүрлі ядро RAID топологияларымен салыстыра отырып қарастырамыз. Linuxбіз зерттеген .
Бастапқыда біз тек негіздерді - ZFS топологияларының өздерін ғана қарастырғымыз келді, бірақ кейін осындай L2ARC, SLOG және Арнайы бөлу сияқты көмекші vdev түрлерін пайдалануды қоса, ZFS кеңейтілген орнату және баптау туралы сөйлесуге дайындалайық.
Ақпарат көзі: www.habr.com
